1.本发明涉及互联网领域,尤其涉及一种基于虚拟形象的联网合唱方法及终端。
背景技术:
2.现有技术中,为了提高用户体验,通常会在不同ktv包厢之间实现联网合唱。现有的异地联网合唱中,演唱者的互动或者是基于语音听觉上的,或者是基于视频直播的形式,但是,上述两种方式用户始终无法体验到接近真实包厢内双人合唱的互动感觉,体验效果较差。目前也有通过构建虚拟现实场景来提高用户的真实体验的方式,但是,这种方式用户只能跟构建出来的虚拟现实场景中的虚拟合唱对象进行合唱,依然无法体验到真实包厢内双人合唱的互动感觉。
技术实现要素:
3.本发明所要解决的技术问题是:提供一种基于虚拟形象的联网合唱方法及终端,在用户异地合唱时给与用户真实包厢的合唱体验。
4.为了解决上述技术问题,本发明采用的一种技术方案为:
5.一种基于虚拟形象的联网合唱方法,其特征在于,包括步骤:
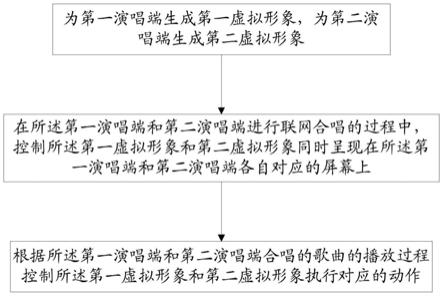
6.为第一演唱端生成第一虚拟形象,为第二演唱端生成第二虚拟形象;在所述第一演唱端和第二演唱端进行联网合唱的过程中,控制所述第一虚拟形象和第二虚拟形象同时呈现在所述第一演唱端和第二演唱端各自对应的屏幕上;
7.根据所述第一演唱端和第二演唱端合唱的歌曲的播放过程控制所述第一虚拟形象和第二虚拟形象执行对应的动作。
8.为了解决上述技术问题,本发明采用的另一种技术方案为:
9.一种基于虚拟形象的联网合唱终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种基于虚拟形象的联网合唱方法中的各个步骤。
10.本发明的有益效果在于:为进行联网合唱的第一演唱端和第二演唱端分别自动生成第一虚拟形象和第二虚拟形象,在联网合唱过程中,在合唱双方各自对应的屏幕上均能够呈现第一虚拟形象和第二虚拟形象,并且根据所述第一演唱端和第二演唱端合唱的歌曲的播放过程控制所述第一虚拟形象和第二虚拟形象执行对应的动作,能够让不同包厢用户连网合唱时具有接近真实包厢内合唱的互动感觉,增强用户的合唱体验。
附图说明
11.图1为本发明实施例的一种基于虚拟形象的联网合唱方法的步骤流程图;
12.图2为本发明实施例的一种基于虚拟形象的联网合唱终端的结构示意图;
13.图3为本发明实施例的两个虚拟形象联合摆开场pose的示意图;
14.图4为本发明实施例的两个虚拟形象对唱时的动作示意图;
15.图5为本发明实施例的两个虚拟形象合唱时的动作示意图。
具体实施方式
16.为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
17.请参照图1,一种基于虚拟形象的联网合唱方法,包括步骤:
18.为第一演唱端生成第一虚拟形象,为第二演唱端生成第二虚拟形象;
19.在所述第一演唱端和第二演唱端进行联网合唱的过程中,控制所述第一虚拟形象和第二虚拟形象同时呈现在所述第一演唱端和第二演唱端各自对应的屏幕上;
20.根据所述第一演唱端和第二演唱端合唱的歌曲的播放过程控制所述第一虚拟形象和第二虚拟形象执行对应的动作。
21.由上述描述可知,本发明的有益效果在于:为进行联网合唱的第一演唱端和第二演唱端分别自动生成第一虚拟形象和第二虚拟形象,在联网合唱过程中,在合唱双方各自对应的屏幕上均能够呈现第一虚拟形象和第二虚拟形象,并且根据所述第一演唱端和第二演唱端合唱的歌曲的播放过程控制所述第一虚拟形象和第二虚拟形象执行对应的动作,能够让不同包厢用户连网合唱时具有接近真实包厢内合唱的互动感觉,增强用户的合唱体验。
22.进一步的,在所述第一演唱端和第二演唱端进行联网合唱之前包括步骤:
23.根据所述第一虚拟形象匹配对应的第二虚拟形象:
24.根据所述第一演唱端的属性建立所述第一虚拟形象的标签,所述标签包括多个子标签,每个子标签对应所述第一演唱端的一个属性,每个子标签有对应的权值;
25.根据所述第一虚拟形象与待匹配的第二虚拟形象之间的各个子标签的相似度及各个子标签对应的权值匹配与所述第一虚拟形象对应的第二虚拟形象。
26.由上述描述可知,通过基于第一演唱端的属性为第一虚拟形象建立包含多个子标签的标签,基于不同虚拟形象之间的子标签的相似度及子标签对应的权值能够为第一演唱端找到与其相匹配的第二虚拟形象,保证了实现联网合唱的双方的匹配度。
27.进一步的,所述根据所述第一演唱端和第二演唱端合唱的歌曲的播放过程控制所述第一虚拟形象和第二虚拟形象执行对应的动作包括:
28.根据所述第一演唱端和第二演唱端合唱的歌曲的播放进度控制所述第一虚拟形象和第二虚拟形象执行对应的动作。
29.由上述描述可知,根据合唱的歌曲的播放进度实时的控制第一虚拟形象和第二虚拟形象执行对应的动作,能够让合唱双方的每一方全程与对方有实时的互动体验,与真实合唱的体验更为接近。
30.进一步的,根据所述第一演唱端和第二演唱端合唱的歌曲的播放进度控制所述第一虚拟形象和第二虚拟形象执行对应的动作包括:
31.当所述第一演唱端和第二演唱端合唱的歌曲开场时,控制所述第一虚拟形象和第二虚拟形象执行第一预设动作,所述第一预设动作由所述第一虚拟形象和第二虚拟形象配合完成;
32.当所述第一演唱端和第二演唱端合唱的歌曲处于演唱过程中时,控制所述第一虚
拟形象和第二虚拟形象执行第二预设动作,所述第二预设动作由所述第一虚拟形象和第二虚拟形象配合完成或独立完成;
33.当所述第一演唱端和第二演唱端合唱的歌曲处于副歌时,控制所述第一虚拟形象和第二虚拟形象执行第三预设动作,所述第三预设动作由所述第一虚拟形象和第二虚拟形象配合完成;
34.当所述第一演唱端和第二演唱端合唱的歌曲结束时,控制所述第一虚拟形象和第二虚拟形象执行第四预设动作,所述第四预设动作由所述第一虚拟形象和第二虚拟形象配合完成。
35.由上述描述可知,在双方合唱的歌曲的开场、处于演唱过程中、处于副歌以及歌曲结束时,均对应地控制第一虚拟形象和第二虚拟形象执行对应的动作,不同歌曲阶段所对应的虚拟形象执行的动作不同,并且有些动作是虚拟形象独自完成,有些动作需要合唱双方的虚拟形象配合完成,能够进一步提高合唱双方的参与感与互动性,进一步接近真实的合唱体验。
36.进一步的,所述控制所述第一虚拟形象和第二虚拟形象执行第二预设动作包括:
37.当所述第一演唱端和第二演唱端对唱时,突出处于唱歌状态的演唱端对应的虚拟形象,控制所述处于唱歌状态的演唱端对应的虚拟形象执行第五预设动作,并控制不处于唱歌状态的演唱端对应的虚拟形象执行第六预设动作;
38.所述第五预设动作根据所述处于唱歌状态演唱端对应的虚拟形象的性别、当前演唱的歌曲的评分、曲风以及节奏进行匹配;
39.所述第六预设动作根据所述不处于唱歌状态的演唱端对应的虚拟形象的性别、当前演唱的歌曲的曲风以及节奏进行匹配;
40.当匹配到多个动作时,则从多个动作中随机选择一个作为执行动作;
41.当所述第一演唱端和第二演唱端合唱时,控制所述第一虚拟形象和第二虚拟形象预设角度对视,并执行对唱动作。
42.由上述描述可知,当第一演唱端和第二演唱端对唱时,突出处于唱歌状态的演唱端对应的虚拟形象,并控制处于唱歌状态的演唱端和不处于唱歌状态的演唱端各自对应的虚拟形象,实现了虚拟形象的站位,同时当双方合唱时,则控制合唱双方对应的虚拟形象对视,并执行对唱动作,进一步增强演唱双方的合作感知。
43.进一步的,还包括步骤:
44.当演唱端处于唱歌状态时,根据所述演唱端演唱的歌词控制其对应的虚拟形象执行与所述歌词匹配的舞蹈动作,所述演唱端包括第一演唱端和第二演唱端。
