1.本发明涉及数据处理领域,尤其涉及一种数据恢复方法及终端。
背景技术:
2.随着手机厂商、应用厂商对数据安全性的重视,不断提高对数据保护的方式方法,不仅是对现有数据加强保护,也逐渐地对删除数据加强其不可恢复性。比如,手机应用大部分使用sqlite存储数据,而常见对数据彻底抹除的方法为删除后对相应的字节置零,使传统数据恢复手段无法生效。
3.数据保护手段提高,恢复技术也从未停止探索。手机数据恢复领域经过多年研究发展,从传统的sqlite文件恢复技术,到之后的镜像文件碎片、数据库备份文件、会话文件、索引数据库等恢复技术,每项技术的产生都能在某一阶段内提高有效数据的恢复能力。
4.目前市面上已知的各项恢复技术随着手机厂商、应用厂商的加固,均很难恢复到可用数据。例如,镜像文件碎片因高版本android系统被加密导致无法恢复出碎片文件,android端索引数据库被加密并且删除置零也导致无法恢复到有效数据。
技术实现要素:
5.本发明所要解决的技术问题是:提供一种数据恢复方法,实现对数据的恢复。
6.为了解决上述技术问题,本发明采用的一种技术方案为:
7.一种数据恢复方法,包括步骤:
8.获取分词数据,所述分词数据包括分词碎片标识和所述分词碎片标识对应的数据块;
9.按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到目标分词碎片时,获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容;
10.根据所述分词碎片标识拼接所述分词碎片内容,得到还原数据;
11.对比所述还原数据和未删除数据,得到已删除数据。
12.为了解决上述技术问题,本发明采用的另一种技术方案为:
13.一种数据恢复终端,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
14.获取分词数据,所述分词数据包括分词碎片标识和所述分词碎片标识对应的数据块;
15.按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到目标分词碎片时,获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容;
16.根据所述分词碎片标识拼接所述分词碎片内容,得到还原数据;
17.对比所述还原数据和未删除数据,得到已删除数据。
18.本发明的有益效果在于:因为了方便数据的检索,现在数据存储除了作为完整数据存储外,还会进行分片并建立索引方便进行数据查找,删除完整数据时,对应的分片数据通常不会删除,此时通过按照分片得到的分词碎片的分词碎片标识递增排列,遍历还原出分词碎片对应的分词碎片内容,最终拼接得到还原数据,因未删除的数据的分片数据也会被存储,故经过和未删除数据的排重后就能得到已删除数据,实现数据恢复,并且适用于所有进行分片存储的系统中如全文检索系统中。
附图说明
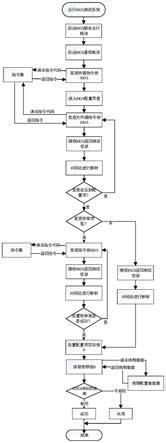
19.图1为本发明实施例的一种数据恢复方法的步骤流程图;
20.图2为本发明实施例的一种数据恢复终端的结构示意图;
21.图3为本发明实施例的一种分词碎片标识示意图;
22.图4为本发明实施例的一种数据块示意图;
23.图5为本发明实施例的一种滑动窗口示意图;
24.图6为本发明实施例的一种原始数据示意图;
25.图7为本发明实施例的一种还原数据示意图;
26.图8为本发明实施例的未标记的滑动窗口示意图;
27.图9为本发明实施例的一种数据恢复方法的过程示意图;
28.图10为本发明实施例的实现一种数据恢复方法的系统框图;
29.标号说明:
30.1、一种数据恢复终端;2、处理器;3、存储器。
具体实施方式
31.为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
32.请参照图1,一种数据恢复方法,包括步骤:
33.获取分词数据,所述分词数据包括分词碎片标识和所述分词碎片标识对应的数据块;
34.按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到目标分词碎片时,获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容;
35.根据所述分词碎片标识拼接所述分词碎片内容,得到还原数据;
