1.本发明属于智能优化领域,特别涉及一种基于强化学习和粒子群算法的智能寻优方法。
背景技术:
2.现实世界的优化问题常具有搜索空间不连续(存在离散形变量)、优化目标非凸(即存在多个局部极值点)、问题求解空间高维复杂等特点,采用梯度优化的方式面临建模困难、易陷入局部极值等问题,目前常采用智能寻优方法求解,能够在有限时间内给出尽可能优化的方案,且易于实现并行处理以提升效率。
3.智能寻优方法通常采用贪婪的策略,在当前解的基础上进行一定的变化,若变化后的新解更好,则逐步淘汰旧的解,如此循环迭代直到算法收敛。此类方法可采用群体优化的方式,同时对一群解进行变化和淘汰,从而实现求解过程的并行化处理,提升求解效率,但是随着算法优化进度的变化,算法中固定设置的参数往往导致算法优化过程陷入局部最优、或者算法优化步长太小速度过低,导致优化效果不佳。因此,有必要研究一种使算法参数随着优化过程而自适应调整,而不是采用固定的数值,从而实现粒子群算法优化过程中全局最优与求解速度的动态平衡,提升寻优优化效果。
技术实现要素:
4.针对上述技术问题,本发明提供一种基于强化学习和粒子群算法的智能体寻优方法,实现粒子群算法优化过程中全局最优与求解速度的动态平衡,提升了算法的快速性。
5.为了实现上述目的,本发明采用如下技术方案:一种基于强化学习和粒子群算法的智能寻优方法,利用强化学习优化粒子群算法参数,通过强化学习的输入、输出和优化目标设计,自适应调整粒子群算法参数;所述输入、所述输出和所述优化目标的设计思路为:所述输入,即状态,以粒子群算法的优化进度表征;所述输出,即动作,以粒子群算法速度更新公式参数表征,所述速度更新公式参数包括局部极值权重、全局极值权重和惯性因子;所述优化目标,即回报,以当前粒子的适应度函数值作为正回报,当前迭代次数作为负回报。
6.进一步地,所述状态的表达式为:其中,为当前迭代步数,为当前粒子最优适应度,为当前平均适应度,为当前全局适应度方差。
7.进一步地,所述动作的表达式为:
其中,分别为局部极值权重、全局极值权重和惯性因子。
8.进一步地,所述回报的表达式为:其中,为粒子当前适应度即正回报,为经调节的负回报,为调节因子。
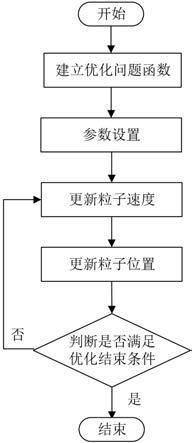
9.优选地,包括以下步骤:s1:建立优化问题函数设待优化变量个数为,建立粒子的位置向量,其中表示第个待优化变量,其定义域范围为,所述位置向量对应优化问题的解;根据优化问题设计适应度函数,其函数值越大对应所述优化问题的解越好;s2:参数设置根据待优化变量和待优化变量速度的定义域范围,按照均匀分布随机生成个粒子的初始位置和初始速度,此时令迭代次数;其中,所述待优化变量速度为待优化变量的调整算子,用表示的速度,其定义域为;s3:更新粒子速度s31:利用强化学习算法计算速度更新公式参数结合粒子群算法特点,分别设计强化学习算法的状态、动作、回报如下:(1)状态:包含描述粒子群算法进度的信息,具体设计为:(2)动作:包含粒子群算法速度更新公式参数,具体设计为:(3)回报:以当前粒子的适应度函数值作为正回报,当前迭代次数作为负回报,具体设计为:以状态为输入,通过正向计算和反向计算相结合,得到速度更新公式参数;s32:根据强化学习算法的输出更新粒子速度根据速度更新公式,遍历个粒子和每个粒子的个维度,得到每个粒子的个维度的速度值;s4:更新粒子位置根据位置更新公式,遍历个粒子和每个粒子的个维度,得到每个粒子的个维度的位置;s5:判断是否满足优化结束条件计算整个粒子群所经历的最好位置的适应度函数值,其中是全局极值,是满足时粒子的位置;若迭代次数达到上限或已经得到最优结果,则结束迭代,并将作为最优结果,否则返回s3进行下一轮迭代。
10.进一步地,其特征在于,s32中,所述速度更新公式为:其中,,为随机数,范围为,符合均匀分布;表示第个粒子在第次迭代时的;为第个粒子在第次迭代时的;为局部极值,是的第个待优化量,为第个粒子在满足时的位置;为全局极值的第个待优化量。
