1.本发明涉及网络技术领域,特别是一种基于深度强化学习的网络流量调度方法以及系统。
背景技术:
2.随着互联网的快速发展,人们对广域网数据传播有了更高的要求。一方面需要更大的带宽保障,一方面对数据传输的可靠性提高了要求。在这种情况下,如何选取满足qos需求的链路成了当下的研究热点。
3.基于早期提出的“推动网络的创新,需要在硬件数据通路上编程”的论述,即动态网络,研究人员一开始想法就是分层,将数据与控制分开。随着研究的进行,三层的sdn(软件定义网络)应运而生。实现了对底层数据的解耦合,数据与控制层分开。传统的研究思路在sdn架构中控制层使用ospf等传统算法进行链路选择,但局限性很大,传统算法只是选择跳数最短的链路,并不是实际上时延最小或者带宽较大的链路,容易造成链路阻塞。在此基础上,q学习为寻路提供了很好的帮助,基于马尔科夫决策的q学习为每一个状态遍历所有可以选择的动作,从而选择最优的动作,局限性在于当状态和动作逐渐增加时,遍历效率就变得低下,也会浪费很大的存储空间。
技术实现要素:
4.发明目的:为克服现有技术的局限,本发明目的在于提供一种网络流量调度方法以及系统,采用了一种基于深度强化学习的深度q学习来进行寻路,通过利用sdn的全局视图,与实际环境交互,在学习与训练中通过计算链路之间的实际指标来获得最优最合适的链路,最后将智能体部署到真实环境中,达到智能化的寻路结果。
5.技术方案:为实现上述发明目的,本发明采用以下技术方案:
6.基于深度强化学习的网络流量调度方法,包括如下步骤:
7.软件定义网络sdn控制器收集网络信息,包括端口、带宽和时延信息;
8.对收集到的网络信息进行处理,计算出整个网络中的所有链路状态指标,包括带宽指标、时延指标和丢包率,并将每一条链路的相关信息设置成元组形式,存储到网络信息数据存储库中;每一个元组包括源节点,目的节点以及对应的指标信息;
9.以网络信息数据存储库中的信息作为输入,为随机状态s
t
选择最优的动作a
t
,然后到达下一个状态s
t 1
,同时获得奖励r
t
;将新的元组信息《s
t
,a
t
,s
t 1
,r
t
》存储在数据集中,方便后续采用经验重放机制进行训练;
10.根据全局视图,采用双重深度q学习网络ddqn对路径状态信息进行探索与学习,计算出每一对源、目的节点之间的最优路径,将这些路径存储在链路数据存储库;
11.根据实际流量转发需求,检索最优路径,同时将检索到的最优路径部署到相应的路由设备上。
12.作为优选,sdn控制器从底层转发设备收集网络信息,根据这些信息生成整个网络
的实际拓扑图,通过周期性地收集节点和链路的拓扑信息,检测节点和链路相关的拓扑变化,并将这些信息存储到网络信息数据存储库中,实时提供更新后的全局视图。
13.作为优选,使用深度强化学习drl来计算出最优路径,将路径状态信息作为输入,输出的是动态变化的最优路径,根据实时的拓扑变化,寻路会出现不同的结果,最后部署或者更新交换机的路径信息。
14.作为优选,基于ddqn算法学习从初始状态到目标状态,即源节点到目标节点,转换过程中所采取的一系列步骤;每个步骤包括选择和执行一个行动,改变状态,以及获得奖励;ddqn的三个指标的设定分别为:
15.状态空间:是ddqn可以观测到的状态的集合,每一个状态都是代表着通信的源、目的节点对,在给定n个节点的网络中,状态空间大小为n!/(n-2)!,ddqn根据全局视图来构建状态空间;
16.动作空间:是对于状态空间中状态转换所执行的动作的集合,状态a
t
∈[1,
…
,k]对应着对于给定的状态s
t
的路径选择pi∈[p1,
…
,pk],其中k表示当前状态可选择的动作数量;
[0017]
奖励函数:根据路径指标计算出来的,路径的指标包括三个部分:带宽bandwidth
link
,丢包率d
link
以及时延l
link
,奖励函数的计算方式为,奖励函数的计算方式为既奖励函数与带宽成反比,与时延以及丢包成正比;其中βa、βb、l
