一种基于列式存储数据仓库的轻量级分布式etl架构方法
技术领域:
:1.本发明涉及etl架构
技术领域:
:,特别涉及一种基于列式存储数据仓库的轻量级分布式etl架构方法。
背景技术:
::2.etl是数据仓库中非常重要的一个环节,传统的etl工具传统的etl工具是设置一个专有的转换置于数据源和目标数据仓库之间,它用于运用所有的转换程序,这种方法解决了在不同系统平台上使用不同的编程语言的问题。但是在数据转换过程中,专有执行所有转换工作成为“瓶颈”。在抽取、转换数据的时候,各数据源需要一行接一行的抽取、转换,最后存储到数据仓库中。这对与大量数据、多目标源的情况来说,读写效率非常低。此外传统etl工具在应用到分布式etl架构的过程中也存在数据不一致的问题。技术实现要素:3.针对现有技术存在的问题及技术要求,本发明的目的是提供了一种基于列式存储数据仓库的轻量级分布式etl架构方法,通过kettle工具集对数据库服务器的数据源进行抽取、转换,同时airflow分布式调度平台结合celery分布式消息队列调度作业,并采用redis集群服务器作为代理在客户端和多个工作节点之间通信,实现高可用性和水平伸缩,提高了读写效率。4.为了达到上述目的,本发明采用以下技术方案实现:5.一种基于列式存储数据仓库的轻量级分布式etl架构方法,包括数据库服务器、kettle工具集、redis集群服务器、airflow分布式调度平台、ldap统一身份认证服务器、clickhouse数据仓库集群、zookeeper集群服务器以及对象存储ks3服务器;所述的kettle工具集与数据库服务器、airflow分布式调度平台通信;所述的airflow分布式调度平台与redis集群服务器、ldap统一身份认证服务器、clickhouse数据仓库集群通信;所述的clickhouse数据仓库集群zookeeper集群服务器、对象存储ks3服务器通信。6.所述的数据库服务器,为轻量级分布式etl架构及airflow分布式调度平台提供数据源。7.所述的kettle工具集,对全量、增量数据源的抽取、转换;抽取分为对初始全量数据源的一次抽取及增量数据源的定期抽取,将抽取数据源的transformation转换、job作业组件,生成为.ktr、.kjb文件;8.转换,包括初始全量数据源转换和增量数据源转换;初始全量数据源转换,包括以下步骤:9.(s101)在kettle工具集中新建transformation,设置数据表每页数量参数n;10.(s102)新建tableinput组件,通过sql语句获取数据表记录总数t;11.(s103)通过javaexpression组件计算数据表的总页数p,得到分页的数据表;12.(s104)在kettle工具集中新建job;13.(s105)使用sql语言进行分页查询,设查询页为i,从i=1开始;14.(s106)判断是否i《p,是则跳转至步骤(s107),否则跳转步骤(s112);15.(s107)抽取第i页的数据,通过transformation转换处理;16.(s108)在kettle工具集中新建job,将transformation转换处理的返回数据写入临时csv文件;17.(s109)判断是否有ck-client客户端,是则跳转步骤(s110),否则跳转步骤(s111);18.(s110)导入临时csv文件到clickhouse数据仓库集群中,zookeeper集群服务器执行主副本同步,跳转至步骤(s111);19.(s111)删除临时csv文件,查询页i=i 1,跳转至步骤(s106);20.(s112)判断临时csv文件是否为空,是则完成初始全量数据源转换,否则删除临时csv文件,完成初始全量数据源转换;21.增量数据源转换,完成初始全量数据加载后,增量数据通过kettle工具集转换处理后,通过airflow分布式调度平台定期同步到clickhouse数据仓库集群。22.所述的redis集群服务器,作为celery分布式消息队列调度作业的代理,在客户端和多个工作节点之间通信,同时存储调度任务的状态数据。23.所述的airflow分布式调度平台,包括对登录的用户进行身份验证、分布式etl调度、批处理定时任务;对登录的用户进行身份验证采用ldap统一身份认证服务器对登录的用户进行身份验证,用户身份分为管理员用户、普通用户,并记录登录用户的基本信息、登录信息;分布式etl调度采用了celery分布式任务,并发处理数据,并通过webserver服务,在web界面上触发dag作业,scheduler计划调度服务,worker执行分布式etl调度作业,并通过flower服务监控分布式etl调度作业情况,其中分布式etl调度作业包括加载jobs.yml文件、校验jobs.yml文件格式、获取*.kjb参数、执行kettle工具集的运行命令、动态生成dag、在ui界面查看task状态、代码以及log。