1.本发明涉及科技大数据流行性及前沿性度量技术领域,特别是涉及本发明涉及一种基于主题演化趋势的科技大数据流行性及前沿性度量方法。
背景技术:
2.现有的对科技大数据流行性度量方法研究中,通常利用lda算法获得文档主题分布,但其未考虑到科技大数据发表时间对于流行性及前沿性度量的影响,没有考虑到科技大数据主题随着时间的演变趋势,无法有效表示出科技大数据流行性及前沿性随着时间推进的变化趋势。
3.科技大数据有着明确的发表时间数据,而且随着时间的变化,科技大数据的流行性及前沿性必然发生变化,因此这是一个动态的演变趋势。在lda模型中,给定语料库的所有文档,并不会考虑文档时间先后顺序,在建模过程中认为语料库的主题是固定不变的。因此如何引入时间因素,考虑文档的时间属性及主题随时间的动态演化,更准确地表示科技大数据流行性及前沿性是一个难点。
技术实现要素:
4.本发明为克服现有度量方法存在的不足之处,提出一种基于主题演化趋势的科技大数据流行性及前沿性度量方法,以期能更加准确地度量出科技大数据流行性及前沿性,从而提高科技大数据价值评估准确性。
5.本发明为达到上述发明目的,采用如下技术方案:
6.本发明一种基于主题演化趋势的科技大数据流行性及前沿性度量方法的特点是按以下步骤进行:
7.步骤1、获取科技数据的标题、摘要、关键词、发表时间信息:
8.步骤1.1、定义科技数据集的序号集合为d∈{1,2,...,d,...,|d|},其中,d表示任意科技数据的编号,|d|表示科技数据的数量;
9.步骤1.2、获取|d|篇科技数据的发表时间,其中,将第d篇科技数据的发表时间为一个时间切片t,则将时间切片t中的第d篇科技数据记为d
d,t
,且t∈{1,2,...,t},t表示时间切片总数;
10.获取|d|篇科技数据的标题、摘要和关键词信息并利用关键词构造的人工分词词典进行分词处理,再去除标点符号、停用词及低频词,从而构成文本集合其中,第d篇科技数据所对应的文本信息,记为w
dn
表示第d篇文本信息中第n个词,nd表示第d篇文本信息中词的总数;
11.步骤2、基于科技数据的发表时间信息和文本信息,构建动态主题模型dtm:
12.步骤2.1、利用式(1)所示的线性动态模型采样时间切片t的演化参数α
t
:
13.14.式(1)中,α
t-1
表示时间切片t-1内的演化参数,表示正态分布,θ表示变量参数,i是单位矩阵;
15.步骤2.2、利用式(2)所示的状态空间模型采样时间切片t内主题k的自然参数β
t,k
:
[0016][0017]
式(2)中,β
t,k-1
表示时间切片t中主题k-1的自然参数,δ表示变量参数;
[0018]
步骤2.3、对于时间切片t中的第d篇科技数据d
d,t
,利用式(3)从先验参数(α
t
,σ2i)的正态分布中采样文档-主题分布参数η
d,t
:
[0019][0020]
式(3)中,σ表示变量参数;
[0021]
利用式(4)从先验参数(π(η
d,t
))的多项分布中采样单词对应的主题k:
[0022]
k~mult(π(η
d,t
))
ꢀꢀꢀꢀꢀ
(4)
[0023]
式(4)中,π为用于将多项自然参数映射为平均参数的函数;mult表示多项式分布;
[0024]
利用式(5)从先验参数为(π(β
t,k
))的多项分布中采样生成文档d
d,t
中的单词w
d,n,t
:
[0025]wd,n,t
~mult(π(β
t,k
))
ꢀꢀꢀꢀꢀ
(5)
[0026]
步骤2.4、对于数据集合利用式(6)得到动态主题模型dtm:
[0027][0028]
式(6)中,α表示演化参数,η表示文档-主题分布参数,β表示主题自然参数,表示超参数的先验分布;
[0029]
步骤2.5、利用所述动态主题模型dtm获得文档主题分布p(k
t
|d),其中,k
t
表示时间切片t中的任一主题;
[0030]
步骤3、计算时间切片t下的文档集合中第j个文档d
tj
的文档主题分布为p(k
t
|d
tj
);从而利用式(7)时间切片t下主题k
t
的主题热度值topichot(k
t
):
[0031][0032]
式(7)中,n
t
表示时间切片t下的文档集合中的文档数量;
[0033]
步骤4、利用式(8)计算时间切片t下的文档集合中第j个文档d
tj
的流行性 popularity(d
tj
):
[0034][0035]
步骤5、计算科技数据的前沿性:
[0036]