link
三个参数是可调的,在[0,1]之内,为计算奖励提供权重值。
[0018]
作为优选,为了避免某个度量指标影响太大,对奖励函数进行归一化处理,将度量的范围重新缩放到一个范围[a,b];归一化过程如下:
[0019]
其中每个xi为待归一化的值,为归一化后的值,x为归一化所用值的集合;
[0020]
归一化后的奖励函数的计算表达式如下:
[0021][0022]
其中分别是归一化后的带宽、丢包率以及时延。
[0023]
作为优选,采用双重深度q学习网络来逼近最优策略,两个网络分别是目标神经网络以及在线神经网络;在线神经网络的作用是根据状态s
t
的奖励值r
t
获得更新后的q值:获得更新后的q值:其中q
t
(s
t
,a
t
)是状态s
t
对应动作a
t
的更新前q值,q
t 1
(s
t
,a
t
)是更新后的值,α是预设的权值,表示未更新时候到达下一状态s
t 1
获得最小q值的估计值;目标神经网络根据关联状态获得最小q值对应的动作再根据这个动作获得更新后的q值:q
t 1
′
(s
t
,a
t
)=r
t
γ*q
t
(s
t
,a
′
),γ是预设的权值,q
t
(s
t
,a
′
)是未更新时候当前状态的最优q值;在学习过程中,训练在线神经网络减小损失函数:loss=(q
t 1
′
(s
t
,a
t
)-q
t 1
(s
t
,a
t
))2,即减小两网络更新后的差值。
[0024]
作为优选,在学习阶段,为了提高训练的稳定性,目标神经网络和在线神经网络的权重是一样的;在训练过程中,目标神经网络的权重在预定步数之后定期进行更新来配合在线神经网络;两个网络的结构是一样的,输入层只有一个神经元,将状态作为输入,输出层有k个神经元,也就是动作空间中的k个动作都有一个神经元,输出层根据每个动作来计算对应的q值;两个网络全连接层之前添加有卷积层,通过卷积层处理流量之间的关系,当相似流多次经过时,不会浪费资源重复计算路径。
[0025]
基于所述的网络流量调度方法的流量调度系统,包括知识层、管理层、控制层和数据层的四层sdn结构;
[0026]
所述数据层,由一系列不存在主动转发能力的交换机以及与其相连的主机构成,通过南向接口向控制层发送底层的全局信息,并接收控制层传下来的转发策略,根据策略进行路由转发;
[0027]
所述控制层,从数据层收集全局信息,将全局信息统计成矩阵形式,存储到管理层,后通过北向接口转发给知识层作为drl智能体的输入,而后将转发策略下发到数据层;
[0028]
所述管理层,包含数据处理模块和网络信息数据存储库,数据处理模块利用控制层收集到的原始数据,计算出链路可用带宽、时延和丢包率,这些度量用来描述路由选择的链路状态;
[0029]
所述知识层,通过drl智能体学习网络行为,智能计算路径;知识层与管理层和控制层交互,检索链路状态信息和计算路由并下发安装路由信息。
[0030]
作为优选,数据层的交换机使用open vswitch交换机,控制层使用open daylight控制器;当交换机接收到数据传输时,会先去查询自身的流表项是否存在对应的下一跳,如果不存在,通过南向openflow协议的packet_in消息将该数据包发往控制器,询问控制器如何处理,而后控制器在通过drl智能体寻路后,将最优路径安装到交换机上,完成寻路过程。
[0031]
基于相同的发明构思,本发明提供的一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现所述的基于深度强化学习的网络流量调度方法。
[0032]
有益效果:与现有技术相比,本发明具有以下技术效果:
[0033]