36.对比所述还原数据和未删除数据,得到已删除数据。
37.从上述描述可知,本发明的有益效果在于:因为了方便数据的检索,现在数据存储除了作为完整数据存储外,还会进行分片并建立索引方便进行数据查找,删除完整数据时,对应的分片数据通常不会删除,此时通过按照分片得到的分词碎片的分词碎片标识递增排列,遍历还原出分词碎片对应的分词碎片内容,最终拼接得到还原数据,因未删除的数据的分片数据也会被存储,故经过和未删除数据的排重后就能得到已删除数据,实现数据恢复,并且适用于所有进行分片存储的系统中如全文检索系统中。
38.进一步地,所述按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到
目标分词碎片时,获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容具体为:
39.按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到目标分词碎片时,判断所述目标分词碎片与前一分词碎片的分词碎片标识是否连续,若是,则保留所述前一分词碎片的缓冲数据后,获取所述目标分词碎片对应的所述目标数据块,并根据所述缓冲数据集所述目标数据块还原分词碎片内容;并拼接所述分词碎片内容和前一分词碎片对应的分词碎片内容;
40.否则,直接获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容。
41.由上述描述可知,因一段完整数据可能会被分为多个分词碎片且通常在分词过程中会有关联性,在进行解析时,若是分词碎片标识连续的分词碎片,则将解析其前一个分词碎片的缓存内容保存,提高解析结果的准确度,即保证还原数据的准确。
42.进一步地,所述获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容包括:
43.获取所述目标数据块中的索引定位字节,根据所述索引定位字节得到解析位置;
44.从所述解析位置开始,获取滑动窗口结构,并根据所述滑动窗口结构获取待确定位置,采用第一预设公式或第二预设公式计算所述待确定位置的值,并根据所述滑动窗口结构从所述解析位置开始解析,还原分词碎片内容。
45.由上述描述可知,得到解析位置后,因不同的分词算法有不同的滑动窗口结构,有的滑动窗口的值就是实际含义值,有的滑动窗口的值需要进行转换才能得到其实际含义,此时需要借助根据具体分词算法对应的公式和待确定位置获取滑动窗口中存储值的隐含含义,从而确认每个滑动窗口的内容,实现分词碎片内容的确定。
46.进一步地,获取预设分词算法;
47.根据所述预设分词算法获取所述第一预设公式及所述第二预设公式。
48.由上述描述可知,分词的算法有很多,根据不同的分词算法获取不同的预设公式,使得滑动窗口的解析结果能够与原意一致,避免出现错误。
49.进一步地,所述对比所述还原数据和未删除数据,得到已删除数据包括:
50.对比所述还原数据和未删除数据,标记不与所述未删除数据对应的所述还原数据为已删除数据。
51.由上述描述可知,因原始数据中可能存在一些不会被分片形成分词碎片的字符,故此时可获取相似度判断还原数据是否与未删除数据对应,而不是通过一致性判断,提高最终输出的已删除数据的准确性。
52.请参照图2,一种数据恢复终端,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
53.获取分词数据,所述分词数据包括分词碎片标识和所述分词碎片标识对应的数据块;
54.按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到目标分词碎片时,获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容;
55.根据所述分词碎片标识拼接所述分词碎片内容,得到还原数据;
56.对比所述还原数据和未删除数据,得到已删除数据。
57.本发明的有益效果在于:因为了方便数据的检索,现在数据存储除了作为完整数据存储外,还会进行分片并建立索引方便进行数据查找,删除完整数据时,对应的分片数据通常不会删除,此时通过按照分片得到的分词碎片的分词碎片标识递增排列,遍历还原出分词碎片对应的分词碎片内容,最终拼接得到还原数据,因未删除的数据的分片数据也会被存储,故经过和未删除数据的排重后就能得到已删除数据,实现数据恢复,并且适用于所有进行分片存储的系统中如全文检索系统中。
