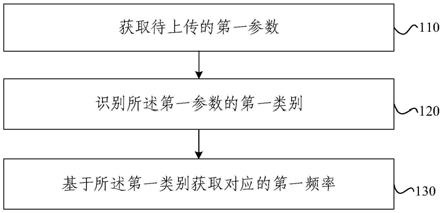
基于fpga的优化速率匹配方法及系统
技术领域:
:1.本发明涉及的是一种通信编码领域的技术,具体是一种基于fpga的优化速率匹配方法及系统。
背景技术:
::2.在lte通信系统中,为降低信息码元的传输误码率,采用turbo码作为信道的查错控制技术,提高通信系统的可靠性。turbo码是一种编码率为1/3的并行级联卷积编码(pccc,parallelconcatenatedconvolutionalcode),通过一段经过码块切分和crc添加的二进制比特流输出为三段长度均为dr=kr 4的比特流简记为其中:r码块序号,kr是码块r中的比特数目,其取值范围介于40到6144;i=0,1,2,被称为系统比特流(systematic),被称为第一校验比特流(parity1),被称为第二校验比特流(parity2),三段比特流并行同时输出。3.为能够更好地提升通信系统的纠错能力,lte系统在速率匹配前先需要进行crc添加、码块分割、信道编码,其中速率匹配是根据编码率为1/3的比特流输出其中:er是码块r中的速率匹配比特数目。4.由于速率匹配的处理过程中涉及到大量的数据搬移,速率匹配操作成为lte基带处理和硬件实现当中的一大瓶颈,严重制约基带的处理性能。尽管现有的速率匹配流程确实可以实现功能,并有在fpga上实现的可行性。但从硬件的角度来看,该流程还存在着很大的优化空间。5.按照传统的速率匹配方案,系统比特流第一校验比特流第二校验比特流三路数据需要分别先进行子块交织。在子块交织这一过程中,由于需要将交织矩阵中某一列的数据完整地读取出来,再写入到交织后矩阵中另一列的位置上,因此直接将这两个步骤映射到fpga当中的话需要两个不同的ram。占据大量的硬件资源作为存储空间,消耗数据存储和读取的时间。以输入的的码长d均为5700比特为例,那么上述两步步骤就需要消耗掉高达5700×6比特的存储空间,当不采用并行方式,存取这些比特还将至少花费5700×6个时钟周期。同样地,对于比特收集这一步,这一步计算完成的是对交织后的三路数据的一个重新的排列,需要进行排列的数据的长度就是三路数据的长度之和。当原始码长为5700比特,对应的就要消耗掉5700×3比特的存储空间和5700×3拍个时钟周期进行数据存取。比特选择与输出这一步中所完成的就是从收集完成的数据当中挑选出合适长度的数据。当输入的wk的总长度大于信道的所能承载的比特个数,将有一部分花费存储空间和处理时间所得到的数据不能够被输出,浪费大量的计算资源。6.根据以上分析,按照传统的速率匹配方案对一长为5700比特的码块进行速率匹配,总共需要消耗5700×9比特的存储空间,至少5700×9个时钟周期。技术实现要素:7.本发明针对现有速率匹配技术在fpga上资源消耗和时延较大的问题,提出一种基于fpga的优化速率匹配方法及系统,针对fpga的特点进行速率匹配方式的优化,并在fpga上实现并进一步优化,显著减少了数据搬移次数,降低了计算消耗的时间和存储空间。8.本发明是通过以下技术方案实现的:9.本发明涉及一种基于fpga的优化速率匹配方法,根据turbo编码后得到的比特流,分别生成系统比特、第一、第二校验比特交织矩阵,在输出数据时参考速率匹配的具体规则对应进行地址转换并从各交织矩阵中读取数据后以串行方式输出结果。10.所述的系统比特、第一、第二校验比特交织矩阵,分别通过以下方式得到:设置等长的系统数组systematic、第一校验数组parity1、第二校验数组parity2,并分别在三个数组的头部存入虚比特,即设置比特值为null;随后将turbo编码后得到的等长的系统比特流第一校验比特流和第二校验比特流分别存储至三个数组中,若将该三个数组按每32个元素分一行的方式,即等效于得到系统比特、第一、第二校验比特的交织矩阵,其中:k表示当前已经输出的比特数量。11.