本发明能够对网络寻路中存在的过估计问题进行改良,原生的dqn算法当动作选择估计出现问题时,后续的寻路都在错误的动作上进行,使得寻路造成过估计问题,ddqn则很好的解决了这个问题。本发明方法中使用最小奖励的q值在设计使得寻路更精准。在实际生活中,丢包率可能很小,时延大部分是毫秒级而带宽则偏向于一个较大的数值,进行正相关时,时延和丢包会产生精度丢失,而负相关则使得对于三个参数的关注度更相近。此外,引入的逻辑上的四层结构对于传统的三层结构来说更突出了寻路算法的重要性,控制层中更多是控制器自身的信息流转,而知识层中时嵌入的学习好的智能体不再是控制器的信息流转,称之为知识层更符合算法的整体结构,逻辑更为清晰。
附图说明
[0034]
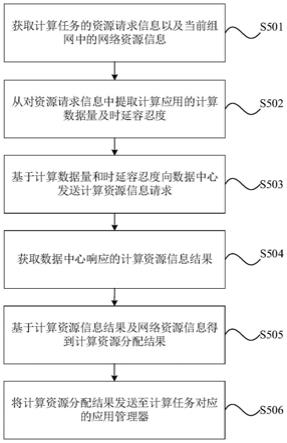
图1为本发明实施例的网络流量调度方法流程图。
[0035]
图2为本发明实施例的网络流量调度系统架构图。
[0036]
图3为本发明实施例中智能寻路算法流程图。
具体实施方式
[0037]
下面结合附图和具体实施例对本发明方案做进一步说明。
[0038]
如图1所示,本发明实施例提供的一种基于深度强化学习的网络流量调度方法,包括以下步骤:
[0039]
步骤一、网络信息收集。sdn控制器中的拓扑发现模块通过南向协议open flow获取一段时间内的实时网络信息,包括端口信息以及带宽信息、时延信息等,控制器收集这些信息备用,为后续信息处理做信息累计。
[0040]
步骤二、管理层的数据处理模块对收集到的网络信息进行处理,通过计算获得所有链路的状态指标。
[0041]
1.带宽指标:对于任意一条链路k∈m(m即为实时拓扑中的链路集合),对于其上的每一个节点i∈k,这条链路的带宽指标取带宽最小的那一段。
[0042]
2.时延指标:对于任意一条链路k∈m,对于其上的每一个节点i∈k,链路延迟等于每一对节点之间的延迟之和。
[0043]
3.丢包率:对于任意一条链路k∈m,对于其上的每一个节点i∈k,这条链路的丢包率为单位1减去每一对节点之间的准确送达率连乘。
[0044]
将每一条链路的相关信息设置成元组形式《res,dst,bw
res,dst
,d
res,dst
,l
res,dst
》,包括源节点res、目的节点dst以及对应的指标信息,存储到网络信息数据存储库中,供给ddqn进行寻路。
[0045]
步骤三、管理层的数据处理模块将控制层传输的数据处理完成后存储到网络信息数据存储库中。以网络信息数据存储库中的信息作为输入,采用epsilon-greedy方法为当前的随机状态s
t
选择最优的动作a
t
,然后到达下一个状态s
t 1
,同时获得他的奖励r
t
。将新的元组信息《s
t
,a
t
,s
t 1
,r
t
》存储在数据集中,方便后续采用经验重放机制进行训练。
[0046]
步骤四、根据全局视图,采用双重深度q学习网络ddqn对路径状态信息进行探索与学习,计算出每一对源、目的节点之间的最优路径,将这些路径存储在链路数据存储库。
[0047]
本步骤中基于ddqn算法学习从初始状态到目标状态,即源节点到目标节点,转换过程中所采取的一系列步骤;每个步骤包括选择和执行一个行动,改变状态,以及获得奖励;ddqn的三个指标的设定分别为:
[0048]
状态空间:是ddqn可以观测到的状态的集合,每一个状态都是代表着通信的源、目的节点对,在给定n个节点的网络中,状态空间大小为n!/(n-2)!,ddqn根据全局视图来构建状态空间;
[0049]
动作空间:是对于状态空间中状态转换所执行的动作的集合,状态a
t
∈[1,
…
,k]对应着对于给定的状态s
t
的路径选择pi∈[p1,
…
,pk],其中k表示当前状态可选择的动作数量;
[0050]
奖励函数:根据路径指标计算出来的,路径的指标包括三个部分:带宽bandwidth
link
,丢包率d
link
以及时延l
link
,奖励函数的计算方式为
既奖励函数与带宽成反比,与时延以及丢包成正比;其中βa、βb、l
link
三个参数是可调的,在[0,1]之内,为计算奖励提供权重值。
[0051]