11.进一步地,s4中,所述位置更新公式为:其中,表示第次迭代时第个粒子的。
12.进一步地,所述强化学习算法为深度确定性策略梯度算法。
13.本发明的有益效果:本发明将粒子群算法参数设置等效为序列决策问题,在粒子群算法寻优过程中利用强化学习方法动态调整粒子群速度迭代公式的参数,实现了迭代步长的自适应调整,解决了粒子群算法中速度更新公式参数设定主观性强的问题,避免了因为参数设置不当导致的算法不收敛及迭代次数多的问题,实现粒子群算法优化过程中全局最优与求解速度的动态平衡,提升了算法的快速性。本方法具有良好的扩展性,除了粒子群算法外,还可应用到其他优化算法的参数自适应调整过程中。
附图说明
14.图1为本方法的流程图;图2为强化学习算法输入输出示意图。
具体实施方式
15.下面结合附图和具体实施例对本发明的技术方案作进一步具体的说明。
16.一种基于强化学习和粒子群算法的智能寻优方法,利用强化学习优化粒子群算法参数,通过强化学习的输入、输出和优化目标设计,自适应调整粒子群算法参数;所述输入、所述输出和所述优化目标的设计思路为:所述输入,即状态,以粒子群算法的优化进度表征;所述状态的表达式为:
其中,为当前迭代步数,为当前粒子最优适应度,为当前平均适应度,为当前全局适应度方差。
17.所述输出,即动作,以粒子群算法速度更新公式参数表征,所述速度更新公式参数包括局部极值权重、全局极值权重和惯性因子;所述动作的表达式为:其中,分别为局部极值权重、全局极值权重和惯性因子。
18.所述优化目标,即回报,以当前粒子的适应度函数值作为正回报,当前迭代次数作为负回报。
19.所述回报的表达式为:其中,为粒子当前适应度即正回报,为经调节的负回报,为调节因子。
20.具体包括以下步骤:s1:建立优化问题函数设待优化变量个数为,建立粒子的位置向量,其中表示第个待优化变量,其定义域范围为,所述位置向量对应优化问题的解;根据优化问题设计适应度函数,其函数值越大对应所述优化问题的解越好;s2:参数设置根据待优化变量和待优化变量速度的定义域范围,按照均匀分布随机生成个粒子的初始位置和初始速度,此时令迭代次数;其中,所述待优化变量速度为待优化变量的调整算子,用表示的速度,其定义域为;设置调节因子初始值;s3:更新粒子速度s31:利用强化学习算法计算速度更新公式参数结合粒子群算法特点,分别设计强化学习算法的状态、动作、回报如下:(1)状态:包含描述粒子群算法进度的信息,具体设计为:(2)动作:包含粒子群算法速度更新公式参数,具体设计为:(3)回报:以当前粒子的适应度函数值作为正回报,当前迭代次数作为负回报,具体设计为:以状态为输入,通过正向计算和反向计算相结合,得到速度更新公式参数;所述强
化学习算法为深度确定性策略梯度算法。
21.s32:根据强化学习算法的输出更新粒子速度根据速度更新公式,遍历个粒子和每个粒子的个维度,得到每个粒子的个维度的速度值;s32中,所述速度更新公式为:其中,,为随机数,范围为,符合均匀分布;表示第个粒子在第次迭代时的;为第个粒子在第次迭代时的;为局部极值,是的第个待优化量,为第个粒子在满足时的位置;为全局极值的第个待优化量。
22.s4:更新粒子位置根据位置更新公式,遍历个粒子和每个粒子的个维度,得到每个粒子的个维度的位置;s4中,所述位置更新公式为:其中,表示第次迭代时第个粒子的。
23.s5:判断是否满足优化结束条件计算整个粒子群所经历的最好位置的适应度函数值,其中是全局极值,是满足时粒子的位置;若迭代次数达到上限或已经得到最优结果,则结束迭代,并将作为最优结果,否则返回s3进行下一轮迭代。
24.以上关于本发明的具体描述,仅用于说明本发明而非受限于本发明实施例所描述的技术方案,本领域的普通技术人员应当理解,仍然可以对本发明进行修改或等同替换,以达到相同的技术效果;只要满足使用需要,都在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
