1.本发明实施例涉及电话语音交互技术,尤其涉及一种电话语音交互方法、装置、设备及存储介质。
背景技术:
2.随着人工智能、智能电话机器人等技术的发展,越来越多的销售、客户服务通过智能电话机器人去实现营销电话的拨出和接听客服电话,有效的提高了电话营销和服务客户的工作效率。
3.而现有的智能电话机器人的运行逻辑相对简单,基于语音识别技术在通话者说话一段话之后对采集到的语音进行识别,识别出语音文本,然后基于语音文本进行话术语音匹配,最后将匹配到的语音进行播放。在对通话者的语音进行识别的过程中,往往是等待通话者说完一段话后才进行语音识别匹配话术语音并播放,使得对通话者的答复间隔相对较长,给通话者的感觉是系统响应迟钝,对于通话者的话语回复较慢。并且在通话的过程中,对于通话者的打断行为、长时间不说话等行为不能够准确的识别,使得智能电话机器人的响应木讷,显得不够灵活。
技术实现要素:
4.本发明提供一种电话语音交互方法、装置、设备及存储介质,以实现更及时的对通话者的话语回应。
5.第一方面,本发明实施例提供了一种电话语音交互方法,包括:
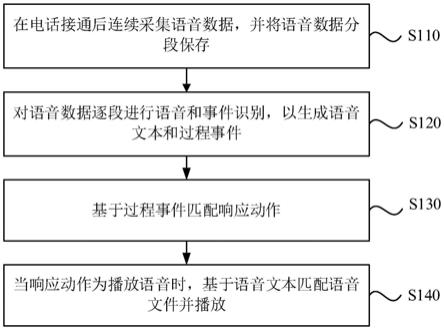
6.在电话接通后连续采集语音数据,并将所述语音数据分段保存;
7.对所述语音数据逐段进行语音和事件识别,以生成语音文本和过程事件;
8.基于所述过程事件匹配响应动作;
9.当所述响应动作为播放语音时,基于所述语音文本匹配语音文件并播放。
10.可选的,所述语音数据包括至少一段;
11.所述在电话接通后连续采集语音数据,包括:
12.在电话拨通后连续采集所述电话的通话数据;
13.间隔预设的时间长度将采集到的所述通话数据作为一段语音数据进行存储。
14.可选的,所述对所述语音数据进行语音和事件识别,以生成语音文本和过程事件,包括:
15.对所述语音数据进行人声识别,生成开始说话事件和结束说话事件;
16.基于所述开始说话事件和所述结束说话事件对所述语音数据进行语音识别,获得语音文本。
17.可选的,所述对所述语音数据进行人声识别,生成开始说话事件和结束说话事件,包括:
18.识别当前的所述语音数据是否人声数据;
19.若当前时刻的所述语音数据是人声数据,则判断前一时刻是否为人声数据;
20.若前一时刻不是人声数据,则生成开始说话事件;
21.若当前时刻的所述语音数据不是人声数据时,则判断前一时刻是否为人声数据;
22.若前一时刻是人声数据,则生成结束说话事件。
23.可选的,所述过程事件还包括打断事件;
24.在所述若前一时刻不是人声数据,则生成开始说话事件前,还包括:
25.获取当前是否为正在播放语音文件;
26.若是,则生成打断事件;
27.若否,则生成开始说话事件。
28.可选的,使用webrtc的vad算法实现当前的所述语音数据是否人声数据的识别。
29.可选的,在所述生成结束说话事件之后,还包括:
30.计时所述语音数据不是人声数据的持续时间;
31.当所述持续时间达到预设的时间阈值后,生成提醒事件。
32.第二方面,本发明实施例还提供了一种电话语音交互装置,包括:
33.采集模块,用于在电话接通后连续采集语音数据;
34.识别模块,用于对所述语音数据进行语音和事件识别,以生成语音文本和过程事件;
35.匹配模块,用于基于所述过程事件匹配响应动作;
36.响应模块,用于当所述响应动作为播放语音时,基于所述语音文本匹配语音文件并播放。
37.第三方面,本发明实施例还提供了一种电话语音交互设备,所述设备包括:
38.一个或多个处理器;
39.存储装置,用于存储一个或多个程序;
40.当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面所述的电话语音交互方法。
41.第四方面,本发明实施例还提供了一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行如第一方面所述的电话语音交互方法。
42.本发明通过在电话接通后连续采集语音数据,并将语音数据分段保存,然后对语音数据逐段进行语音和事件识别,生成语音文本和过程事件,将语音数据分段保存并识别处理,可有效的降低对服务器的性能要求,避免同一事件需要处理大量的数据流,并且分段识别生成语音文本和过程事件可有效的提高电话软交换平台对通话者的动作响应速度,避免出现通话者等待答复的情况。