将主题k在每一个时间切片内所对应的主题热度值中主题热度最高的时间切片记为tm并将对应的最高主题热度值记为
[0037]
利用式(9)得到时间切片t下的文档集合中第j个文档d
tj
在主题k上的前沿性 frontier(d
tj,k
):
[0038][0039]
利用式(10)计算时间切片t下的文档集合中第j个文档d
tj
的前沿性frontier(d
tj
):
[0040]
frontier(d
tj
)=∑
k∈k
frontier(d
tj,k
)
ꢀꢀꢀꢀꢀꢀ
(10)。
[0041]
与已有技术相比,本发明有益效果体现在:
[0042]
1、本发明通过利用科技大数据关键词构建人工分词词典,使得文档分词效果得到显著提高,有利于获得更加准确的分词结果,为后续dtm模型提供高质量的输入语料库。
[0043]
2、本发明通过dtm模型引入科技大数据发表时间属性,刻画出语料库主题随着时间的动态演化过程,可以得到不同主题在不同时间节点的热度变化,相比于固定不变的主题,利用此模型得到的结果更加符合实际情形。
[0044]
3、本发明基于科技大数据的文档主题分布及其发表年份数据,结合科技大数据发表年份各个主题的热度计算出科技大数据流行性及前沿性,从而提高了科技大数据流行性及前沿性度量的准确性。
附图说明
[0045]
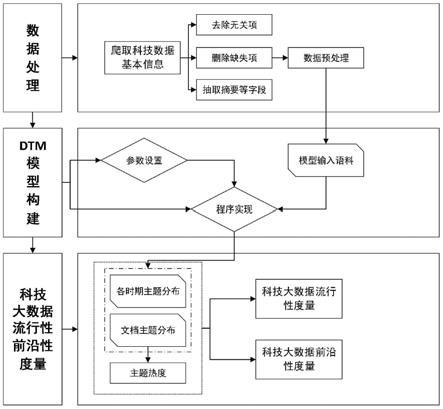
图1是本发明的科技大数据流行性及前沿性计算流程图;
具体实施方式
[0046]
本实施例中,一种基于主题演化趋势的科技大数据流行性及前沿性度量方法,是通过 dtm模型引入文档时间因素,从而刻画出语料库主题随时间的动态演化,计算出不同主题在不同时间的热度变化的热度演化趋势,以此作为计算科技大数据流行性和前沿性的基础,结合科技大数据的发表年份及其文档主题分布,可以度量科技大数据流行性和前沿性指标,从而能提高科技大数据价值评估准确性,具体的说,如图1所示,该方法是按如下步骤进行:
[0047]
步骤1、从科技文献数据集中获取科技数据的标题、摘要、关键词、发表时间信息:
[0048]
步骤1.1、定义科技数据集的序号集合为d∈{1,2,...,d,...,|d|},其中,d表示任意科技数据的编号,|d|表示科技数据的数量;
[0049]
步骤1.2、获取|d|篇科技数据的发表时间,其中,将第d篇科技数据的发表时间为一个时间切片t,则将时间切片t中的第d篇科技数据记为d
d,t
,且t∈{1,2,...,t},t表示时间切片总数;
[0050]
获取|d|篇科技数据的标题、摘要和关键词信息并利用关键词构造的人工分词词典进行分词处理,再去除标点符号、停用词及低频词,从而构成文本集合其中,第d篇科技数据所对应的文本信息,记为w
dn
表示第d篇文本信息中第n个
词,nd表示第d篇文本信息中词的总数;
[0051]
具体实例中,采集的期刊论文基本信息涵盖各个期刊2012-2020年的论文基本信息,包括科技论文标题、科技论文关键词、科技论文摘要、科技论文发表时间四个字段,共5496条数据,并对文本信息进行分词处理,包括以下步骤:
[0052]
step1:通过论文关键词构建人工分词词典,词典格式为一个词占一行,每一行分三部分:词语、词频(可省略)、词性(可省略),三部分用空格隔开,顺序不可颠倒,在python中使用jieba进行分词,关键代码为file_userdict='dict.txt'、jieba.load_userdict(file_userdict),其中dict.txt为人工分词词典;
[0053]
step2:基于百度中文停用词表构造停用表,包括标点符号、停用词、词频地的词以及“研究”、“模型”等词,在python中通过加载停用词表实现此功能,关键代码为word_stop= open('cn_stopwords.txt')。
[0054]
步骤2、基于科技数据的发表时间信息和文本信息,构建动态主题模型dtm:
[0055]
步骤2.1、利用式(1)所示的线性动态模型采样时间切片t的演化参数α
t
:
[0056][0057]
式(1)中,α
t-1
表示时间切片t-1内的演化参数,表示正态分布,θ表示变量参数,i是单位矩阵;
[0058]
步骤2.2、利用式(2)所示的状态空间模型采样时间切片t内主题k的自然参数β
t,k
:
[0059][0060]
式(2)中,β
t,k-1