58.进一步地,所述按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到目标分词碎片时,获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容具体为:
59.按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到目标分词碎片时,判断所述目标分词碎片与前一分词碎片的分词碎片标识是否连续,若是,则保留所述前一分词碎片的缓冲数据后,获取所述目标分词碎片对应的所述目标数据块,并根据所述缓冲数据集所述目标数据块还原分词碎片内容;并拼接所述分词碎片内容和前一分词碎片对应的分词碎片内容;
60.否则,直接获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容。
61.由上述描述可知,因一段完整数据可能会被分为多个分词碎片且通常在分词过程中会有关联性,在进行解析时,若是分词碎片标识连续的分词碎片,则将解析其前一个分词碎片的缓存内容保存,提高解析结果的准确度,即保证还原数据的准确。
62.进一步地,所述获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容包括:
63.获取所述目标数据块中的索引定位字节,根据所述索引定位字节得到解析位置;
64.从所述解析位置开始,获取滑动窗口结构,并根据所述滑动窗口结构获取待确定位置,采用第一预设公式或第二预设公式计算所述待确定位置的值,并根据所述滑动窗口结构从所述解析位置开始解析,还原分词碎片内容。
65.由上述描述可知,得到解析位置后,因不同的分词算法有不同的滑动窗口结构,有的滑动窗口的值就是实际含义值,有的滑动窗口的值需要进行转换才能得到其实际含义,此时需要借助根据具体分词算法对应的公式和待确定位置获取滑动窗口中存储值的隐含含义,从而确认每个滑动窗口的内容,实现分词碎片内容的确定。
66.进一步地,获取预设分词算法;
67.根据所述预设分词算法获取所述第一预设公式及所述第二预设公式。
68.由上述描述可知,分词的算法有很多,根据不同的分词算法获取不同的预设公式,使得滑动窗口的解析结果能够与原意一致,避免出现错误。
69.进一步地,所述对比所述还原数据和未删除数据,得到已删除数据包括:
70.对比所述还原数据和未删除数据,标记不与所述未删除数据对应的所述还原数据为已删除数据。
71.由上述描述可知,因原始数据中可能存在一些不会被分片形成分词碎片的字符,
故此时可获取相似度判断还原数据是否与未删除数据对应,而不是通过一致性判断,提高最终输出的已删除数据的准确性。
72.本发明上述一种数据恢复方法及终端能够适用于存在数据分片的系统中,如fts(full text search,全文检索)系统,以下通过具体实施方式进行说明:
73.请参照图1,本发明的实施例一为:
74.一种数据恢复方法,具体包括:
75.s1、获取分词数据,所述分词数据包括分词碎片标识和所述分词碎片标识对应的数据块;
76.请参照图3,图中id即为分词碎片标识示意图;
77.s2、按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到目标分词碎片时,获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容,具体为:
78.s21、按照所述分词碎片标识的递增关系遍历所述分词碎片,当遍历到目标分词碎片时,判断所述目标分词碎片与前一分词碎片的分词碎片标识是否连续,若是,则执行s22,否则,执行s23;
79.请参照图3,图3中recno12和13所对应的id即为连续的分词碎片标识;
80.s22、保留所述前一分词碎片的缓冲数据后,获取所述目标分词碎片对应的所述目标数据块,并根据所述缓冲数据集所述目标数据块还原分词碎片内容;并拼接所述分词碎片内容和前一分词碎片对应的分词碎片内容;
81.s23、直接获取所述目标分词碎片对应的所述目标数据块,并根据所述目标数据块还原分词碎片内容,包括:
82.s231、获取所述目标数据块中的索引定位字节,根据所述索引定位字节得到解析位置;
83.请参照图4,即为目标数据块示意图,如图4中为fts系统下分片时得到的数据块,则根据其中第三字节和第四字节为索引定位字节,可以获取索引位置0275;从该位置可以获取索引的值从而确定解析位置;