附图说明
43.图1为本发明实施例一提供的电话语音交互方法的流程图;
44.图2为本发明实施例二提供的电话语音交互装置的结构示意图;
45.图3为本发明实施例三提供的电话语音交互设备的结构示意图。
具体实施方式
46.下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
47.实施例一
48.图1为本发明实施例一提供的电话语音交互方法的流程图,本实施例可适用于智能电话机器人进行营销电话拨打和客服电话应答等情况,该方法可以由电话语音交互装置来执行,该电话语音交互装置可以由软件和/或硬件实现,可配置在计算机设备中,例如,服务器、工作站、个人电脑,等等,该方法具体包括如下步骤:
49.步骤110、在电话接通后连续采集语音数据,并将语音数据分段保存。
50.在本发明实施例中,可采用freeswitch电话软交换平台来实现电话的接通和语音数据的采集。freeswitch是一个跨平台的开源电话软交换平台,主要开发语言是c,以mpl1.1发布。它有很强的可伸缩性
──
从最简单的软电话到商业级的软交换平台几乎无所不能。它支持sip、skype、h323、iax及google talk等通信协议。另外,它还支持很多高级的sip特性,如presence、blf、sla以及tcp tls和srtp等。它可以作为纯sbc使用,如作为t.38及其它点对点通信的代理等。也可以作为b2bua连接其它开源的voip系统,如openpbx、bayonne、yate、asterisk等。freeswitch支持各种带宽的语音编解码,支持8k,16k,32k及48khz的高清通话,并可以在桥接不同频率的语音时自动进行转换。
51.其中,语音数据指的是原始声音的模拟输入(电信号)转化后的数字化信息(数据)。
52.在具体实现中,语音数据可以是在拨通电话后开始采集,也可以是在电话被接听的时候开始采集,具体可根据实际情况进行改变。在拨通电话或被接听后开始连续采集产生的语音数据,直至该通话被结束。并且在本发明实施例中,在采集语音数据时,将语音数据进行分段存储传输,也就是说,在采集的过程中按照一定的时间或大小进行分段,在达到设定的时间间隔或数据大小后统一发送到后一步骤中进行处理。为使通话过程中的响应更及时,该设定的时间间隔或数据大小设定应设定的相对小一些,以保障语音数据能够被及时的处理,以及时做出相应的响应动作。例如将时间间隔设定为1ms、2ms、3ms、5ms、10ms、20、30ms、100ms、200ms等。对应的,通过设定数据大小的方式进行分段时,需要使每个分段内的数据对应的时间间隔相对较小。
53.其中,时间间隔与数据大小的关系公式如下:
54.data_size=采样精度/8*采样率*发送时间间隔/1000
55.例如,时间间隔设定为40ms,则当语音数据的编码格式为pcm、精度为16bit、采样率为8k时,对应的数据大小为16/8*8000*40/1000=640byte。
56.步骤120、对语音数据逐段进行语音和事件识别,以生成语音文本和过程事件。
57.在具体实现中,过程事件可包括通话过程中通话者接听电话、开始说话(对话过程中开始说话)、结束说话(对话过程中说完一句话)、打断说话、挂断电话等事件。而对于事件的识别可结合通话者是否正在说话以及通话状态进行判断识别,而不需要涉及到对语音数据对应的文本内容识别判断,有效的降低计算量。
58.在识别过程事件之后还包括对语音数据进行语音文本识别。语音识别是指让机器
通过识别和理解过程把语音信号转变为相应的文本或命令。语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术三个方面。语音识别技术目前发展的较为成熟,可直接借用现有的语音识别技术实现本发明实施例中的语音数据识别。
59.在具体实现中,本发明实施例中将语音数据进行了分段,在利用语音识别技术进行识别时对服务器压力相对较小,并且可实现更为及时的语音文本识别,提高响应速度。