为了避免某个度量指标影响太大,对奖励函数进行归一化处理,将度量的范围重新缩放到一个范围[a,b];归一化过程如下:
[0052]
其中每个xi为待归一化的值,为归一化后的值,x为归一化所用值的集合;
[0053]
归一化后的奖励函数的计算表达式如下:
[0054][0055]
其中分别是归一化后的带宽、丢包率以及时延。
[0056]
采用双重深度q学习网络来逼近最优策略,两个网络分别是目标神经网络以及在线神经网络。当迭代的步数超过设定的训练步数时,ddqn从重放内存中获取一个小批处理来训练在线神经网络,使用经验重放机制可以使得智能体在更少的交互中就可以学习。在线神经网络的作用是根据状态s
t
的奖励值r
t
获得更新后的q值:其中q
t
(s
t
,a
t
)是状态s
t
对应动作a
t
的更新前q值,q
t 1
(s
t
,a
t
)是更新后的值,α是预设的权值,表示未更新时候到达下一状态s
t 1
获得最小q值的估计值;目标神经网络根据关联状态获得最小q值对应的动作q值对应的动作再根据这个动作获得更新后的q值:q
t 1
′
(s
t
,a
t
)=r
t
γ*q
t
(st,a
′
),γ是预设的权值,q
t
(s
t
,a
′
)是未更新时候当前状态的最优q值;在学习过程中,训练在线神经网络减小损失函数:loss=(q
t 1
′
(s
t
,a
t
)-q
t 1
(s
t
,a
t
))2,即减小两网络更新后的差值,避免了过度估计的问题。然后,利用梯度下降和反向传播算法来调整在线神经网络的权值和偏差。用在线神经网络的权值和偏差更新目标神经网络的权值和偏差,ddqn代理然后移动到下一个状态。在学习阶段,为了提高训练的稳定性,目标神经网络和在线神经网络的权重是一样的;在训练过程中,目标神经网络的权重在预定步数之后定期进行更新来配合在线神经网络;两个网络的结构是一样的,输入层只有一个神经元,将状态作为输入,输出层有k个神经元,也就是动作空间中的k个动作都有一个神经元,输出层根据每个动作来计算对应的q值;两个网络全连接层之前添加有卷积层,通过卷积层处理流量之间的关系,当相似流多次经过时,不会浪费资源重复计算路径。
[0057]
步骤五、最后,在ddqn完成状态转换之后,通过每一个状态对应的最小q值来检索对应的路径选择,将这些路径存储在候选链路数据存储库。
[0058]
步骤六、根据实际流量转发需求,检索最优路径,同时将检索到的最优路径部署到相应的路由设备上。可通过控制器中的流量安装模块通过北向接口将实际路径安装到数据层的转发设备上,这里安装过程是通过南向协议的帮助实现的。
[0059]
基于上述的网络流量调度方法的网络流量调度系统,包括知识层、管理层、控制层、数据层的四层sdn结构。
[0060]
数据层,由一系列不存在主动转发能力的交换机以及与其相连的主机构成,通过
南向接口向控制层发送底层的全局信息,并接收控制层传下来的转发策略,根据策略进行路由转发。
[0061]
控制层,从数据层收集全局信息,将全局信息统计成矩阵形式,存储到管理层,后通过北向接口转发给知识层作为drl智能体的输入,而后将转发策略下发到数据层。控制层包括拓扑发现、统计和流程安装三个模块。拓扑发现模块用于收集数据层的数据信息,统计模块用于对信息进行处理,流量安装模块用于将最优路径安装到open vswitch中。
[0062]
管理层,包含数据处理模块和网络信息数据存储库,数据处理模块利用控制层收集到的原始数据,计算出链路可用带宽、时延和丢包率,这些度量用来描述路由选择的链路状态。
[0063]
知识层,通过drl智能体学习网络行为,智能计算路径;知识层与管理层和控制层交互,检索链路状态信息和计算路由并下发安装路由信息。
[0064]
数据层的交换机可使用open vswitch交换机,控制层可使用open daylight控制器;当交换机接收到数据传输时,会先去查询自身的流表项是否存在对应的下一跳,如果不存在,通过南向openflow协议的packet_in消息将该数据包发往控制器,询问控制器如何处理,而后控制器在通过drl智能体寻路后,将最优路径安装到交换机上,完成寻路过程。