所述的对应进行地址转换包括:①对于系统比特和第一校验比特交织矩阵,通过地址转换式将行号和列号转换为所选择的比特在系统数组systematic、第一校验数组parity1中实际存储的位置,其中:数组p表示列间置换矩阵;②对于第二校验比特交织矩阵,通过地址转换式交织矩阵,通过地址转换式转换为所选择的比特在第二校验数组parity2中实际存储的位置,其中:“ 1”和整除矩阵总元素个数对应协议中第二校验比特矩阵额外的循环移位。技术效果12.本发明利用交织矩阵的特性,设计新的速率匹配算法,减少无谓的数据反复搬移,降低算法的时延和存储空间的消耗;本发明系统利用turbo编码码长与对应的虚比特个数之间的关系,通过基于查表法的虚比特个数计算器,减少硬件资源的开销;本发明利用了fpga中blockram映射的规则的特点,将富余的硬件资源用于在比特储存器、第一校验比特储存器、第二校验比特储存器中设置虚比特信息位,使得fpga中blockram的资源利用更为充分,免去进行比特选择输出时对虚比特需要进行额外判断的硬件结构;本发明通过将读取状态机的四种状态的其中的三种状态进行独热编码,使得状态寄存器可用于储存器的选通,节省资源。所述硬件架构不仅继承了针对fpga硬件结构的新速率匹配算法所带来的低算法的时延和低存储空间的消耗,还进一步降低了lut、ff这些其他硬件资源的消耗。附图说明13.图1为本发明方法流程图;14.图2为本发明系统示意图;15.图3为实施例虚比特个数计算器示意图;16.图4为实施例储存器示意图;17.图5为读取计数器、列交织器、读取地址翻译器示意图;18.图6为读取状态机的状态转移示意图;19.图7为实施例效果示意图。具体实施方式20.如图1所示,为本发明中涉及的一种针对fpga的新速率匹配算法,包括以下步骤:21.①计算系统比特流长度d、虚比特长度nd、待匹配比特流长度e。22.②设置三个等长的数组systematic、parity1和parity2,分别在三个数组的头部存入虚比特,即设置比特值为null;随后将turbo编码后得到的三段等长的比特流分别存储至三个数组中,作为系统比特、第一、第二校验比特的交织矩阵。23.③变量初始化:当计数器变量k小于步骤①计算得到的待匹配比特流长度e时,则表明要继续输出则执行步骤④,反之则停止输出。24.④由于数组的长度等长,输出比特时,通过分别计算并比较由于数组的长度等长,输出比特时,通过分别计算并比较与以判断当前应当输出的是系统比特、第一或第二校验比特,其中:速率匹配输出的首个比特的位置ncb表示第r个码块软缓存比特长度,rvidx表示该传输的冗余版本号,表示交织矩阵的行数,表示交织矩阵的列数;当比较结果为小于,则从systematic数组中读取系统比特,否则判断于,则从systematic数组中读取系统比特,否则判断是奇数时,则从parity1数组中读取第一校验比特;当是偶数时,则从parity2数组中读取第二校验比特。25.⑤对于系统数组systematic、第一校验数组parity1,通过地址转换式对于系统数组systematic、第一校验数组parity1,通过地址转换式将行号和列号转换为所选择的比特在systematic数组和parity1数组中实际存储的位置,其中:行变量row和列变量col分别表示当前选择的比特在交织矩阵中的位置,数组p表示列间置换矩阵;对于第二校验数组parity2,通过地址转换式式进行转换,其中:“ 1”和整除矩阵总元素个数对应协议中第二校验比特矩阵额外的循环移位。26.所述的列间置换矩阵p具体为:[0,16,8,24,4,20,12,28,2,18,10,26,6,22,14,30,1,17,9,25,5,21,13,29,3,19,11,27,7,23,15,31]。[0027]⑥根据步骤⑤计算得到的待选取比特所在的数组名称和读取地址读取交织矩阵,选取得到一个比特,然后判断当比特的值为null,即虚比特时则不输出,且计数器变量k不进行累加,否则输出,并令计数器变量k增加1。[0028]⑦每输出一个系统比特或每输出两个校验比特后,更新所选择的比特在交织矩阵中的相对位置,具体为:累加行变量row,当行号累加到交织矩阵末尾后,再累加列变量col。