1.本发明涉及元宇宙领域,尤其涉及元宇宙空间服务器的数据存储、索引、查询方法及系统。
背景技术:
2.元宇宙中虚拟人物在场景中活动,会产生轨迹,回访时会调用轨迹数据。大型的元宇宙的场景空间都是各方独立开发,然后再拼接,那么一个巨型场景空间其实是由多个空间服务器共同运行支撑的。这就会涉及到一个虚拟人物会在不同的空间服务器中的留下大量轨迹,如何在不同的服务器中一致性的存储虚拟人物的轨迹,使得存储的轨迹便于查询,并节约存储空间这是元宇宙中分布式计算目前需要解决的问题。
技术实现要素:
3.本发明提供了元宇宙空间服务器的数据存储方法、索引方法及查询方法,用于解决现有的元宇宙空间服务器存储方法占用存储空间大,且不便于索引、查询的技术问题。
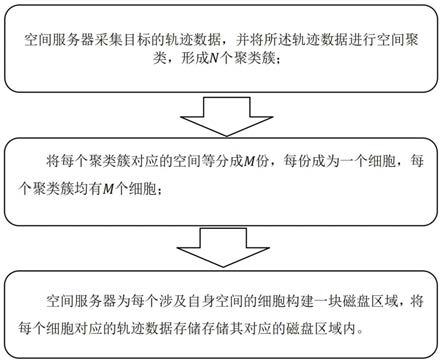
4.为解决上述技术问题,本发明提出的技术方案为:一种元宇宙空间服务器的数据存储方法,包括以下步骤:空间服务器采集目标的轨迹数据,并将所述轨迹数据进行空间聚类,形成个聚类簇;将每个聚类簇对应的空间等分成份,每份成为一个细胞,每个聚类簇均有个细胞;空间服务器为每个涉及自身空间的细胞构建一块磁盘区域,将每个细胞对应的轨迹数据存储其对应的磁盘区域内。
5.优选的,还包括以下步骤:当空间服务器采集到目标新的轨迹数据时,查询新的轨迹数据所对应的细胞,并将新的轨迹数据存储到其对应细胞的磁盘区域内;空间服务器实时统计每个细胞内的轨迹数据量,将每个细胞内的轨迹数据量与其对应的标定阈值y进行比较,当存在任一细胞a内的轨迹数据量超过标定阈值y时,将所述细胞a分裂成两个新细胞,并分别为两个新细胞构建磁盘区域,将两个新细胞对应的轨迹数据存储至其对应的磁盘区域内。
6.优选的,还包括以下步骤:空间服务器实时统计其对应空间下的轨迹数据量,并将所述轨迹数据量与其对应的阈值w进行比较,当所述轨迹数据量大于所述阈值w时,空间服务器将其内的轨迹数据量重新进行空间聚类,并将重新空间聚类后得到的聚类簇对应的空间重新划分细胞,并分别为重新划分的细胞重新构建磁盘区域,将每个重新划分的细胞对应的轨迹数据存储其对应的磁盘区域内。
7.优选的,将所述轨迹数据进行空间聚类通过dbscan聚类算法实现。
8.优选的,每个空间服务器采集的轨迹数据,为其空间坐标系下的轨迹数据;将所述轨迹数据进行空间聚类前,还包括以下步骤:将所述元宇宙的多个空间服务器对应的空间拼接成一个完整空间,构建所述完整空间的坐标系,并定位所述完整空间的坐标系原点;根据所述完整空间的坐标系原点及每个空间服务器的坐标系原点之间的关系,将每个空间服务器采集的轨迹数据的坐标转换至所述完整空间的坐标系下。
9.优选的,所述完整空间的坐标系原点为完整空间的中心点,根据所述完整空间的坐标系原点及每个空间服务器的坐标系原点之间的关系,将每个空间服务器采集的轨迹数据的坐标转换至所述完整空间的坐标系下,包括以下步骤:根据完整空间的坐标系原点,计算每个空间服务器的坐标系原点在所述完整空间的换算坐标;将每个空间服务器采集的轨迹数据加上与其对应的换算坐标,得到每个空间服务器采集的轨迹数据在所述完整空间坐标系下的坐标。
10.一种元宇宙空间服务器的数据索引方法,所述空间服务器中存储的每条轨迹数据表示为,其中,代表该目标的唯一标识,代表目标在时刻的空间坐标;所述数据索引方法,包括以下步骤:采用包围盒算法将空间服务器中的每个细胞及其轨迹数据进行包围,形成每个细胞的包围盒;利用r树空间索引对所有的包围盒进行索引,r树的叶节点包含包围盒,每个包围盒具体包含了目标的轨迹数据;构建轨迹数据的倒排索引if,if的根节点是目标的id号,id号接下来的节点就是包含该id的所有r树叶节点,并且叶节点按照该id的轨迹时间进行排序。
11.优选的,所述包围盒算法为最小包围立方体算法。
12.一种元宇宙空间服务器的数据查询方法,包括以下步骤:设查询条件,代表查询的空间立方体,代表开始时间和结束时间,代表目标的标识,查询条件意思为在时间段内,在空间内,查询目标的轨迹点。
13.s1:将作为查询条件检索构建好的r树,获得结果叶节点集合ls;s2:将ls中的叶节点与倒排索引if中以为根的所有的叶节点做交集,得到结果集lsr;s3:将lsr中的每个包围盒的时间与求交,结果为空的包围盒丢弃;s4:将剩余的包围盒中按照时间顺序取出的轨迹点,即为查询结果。
14.一种计算机系统,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