24.所述的clickhouse数据仓库集群,建有副本表、主表,并通过排序键指定一个数据片段内数据的排序标准,并通过分区键指定数据分区;同时通过replicatedmergetree表引擎第一个参数指定zookeeper集群服务器中创建的数据表的路径,通过replicatedmergetree表引擎第二个参数定义副本表、主表的名称;并通过zookeeper集群服务器的监听节点完成副本表、主表之间的协同。25.所述的对象存储ks3服务器,对clickhouse数据仓库集群内的数据进行备份与恢复。26.与现有技术相比,本发明的有益效果是:27.本发明一种基于列式存储数据仓库的轻量级分布式etl架构方法,针对etl架构进行整合,通过kettle工具集实现轻量级分布式etl架构的数据抽取、转换,保证了数据的一致性;通过airflow分布式调度平台提高了轻量级分布式etl架构调度作业的水平伸缩性;同时采用clickhouse数据仓库集群作为目标数据库提高了轻量级分布式etl架构的查询能力,并通过对象存储ks3服务器进行数据的保存与备份,保证数据的安全性。28.上述说明仅是本发明技术方案的概述,为了能够更清楚地了解本发明的技术手段,从而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下列举本发明的具体实施方法。29.根据下文结合附图对本发明具体实施例的详细描述,本领域技术人员将会更加明了本发明的上述及其他目的、特征和优点,但不作为对本发明的限定。附图说明30.图1为本发明的架构图;31.图2为本发明的初始全量数据源转换流程图。具体实施方式32.为了便于理解本发明,下面将对本发明进行更全面的描述。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。33.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的
技术领域:
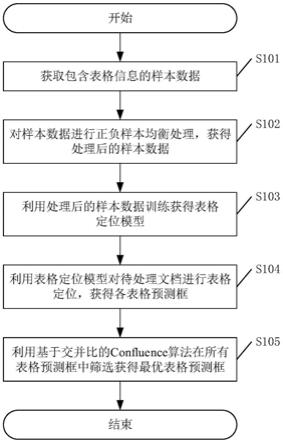
:的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。34.以下结合附图对本发明提供的具体实施方式进行详细说明。35.如图1所示,一种基于列式存储数据仓库的轻量级分布式etl架构方法的架构图,包括数据库服务器、kettle工具集、redis集群服务器、airflow分布式调度平台、ldap统一身份认证服务器、clickhouse数据仓库集群、zookeeper集群服务器以及对象存储ks3服务器;所述的kettle工具集与数据库服务器、airflow分布式调度平台通信;所述的airflow分布式调度平台与redis集群服务器、ldap统一身份认证服务器、clickhouse数据仓库集群通信;所述的clickhouse数据仓库集群zookeeper集群服务器、对象存储ks3服务器通信。36.数据库服务器,为轻量级分布式etl架构及airflow分布式调度平台提供数据源。37.kettle工具集,对全量、增量数据源的抽取、转换;抽取分为对初始全量数据源的一次抽取及增量数据源的定期抽取,将抽取数据源的transformation转换、job作业组件,生成为.ktr、.kjb文件;38.转换,包括初始全量数据源转换和增量数据源转换;39.如图2所示,一种基于列式存储数据仓库的轻量级分布式etl架构方法的初始全量数据源转换流程图,包括以下步骤:40.(s101)在kettle工具集中新建transformation,设置数据表每页数量参数n;41.(s102)新建tableinput组件,通过sql语句获取数据表记录总数t;42.(s103)通过javaexpression组件计算数据表的总页数p,得到分页的数据表;43.(s104)在kettle工具集中新建job;44.(s105)使用sql语言进行分页查询,设查询页为i,从i=1开始;45.(s106)判断是否i《p,是则跳转至步骤(s107),否则跳转步骤(s112);46.(s107)抽取第i页的数据,通过transformation转换处理;47.(s108)在kettle工具集中新建job,将transformation转换处理的返回数据写入临时csv文件;48.(s109)判断是否有ck-client客户端,是则跳转步骤(s110),否则跳转步骤(s111);49.(s110)导入临时csv文件到clickhouse数据仓库集群中,zookeeper集群服务器执行主副本同步,跳转至步骤(s111);50.(s111)删除临时csv文件,查询页i=i 1,跳转至步骤(s106);51.