1.本发明属于大数据存储系统领域,具体涉及基于信息流的大数据存储系统。
背景技术:
2.信息流的广义定义是指人们采用各种方式来实现信息交流,从面对面的交谈直到采用各种现代化的传递媒介,信息流的狭义定义是从现代信息技术研究、发展、应用的角度看,指的是信息处理过程中信息在计算机系统和通信网络中的流动。
3.目前,专利号为cn201811575618.5的发明专利公开了一种基于大数据的信息流存储系统,所述存储系统包括依次电连接的信息源、信息采集模块、数据处理模块和存储模块,所述信息源包括本地信息存储模块、异地信息存储模块和互联网信息存储模块;所述信息采集模块包括第一信息采集模块、第二信息采集模块、第三信息采集模块、登录信息采集模块和第一输出模块,所述本地信息存储模块与第一信息采集模块电连接,所述异地信息存储模块与第二信息采集模块电连接,所述互联网信息存储模块与第三信息采集模块电连接,所述本地信息存储模块、异地信息存储模块和互联网信息存储模块分别与登录信息采集模块电连接,所述第一信息采集模块、第二信息采集模块、第三信息采集模块和登录信息采集模块分别与第一输出模块电连接;所述数据处理模块包括第一数据接收模块、第一访问接收模块、数据分析模块、数据优化模块和第二输出模块,所述第一输出模块分别与第一数据接收模块、第一访问接收模块电连接,所述第一数据接收模块、第一访问接收模块分别与数据分析模块电连接,所述数据分析模块、数据优化模块和第二输出模块依次电连接;所述存储模块包括第一存储模块和第二存储模块,所述第二输出模块、第一存储模块、第二存储模块依次电连接,其通过数据处理模块进行数据的处理分析操作,最后通过存储模块进行存储或查询,增加了系统的存储能力,但是该系统存在任务不能并行处理,因此数据存储的耗时较长,且不能对数据进行预处理,源数据中含有较多的有问题数据,后续的处理难度大,并且没有创建索引,不利于数据的查找。
4.因此,针对上述不能对数据进行预处理和没有索引的问题,亟需得到解决,以改善存储系统的使用场景。
技术实现要素:
5.(1)要解决的技术问题针对现有技术的不足,本发明的目的在于提供基于信息流的大数据存储系统,该存储系统旨在解决现有技术下任务不能并行处理,因此数据存储的耗时较长,且不能对数据进行预处理,源数据中含有较多的有问题数据,后续的处理难度大,并且没有创建索引,不利于数据的查找的技术问题。
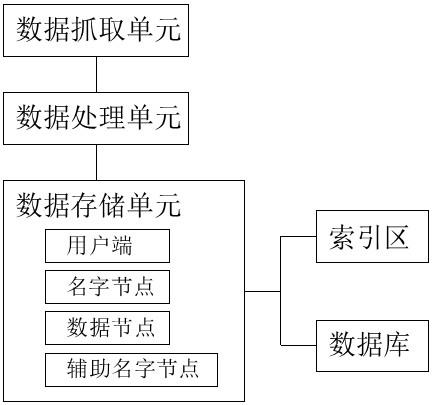
6.(2)技术方案为了解决上述技术问题,本发明提供了这样基于信息流的大数据存储系统,该存储系统包括数据抓取单元、数据预处理单元和数据存储单元;其中,
所述数据抓取单元根据抓取策略,将互联网上的网页下载到本地,其流程为:首先选取种子url;将种子url放入待抓取url队列;从待抓取url队列中取出待抓取url,解析dns,并且得到主机的ip,并将url对应的网页下载下来,存储进已下载网页库中,然后将这些已抓取的url放进已抓取url队列;分析已抓取url队列中的url,分析其中的其他url,并且将url放入待抓取url队列,从而进入下一个循环;所述数据预处理单元针对数据抓取单元抓取到的有问题数据进行清洗和转换,数据清洗和转换的处理方式包括:纠正错误、删除重复项、统一规格、修正逻辑、转换构造、数据压缩;所述数据存储单元包括索引区和数据库,所述数据存储单元内预装有用户端、名字节点、数据节点和辅助名字节点,所述数据存储单元用于存储数据预处理单元处理后的数据,其具体存储步骤为:(1)构建数据索引;(2)用户端创建一个新的文件;(3)调用名字节点,去创建一个没有block关联的新文件,创建前,名字节点校验文件是否存在,判断用户端有无权限去创建,校验通过后,名字节点就会记录下新文件;(4)用户端开始写数据,并把数据切成一个个小packet,然后排成队列 data queue,为每个packet构建一个map任务,在每个map任务中调用map函数对packet中的每条数据记录进行处理;(5)处理接受 data queue,先问询名字节点这个新的 block 最适合存储的数据节点,把它们排成一个 pipeline,把 packet 按队列输出到管道的第一个数据节点中,第一个名字节点又把 packet 输出到第二个数据节点中,以此类推;(6)map的输出位于运行map任务的节点的本地磁盘上,任务有5个复制线程,因此可以并行地复制map的输出,当所有map的输出复制完毕后,会进行总的merge,这个阶段将所有的map输出进行合并,维持其顺序排序,合并是循环进行的;(7)用户端完成写数据后,调用close方法关闭写入流。