[0029]如图2所示,为本实施例涉及的一种实现上述优化速率匹配方法的系统,具备三条数据输入端,支持系统比特流、第一和第二校验比特流并行输入,采用串行输出匹配后的二进制信号,输出数据的位宽为1位,同时还配置输出使能信号,该系统包括:配置信息计算器、比特流采集器、码块计数器、写入计数器、虚比特生成器、系统比特储存器systematicram、第一校验比特储存器parity1ram、第二校验比特储存器parity2ram、读取状态机、读取计数器、列交织器、读地址翻译器和输出计数器,其中:配置信息计算器根据上层配置计算此次速率匹配所需要接收和匹配后的二进制信号的长度、交织矩阵行数、虚比特个数等关键信息,比特流采集器与前级turbo编码器相连,并行接收三条等长的代表比特流的二进制信号;写入计数器实时监控当前比特流采集器所从turbo编码器接收到的二进制信号长度,并将当前计数值作为比特储存器的储存地址报告给系统比特、第一和第二校验比特储存器;三个储存器分别生成系统矩阵、第一和第二校验比特矩阵;在完成数据存储后,读取状态机将根据当前的上层指定的冗余版本号,从无读取状态(no_ram_reading)转入读取系统比特状态(s_ram_reading)或读取第一校验比特状态(p1_ram_reading)或读取第二校验比特状态(p2_ram_reading)状态,这三种状态将分别选通系统比特、第一和第二校验比特储存器进行数据输出;读取计数器参照读取状态机的状态给出行号和列号两个计数值,通过列交织器和读地址翻译器两个器件将该两个计数值转换成所需数据在系统比特、第一和第二校验比特储存器中实际所在的地址,提供给当前需要输出数据的储存器;输出计数器实时监控当前已经输出的二进制信号长度,一旦信号长度达到了配置信息计算器给出的匹配后的二进制信号的长度,即告知读取状态机回到no_ram_reading状态,进而停止系统比特、第一和第二校验比特储存器的数据输出;码块计数器依据读取状态机的状态转换情况统计当前turbo编码器输出了几段二进制信号,该器件向外报告当前的统计情况,便于速率匹配之后的所需要进行其他的信号处理。[0030]如图3所示,所述的配置信息计算器根据turbo编码器输出并行接收三条等长的代表比特流的二进制信号,根据其最低5位查表后输出的虚比特个数n0至虚比特生成器。[0031]所述的查表是指:将lte中所有turbo编码长度整除于32,共有四种可能的结果,分别为0,8,16,24,分别对应4种可能的虚比特个数,为28,20,12,4,基于此分析,可以采用查表法计算虚比特个数,而不是现有算法中的减法,节省fpga的4个寄存器(filp-flop)的硬件资源。[0032]所述的基于fpga的速率匹配系统中,通过blockram实现存取比特,具体为:xilinx7系列的fpga,其blockram的映射是以18kbits为单位进行的,对于lteturbo比特流,其数据量最大为6144bits,需要在fpga上映射一个18k的bram。[0033]为充分利用blockram本身的存储资源,提升硬件资源的利用率,本实施例将存入到储存器中的数据设计为0、1和虚比特null,使得存入fpga的blockram中的数据位宽增加为2bits,具体如图4所示,所述的系统比特储存器、第一校验比特储存器、第二校验比特储存器的结构相同,均在收到的数字信号所代表的数据为0时,将10存入存储器;当收到的数字信号所代表的数据为1时,将11存入存储器;当存入虚比特时,将00存入存储器,存入数据的高一位由虚比特生成器提供;低一位由比特流采集器提供。[0034]采用如图4所示的方式存储6144bits长度的turbo比特流消耗的存储空间变为6144×2=12288bits,在fpga当中仍然被映射为18kblockram,利用率66%。[0035]优选地,本实施例再将剩余的存储资源用于虚比特的存储以及留作备用,将该blockram具体配置为位宽2,深度8192的blockram。