60.示例性的,在本发明实施例中可在freeswitch电话软交换平台的基础上结合asr模块实现语音文本的识别和过程事件识别。其中,asr(automatic speech recognitio)即自动语音识别,主要是把语音转为文本。具体可直接使用如:腾讯云语音识别(asr)、科大讯飞的以websocket传输语音数据的实时语音识别asr等技术。在本发明中并不具体限定所使用的asr模块来源,只要能够满足本发明实施例中对于语音文本的识别需求即可。
61.步骤130、基于过程事件匹配响应动作。
62.在具体实现中,在前述步骤中基于语音数据识别生成语音文本和过程事件,其中过程事件与通话者的通话动作相对应,例如电话是否被接通、是否挂断、是否正在说话、是否打断freeswitch电话软交换平台正在播放的语音文件、是否长时间未响应等。
63.而对应着上述的各种过程事件(通话动作)freeswitch电话软交换平台需要做出对应的响应,以实现与通话者的交互。例如在利用本发明实施例提供的电话语音交互进行营销电话的自动拨打时,在通话者接听电话后需要播放预设的开场语音、在通话者询问时需要对应的答复、在通话者打断向其正在播放的语音时需要暂停播放,并判断是否为真实打断,进而判断是否继续播放,或切换新的答复语音文件进行答复、在通话者挂断后将通话数据进行上传保存等。
64.步骤140、当响应动作为播放语音时,基于语音文本匹配语音文件并播放。
65.在该步骤中,过程事件匹配到的是通话者发起疑问或需求时,匹配响应动作为对通话者播放语音进行答复,具体的操作为基于语音文本匹配语音文件并播放。
66.本实施例的技术方案,通过在电话接通后连续采集语音数据,并将语音数据分段保存,然后对语音数据逐段进行语音和事件识别,生成语音文本和过程事件,将语音数据分段保存并识别处理,可有效的降低对服务器的性能要求,避免同一事件需要处理大量的数据流,并且分段识别生成语音文本和过程事件可有效的提高电话软交换平台对通话者的动作响应速度,避免出现通话者等待答复的情况。
67.在上述技术方案的基础上,语音数据包括至少一段。结合前述内容可知,实际只有一段语音数据时实际通话时长较短,并且该段语音数据的长度并不超过本发明实施例设定的分段间隔时间或数据大小。
68.而在步骤110中,可包括:
69.步骤111、在电话拨通后连续采集电话的通话数据。
70.在具体实现中,可借由freeswitch电话软交换平台来实现电话的接通和语音数据的连续采集,并将采集的语音数据暂存至缓存区域。
71.步骤112、间隔预设的时间长度将采集到的通话数据作为一段语音数据进行存储。
72.除了上述步骤112中采用间隔预设的时间长度的方式之外,还可以是采用预设的数据大小对语音数据进行分段,然后发送到下一步骤中进行处理。
73.为使通话过程中的响应更及时,该设定的时间间隔或数据大小设定应设定的相对
小一些,以保障语音数据能够被及时的处理,以及时做出相应的响应动作。例如将时间间隔设定为1ms、2ms、3ms、5ms、10ms、20、30ms、100ms、200ms等。对应的,通过设定数据大小的方式进行分段时,需要使每个分段内的数据对应的时间间隔相对较小。
74.步骤120可包括:
75.步骤121、对语音数据进行人声识别,生成开始说话事件和结束说话事件。
76.在本发明实施例中,人声识别指的是对语音数据中的声音进行识别,判断是否为通话者正在说话,进而判断当前与通话者的沟通场景(过程事件)。判断通话者是否开始说话,生成开始说话事件;是否说话结束,生成结束说话事件;是否打断向其正在播放的语音,生成打断事件等。
77.在具体实现中,除了开始说话事件和结束说话事件之外,还可以包括接听事件、打断事件、挂断事件等。
78.步骤122、基于开始说话事件和结束说话事件对语音数据进行语音识别,获得语音文本。
79.在实际实现中,可基于开始说话事件和结束说话事件实现对语音数据的分句,即将语音数据按照通话者的每次说话进行进一步的划分,保障进行文本识别时的语句完整性,保障进行语义判断时的准确性。
80.步骤121中对语音数据进行人声识别,生成开始说话事件和结束说话事件,可包括:
81.步骤1211、识别当前的语音数据是否人声数据。
82.在具体实现中,对于人声数据进行识别,可采用google开源的webrtc框架中的vad算法,该模块的作用主要是用来检测一段语音数据是否是人说话的声音,函数输入为一段二进制语音数据,输出为-1或者1。-1表示该段语音数据不是人的声音,1则表示该段语音数据是人的声音。在其他实施例中,还可以是借由其他的实现方式实现对人声的识别,判断当前通话者是否正在说话。
