1.本发明涉及光学领域,尤其涉及光学检测技术领域,具体是指一种基于深度学习的拉曼光谱去噪方法。
背景技术:
2.拉曼光谱法是上世纪20年代由印度科学家拉曼提出来的一项技术。上世纪六十年代激光器的诞生,给拉曼光谱的应用带来了发展空间。拉曼光谱分析技术由于具有丰富的物质特性信息、无损检验、无需样品制备等优点,作为一种行之有效的检测分析方法目前已被广泛应用。
3.拉曼光谱是一种由物质的分子振动产生的非弹性散射光谱,能够对物质做定性与定量分析,因而在医疗、化工等诸多领域得到广泛的应用。由于拉曼光谱是一种极其敏感的光谱,极易受到噪音和荧光背景的影响,在分析前需预先对光谱进行去噪处理。
4.目前对拉曼光谱进行去噪的主要方法有savitzky-golay平滑滤波、fft滤波、惩罚最小二乘(pls)、阈值法小波去噪。但目前的方法在去噪的过程中容易丢失纯拉曼光谱信息,同时还依靠人为干预来设定输入参数,不同物质的拉曼光谱需要设定不同的输入参数,并且人为设定的参数很难得到最优的去噪效果。这是拉曼光谱术应用于光学检测领域的一大难题。
5.鉴于现有技术中存在的缺陷,本发明提出一种基于深度学习的拉曼光谱去噪方法,实现对拉曼光谱精准高效去噪。
技术实现要素:
6.本发明的目的包括两个:(1)解决目前方法无法精准高效对拉曼光谱进行去噪的问题;(2)解决目前方法无法自动设定去噪参数的问题。基于以上两个目的,本发明提供一种基于深度学习的拉曼光谱去噪方法。
7.为了实现上述目的,本发明采用的技术方案如下:
8.一种基于深度学习的拉曼光谱去噪方法,包括以下几个步骤:
9.步骤1:利用洛伦兹剖面对纯净拉曼光谱特征峰进行拟合,使用泊松噪音和高斯噪音拟合噪音信号,建立由训练集、验证集、测试集组成的拉曼光谱数据库;
10.步骤2:构建深度学习模型,模型整体由编码器结构和解码器结构组成,编码器结构接收原始拉曼光谱并使用卷积神经网络提取光谱特征信息,解码器结构负责将编码器提取的特征信息重构成与原始拉曼光谱尺寸相同的纯净光谱;
11.步骤4:使用训练集训练深度学习模型,包括编码器网络和解码器网络;
12.步骤5:使用测试集测试改进深度学习模型性能,然后使用模型对拉曼光谱进行去噪,并输出纯净拉曼光谱数据。
13.上述方案中,步骤1,生成纯净光谱数据和带有噪音的模拟拉曼光谱的具体步骤如下:
14.步骤11:本发明使用模拟拉曼光谱对模型进行训练,每条模拟拉曼光谱数据由下方公式组成:
15.r(xi)=r(xi) n(xi)
16.其中xi代表拉曼频移,r(xi)代表生成的模拟拉曼光谱、r(xi)代表纯净拉曼光谱、n(xi)代表噪音光谱,模拟拉曼光谱数据r(xi)由二者叠加而成。
17.上述方案中,步骤12:使用洛伦兹剖面对纯净拉曼光谱特征峰进行拟合,拟合公式如下:
[0018][0019]
模拟的纯净拉曼光谱数据由m个洛伦兹峰组成,m个洛伦兹峰具有不同的振幅an、宽度σn并以不同的变量xn为中心。
[0020]
上述方案中,步骤13:拉曼光谱噪音包括泊松噪音(散粒噪音和热噪音)和高斯噪音(读出噪音)。因此拉曼光谱噪音数据通过下列公式生成:
[0021][0022]
其中n
ph
(xi)为散粒噪音、n
th
为热噪音、n
rd
为读出噪音;e(xi)是标准差为1且平均值为0的高斯噪音。
[0023]
上述方案中,散粒噪音可通过下列公式进行模拟:
[0024][0025]
散粒噪音是纯净光谱r(xi)的平方根,当变量xi对应的r(xi)越大时,散粒噪音也越大。有xi没有对应的信号特征时则没有散粒噪音。
[0026]
上述方案中,热噪音可通过下列公式进行模拟:
[0027][0028]
热噪音可以由热背景b的平方根进行模拟,热背景为xi上的常数。并且读出噪音也可被视为xi上的常数;
[0029]nrd
=c。
[0030]
上述方案中,步骤14:在步骤13的基础上模拟大量具有不同信噪比(snr)的模拟拉曼光谱数据,生成的模拟光谱信噪比计算公式如下所示:
[0031][0032]
上述方案中,步骤2中建立的由编码器结构和解码器结构组成深度学习模型具体步骤如下:
[0033]
步骤21:编码器部分用于对拉曼光谱进行特征提取,它使用经典的vgg16网络结构,一共包括五个特征提取层;
[0034]
前两层每层包含两次3