与此同时,由于虚比特本身也被存入到存储器中,本实施例中的硬件结构不再需要通过地址判断何处是虚比特,可以直接将存入ram中的低一位数据赋给数据输出寄存器,将高一位数据作为输出数据的使能信号,实现在blockram硬件资源消耗不增加的情况下,节省8个查找表(look-uptable,lut)和5个寄存器资源。[0036]所述的写入计数器的计数范围为0至nd d-1,。在写入计数器的控制下,储存器将虚比特和比特流,存入到地址范围为0至nd d-1之间的存储空间中。[0037]如图5所示,所述的读取计数器包括:行选取计数器row和列选取计数器col,其计数范围分别是从0到和从0到[0038]所述的列交织器通过查找表中保存的交织矩阵p的内容,将列计数器的计数值col转化为交织后矩阵的列号p[col]。[0039]所述的读取地址翻译器通过乘法器和加法器,根据来自读取计数器的行号row和来自列交织器的交织后列号计算为读地址或或[0040]所述的读取地址翻译器通过将信号左移五位的方式实现乘32计算,不消耗硬件资源,而取余算法仅在读取计数器选取到交织矩阵最后一个元素时会使得需要赋给readaddress的值与的计算结果不同,因此在硬件设计中将这种情况作为一种特殊情况,通过强制复位的方式实现这一翻译地址的跳变。[0041]如图6所示,所述的读取状态机,为有限状态机(fsm),包括:无读取状态(no_ram_reading)、读取系统比特状态(s_ram_reading)、读取第一校验比特状态(p1_ram_reading)、读取第二校验比特状态(p2_ram_reading),其中:读取系统比特状态、读取第一校验比特状态、读取第二校验比特状态三种状态采用独热编码。[0042]所述的状态机的状态由一组位宽为三位的状态寄存器保存,其中:第一位表示选通系统比特储存器,第二位表示选通第一校验比特储存器,第三位表示选通第二校验比特储存器,并且第二和第三位组合控制读取计数器与翻译器,使得状态机中的状态寄存器中的每一位可直接用于选通存储器进行读操作,实现一寄存器发挥多种功能,节省硬件资源。[0043]在比特选取过程中,第一校验比特和第二校验比特直接需要交替选取,且选取的是交织矩阵的同一位置的比特。因此,在状态机处于读取第一校验比特状态时,需要暂停读取计数器的累加;第二校验比特的交织后矩阵需要进行一步额外的循环移位。因此,在状态机处于读取第二校验比特状态时,需要在读取地址翻译器的输出地址上额外加一。[0044]经过具体实际实验,在xilinxvirtex-7xc7z035ffg676-2fpga上进行实现,得到如图7所示的输入输出时序图,图中所使用的系统比特流,第一校验比特流,第二校验比特流测试向量长度为5700比特,三条比特流并行输入;输出的速率匹配后比特流长度为7776比特。[0045]如图可见,从系统比特流,第一校验比特流,第二校验比特流输入至速率匹配后比特流输出之间的间隔为5710个时钟周期,对比现有的速率匹配算法,该算法的时延大幅下降。[0046]表1优化的速率匹配硬件结构的资源消耗名称数量lut206ff246bram1.5[0047]如表1所示,为优化的速率匹配硬件结构的在fpga上映射后的资源消耗,该硬件结构在virtex-7器件上的最大综合频率可达到430.08mhz。[0048]与现有技术相比,本发明通过校验比特矩阵对应进行地址转换直接得到输出比特流,从而减少数据搬移次数,降低计算消耗的时间和存储空间;通过信息计算器中所包含的基于查表法的虚比特个数计算器的设计;所述的新速率匹配硬件结构中系统比特储存器、第一校验比特储存器、第二校验比特储存器中通过设置虚比特信息位的设计;通过读取状态机中通过将状态机的四种状态的其中的三种状态进行独热编码的设计。综上,本发明通过较少的硬件资源,尤其是存储资源的开销、同时在此资源占用的条件下仍然实现较低的时延和高达430.08mhz的综合频率,非常适合资源量有限的fpga器件。[0049]上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。当前第1页12当前第1页12