(s112)判断临时csv文件是否为空,是则完成初始全量数据源转换,否则删除临时csv文件,完成初始全量数据源转换;52.增量数据源转换,完成初始全量数据加载后,增量数据通过kettle工具集转换处理后,通过airflow分布式调度平台定期同步到clickhouse数据仓库集群。53.redis集群服务器,作为celery分布式消息队列调度作业的代理,在客户端和多个工作节点之间通信,同时存储调度任务的状态数据。54.airflow分布式调度平台,包括对登录的用户进行身份验证、分布式etl调度、批处理定时任务;对登录的用户进行身份验证采用ldap统一身份认证服务器对登录的用户进行身份验证,用户身份分为管理员用户、普通用户,并记录登录用户的基本信息、登录信息;分布式etl调度采用了celery分布式任务,并发处理数据,并通过webserver服务,在web界面上触发dag作业,scheduler计划调度服务,worker执行分布式etl调度作业,并通过flower服务监控分布式etl调度作业情况,其中分布式etl调度作业包括加载jobs.yml文件、校验jobs.yml文件格式、获取*.kjb参数、执行kettle工具集的运行命令、动态生成dag、在ui界面查看task状态、代码以及log。55.clickhouse数据仓库集群,建有副本表、主表,并通过排序键指定一个数据片段内数据的排序标准,并通过分区键指定数据分区;同时通过replicatedmergetree表引擎第一个参数指定zookeeper集群服务器中创建的数据表的路径,通过replicatedmergetree表引擎第二个参数定义副本表、主表的名称;并通过zookeeper集群服务器的监听节点完成副本表、主表之间的协同。56.对象存储ks3服务器,对clickhouse数据仓库集群内的数据进行备份与恢复。57.以上所述实例的各技术特征可以进行任意组合,为使描述简洁,未对上述实例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。58.以上所述实例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此理解为对本发明范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和非实质性的改进,这些都属于本发明的保护范围。因此,本发明的保护范围应以所附权利要求为准。当前第1页12当前第1页12
技术领域:
:1.本发明涉及etl架构
技术领域:
:,特别涉及一种基于列式存储数据仓库的轻量级分布式etl架构方法。
背景技术:
::2.etl是数据仓库中非常重要的一个环节,传统的etl工具传统的etl工具是设置一个专有的转换置于数据源和目标数据仓库之间,它用于运用所有的转换程序,这种方法解决了在不同系统平台上使用不同的编程语言的问题。但是在数据转换过程中,专有执行所有转换工作成为“瓶颈”。在抽取、转换数据的时候,各数据源需要一行接一行的抽取、转换,最后存储到数据仓库中。这对与大量数据、多目标源的情况来说,读写效率非常低。此外传统etl工具在应用到分布式etl架构的过程中也存在数据不一致的问题。技术实现要素:3.针对现有技术存在的问题及技术要求,本发明的目的是提供了一种基于列式存储数据仓库的轻量级分布式etl架构方法,通过kettle工具集对数据库服务器的数据源进行抽取、转换,同时airflow分布式调度平台结合celery分布式消息队列调度作业,并采用redis集群服务器作为代理在客户端和多个工作节点之间通信,实现高可用性和水平伸缩,提高了读写效率。4.为了达到上述目的,本发明采用以下技术方案实现:5.一种基于列式存储数据仓库的轻量级分布式etl架构方法,包括数据库服务器、kettle工具集、redis集群服务器、airflow分布式调度平台、ldap统一身份认证服务器、clickhouse数据仓库集群、zookeeper集群服务器以及对象存储ks3服务器;所述的kettle工具集与数据库服务器、airflow分布式调度平台通信;所述的airflow分布式调度平台与redis集群服务器、ldap统一身份认证服务器、clickhouse数据仓库集群通信;所述的clickhouse数据仓库集群zookeeper集群服务器、对象存储ks3服务器通信。6.所述的数据库服务器,为轻量级分布式etl架构及airflow分布式调度平台提供数据源。7.所述的kettle工具集,对全量、增量数据源的抽取、转换;抽取分为对初始全量数据源的一次抽取及增量数据源的定期抽取,将抽取数据源的transformation转换、job作业组件,生成为.ktr、.kjb文件;8.转换,包括初始全量数据源转换和增量数据源转换;初始全量数据源转换,包括以下步骤:9.(s101)在kettle工具集中新建transformation,设置数据表每页数量参数n;10.