表示时间切片t中主题k-1的自然参数,δ表示变量参数;
[0061]
步骤2.3、对于时间切片t中的第d篇科技数据d
d,t
,利用式(3)从先验参数(α
t
,σ2i)的正态分布中采样文档-主题分布参数η
d,t
:
[0062][0063]
式(3)中,σ表示变量参数;
[0064]
利用式(4)从先验参数(π(η
d,t
))的多项分布中采样单词对应的主题k:
[0065]
k~mult(π(η
d,t
))
ꢀꢀꢀꢀꢀꢀ
(4)
[0066]
式(4)中,π为用于将多项自然参数映射为平均参数的函数;mult表示多项式分布;
[0067]
利用式(5)从先验参数为(π(β
t,k
))的多项分布中采样生成文档d
d,t
中的单词w
d,n,t
:
[0068]wd,n,t
~mult(π(β
t,k
))
ꢀꢀꢀꢀꢀꢀꢀ
(5)
[0069]
步骤2.4、对于数据集合利用式(6)得到动态主题模型dtm:
[0070][0071][0072]
式(6)中,α表示演化参数,η表示文档-主题分布参数,β表示主题自然参数,表示超参数的先验分布;
[0073]
步骤2.5、利用动态主题模型dtm获得文档主题分布p(k
t
|d),其中,k
t
表示时间切片t 中的任一主题;
[0074]
本实施例中,设置模型参数,训练dtm模型,包括以下步骤:
[0075]
step1:主题数目选择采用一致性评分确定主题数目,当一致性评分最高时,取此时的主题数目k为最优;
[0076]
step2:按照论文发表年份个数以及不同年份发表论文数量设置语料库间隔,在python中实现的语句为time_slice=[378,655,743,823,789,789,713,715,359],其中378表示在2012年发表的论文数量,其他以此类推。
[0077]
step3:通过python实现dtm模型训练,核心代码为:
[0078]
ldaseq=ldaseqmodel.ldaseqmodel(corpus=corpus,id2word=dictionary,time_slice=time_slice, num_topics=7),当模型达到迭代次数收敛后,可得到模型的训练结果,通过topicevolution= ldaseq.print_topic_times(topic=0)可以查询指定主题在不同时期的演变,此处为第一个主题,通过docnum=ldaseq.doc_topics(i)可以输出所有文档的主题分布。
[0079]
步骤3、计算时间切片t下的文档集合中第j个文档d
tj
的文档主题分布为p(k
t
|d
tj
);从而利用式(7)时间切片t下主题k
t
的主题热度值topichot(k
t
):
[0080][0081]
式(7)中,n
t
表示时间切片t下的文档集合中的文档数量;
[0082]
本实例中,t记为某一年份,该年份下论文篇数即文档数量为n
t
,可以计算出该年份下所有主题的热度;对于一个主题k,其热度是根据该年份所有论文在这个主题上概率分布的累加与该年份发表论文数量的比值,即公式(7);相同的处理步骤可以得到各个年份不同主题的热度;
[0083]
步骤4、利用式(8)计算时间切片t下的文档集合中第j个文档d
tj
的流行性popularity(d
tj
):
[0084][0085]
具体实施中,基于主题热度演化趋势,可以计算得到每个科技数据的流行性:对于一篇论文,其发表年份为t,可以匹配得到对应年份主题热度topichot(k
t
),通过该论文的文档主题分布即该论文在不同主题上的概率分布与对应年份主题热度topichot(k
t
)相乘后累加,即可获得该论文流行性度量值。
[0086]
步骤5、计算科技数据的前沿性:
[0087]
将主题k在每一个时间切片内所对应的主题热度值中主题热度最高的时间切片记为tm并将对应的最高主题热度值记为
[0088]
利用式(9)得到时间切片t下的文档集合中第j个文档d
tj
在主题k上的前沿性 frontier(d
tj,k
):
[0089][0090]
利用式(10)计算时间切片t下的文档集合中第j个文档d
tj
的前沿性frontier(d
tj
):
[0091]
frontier(d
tj
)=∑
k∈k
frontier(d
tj,k
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