×
1的卷积处理,以及一次2
×
1的最大池化处理。第三层、第四层则包含三次3
×
1卷积处理和一次最大池化处理,最后一层仅有三次3
×
1卷积处理,无最大池化处理;
[0035]
每次卷积处理均包含批处理以及relu激活函数。
[0036]
上述方案中,步骤22:在步骤21基础上构建解码器部分,解码器部分将编码器部分提取出的特征信息进行重构以获得等尺寸的纯净拉曼光谱,它包含四次操作,每次操作包含一次上采样(up-sampling)处理、一次特征融合(copy and crop)以及两次3
×
1的卷积处理;
[0037]
特征图首先经上采样处理后尺寸缩小为原来的一半,然后与编码器部分对应的卷积层进行特征融合处理,最后再进行两次带有relu激活函数的卷积处理;在解码器末尾是一层无激活函数的1
×
1卷积层,用于输出重构后的纯净光谱。
[0038]
本发明通过搭建深度学习模型,对拉曼光谱进行去噪,解决了目前方法依赖人工设置参数、不便捷、不高效等缺点,本发明具有以下优点:
[0039]
1、本发明的基于深度机器学习模型实现对拉曼光谱数据去噪的方法,使用大量不同的拉曼光谱数据进行训练,使模型具有更强的泛化能力和鲁棒性,可自动对不同物质的拉曼光谱信号进行去噪,无需人工干预设定参数。
[0040]
2、本发明使用了编码器网络与解码器网络构成的u形结构,这种u形结构可对拉曼光谱数据进行去噪的同时最大程度的保留拉曼光谱本身携带的信息,而以往方法在去噪的过程中容易丢失光谱本身携带的信息,相较于传统方法,本发明更加高效且精确。
[0041]
3、本发明针对拉曼光谱去噪中遇到的问题,采用tensorflow深度学习框架编程实现,同时易于拓展和使用,在拉曼光谱去噪处理中具有一定的实际应用价值。
附图说明
[0042]
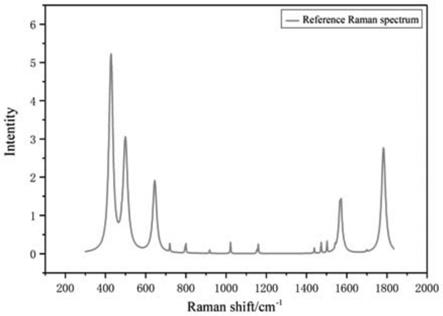
图1为洛伦兹剖面模拟的纯净拉曼光谱;
[0043]
图2为使用泊松噪音和高斯噪音拟合的拉曼光谱;
[0044]
图3为深度学习模型网络示意图;
[0045]
图4为模型去噪结果示意图;
[0046]
图5为本方法与传统方法去噪性能对比图。
具体实施方式
[0047]
下面结合附图与实施例对本发明作进一步说明。
[0048]
本实例提供一种基于深度学习的拉曼光谱去噪方法,在该方法中使用大量模拟拉曼光谱数据进行训练,搭建具有编码器与解码器结构的u型深度学习模型对拉曼光谱数据进行去噪处理。本发明可精准、高效、自动的对拉曼光谱进行去噪处理,能够解决拉曼光谱去噪过程中光谱信息丢失、依赖人工干预设定参数等问题。
[0049]
本方法具体步骤如下:
[0050]
步骤1:使用公式模拟拉曼光谱数据,使用洛伦兹剖面对纯净拉曼光谱特征峰进行拟合,如图1所示。使用泊松噪音和高斯噪音拟合噪音信号,如图2所示。并建立由训练集、验证集、测试集组成的拉曼光谱数据库,具体步骤如下。
[0051]
步骤11:每条模拟拉曼光谱数据由下方公式组成:
[0052]
r(xi)=r(xi) n(xi)
[0053]
其中xi代表拉曼频移,r(xi)代表生成的模拟拉曼光谱、r(xi)代表纯净拉曼光谱、n
(xi)代表噪音光谱,模拟拉曼光谱数据r(xi)由二者叠加而成。
[0054]
步骤12:使用洛伦兹剖面对纯净拉曼光谱特征峰进行拟合,拟合公式如下所示:
[0055][0056]
模拟的纯净拉曼光谱数据由m个洛伦兹峰组成,m个洛伦兹峰具有不同的振幅an、宽度σn并以不同的变量xn为中心。每一条模拟拉曼光谱数据的上述参数均使用随机数,洛伦兹峰数m的取值范围为[5,10]、振幅an的取值范围为[1,6]、宽度σn取值范围为[10,15]、洛伦兹峰中心xn的取值范围为[300,1836]。
[0057]
步骤13:拉曼光谱噪音包括泊松噪音(散粒噪音和热噪音)和高斯噪音(读出噪音)。因此拉曼光谱噪音数据通过下列公式生成:
[0058][0059]
其中n
ph
(xi)为散粒噪音、n
th
为热噪音、n
rd
为读出噪音。e(xi)是标准差为1且平均值为0的高斯噪音。散粒噪音可通过下列公式进行模拟:
[0060][0061]
散粒噪音是纯净光谱r(xi)的平方根,当变量xi对应的r(xi)越大时,散粒噪音也越大。有xi没有对应的信号特征时则没有散粒噪音。