45.由上述描述可知,当演唱端处于唱歌状态时,能够进一步根据演唱端演唱的歌词控制对应的虚拟形象执行与歌词匹配的舞蹈动作,使得虚拟形象的动作与歌曲融合度更高,让用户更有身临其境的感觉。
46.进一步的,还包括步骤:
47.在所述第一演唱端和第二演唱端进行联网合唱的过程中,实时确定所述第一演唱端和第二演唱端唱歌的默契指数并进行显示。
48.由上述描述可知,在联网合唱过程中,实时对合唱双方的默契指数进行确定并显示,能够让合唱双方实时获知与对方的默契,进一步增强演唱双方的合作感知,更贴近于现
实的合唱体验。
49.进一步的,所述确定所述第一演唱端和第二演唱端唱歌的默契指数包括:
50.确定所述第一演唱端所有已演唱句子的第一平均得分;
51.确定所述第二演唱端所有已演唱句子的第二平均得分;
52.根据所述第一演唱端的性别、第二演唱端的性别、所述第一平均得分和第二平均得分确定所述第一演唱端和第二演唱端的默契指数。
53.由上述描述可知,根据合唱双方的性别以及各自的平均演唱得分能够准确客观地确定出合唱双方的默契指数。
54.进一步的,还包括:
55.当所述第一演唱端和第二演唱端合唱的歌曲结束时,确定并显示所述第一演唱端和第二演唱端合唱的成绩单;
56.根据所述成绩单控制所述第一虚拟形象和第二虚拟形象执行第七预设动作,所述第七预设动作由所述第一虚拟形象和第二虚拟形象配合完成。
57.由上述描述可知,当歌曲合唱结束时,对双方合唱的成绩进行计算并显示,同时基于合唱成绩控制双方对应的虚拟形象执行对应的相互配合完成的动作,不仅能够让合唱双方直观地获知二者的合唱成果,而且能够对合唱双方起到激励作用。
58.请参照图2,一种基于虚拟形象的联网合唱终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种基于虚拟形象的联网合唱方法中的各个步骤。
59.上述基于虚拟形象的联网合唱方法及终端能够适用于任何需要实现异地联网合唱的场景,比如,在ktv场景中,处于不同包厢的演唱端之间的联网合唱;或者处于不同移动端处的用户之间的联网合唱等,以下通过具体的实施方式进行说明书:
60.实施例一
61.本实施例应用于在ktv包厢中实现的联网合唱中,请参照图1,一种基于虚拟形象的联网合唱方法,包括步骤:
62.为第一演唱端自动生成第一虚拟形象,为第二演唱端自动生成第二虚拟形象;
63.在所述第一演唱端和第二演唱端进行联网合唱之前包括步骤:
64.根据所述第一虚拟形象匹配对应的第二虚拟形象:
65.根据所述第一演唱端的属性建立所述第一虚拟形象的标签,所述标签包括多个子标签,每个子标签对应所述第一演唱端的一个属性,每个子标签有对应的权值;
66.根据所述第一虚拟形象与待匹配的第二虚拟形象之间的各个子标签的相似度及各个子标签对应的权值匹配与所述第一虚拟形象对应的第二虚拟形象;
67.即用户在ktv包厢后,当连接上演唱设备要进行唱歌时,系统会为用户自动生成对应的虚拟形象,在建立与用户对应的虚拟形象时,会根据用户的属性建立其对应的虚拟形象的标签,每一个虚拟形象的标签包括多个子标签,每个子标签对应用户的一个属性,比如用户有地理位置、性别、歌曲喜好、歌曲等级等属性,则其对应的虚拟形象具有地理位置、性别、歌曲喜好、歌曲等级等子标签,每个子标签具有对应的匹配权值,比如性别:30%,地理位置:40%,歌曲喜好:20%,歌手等级:10%,每个虚拟形象的子标签以及对应的权值可以进行动态设置,在给用户建立虚拟形象,并设置虚拟形象的子标签及对应的权值后,系统会
将每一个用户对应的虚拟形象上传至云端;