83.步骤1212、若当前时刻的语音数据是人声数据,则判断前一时刻是否为人声数据。
84.步骤1213、若前一时刻不是人声数据,则生成开始说话事件。
85.通过在判断到人声数据时,判断前一刻是否为人声数据,可确定前一个通话者是否正在说话,进而判断当前是通话者开始说话,还是正在说话过程中。
86.步骤1214、若当前时刻的语音数据不是人声数据时,则判断前一时刻是否为人声数据。
87.步骤1215、若前一时刻是人声数据,则生成结束说话事件。
88.通过在判断不是人声数据时,判断前一刻是否为人声数据,可确定前一个通话者是否正在说话,进而判断当前是通话者结束说话,还是正在聆听向其播放的语音中。
89.此外,在一个实施例中,过程事件还包括打断事件;
90.在步骤1213前,还包括:
91.获取当前是否为正在播放语音文件,也就是说,判断当前是否正在回答通话者的问题,或者是正在向通话者介绍业务等。
92.若当前时刻的语音数据是人声数据,且前一时刻不是人声数据时,检测到当前正在播放语音文件,则生成打断事件,否则,则生成开始说话事件。
93.在步骤1215生成结束说话事件之后,还包括:
94.计时语音数据不是人声数据的持续时间,当持续时间达到预设的时间阈值后,生成提醒事件。
95.通过计时语音数据不是人声数据的持续时间,可获得通话者静默时长,并基于播放的语音的长度确定通话者是否为长时间无应答,并生成相应的提醒事件。
96.在本发明的一个实施例中,电话语音交互方法被部署在freeswitch电话软交换平台,并且在freeswitch电话软交换平台上的集成了智能语音asr模块和智能语音ivr模块。
97.其中智能语音asr模块可包括如下功能:
98.1)自动语音识别。即基于websocket进行语音数据识别。
99.2)过程事件的产生。事件包括开始说话事件、结束说话事件、打断事件、语音识别完成事件、语音识别失败事件、语音识别中间结果返回事件等。
100.智能语音ivr模块可包括如下功能:
101.1)事件监听:监听并接收freeswitch电话交换平台产生的各种事件。
102.2)事件注册和处理:首先注册各种事件的处理函数,当接收到某个事件时调用相应的处理函数。
103.3)与业务后台交互。根据freeswitch电话交换平台产生的各种事件构造给业务后台的通知事件,并执行业务后台下发的动作指令。
104.其中,智能语音asr模块的自动语音识别可基于科大讯飞提供的以websocket传输语音数据的实时语音识别asr。它能够识别出单声道、编码格式为pcm、精度为16bit、采样率为8k的语音数据,并实时返回识别出来的语句文本。
105.智能语音asr模块的识别过程如下:
106.1)通过websocket方式建立asr服务连接请求。
107.2)以一定的时间间隔(毫秒)将采集到的语音数据不停获取freeswitch电话交换平台的语音数据,直至通话结束。
108.在启动asr识别的时候,通过freeswitch电话交换平台的switch_core_media_bug_add函数向freeswitch电话交换平台增加一个media_bug函数和注册回调函数callback_function,用于语音数据的拷贝和处理。
109.当freeswitch电话交换平台连续采集语音数据,并将语音数据分段写入新增加的media_bug时,会执行注册的回调函数处理media_bug里的语音数据。
110.在此步骤里,回调函数的功能就是从media_bug里读取语音数据,并把数据存放在缓存,发送到asr服务器进行语音识别。
111.3)异步接收返回的语音数据识别结果(语音文本)
112.该步骤为在启动asr服务时即新建一个线程,专门处理asr返回的响应数据。
113.产生语音识别过程事件
114.此步骤,用到了google开源的webrtc框架里的一个vad模块,其作用主要是用来检测一段语音数据是否是人说话的声音,函数输入为一段二进制语音数据,输出为-1或者1。-1表示该段语音数据不是人的声音,1则表示该段语音数据是人的声音。
115.根据该vad模块和asr服务返回的响应数据,可以定义出如下几个关键事件:
116.1)产生建立asr服务连接成功事件:asr_start_success
117.当与asr服务器连接成功时,即可以产生该事件。
118.2)产生建立asr服务连接失败事件:asr_start_fail
119.当与asr服务器连接失败时,即可以产生该事件。
120.3)产生开始说话事件:sentence_begin
121.在前述步骤中回调函数callback_function里,调用vad模块的webrtcvad_process函数,我们可以判断出当前的语音数据是否为人说话的声音。在组件的asr模块里设置了2个会话变量,如is_voice和speaking,初始值都为false。当判断当前语音数据为人的声音时,把is_voice置为true。然后判断当speaking为false并且is_voice为ture时产生开始说话事件asr::sentence_begin,同时把speaking置为true。这样通过这两个变量的状态值转换,就可以只在刚开始说话时产生开始说话事件asr::sentence_begin事件,避免在说话过程中一直产生该事件。
122.4)产生结束说话事件:sentence_end
123.如同3.2.2步骤3)原理,当webrtcvad_process函数判断当前的语音数据不是人说话的声音时,把is_voice置为false。然后判断当speaking为true并且is_voice为false时产生结束说话事件asr::sentence_end,同时把speaking置为false。这样通过这两个变量的状态值转换,就可以在说话停止时产生结束说话事件asr::sentence_end事件,避免在人没有说话时也产生该事件。
124.5)产生语音识别过程失败事件:asr_task_fail
125.当在发送语音数据过程中发生错误或者asr服务器识别过程中发生错误,如网络中断等,即可以产生该事件。
126.6)产生语音识别完成事件:sentence_complete
127.当asr服务器识别完一句话的内容时,即可以产生该事件。
128.智能语音ivr模块,主要功能包括注册事件处理函数、监听和处理事件和执行业务后台下发的指令。
129.具体如下:
130.注册事件处理函数
131.智能语音ivr接收的事件包括不限于:channel_answer、channel_hangup_complete、record_start、channel_execute_complete、playback_start、playback_stop、custom(自定义事件)。因此针对这些事件,都需要做不同的逻辑处理。
132.例如收到channel_answer事件需要把通话状态改为answer,channel_hangup_complete需要断开与freeswitch电话交换平台的socket连接,收到playback_start事件需要把播放声音状态置为true,收到sentence_begin句子_开始则重置静音计时,收到sentence_end句子_结束则开始静音计时并向业务后台反馈识别出的内容,等等。
133.监听和处理事件
134.该组件ivr模块启动socket服务,开始监听某个端口,比如8041端口,等待freeswitch电话交换平台连接上来。当freeswitch电话交换平台会话线程连接上智能ivr组件后,创建新线程,接收并处理freeswitch电话交换平台产生的各种事件。接收和处理的事件包括不限于:channel_answer、channel_hangup_complete、record_start、channel_execute_complete、playback_start、playback_stop、sentence_begin、sentence_end。
135.发送业务事件通知和执行业务后台下发的指令
136.智能ivr模块与业务后台通过json格式的消息体进行数据传输。消息格式主要包括请求信息体和响应消息体。其中请求消息体由智能ivr模块发送给业务后台,响应消息体由业务后台发送给智能ivr模块。
137.业务事件通知主要有:enter_notify、answer_notify、interrupt_notify中断、silent_notify、leave_notify、asr_notify。