15.本发明具有以下有益效果:1、本发明中的元宇宙空间服务器的数据存储方法及系统,利用空间聚类对目标(如虚拟人物)轨迹数据(即轨迹点)进行存储,利用空间上的相近性实现了存储空间的节约,并且对下一步的索引构建提供了良好的设计基础,此外,本发明中的数据索引、查询方法及系统,针对轨迹的索引,结合r树和倒排索引,利用r树对空间点的索引能力和利用倒排索引对虚拟人物标识的索引,将两者很好的结合起来。在查询时首先利用r树检索到候选结果集,然后利用倒排索引精筛,实现了快速的查询效果。
16.2、在优选方案中,本发明对各个空间服务器中的轨迹数据进行归一化后在进行存储,能进一步提高查询效率,此外,本发明在元宇宙多场景拼接实现中的对虚拟人物轨迹进行处理,能为多场景空间服务器共同提供场景奠定了技术基础。此外,本发明设计了多场景服务器虚拟人物轨迹的模型,该模型阐述了虚拟人物在多场景空间的运动本质。
17.除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照附图,对本发明作进一步详细的说明。
附图说明
18.构成本技术的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:图1是本发明中的分布式多场景空间服务器轨迹模型;图2是本发明的元宇宙空间服务器的数据存储方法。
具体实施方式
19.以下结合附图对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。
20.实施例一:如图2所示,本实施中公开了一种元宇宙空间服务器的数据存储方法,包括以下步骤:空间服务器采集目标的轨迹数据,并将所述轨迹数据进行空间聚类,形成个聚类簇;将每个聚类簇对应的空间等分成份,每份成为一个细胞,每个聚类簇均有个细胞;空间服务器为每个涉及自身空间的细胞构建一块磁盘区域,将每个细胞对应的轨迹数据存储其对应的磁盘区域内。
21.此外,在本实施例中,还公开了一种元宇宙空间服务器的数据索引方法,所述空间服务器中存储的每条轨迹数据表示为,其中,代表该目标的唯一标识,代表目标在时刻的空间坐标;所述数据索引方法,包括以下步骤:采用包围盒算法将空间服务器中的每个细胞及其轨迹数据进行包围,形成每个细胞的包围盒;
利用r树空间索引对所有的包围盒进行索引,r树的叶节点包含包围盒,每个包围盒具体包含了目标的轨迹数据;构建轨迹数据的倒排索引if,if的根节点是目标的id号,id号接下来的节点就是包含该id的所有r树叶节点,并且叶节点按照该id的轨迹时间进行排序。
22.此外,在本实施例中,还公开了一种元宇宙空间服务器的数据查询方法,包括以下步骤:设查询条件,代表查询的空间立方体,代表开始时间和结束时间,代表目标的标识,查询条件意思为在时间段内,在空间内,查询目标的轨迹点。
23.s1:将作为查询条件检索构建好的r树,获得结果叶节点集合ls;s2:将ls中的叶节点与倒排索引if中以为根的所有的叶节点做交集,得到结果集lsr;s3:将lsr中的每个包围盒的时间与求交,结果为空的包围盒丢弃;s4:将剩余的包围盒中按照时间顺序取出的轨迹点,即为查询结果。
24.此外,在本实施例中,还公开了一种计算机系统,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
25.本发明中的元宇宙空间服务器的数据存储方法及系统,利用空间聚类对目标轨迹数据(即虚拟人物的轨迹点)进行存储,利用空间上的相近性实现了存储空间的节约,并且对下一步的索引构建提供了良好的设计基础,此外,本发明中的数据索引、查询方法及系统,针对轨迹的索引,结合r树和倒排索引,利用r树对空间点的索引能力和利用倒排索引对虚拟人物标识的索引,将两者很好的结合起来。在查询时首先利用r树检索到候选结果集,然后利用倒排索引精筛,实现了快速的查询效果。
26.实施例二:实施例二是实施例一的优选实施例,其与实施例一的不同之处,对元宇宙空间服务器的数据存储方法、索引方法及查询方法的具体步骤进行了介绍,具体包括以下步骤:本实施例中,目标为虚拟人物,采集的目标轨迹数据为虚拟人物的轨迹点,即本发明主要面向元宇宙中跨不同场景空间服务器存储和索引大量虚拟人物的轨迹。