68.则在用户要寻找合唱对象时,可以从云端获取可选择的虚拟形象,构成虚拟形象集合,然后一一比对用户对应的第一虚拟形象与获取到的虚拟形象集合中的每一个虚拟形象进行子标签相似度的计算,再乘以对应的子标签权值,得到两个虚拟形象之间的相似度,基于相似度来匹配与用户最合适的用户进行连麦合唱,比如要进行相似度计算的第一虚拟形象和第二虚拟形象各个子标签地理位置、性别、歌曲喜好、歌曲等级的值分别为a1、a2、a3、a4以及b1、b2、b3、b4,则分别一一比对a1与b1、a2与b2、a3与b3以及a4与b4之间的相似度,如果进行比对的子标签越接近,则子标签对应的相似度值越大,可以根据需要基于两个子标签之间的相似性进行数值的转化,假设四个子标签一一比对后得到的相似度值分别为c1、c2、c3、c4,则最终计算得到的两个虚拟形象之间的相似度s=c1*40% c2*30% c3*20% c4*10%;
69.在将从云端获取的虚拟形象集合中的每一个虚拟形象均与用户对应的第一虚拟形象计算得到相似度后,选择相似度最大的作为与第一虚拟形象匹配的第二虚拟形象,第二虚拟形象对应第二演唱端;
70.在所述第一演唱端和第二演唱端进行联网合唱的过程中,控制所述第一虚拟形象和第二虚拟形象同时呈现在所述第一演唱端和第二演唱端各自对应的屏幕上;
71.虽然第一演唱端和第二演唱端异地,但是通过在各自演唱对应的显示屏上同时显示两个演唱端各自对应的第一虚拟形象和第二虚拟形象,则两个演唱端能够在屏幕上看到两个虚拟形象对唱的情景;
72.根据所述第一演唱端和第二演唱端合唱的歌曲的播放过程控制所述第一虚拟形象和第二虚拟形象执行对应的动作。
73.实施例二
74.本实施例与实施例一的不同在于,进一步限定了如何根据所述第一演唱端和第二演唱端合唱的歌曲的播放过程控制所述第一虚拟形象和第二虚拟形象执行对应的动作,包括:
75.根据所述第一演唱端和第二演唱端合唱的歌曲的播放进度控制所述第一虚拟形象和第二虚拟形象执行对应的动作;
76.具体的,当所述第一演唱端和第二演唱端合唱的歌曲开场时,控制所述第一虚拟形象和第二虚拟形象执行第一预设动作,所述第一预设动作由所述第一虚拟形象和第二虚拟形象配合完成;
77.如图3所示,第一虚拟形象和第二虚拟形象可以配合摆出预设的姿势pose;
78.当所述第一演唱端和第二演唱端合唱的歌曲处于演唱过程中时,控制所述第一虚拟形象和第二虚拟形象执行第二预设动作,所述第二预设动作由所述第一虚拟形象和第二虚拟形象配合完成或独立完成;
79.具体的,当所述第一演唱端和第二演唱端对唱时,突出处于唱歌状态的演唱端对应的虚拟形象,控制所述处于唱歌状态的演唱端对应的虚拟形象执行第五预设动作,并控制不处于唱歌状态的演唱端对应的虚拟形象执行第六预设动作,比如,让处于唱歌状态的演唱端对应的虚拟形象往前站,演唱前拿起麦克风,然后拿着麦克风开始唱歌,并执行对应的动作,具体的,可以根据所述处于唱歌状态演唱端对应的虚拟形象的性别、当前演唱的歌
曲的评分、曲风以及节奏进行匹配;可以让不处于唱歌状态的演唱端对于的虚拟形象往后站,放下麦克风,做鼓掌、踱步或招手等动作,具体执行的动作可以根据所述不处于唱歌状态的演唱端对应的虚拟形象的性别、当前演唱的歌曲的曲风以及节奏进行匹配,具体的如图4所示,此时还可以对各个演唱端对应的歌词进行突出以及区分显示,从而让演唱端感知哪段歌词应该由哪一端进行演唱;
80.当匹配到多个动作时,则从多个动作中随机选择一个作为执行动作;
81.当所述第一演唱端和第二演唱端合唱时,控制所述第一虚拟形象和第二虚拟形象按预设角度对视,并执行对唱动作,比如,两个虚拟形象拿起麦克风,45度对视,并执行对唱动作,类似图5所示,从而营造出实际对唱的场景;