技术领域:
:1.本发明涉及的是一种通信编码领域的技术,具体是一种基于fpga的优化速率匹配方法及系统。
背景技术:
::2.在lte通信系统中,为降低信息码元的传输误码率,采用turbo码作为信道的查错控制技术,提高通信系统的可靠性。turbo码是一种编码率为1/3的并行级联卷积编码(pccc,parallelconcatenatedconvolutionalcode),通过一段经过码块切分和crc添加的二进制比特流输出为三段长度均为dr=kr 4的比特流简记为其中:r码块序号,kr是码块r中的比特数目,其取值范围介于40到6144;i=0,1,2,被称为系统比特流(systematic),被称为第一校验比特流(parity1),被称为第二校验比特流(parity2),三段比特流并行同时输出。3.为能够更好地提升通信系统的纠错能力,lte系统在速率匹配前先需要进行crc添加、码块分割、信道编码,其中速率匹配是根据编码率为1/3的比特流输出其中:er是码块r中的速率匹配比特数目。4.由于速率匹配的处理过程中涉及到大量的数据搬移,速率匹配操作成为lte基带处理和硬件实现当中的一大瓶颈,严重制约基带的处理性能。尽管现有的速率匹配流程确实可以实现功能,并有在fpga上实现的可行性。但从硬件的角度来看,该流程还存在着很大的优化空间。5.按照传统的速率匹配方案,系统比特流第一校验比特流第二校验比特流三路数据需要分别先进行子块交织。在子块交织这一过程中,由于需要将交织矩阵中某一列的数据完整地读取出来,再写入到交织后矩阵中另一列的位置上,因此直接将这两个步骤映射到fpga当中的话需要两个不同的ram。占据大量的硬件资源作为存储空间,消耗数据存储和读取的时间。以输入的的码长d均为5700比特为例,那么上述两步步骤就需要消耗掉高达5700×6比特的存储空间,当不采用并行方式,存取这些比特还将至少花费5700×6个时钟周期。同样地,对于比特收集这一步,这一步计算完成的是对交织后的三路数据的一个重新的排列,需要进行排列的数据的长度就是三路数据的长度之和。当原始码长为5700比特,对应的就要消耗掉5700×3比特的存储空间和5700×3拍个时钟周期进行数据存取。比特选择与输出这一步中所完成的就是从收集完成的数据当中挑选出合适长度的数据。当输入的wk的总长度大于信道的所能承载的比特个数,将有一部分花费存储空间和处理时间所得到的数据不能够被输出,浪费大量的计算资源。6.根据以上分析,按照传统的速率匹配方案对一长为5700比特的码块进行速率匹配,总共需要消耗5700×9比特的存储空间,至少5700×9个时钟周期。技术实现要素:7.本发明针对现有速率匹配技术在fpga上资源消耗和时延较大的问题,提出一种基于fpga的优化速率匹配方法及系统,针对fpga的特点进行速率匹配方式的优化,并在fpga上实现并进一步优化,显著减少了数据搬移次数,降低了计算消耗的时间和存储空间。8.本发明是通过以下技术方案实现的:9.本发明涉及一种基于fpga的优化速率匹配方法,根据turbo编码后得到的比特流,分别生成系统比特、第一、第二校验比特交织矩阵,在输出数据时参考速率匹配的具体规则对应进行地址转换并从各交织矩阵中读取数据后以串行方式输出结果。10.所述的系统比特、第一、第二校验比特交织矩阵,分别通过以下方式得到:设置等长的系统数组systematic、第一校验数组parity1、第二校验数组parity2,并分别在三个数组的头部存入虚比特,即设置比特值为null;随后将turbo编码后得到的等长的系统比特流第一校验比特流和第二校验比特流分别存储至三个数组中,若将该三个数组按每32个元素分一行的方式,即等效于得到系统比特、第一、第二校验比特的交织矩阵,其中:k表示当前已经输出的比特数量。11.