[0062]
热噪音可通过下列公式进行模拟:
[0063][0064]
热噪音可以由热背景b的平方根进行模拟,热背景为xi上的常数。并且读出噪音也可被视为xi上的常数。
[0065]nrd
=c
[0066]
步骤14:在步骤13的基础上模拟大量具有不同信噪比(snr)的模拟拉曼光谱数据,生成的模拟光谱信噪比计算公式如下所示:
[0067][0068]
等比生成snr范围为-4~20的拉曼光谱数据140000条,其中100000条数据用于对深度学习模型进行训练,10000条数据用于在模型训练过程中进行验证,30000条数据用于对模型进行测试。
[0069]
步骤2:构建深度学习模型,如图3所示。模型整体由编码器结构和解码器结构组成。编码器结构用于接收原始拉曼光谱并使用卷积神经网络提取光谱特征信息,本次使用数据维度为1536
×
1的拉曼光谱数据,数据经过编码器结构后数据尺寸被压缩至96但通道数提升至512,解码器结构负责将编码器提取的特征信息重构成与原始拉曼光谱尺寸相同的纯净光谱,即将96
×
512的数据还原为1536
×
1。
[0070]
步骤21:编码器部分用于对拉曼光谱进行特征提取,它使用经典的vgg16网络结构,一共包括五个特征提取层。前两层每层包含两次3
×
1的卷积处理,以及一次2
×
1的最大池化处理。第三层第四层则包含三次3
×
1卷积处理和一次最大池化处理,最后一层仅有三
次3
×
1卷积处理,无最大池化处理。每次卷积处理均包含批处理以及relu激活函数。
[0071]
步骤22:在步骤21基础上构建解码器部分,解码器部分将编码器部分提取出的特征信息进行重构以获得等尺寸的纯净拉曼光谱,它包含四次操作,每次操作包含一次上采样(up-sampling)处理、一次特征融合(copy and crop)以及两次3
×
1的卷积处理。特征图首先经上采样处理后尺寸缩小为原来的一半,然后与编码器部分对应的卷积层进行特征融合处理,最后再进行两次带有relu激活函数的卷积处理。在解码器末尾是一层无激活函数的1
×
1卷积层,用于输出重构后的纯净光谱。
[0072]
步骤3:使用训练集训练深度学习模型,包括编码器结构与解码器结构,使用mse作为模型损失函数,公式如下:
[0073][0074]
其中n为数据尺寸大小,本文选用的拉曼光谱尺寸为1536
×
1,故此处的n同样为1536,i为拉曼频移,yi为在i处拉曼频移位置纯净光谱的相对浓度,为在i处拉曼频移位置模型预测的光谱的相对浓度。模型训练优化算法采用adam方法,其学习率设置为0.01,训练轮数为100轮,批大小为50,并设有早停机制防止模型过拟合。
[0075]
步骤5:将模型用于对拉曼光谱进行去噪处理,并输出去噪后的拉曼光谱,如图4所示。本发明提出的方法与传统方法去噪性能对比图,如图5所示,去噪性能分析如表1所示。
[0076]
表1拉曼光谱去噪性能统计表
[0077] 信噪比snr/db结构相似度ssim原拉曼光谱8.030.87fft滤波14.640.92sg平滑滤波16.340.93本发明提出方法35.370.99
[0078]
由于表1中拉曼光谱去噪性能统计表中数据结果可知,本发明能够有效地对拉曼光谱进行噪音去除,较好的保留拉曼光谱信息,为进一步对拉曼光谱进行定性与定量提供精确可靠的信息。
[0079]
为了对模型去噪性能结果进行评估,本发明采用信噪比(snr)和结构相似比(ssim)指标。信噪比能客观评价拉曼光谱噪声水平,是评价拉曼光谱去噪性能的重要指标之一,信噪比越大表示去噪性能越好,越逼近纯净无噪音的拉曼光谱。结构相似度常用与评价拉曼光谱结构相似性,是一种全参考质量评价方法,结构相似度越大表示去噪性能越好。由表可知本发明提出的方法,在信噪比和结构相似度上均大于传统方法,故证明本方法可精准高效的对拉曼光谱进行去噪。
[0080]
本发明已经通过上述实例进行了说明,但应当理解的是,上述实例知识用于举例和说明的目的。因此,凡在技术领域中通过逻辑分析、推理或者有限实验得到技术方法,皆应当属于描述的实例保护范围内。
[0081]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