7.使用本技术方案的存储系统时,(1)构建数据索引;(2)用户端创建一个新的文件;(3)调用名字节点,去创建一个没有block关联的新文件,创建前,名字节点校验文件是否存在,判断用户端有无权限去创建,校验通过后,名字节点就会记录下新文件;(4)用户端开始写数据,并把数据切成一个个小packet,然后排成队列 data queue,为每个packet构建一个map任务,在每个map任务中调用map函数对packet中的每条数据记录进行处理;(5)处理接受 data queue,先问询名字节点这个新的 block 最适合存储的数据节点,把它们排成一个 pipeline,把 packet 按队列输出到管道的第一个数据节点中,第一个名字节点又把 packet 输出到第二个数据节点中,以此类推;(6)map的输出位于运行map任务的节点的本地磁盘上,任务有5个复制线程,因此可以并行地复制map的输出,当所有map的输出复制完毕后,会进行总的merge,这个阶段将所有的map输出进行合并,维持其顺序排序,合并是循环进行的;(7)用户端完成写数据后,调用close方法关闭写入流。
8.优选地,所述数据抓取单元的抓取策略为大站优先策略,即对于待抓取url队列中的所有网页,根据所属的网站进行分类,对于待下载页面数多的网站,优先下载。
9.优选地,所述数据抓取单元抓取到的有问题数据的数据错误形式包括:数据值错
误、数据类型错误、数据编码错误、数据格式错误、数据异常错误、依赖冲突、多值错误。
10.优选地,所述数据预处理单元中统一规格的处理包括以下几个方面:名称、类型、单位、格式、长度、小数位数、计数方法、缩写规则、值域、约束。
11.优选地,所述数据预处理单元中转换构造的内容包括:数据类型转换、数据语义转换、数据值域转换、数据粒度转换、表/数据拆分、行列转换、数据离散化、提炼新字段、属性构造、数据压缩。
12.优选地,所述用户端与名字节点交互,能获取文件的位置信息,用户端与数据节点交互,能读取或者写入数据,所述名字节点用来处理客户端读写请求,所述数据节点用来存储实际的数据块并执行数据块的读写操作,所述辅助名字节点,分担名字节点的工作量。
13.优选地,所述构建数据索引的具体步骤为:首先指定数据的reduce个数为32,map进程检测输入文件的输入格式、对key进行计算,然后输出,指定分区函数,对记录进行分区,即根据各自项目的需求,使这些记录分发到每个reduce进程去,每个reduce接收数据,基于本地磁盘创建lucene索引,把索引合成一整块。
14.优选地,所述数据预处理单元中数据压缩的处理方式包括:数据聚合、维度约减、数据块消减、数据无损压缩和数据有损压缩。
15.(3)有益效果与现有技术相比,本发明的有益效果在于:本发明的存储系统利用map任务有5个复制线程,因此可以并行地复制map的输出任务,因此提高数据存储的速度,且通过数据预处理单元针对数据抓取单元抓取到的有问题数据进行清洗和转换,其目的为纠正错误、删除重复项、统一规格、修正逻辑、转换构造、数据压缩,从而保证数据的完整性,且减少数据量,便于数据的后续处理,并且通过构建数据索引,利用索引的唯一性可以确保数据的唯一性,同时可以加快数据的检索速度,减少分组和排序时间。
附图说明
16.图1为本发明存储系统一种具体实施方式的整体框架结构示意图;图2为本发明存储系统一种具体实施方式的流程图。
具体实施方式
17.实施例1本具体实施方式是基于信息流的大数据存储系统,其整体框架结构示意图如图1所示,其流程图如图2所示,该存储系统包括数据抓取单元、数据预处理单元和数据存储单元;数据抓取单元根据抓取策略,将互联网上的网页下载到本地,其流程为:首先选取种子url;将种子url放入待抓取url队列;从待抓取url队列中取出待抓取url,解析dns,并且得到主机的ip,并将url对应的网页下载下来,存储进已下载网页库中,然后将这些已抓取的url放进已抓取url队列;分析已抓取url队列中的url,分析其中的其他url,并且将url放入待抓取url队列,从而进入下一个循环;数据预处理单元针对数据抓取单元抓取到的有问题数据进行清洗和转换,数据清洗和转换的处理方式包括:纠正错误、删除重复项、统一规格、修正逻辑、转换构造、数据压