27.第一,如何跨场景空间服务器存储虚拟人物的轨迹;第二,如何跨场景空间服务器索引虚拟人物的轨迹;第三,如何通过索引查询虚拟人物轨迹;如图1所示,用户在戴着vr/ar眼镜以虚拟人物在元宇宙场景中漫游时,在每个场景都会留下轨迹,虚拟人物从一个场景空间进入另一个空间服务器s的场景空间后,空间服务器s会检测到该虚拟人物对应的vr/ar眼镜,因此该虚拟人物在新的场景空间里的轨迹由对应的空间服务器s进行存储。那么针对某位虚拟人物u,u的轨迹会跨多个空间服务器进行存储。
28.一、数据存储:设每个服务器的场景空间为三维空间,当服务器与用户的vr/ar眼镜进行通信时就表明该用户在元宇宙的虚拟人物就进入了该服务器所对应的场景空间。虚拟人物在场景空间中位置定时由服务器探测并采集,形式为,其中代表该虚拟人物的唯一标识,代表虚拟人物在时刻的空间坐标,并且是相对于该服务器的空间场景而言的。
29.1、归一化:由于不同的空间服务器采集的轨迹点的坐标系不同,每个场景空间服务器都使用了自己的空间坐标原点,这样的话,即使相同的所代表的空间坐标也是不同的,为了在不同的服务器中一致性的存储虚拟人物的轨迹,需存储轨迹点之前,需要对不同空间服务器采集的轨迹点进行归一化,其中,归一化方法如下:s11:按照空间逻辑将各个服务器提供的场景空间进行拼接形成该元宇宙完整的空间场景;s12:将整个完整空间的中心点设为原点,即;s13:根据整个空间的原点,计算每个服务器场景空间的原始原点在新的完整空间下的坐标;s14:将每个原始空间位置与相应的相加,即,所得即为在整个完整空间的坐标。
30.2、基于聚类的存储方法在本实施例中,轨迹的存储方法采用基于聚类的存储方法,该方法具体为:设每个空间服务器都采集到了虚拟人物的轨迹信息,每个轨迹点表示为,其中是归一化的坐标。
31.s21:预先假设聚类数量为,对当前现有的轨迹点进行dbscan聚类操作,形成个聚类;s22:针对每个聚类,将每个聚类的空间等分为份,即总共有份,每份成为一个细胞;s23:场景空间服务器针对涉及自身的细胞,为每个细胞构建一块磁盘区域,并将细胞中的存入;s24:针对跨场景空间服务器的细胞,如细胞a跨服务器s和r,那么s和r分别各存储一份a;s25:当某服务器t新采集到虚拟人物的轨迹点l后,t判断l所在的细胞,并将l存储入对应的细胞中;
s26:当一个细胞中的轨迹点数量超过阈值y,细胞发生分裂,变为2个细胞;s27:当整个空间的轨迹点超过阈值w,重新进行dbscan聚类操作,聚类完成后继续s22。
32.3、基于倒排和r树的虚拟人物轨迹索引s31:针对“(1)基于聚类的存储方法”中所产生的细胞,利用最小包围立方体mbb(minimum bounding box)将每个细胞进行包围,形成包围盒cmbb;s32:利用r树空间索引对所有的包围盒cmbb进行索引,r树的叶节点包含包围盒cmbb,每个包围盒cmbb具体包含了虚拟人物的轨迹点;s33:构建倒排索引if,if的根节点是虚拟人物的id号,id号接下来的节点就是包含该id的所有r树叶节点,并且叶节点按照该id的轨迹时间进行排序。
33.4、基于虚拟人物轨迹索引的查询算法设查询条件,代表查询的空间立方体,代表开始时间和结束时间,代表虚拟人物的标识,查询条件意思为在时间段内,在空间内,查询虚拟人物的轨迹点。
34.s41:将作为查询条件检索构建好的r树,获得结果叶节点集合ls;s42:将ls中的叶节点与倒排索引if中以为根的所有的叶节点做交集,得到结果集lsr;s43:将lsr中的每个包围盒cmbb的时间与求交,结果为空的包围盒cmbb丢弃;s44:将剩余的包围盒cmbb中按照时间顺序取出的轨迹点,即为查询结果。
35.本发明具有以下优点:(1)本发明是元宇宙多场景拼接实现中的对虚拟人物轨迹处理的发明,为多场景空间服务器共同提供场景奠定了技术基础。
36.(2)设计了多场景服务器虚拟人物轨迹的模型,该模型阐述了虚拟人物在多场景空间的运动本质。
37.(3)本发明设计了利用聚类对虚拟人物轨迹点进行存储,利用空间上的相近性实现了存储空间的节约,并且对下一步的索引构建提供了良好的设计基础。
38.(4)本发明设计了针对轨迹的索引,结合r树和倒排索引,利用r树对空间点的索引能力和利用倒排索引对虚拟人物标识的索引,将两者很好的结合起来。在查询时首先利用r树检索到候选结果集,然后利用倒排索引精筛,实现了快速的查询效果。
39.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。