[0065]
图2为本发明实施例的流量调度系统的总体架构图,本发明实施例采用如图2所示的框架实现,在知识层,存在ddqn智能体,可以通过历史信息来实现寻路过程,以及候选链路存储库;在管理层中存在网络信息数据存储库;在控制层使用基于python开发的open daylight控制器,开发控制器南向采用openflow协议与数据层的open vswitch交换机通信,北向接口采用rest api与应用平面通信;数据平面采用open vswitch交换机,根据流表项实现对数据包的转发等相应的操作。物理上的sdn三层结构形成了逻辑上的四层结构。
[0066]
在一个实施例中,流量调度的实现步骤如下:
[0067]
步骤1、在控制器文件夹下添加新的网络流量调度配置与应用程序文件。
[0068]
步骤2、在添加的网络流量调度配置与应用程序文件完成对控制器核心包库的调用和声明,并实现对controller、toaster、handler等基类的继承和函数的3定义,尤其是监听packet_in消息事件对应的handler定义,实现与控制器的通信。
[0069]
步骤3、开发ddqn智能体,实现智能寻路过程,并且将寻路结果暂存候选路径存储库中。
[0070]
步骤4、将对应的寻路结果经过流量安装模块安装到数据层的交换机上。
[0071]
图3所示为ddqn智能体智能寻路算法流程图。算法输入为n(训练总步骤数)、ε(ε-greedy大小,表示采取ε的概率使用以往的经验去学习,1-ε的概率进行随机探索)、de(衰变率)、rm(经验重放开始大小)、tup(目标网络更新的频率),nn(神经网络)。
[0072]
当训练次数小于预定次数时,获得最初的初始状态s
t
,判断s
t
的下一个状态是否是最终状态,若是则算法结束,反之更新ε,同时为当前状态选择最合适的动作到下一状态并将当前元组信息存储到数据集中。
[0073]
此时,判断是否到经验重放开始时期,未达到,继续进行元组信息获取过程,反之,开始进行学习阶段,ddqn用在线神经网络估计当前q值,以及与之关联的最优动作,随着当前动作获得目标网络对应的下一个状态的q值,防止过估计。最小化损失函数以及更新在线网络的权重。
[0074]
此时开始判断是否到达目标网络权重更新阶段,若还没有,则继续训练,反之更新目标网络权重,并到达下一状态,直至整个算法结束。
[0075]
在一个实施例中,网络流量调度系统的工作流程如下:
[0076]
步骤1、数据层的open vswitch交换机接收到数据包,解析数据,匹配交换机中的流表项,如果匹配到流表项,则根据流表项进行调度,如果没有匹配到流表项,则通过南向openflow协议的packet_in消息将该数据包发往控制器,询问控制器如何处理;
[0077]
步骤2、知识层通过北向rest api监听到达控制器的packet_in消息,并获取packet_in消息中包含的数据内容。解析数据,根据经验重放进行寻路过程。
[0078]
步骤3、知识层的网络流量调度结果,通过北向rest api连接控制器发送packet_out消息,将数据包发回到交换机,以及通过flow_mod消息发送流表到交换机,指示该数据包到达交换机之后该执行的操作;
[0079]
步骤4、数据层的open vswitch交换机根据流表项指示的相应操作对数据进行调度。
[0080]
基于相同的发明构思,本发明实施例还提供了一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该计算机程序被加载至处理器时实现上述的基于深度强化学习的网络流量调度方法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。