所述的对应进行地址转换包括:①对于系统比特和第一校验比特交织矩阵,通过地址转换式将行号和列号转换为所选择的比特在系统数组systematic、第一校验数组parity1中实际存储的位置,其中:数组p表示列间置换矩阵;②对于第二校验比特交织矩阵,通过地址转换式交织矩阵,通过地址转换式转换为所选择的比特在第二校验数组parity2中实际存储的位置,其中:“ 1”和整除矩阵总元素个数对应协议中第二校验比特矩阵额外的循环移位。技术效果12.本发明利用交织矩阵的特性,设计新的速率匹配算法,减少无谓的数据反复搬移,降低算法的时延和存储空间的消耗;本发明系统利用turbo编码码长与对应的虚比特个数之间的关系,通过基于查表法的虚比特个数计算器,减少硬件资源的开销;本发明利用了fpga中blockram映射的规则的特点,将富余的硬件资源用于在比特储存器、第一校验比特储存器、第二校验比特储存器中设置虚比特信息位,使得fpga中blockram的资源利用更为充分,免去进行比特选择输出时对虚比特需要进行额外判断的硬件结构;本发明通过将读取状态机的四种状态的其中的三种状态进行独热编码,使得状态寄存器可用于储存器的选通,节省资源。所述硬件架构不仅继承了针对fpga硬件结构的新速率匹配算法所带来的低算法的时延和低存储空间的消耗,还进一步降低了lut、ff这些其他硬件资源的消耗。附图说明13.图1为本发明方法流程图;14.图2为本发明系统示意图;15.图3为实施例虚比特个数计算器示意图;16.图4为实施例储存器示意图;17.图5为读取计数器、列交织器、读取地址翻译器示意图;18.图6为读取状态机的状态转移示意图;19.图7为实施例效果示意图。具体实施方式20.如图1所示,为本发明中涉及的一种针对fpga的新速率匹配算法,包括以下步骤:21.①计算系统比特流长度d、虚比特长度nd、待匹配比特流长度e。22.②设置三个等长的数组systematic、parity1和parity2,分别在三个数组的头部存入虚比特,即设置比特值为null;随后将turbo编码后得到的三段等长的比特流分别存储至三个数组中,作为系统比特、第一、第二校验比特的交织矩阵。23.③变量初始化:当计数器变量k小于步骤①计算得到的待匹配比特流长度e时,则表明要继续输出则执行步骤④,反之则停止输出。24.④由于数组的长度等长,输出比特时,通过分别计算并比较由于数组的长度等长,输出比特时,通过分别计算并比较与以判断当前应当输出的是系统比特、第一或第二校验比特,其中:速率匹配输出的首个比特的位置ncb表示第r个码块软缓存比特长度,rvidx表示该传输的冗余版本号,表示交织矩阵的行数,表示交织矩阵的列数;当比较结果为小于,则从systematic数组中读取系统比特,否则判断于,则从systematic数组中读取系统比特,否则判断是奇数时,则从parity1数组中读取第一校验比特;当是偶数时,则从parity2数组中读取第二校验比特。25.⑤对于系统数组systematic、第一校验数组parity1,通过地址转换式对于系统数组systematic、第一校验数组parity1,通过地址转换式将行号和列号转换为所选择的比特在systematic数组和parity1数组中实际存储的位置,其中:行变量row和列变量col分别表示当前选择的比特在交织矩阵中的位置,数组p表示列间置换矩阵;对于第二校验数组parity2,通过地址转换式式进行转换,其中:“ 1”和整除矩阵总元素个数对应协议中第二校验比特矩阵额外的循环移位。26.所述的列间置换矩阵p具体为:[0,16,8,24,4,20,12,28,2,18,10,26,6,22,14,30,1,17,9,25,5,21,13,29,3,19,11,27,7,23,15,31]。[0027]⑥根据步骤⑤计算得到的待选取比特所在的数组名称和读取地址读取交织矩阵,选取得到一个比特,然后判断当比特的值为null,即虚比特时则不输出,且计数器变量k不进行累加,否则输出,并令计数器变量k增加1。[0028]⑦每输出一个系统比特或每输出两个校验比特后,更新所选择的比特在交织矩阵中的相对位置,具体为:累加行变量row,当行号累加到交织矩阵末尾后,再累加列变量col。