(s102)新建tableinput组件,通过sql语句获取数据表记录总数t;11.(s103)通过javaexpression组件计算数据表的总页数p,得到分页的数据表;12.(s104)在kettle工具集中新建job;13.(s105)使用sql语言进行分页查询,设查询页为i,从i=1开始;14.(s106)判断是否i《p,是则跳转至步骤(s107),否则跳转步骤(s112);15.(s107)抽取第i页的数据,通过transformation转换处理;16.(s108)在kettle工具集中新建job,将transformation转换处理的返回数据写入临时csv文件;17.(s109)判断是否有ck-client客户端,是则跳转步骤(s110),否则跳转步骤(s111);18.(s110)导入临时csv文件到clickhouse数据仓库集群中,zookeeper集群服务器执行主副本同步,跳转至步骤(s111);19.(s111)删除临时csv文件,查询页i=i 1,跳转至步骤(s106);20.(s112)判断临时csv文件是否为空,是则完成初始全量数据源转换,否则删除临时csv文件,完成初始全量数据源转换;21.增量数据源转换,完成初始全量数据加载后,增量数据通过kettle工具集转换处理后,通过airflow分布式调度平台定期同步到clickhouse数据仓库集群。22.所述的redis集群服务器,作为celery分布式消息队列调度作业的代理,在客户端和多个工作节点之间通信,同时存储调度任务的状态数据。23.所述的airflow分布式调度平台,包括对登录的用户进行身份验证、分布式etl调度、批处理定时任务;对登录的用户进行身份验证采用ldap统一身份认证服务器对登录的用户进行身份验证,用户身份分为管理员用户、普通用户,并记录登录用户的基本信息、登录信息;分布式etl调度采用了celery分布式任务,并发处理数据,并通过webserver服务,在web界面上触发dag作业,scheduler计划调度服务,worker执行分布式etl调度作业,并通过flower服务监控分布式etl调度作业情况,其中分布式etl调度作业包括加载jobs.yml文件、校验jobs.yml文件格式、获取*.kjb参数、执行kettle工具集的运行命令、动态生成dag、在ui界面查看task状态、代码以及log。24.所述的clickhouse数据仓库集群,建有副本表、主表,并通过排序键指定一个数据片段内数据的排序标准,并通过分区键指定数据分区;同时通过replicatedmergetree表引擎第一个参数指定zookeeper集群服务器中创建的数据表的路径,通过replicatedmergetree表引擎第二个参数定义副本表、主表的名称;并通过zookeeper集群服务器的监听节点完成副本表、主表之间的协同。25.所述的对象存储ks3服务器,对clickhouse数据仓库集群内的数据进行备份与恢复。26.与现有技术相比,本发明的有益效果是:27.本发明一种基于列式存储数据仓库的轻量级分布式etl架构方法,针对etl架构进行整合,通过kettle工具集实现轻量级分布式etl架构的数据抽取、转换,保证了数据的一致性;通过airflow分布式调度平台提高了轻量级分布式etl架构调度作业的水平伸缩性;同时采用clickhouse数据仓库集群作为目标数据库提高了轻量级分布式etl架构的查询能力,并通过对象存储ks3服务器进行数据的保存与备份,保证数据的安全性。28.上述说明仅是本发明技术方案的概述,为了能够更清楚地了解本发明的技术手段,从而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下列举本发明的具体实施方法。29.根据下文结合附图对本发明具体实施例的详细描述,本领域技术人员将会更加明了本发明的上述及其他目的、特征和优点,但不作为对本发明的限定。附图说明30.图1为本发明的架构图;31.图2为本发明的初始全量数据源转换流程图。具体实施方式32.为了便于理解本发明,下面将对本发明进行更全面的描述。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。33.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的
技术领域:
