技术特征:
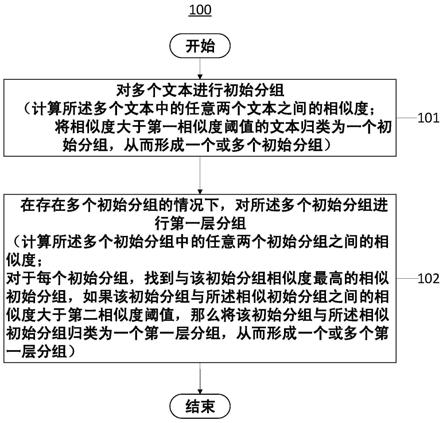
1.一种对包含近似词语的多个文本进行分组的方法,包括:对所述多个文本进行初始分组,包括:计算所述多个文本中的任意两个文本之间的相似度;将相似度大于第一相似度阈值的文本归类为一个初始分组,从而形成一个或多个初始分组;在存在多个初始分组的情况下,对所述多个初始分组进行第一层分组,包括:计算所述多个初始分组中的任意两个初始分组之间的相似度;对于每个初始分组,找到与该初始分组相似度最高的相似初始分组,如果该初始分组与所述相似初始分组之间的相似度大于第二相似度阈值,那么将该初始分组与所述相似初始分组归类为一个第一层分组,从而形成一个或多个第一层分组。2.根据权利要求1所述的方法,还包括:在存在多个较低层分组的情况下,对该多个较低层分组进行后续层分组,包括:计算所述多个较低层分组中的任意两个较低层分组之间的相似度;对于每个较低层分组,找到与该较低层分组相似度最高的相似较低层分组,如果该较低层分组与所述相似较低层分组之间的相似度大于对应的相似度阈值,那么将该较低层分组与所述相似较低层分组归类为一个较高层分组,从而形成一个或多个较高层分组;以及重复进行后续层分组,直到无法继续对较低层分组进行归类,或者已将所有较低层分组归类到同一组。3.根据权利要求2所述的方法,还包括:针对每一层分组,按照分组中的成员数量、分组的组号以及相似度高低,以从上级到下级的顺序排序。4.根据权利要求2所述的方法,其中,较高层的分组步骤中使用的相似度阈值小于较低层的分组步骤中使用的相似度阈值。5.根据权利要求1所述的方法,其中,通过将每个文本转换成向量,并利用向量来计算两个文本之间的相似度。6.根据权利要求2所述的方法,其中,对于每一层中的每个分组,通过生成分组中的各分组成员的组代表分词,将组代表分词转换成向量,并利用向量来计算每一层中的两个分组之间的相似度。7.根据权利要求2所述的方法,其中,将每一层中的一个分组中的各成员与另一分组中的各成员之间的相似度的中位值或平均值,作为这两个分组之间的相似度。8.根据权利要求1所述的方法,还包括:在进行所述初始分组之前,对每个文本进行关键词提取处理,从而获得与所述多个文本分别对应的多个词组,以及基于所述多个词组计算所述多个文本中的任意两个文本之间的相似度。9.根据权利要求8所述的方法,对每个文本进行关键词提取处理包括:去除停用词或高频词,以及增加所获得的关键词的关联词或将所获得的关键词替换为关联词。10.一种对包含近似词语的多个文本进行分组的装置,包括:存储器,其上存储有指令;以及
处理器,被配置为执行存储在所述存储器上的指令,以执行以根据权利要求1至9中的任一项所述的方法。11.一种计算机可读存储介质,包括计算机可执行指令,所述计算机可执行指令在由一个或多个处理器执行时,使得所述一个或多个处理器执行根据权利要求1至9中的任意一项所述的方法。
技术总结
本公开涉及包含近似词语的文本的分组方法、装置及介质。提供了一种对包含近似词语的多个文本进行分组的方法,包括:对多个文本进行初始分组,包括:计算多个文本中的任意两个文本之间的相似度;将相似度大于第一相似度阈值的文本归类为一个初始分组,形成一个或多个初始分组;在存在多个初始分组的情况下,对多个初始分组进行第一层分组,包括:计算多个初始分组中的任意两个初始分组之间的相似度;对于每个初始分组,找到与该初始分组相似度最高的相似初始分组,如果该初始分组与相似初始分组之间的相似度大于第二相似度阈值,则将该初始分组与相似初始分组归类为一个第一层分组,形成一个或多个第一层分组。形成一个或多个第一层分组。形成一个或多个第一层分组。
技术研发人员:杨诗友
受保护的技术使用者:中国电信股份有限公司
技术研发日:2020.11.11
技术公布日:2022/5/16
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。