84.s232、从所述解析位置开始,获取滑动窗口结构,并根据所述滑动窗口结构获取待确定位置,采用第一预设公式或第二预设公式计算所述待确定位置的值,并根据所述滑动窗口结构从所述解析位置开始解析,还原分词碎片内容;
85.其中,在s232之前包括:根据所述预设分词算法获取所述滑动窗口结构、所述第一预设公式及所述第二预设公式;
86.请参照图5,为滑动窗口示意图,a类型为每个碎片数据块首个滑动窗口的规则即滑动窗口结构,由分词内容长度、1字节填充、分词内容字节、索引内容id、副本数(0=2
÷
2-1)及分词id组成;b类型为后续滑动窗口的规则即滑动窗口的结构,由字节继承数(0=1-1)、分词内容长度、分词内容字节、索引内容id、副本数(0=2
÷
2-1)及分词id组成;通过这两种规则对每个滑动窗口数据进行解析;
87.其中,分词内容长度表示分词内容字节所占的字节数;索引内容id表示该滑动窗口对应的索引内容标识;副本数表示该滑动窗口的备份数,分词id表示该滑动窗口在目标分词碎片中的位置,若一个目标分词碎片的分词碎片内容与其他分词碎片关联,则分词id
从预设数量开始编号,如01表示目标分词碎片的内容不与其他分词碎片的内容关联,大于01则表示目标分词碎片的分词碎片内容与其他分词碎片关联;字节继承数表示从前一分词碎片中分词内容字节里继承的字节的个数;
88.在一种可选的实施方式中,第一预设公式为:
89.sn×
1280 (s
n-1
–
128)
×
1281
…
(s1–
128)
×
128
n-1
;
90.第二预设公式为:
91.(sn×
1280 (s
n-1
–
128)
×
1281
…
(s1–
128)
×
128
n-1
)
÷2–192.其中,n表示参与计算的字节个数,sn表示第n个字节的值。
93.则,在计算副本数时使用第二预设公式,在计算索引内容id、分词id及字节继承数时都使用第一预设公式;
94.则可知,若字节继承数为1,则表示从前一分词碎片继承1个字节,此时需要获取前一分词碎片对应的缓存数据;如图4中02 02 ba 86 17 02 06;表示从上个分词“不”(utf编码0xe4b88d)继承了一个字节0xe4(图4中位于0x3e位置的字节),则得到分词碎片内容“了”(utf编码0xe4ba86);
95.由如,请参照图8,左侧为右侧字符对应的滑动窗口内容,“没”的utf8编码为0xe6b2a1,滑动窗口第1个字节0x02表示继承1个字节(1=2-1),第2个字节0x02表示后续两个字节0xb2、0xa1为分词的组成部分,第5个字节0x13表示该分词所在的消息id为19,第6个字节0x02表示副本数为0(0=2
÷
2-1),第7个字节表示分词id为2(一条数据内的多个分词,分词id为2开始累加)。“加”、“密”也同理,得出分词id分别为3、4,对该消息重组后即得到完整内容“没加密”;
96.s3、根据所述分词碎片标识拼接所述分词碎片内容,得到还原数据;
97.请参照图6,为原始数据示意,图7为还原数据示意,因一些符号不会产生分词,二者会存在一定差异;
98.s4、对比所述还原数据和未删除数据,得到已删除数据,包括:
99.对比所述还原数据和未删除数据,标记不与所述未删除数据对应的还原数据为已删除数据;其中,对比未删除数据与还原数据的相似度,若相似度超过阈值,则认为该还原数据和未删除数据是对应的,即为同一条数据。
100.请参照图2,本发明的实施例二为:
101.一种数据恢复终端1,包括处理器2、存储器3及存储在存储器3上并可在所述处理器2上运行的计算机程序,所述处理器2执行所述计算机程序时实现实施例一中的各个步骤。
102.综上所述,本发明提供了一种数据恢复方法及终端,利用现有数据为了方便检索会进行分片的特征,在原数据被删除的情况下通过获取对应的分片数据进行分析,根据分片数据得到还原数据,因不论是已删除数据还是未删除数据,都会存在对应的分片及分词碎片,故根据还原数据和未删除数据是否一致还可以判断还原是否准确,最终进行与未删除数据的排重即可获取已删除数据,能够确保所恢复的已删除数据的准确性,并且只要存在建立索引、进行分片的系统中都可实现数据恢复,实用性强。
103.以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括
在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。