82.当所述第一演唱端和第二演唱端合唱的歌曲处于副歌时,控制所述第一虚拟形象和第二虚拟形象执行第三预设动作,所述第三预设动作由所述第一虚拟形象和第二虚拟形象配合完成,比如两个虚拟形象做牵手或者配合跳舞等互动动作;
83.当所述第一演唱端和第二演唱端合唱的歌曲结束时,控制所述第一虚拟形象和第二虚拟形象执行第四预设动作,所述第四预设动作由所述第一虚拟形象和第二虚拟形象配合完成,比如两个虚拟形象手牵手完成谢幕动作;
84.在另一个可选的实施方式中,当演唱端处于唱歌状态时,根据所述演唱端演唱的歌词控制其对应的虚拟形象执行与所述歌词匹配的舞蹈动作,所述演唱端包括第一演唱端和第二演唱端,比如,当演唱到比较抒情的歌词时,则虚拟形象对应执行比较舒缓的舞蹈动作,当演唱到振奋人心的歌词时,则虚拟形象对应执行幅度比较大的、比较律动的舞蹈动作;
85.当所述第一演唱端和第二演唱端合唱的歌曲结束时,确定并显示所述第一演唱端和第二演唱端合唱的成绩单;
86.根据所述成绩单控制所述第一虚拟形象和第二虚拟形象执行第七预设动作,所述第七预设动作由所述第一虚拟形象和第二虚拟形象配合完成,比如如果二者合唱成绩很高,则第一虚拟形象和第二虚拟形象可以配合作出点赞的动作,如果二者合唱成绩较低,则第一虚拟形象和第二虚拟形象可以配合作出鼓励的动作;
87.每歌唱完一首歌,根据成绩单对应更新对于的演唱端的歌唱等级,并将成绩单及歌唱等级保存到云端。
88.实施例三
89.本实施例与实施例一或实施例二的不同在于:
90.在所述第一演唱端和第二演唱端进行联网合唱的过程中,实时确定所述第一演唱端和第二演唱端唱歌的默契指数并进行显示;
91.当双方默契指数大于预设值时,则会添加特效以进一步鼓舞进行合唱的双方;
92.具体的,确定所述第一演唱端所有已演唱句子的第一平均得分;
93.确定所述第二演唱端所有已演唱句子的第二平均得分;
94.根据所述第一演唱端的性别、第二演唱端的性别、所述第一平均得分和第二平均得分确定所述第一演唱端和第二演唱端的默契指数;
95.比如,对于合唱双方,定义为m、n;
96.m的已演唱句子的第一平均得分为:sm;
97.n的已演唱句子的第二平均得分为:sn;
98.基准默契指数得分=100-abs(sm-sn);
99.最终算得的默契指数如表1所示:
100.表1
101.ab配对默契指数得分范围默契指数计算公式男-女70-100100-abs(sa-sb)女-女50-100100-abs(sa-sb)x1.5男-男30-100100-abs(sa-sb)x2.5
102.实施例四
103.请参照图2,一种基于虚拟形象的联网合唱终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述实施例一至实施例三中任一个所示的一种基于虚拟形象的联网合唱方法中的各个步骤。
104.综上所述,本发明提供的一种基于虚拟形象的联网合唱方法及终端,为进行联网合唱的第一演唱端和第二演唱端分别自动生成第一虚拟形象和第二虚拟形象,在联网合唱过程中,在合唱双方各自对应的屏幕上均能够呈现第一虚拟形象和第二虚拟形象,并且根据所述第一演唱端和第二演唱端合唱的歌曲的整个播放过程,包括开场、合唱、对唱、副歌以及结束,控制所述第一虚拟形象和第二虚拟形象执行对应的动作,除了基于歌曲的歌唱进度控制虚拟形象的执行动作外,还能够基于演唱端演唱的歌词个性化的控制对于的虚拟形象的执行动作,同时还能够实时计算合唱双方的默契指数,基于默契指数控制两个虚拟形象执行对应的动作,让合唱双方在演唱的整个过程均有参与感以及合作认知,能够让不同包厢用户连网合唱时具有接近真实包厢内合唱的互动感觉,增强用户的合唱体验。
105.以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。