缩;数据存储单元包括索引区和数据库,数据存储单元内预装有用户端、名字节点、数据节点和辅助名字节点,数据存储单元用于存储数据预处理单元处理后的数据,其具体存储步骤为:(1)构建数据索引;(2)用户端创建一个新的文件;(3)调用名字节点,去创建一个没有block关联的新文件,创建前,名字节点校验文件是否存在,判断用户端有无权限去创建,校验通过后,名字节点就会记录下新文件;(4)用户端开始写数据,并把数据切成一个个小packet,然后排成队列 data queue,为每个packet构建一个map任务,在每个map任务中调用map函数对packet中的每条数据记录进行处理;(5)处理接受 data queue,先问询名字节点这个新的 block 最适合存储的数据节点,把它们排成一个 pipeline,把 packet 按队列输出到管道的第一个数据节点中,第一个名字节点又把 packet 输出到第二个数据节点中,以此类推;(6)map的输出位于运行map任务的节点的本地磁盘上,任务有5个复制线程,因此可以并行地复制map的输出,当所有map的输出复制完毕后,会进行总的merge,这个阶段将所有的map输出进行合并,维持其顺序排序,合并是循环进行的;(7)用户端完成写数据后,调用close方法关闭写入流。
18.其中,数据抓取单元的抓取策略为大站优先策略,即对于待抓取url队列中的所有网页,根据所属的网站进行分类,对于待下载页面数多的网站,优先下载,数据抓取单元抓取到的有问题数据的数据错误形式包括:数据值错误、数据类型错误、数据编码错误、数据格式错误、数据异常错误、依赖冲突、多值错误。
19.同时,数据预处理单元中统一规格的处理包括以下几个方面:名称、类型、单位、格式、长度、小数位数、计数方法、缩写规则、值域、约束,数据预处理单元中转换构造的内容包括:数据类型转换、数据语义转换、数据值域转换、数据粒度转换、表/数据拆分、行列转换、数据离散化、提炼新字段、属性构造、数据压缩。
20.另外,用户端与名字节点交互,能获取文件的位置信息,用户端与数据节点交互,能读取或者写入数据,名字节点用来处理客户端读写请求,数据节点用来存储实际的数据块并执行数据块的读写操作,辅助名字节点,分担名字节点的工作量,构建数据索引的具体步骤为:首先指定数据的reduce个数为32,map进程检测输入文件的输入格式、对key进行计算,然后输出,指定分区函数,对记录进行分区,即根据各自项目的需求,使这些记录分发到每个reduce进程去,每个reduce接收数据,基于本地磁盘创建lucene索引,把索引合成一整块。
21.此外,数据预处理单元中数据压缩的处理方式包括:数据聚合、维度约减、数据块消减、数据无损压缩和数据有损压缩。
22.使用本技术方案的存储系统时,(1)构建数据索引;(2)用户端创建一个新的文件;(3)调用名字节点,去创建一个没有block关联的新文件,创建前,名字节点校验文件是否存在,判断用户端有无权限去创建,校验通过后,名字节点就会记录下新文件;(4)用户端开始写数据,并把数据切成一个个小packet,然后排成队列 data queue,为每个packet构建一
个map任务,在每个map任务中调用map函数对packet中的每条数据记录进行处理;(5)处理接受 data queue,先问询名字节点这个新的 block 最适合存储的数据节点,把它们排成一个 pipeline,把 packet 按队列输出到管道的第一个数据节点中,第一个名字节点又把 packet 输出到第二个数据节点中,以此类推;(6)map的输出位于运行map任务的节点的本地磁盘上,任务有5个复制线程,因此可以并行地复制map的输出,当所有map的输出复制完毕后,会进行总的merge,这个阶段将所有的map输出进行合并,维持其顺序排序,合并是循环进行的;(7)用户端完成写数据后,调用close方法关闭写入流。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