:的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。34.以下结合附图对本发明提供的具体实施方式进行详细说明。35.如图1所示,一种基于列式存储数据仓库的轻量级分布式etl架构方法的架构图,包括数据库服务器、kettle工具集、redis集群服务器、airflow分布式调度平台、ldap统一身份认证服务器、clickhouse数据仓库集群、zookeeper集群服务器以及对象存储ks3服务器;所述的kettle工具集与数据库服务器、airflow分布式调度平台通信;所述的airflow分布式调度平台与redis集群服务器、ldap统一身份认证服务器、clickhouse数据仓库集群通信;所述的clickhouse数据仓库集群zookeeper集群服务器、对象存储ks3服务器通信。36.数据库服务器,为轻量级分布式etl架构及airflow分布式调度平台提供数据源。37.kettle工具集,对全量、增量数据源的抽取、转换;抽取分为对初始全量数据源的一次抽取及增量数据源的定期抽取,将抽取数据源的transformation转换、job作业组件,生成为.ktr、.kjb文件;38.转换,包括初始全量数据源转换和增量数据源转换;39.如图2所示,一种基于列式存储数据仓库的轻量级分布式etl架构方法的初始全量数据源转换流程图,包括以下步骤:40.(s101)在kettle工具集中新建transformation,设置数据表每页数量参数n;41.(s102)新建tableinput组件,通过sql语句获取数据表记录总数t;42.(s103)通过javaexpression组件计算数据表的总页数p,得到分页的数据表;43.(s104)在kettle工具集中新建job;44.(s105)使用sql语言进行分页查询,设查询页为i,从i=1开始;45.(s106)判断是否i《p,是则跳转至步骤(s107),否则跳转步骤(s112);46.(s107)抽取第i页的数据,通过transformation转换处理;47.(s108)在kettle工具集中新建job,将transformation转换处理的返回数据写入临时csv文件;48.(s109)判断是否有ck-client客户端,是则跳转步骤(s110),否则跳转步骤(s111);49.(s110)导入临时csv文件到clickhouse数据仓库集群中,zookeeper集群服务器执行主副本同步,跳转至步骤(s111);50.(s111)删除临时csv文件,查询页i=i 1,跳转至步骤(s106);51.(s112)判断临时csv文件是否为空,是则完成初始全量数据源转换,否则删除临时csv文件,完成初始全量数据源转换;52.增量数据源转换,完成初始全量数据加载后,增量数据通过kettle工具集转换处理后,通过airflow分布式调度平台定期同步到clickhouse数据仓库集群。53.redis集群服务器,作为celery分布式消息队列调度作业的代理,在客户端和多个工作节点之间通信,同时存储调度任务的状态数据。54.airflow分布式调度平台,包括对登录的用户进行身份验证、分布式etl调度、批处理定时任务;对登录的用户进行身份验证采用ldap统一身份认证服务器对登录的用户进行身份验证,用户身份分为管理员用户、普通用户,并记录登录用户的基本信息、登录信息;分布式etl调度采用了celery分布式任务,并发处理数据,并通过webserver服务,在web界面上触发dag作业,scheduler计划调度服务,worker执行分布式etl调度作业,并通过flower服务监控分布式etl调度作业情况,其中分布式etl调度作业包括加载jobs.yml文件、校验jobs.yml文件格式、获取*.kjb参数、执行kettle工具集的运行命令、动态生成dag、在ui界面查看task状态、代码以及log。55.clickhouse数据仓库集群,建有副本表、主表,并通过排序键指定一个数据片段内数据的排序标准,并通过分区键指定数据分区;同时通过replicatedmergetree表引擎第一个参数指定zookeeper集群服务器中创建的数据表的路径,通过replicatedmergetree表引擎第二个参数定义副本表、主表的名称;并通过zookeeper集群服务器的监听节点完成副本表、主表之间的协同。56.对象存储ks3服务器,对clickhouse数据仓库集群内的数据进行备份与恢复。57.以上所述实例的各技术特征可以进行任意组合,为使描述简洁,未对上述实例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。58.以上所述实例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此理解为对本发明范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和非实质性的改进,这些都属于本发明的保护范围。因此,本发明的保护范围应以所附权利要求为准。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。