138.enter_notify:当通话拨通后freeswitch电话交换平台连接上智能ivr模块时告知业务后台。
139.answer_notify:当用户接通电话时告知业务后台。
140.asr_notify:当用户说完一句话并获取到识别结果后告知业务后台。
141.interrupt_notify:当机器人正在播放录音时,用户说话打断后告知业务后台。
142.silent_notify:当用户静音达到一定的时长时告知业务后台。
143.leave_notify:当通话结束后把通话明细数据告知业务后台。
144.响应动作主要有:start_asr、playback、break_uuid、noop。
145.start_asr:一般是业务后台接收到enter_notify事件通知时下发该动作,让freeswitch电话交换平台加载启动该组件的智能asr模块。
146.playback:一般是业务后台接收到answer_notify、asr_notify、silent_notify事件通知时下发该动作,让freeswitch电话交换平台播放指定的语音文件。
147.break_uuid:一般是业务后台接收到interrupt_notify事件通知时下发该动作,让freeswitch电话交换平台中断当前播放的语音文件,并执行后续playback动作。
148.noop:一般是业务后台接收到leave_notify事件通知时下发该动作。该指令为空指令,freeswitch电话交换平台不执行任何动作。
149.请求消息体:{
[0150]“calleeid”:“1362286xxxx”,//被叫号码
[0151]“callerid”:“1326504xxxx”//主叫号码
[0152]“notify”:“xxx_notify”//事件类型
[0153]
}
[0154]
响应消息体:{
[0155]“action”:“xxx”//执行动作
[0156]“params”:{action相关参数设置}
[0157]“after_action”:“xxx”//后续要执行的动作
[0158]“after_params”:{after_action相关参数设置}
[0159]
}
[0160]
例如,当智能ivr模块收到channel_answer事件时,即构造answer_notify通知信息体并发送给业务后台通知后台,客户已经接通电话,然后业务后台下发播放开场白录音的playback指令。
[0161]
实施例二
[0162]
图2为本发明实施例二提供的一种电话语音交互装置的结构图。该装置包括:采集模块21、识别模块22、匹配模块23和响应模块24。其中:
[0163]
采集模块21,用于在电话接通后连续采集语音数据;
[0164]
识别模块22,用于对语音数据进行语音和事件识别,以生成语音文本和过程事件;
[0165]
匹配模块23,用于基于过程事件匹配响应动作;
[0166]
响应模块24,用于当响应动作为播放语音时,基于语音文本匹配语音文件并播放。
[0167]
语音数据包括至少一段;
[0168]
采集模块21包括:
[0169]
采集单元,用于在电话拨通后连续采集电话的通话数据;
[0170]
分段单元,用于间隔预设的时间长度将采集到的通话数据作为一段语音数据进行存储。
[0171]
识别模块22包括:
[0172]
事件识别单元,用于对语音数据进行人声识别,生成开始说话事件和结束说话事件;
[0173]
语音识别单元,用于基于开始说话事件和结束说话事件对语音数据进行语音识别,获得语音文本。
[0174]
事件识别单元,包括:
[0175]
人声识别子单元,用于识别当前的语音数据是否人声数据;
[0176]
第一前刻判断子单元,用于若当前时刻的语音数据是人声数据,则判断前一时刻是否为人声数据;
[0177]
开始生成子单元,用于若前一时刻不是人声数据,则生成开始说话事件;
[0178]
第二前刻判断子单元,用于若当前时刻的语音数据不是人声数据时,则判断前一时刻是否为人声数据;
[0179]
结束生成子单元,用于若前一时刻是人声数据,则生成结束说话事件。
[0180]
过程事件还包括打断事件;
[0181]
开始生成子单元,用于在若前一时刻不是人声数据,则生成开始说话事件前,还包括:
[0182]
播放状态子单元,用于获取当前是否为正在播放语音文件;
[0183]
打断生成子单元,用于若是,则生成打断事件;
[0184]
若否,则执行开始生成子单元生成开始说话事件。
[0185]
在本发明实施例中,使用webrtc的vad算法实现当前的语音数据是否人声数据的识别。
[0186]
还包括:
[0187]
计时子单元,用于计时语音数据不是人声数据的持续时间;
[0188]
提醒生成子单元,用于当持续时间达到预设的时间阈值后,生成提醒事件。
[0189]
本发明实施例所提供的电话语音交互装置可执行本发明任意实施例所提供的电话语音交互方法,具备执行方法相应的功能模块和有益效果。
[0190]
实施例三
[0191]
图3为本发明实施例三提供的一种电子设备的结构示意图。如图3所示,该电子设备包括处理器30、存储器31、通信模块32、输入装置33和输出装置34;电子设备中处理器30的数量可以是一个或多个,图3中以一个处理器30为例;电子设备中的处理器30、存储器31、
通信模块32、输入装置33和输出装置34可以通过总线或其他方式连接,图3中以通过总线连接为例。
[0192]
存储器31作为一种计算机可读存储介质,可用于存储软件程序、计算机可执行程序以及模块,如本实施例中的一种电话语音交互方法对应的模块(例如,一种电话语音交互装置中的故障信息接收模块31、解决方案确定模块32和第一维修人员确定模块33)。处理器30通过运行存储在存储器31中的软件程序、指令以及模块,从而执行电子设备的各种功能应用以及数据处理,即实现上述的一种电话语音交互方法。
[0193]
存储器31可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序;存储数据区可存储根据电子设备的使用所创建的数据等。此外,存储器31可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实例中,存储器31可进一步包括相对于处理器30远程设置的存储器,这些远程存储器可以通过网络连接至电子设备。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0194]
通信模块32,用于与显示屏建立连接,并实现与显示屏的数据交互。输入装置33可用于接收输入的数字或字符信息,以及产生与电子设备的用户设置以及功能控制有关的键信号输入。
[0195]
本实施例提供的一种电子设备,可执行本发明任一实施例提供的电话语音交互方法,具体相应的功能和有益效果。
[0196]
实施例四
[0197]
本发明实施例四还提供一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行一种电话语音交互方法,该方法包括:
[0198]
在电话接通后连续采集语音数据,并将所述语音数据分段保存;
[0199]
对所述语音数据逐段进行语音和事件识别,以生成语音文本和过程事件;
[0200]
基于所述过程事件匹配响应动作;
[0201]
当所述响应动作为播放语音时,基于所述语音文本匹配语音文件并播放。
[0202]
通过以上关于实施方式的描述,所属领域的技术人员可以清楚地了解到,本发明可借助软件及必需的通用硬件来实现,当然也可以通过硬件实现,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如计算机的软盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、闪存(flash)、硬盘或光盘等,包括若干指令用以使得一台计算机电子设备(可以是个人计算机,服务器,或者网络电子设备等)执行本发明各个实施例所述的方法。
[0203]
值得注意的是,上述电话语音交互装置的实施例中,所包括的各个单元和模块只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。
[0204]
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行
了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。