[0029]如图2所示,为本实施例涉及的一种实现上述优化速率匹配方法的系统,具备三条数据输入端,支持系统比特流、第一和第二校验比特流并行输入,采用串行输出匹配后的二进制信号,输出数据的位宽为1位,同时还配置输出使能信号,该系统包括:配置信息计算器、比特流采集器、码块计数器、写入计数器、虚比特生成器、系统比特储存器systematicram、第一校验比特储存器parity1ram、第二校验比特储存器parity2ram、读取状态机、读取计数器、列交织器、读地址翻译器和输出计数器,其中:配置信息计算器根据上层配置计算此次速率匹配所需要接收和匹配后的二进制信号的长度、交织矩阵行数、虚比特个数等关键信息,比特流采集器与前级turbo编码器相连,并行接收三条等长的代表比特流的二进制信号;写入计数器实时监控当前比特流采集器所从turbo编码器接收到的二进制信号长度,并将当前计数值作为比特储存器的储存地址报告给系统比特、第一和第二校验比特储存器;三个储存器分别生成系统矩阵、第一和第二校验比特矩阵;在完成数据存储后,读取状态机将根据当前的上层指定的冗余版本号,从无读取状态(no_ram_reading)转入读取系统比特状态(s_ram_reading)或读取第一校验比特状态(p1_ram_reading)或读取第二校验比特状态(p2_ram_reading)状态,这三种状态将分别选通系统比特、第一和第二校验比特储存器进行数据输出;读取计数器参照读取状态机的状态给出行号和列号两个计数值,通过列交织器和读地址翻译器两个器件将该两个计数值转换成所需数据在系统比特、第一和第二校验比特储存器中实际所在的地址,提供给当前需要输出数据的储存器;输出计数器实时监控当前已经输出的二进制信号长度,一旦信号长度达到了配置信息计算器给出的匹配后的二进制信号的长度,即告知读取状态机回到no_ram_reading状态,进而停止系统比特、第一和第二校验比特储存器的数据输出;码块计数器依据读取状态机的状态转换情况统计当前turbo编码器输出了几段二进制信号,该器件向外报告当前的统计情况,便于速率匹配之后的所需要进行其他的信号处理。[0030]如图3所示,所述的配置信息计算器根据turbo编码器输出并行接收三条等长的代表比特流的二进制信号,根据其最低5位查表后输出的虚比特个数n0至虚比特生成器。[0031]所述的查表是指:将lte中所有turbo编码长度整除于32,共有四种可能的结果,分别为0,8,16,24,分别对应4种可能的虚比特个数,为28,20,12,4,基于此分析,可以采用查表法计算虚比特个数,而不是现有算法中的减法,节省fpga的4个寄存器(filp-flop)的硬件资源。[0032]所述的基于fpga的速率匹配系统中,通过blockram实现存取比特,具体为:xilinx7系列的fpga,其blockram的映射是以18kbits为单位进行的,对于lteturbo比特流,其数据量最大为6144bits,需要在fpga上映射一个18k的bram。[0033]为充分利用blockram本身的存储资源,提升硬件资源的利用率,本实施例将存入到储存器中的数据设计为0、1和虚比特null,使得存入fpga的blockram中的数据位宽增加为2bits,具体如图4所示,所述的系统比特储存器、第一校验比特储存器、第二校验比特储存器的结构相同,均在收到的数字信号所代表的数据为0时,将10存入存储器;当收到的数字信号所代表的数据为1时,将11存入存储器;当存入虚比特时,将00存入存储器,存入数据的高一位由虚比特生成器提供;低一位由比特流采集器提供。[0034]采用如图4所示的方式存储6144bits长度的turbo比特流消耗的存储空间变为6144×2=12288bits,在fpga当中仍然被映射为18kblockram,利用率66%。[0035]优选地,本实施例再将剩余的存储资源用于虚比特的存储以及留作备用,将该blockram具体配置为位宽2,深度8192的blockram。与此同时,由于虚比特本身也被存入到存储器中,本实施例中的硬件结构不再需要通过地址判断何处是虚比特,可以直接将存入ram中的低一位数据赋给数据输出寄存器,将高一位数据作为输出数据的使能信号,实现在blockram硬件资源消耗不增加的情况下,节省8个查找表(look-uptable,lut)和5个寄存器资源。[0036]所述的写入计数器的计数范围为0至nd d-1,。在写入计数器的控制下,储存器将虚比特和比特流,存入到地址范围为0至nd d-1之间的存储空间中。[0037]如图5所示,所述的读取计数器包括:行选取计数器row和列选取计数器col,其计数范围分别是从0到和从0到[0038]所述的列交织器通过查找表中保存的交织矩阵p的内容,将列计数器的计数值col转化为交织后矩阵的列号p[col]。[0039]所述的读取地址翻译器通过乘法器和加法器,根据来自读取计数器的行号row和来自列交织器的交织后列号计算为读地址或或[0040]所述的读取地址翻译器通过将信号左移五位的方式实现乘32计算,不消耗硬件资源,而取余算法仅在读取计数器选取到交织矩阵最后一个元素时会使得需要赋给readaddress的值与的计算结果不同,因此在硬件设计中将这种情况作为一种特殊情况,通过强制复位的方式实现这一翻译地址的跳变。[0041]如图6所示,所述的读取状态机,为有限状态机(fsm),包括:无读取状态(no_ram_reading)、读取系统比特状态(s_ram_reading)、读取第一校验比特状态(p1_ram_reading)、读取第二校验比特状态(p2_ram_reading),其中:读取系统比特状态、读取第一校验比特状态、读取第二校验比特状态三种状态采用独热编码。[0042]所述的状态机的状态由一组位宽为三位的状态寄存器保存,其中:第一位表示选通系统比特储存器,第二位表示选通第一校验比特储存器,第三位表示选通第二校验比特储存器,并且第二和第三位组合控制读取计数器与翻译器,使得状态机中的状态寄存器中的每一位可直接用于选通存储器进行读操作,实现一寄存器发挥多种功能,节省硬件资源。[0043]在比特选取过程中,第一校验比特和第二校验比特直接需要交替选取,且选取的是交织矩阵的同一位置的比特。因此,在状态机处于读取第一校验比特状态时,需要暂停读取计数器的累加;第二校验比特的交织后矩阵需要进行一步额外的循环移位。因此,在状态机处于读取第二校验比特状态时,需要在读取地址翻译器的输出地址上额外加一。[0044]经过具体实际实验,在xilinxvirtex-7xc7z035ffg676-2fpga上进行实现,得到如图7所示的输入输出时序图,图中所使用的系统比特流,第一校验比特流,第二校验比特流测试向量长度为5700比特,三条比特流并行输入;输出的速率匹配后比特流长度为7776比特。[0045]如图可见,从系统比特流,第一校验比特流,第二校验比特流输入至速率匹配后比特流输出之间的间隔为5710个时钟周期,对比现有的速率匹配算法,该算法的时延大幅下降。[0046]表1优化的速率匹配硬件结构的资源消耗名称数量lut206ff246bram1.5[0047]如表1所示,为优化的速率匹配硬件结构的在fpga上映射后的资源消耗,该硬件结构在virtex-7器件上的最大综合频率可达到430.08mhz。[0048]与现有技术相比,本发明通过校验比特矩阵对应进行地址转换直接得到输出比特流,从而减少数据搬移次数,降低计算消耗的时间和存储空间;通过信息计算器中所包含的基于查表法的虚比特个数计算器的设计;所述的新速率匹配硬件结构中系统比特储存器、第一校验比特储存器、第二校验比特储存器中通过设置虚比特信息位的设计;通过读取状态机中通过将状态机的四种状态的其中的三种状态进行独热编码的设计。综上,本发明通过较少的硬件资源,尤其是存储资源的开销、同时在此资源占用的条件下仍然实现较低的时延和高达430.08mhz的综合频率,非常适合资源量有限的fpga器件。[0049]上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。