技术特征:
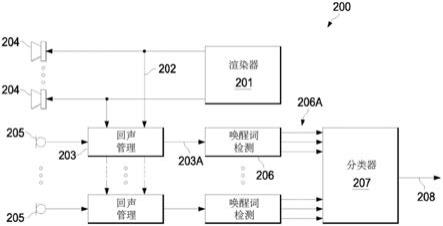
1.一种用于估计用户在环境中的位置的计算机实施的方法,所述方法包括:从所述环境中的多个麦克风中的每一麦克风接收输出信号,所述多个麦克风中的至少两个麦克风被包含在所述环境中的单独位置处的单独装置中,所述输出信号对应于用户的当前话语;从每一麦克风的所述输出信号确定多个当前声学特征;及将分类器应用于所述多个当前声学特征,其中应用所述分类器涉及应用针对先前确定的声学特征进行训练的模型,所述先前确定的声学特征源自所述用户在所述环境中的多个用户区中说出的多个先前话语,其中所述模型将所述环境中的所述多个用户区与所述多个声学特征关联,其中所述分类器的输出提供所述用户当前所在的所述用户区的估计,且其中所述当前话语及所述先前话语包括唤醒词话语,且所述声学特征包含唤醒词置信度度量及/或唤醒词持续时间度量。2.根据权利要求1所述的方法,其中所述多个麦克风中的至少一者被包含在智能音频装置中,或经配置用于与智能音频装置通信。3.根据权利要求1或权利要求2所述的方法,其中所述多个用户区包括多个预定用户区。4.根据权利要求1到3中任一权利要求所述的方法,其中所述估计是在不参考所述多个麦克风的几何位置的情况下确定的。5.根据权利要求1到4中任一权利要求所述的方法,其中所述多个当前声学特征是异步地确定的。6.根据权利要求1到5中任一权利要求所述的方法,其中所述分类器估计每一用户区的后验概率,其中所述用户当前所在的所述用户区被估计为具有最大后验概率的所述用户区。7.根据权利要求1到6中任一权利要求所述的方法,其中使用标记有用户区的训练数据训练所述模型。8.根据权利要求1到6中任一权利要求所述的方法,其中使用未标记有用户区的未标记训练数据训练所述模型。9.根据权利要求1到8中任一权利要求所述的方法,其中所述声学特征进一步包含至少一个接收电平度量。10.根据权利要求9所述的方法,其中所述模型是针对归一化唤醒词置信度、归一化平均接收电平或最大接收电平中的一或多者进行训练的高斯混合模型。11.根据权利要求10所述的方法,其中所述归一化平均接收电平包含在最可信唤醒词的持续时间内的平均接收电平及/或所述最大接收电平包括在所述最可信唤醒词的持续时间内的最大接收电平。12.根据权利要求1到11中任一权利要求所述的方法,其中所述模型的训练在应用所述分类器的过程期间继续。13.根据权利要求12所述的方法,其中所述训练基于来自所述用户的显式反馈。14.根据权利要求12或13所述的方法,其中所述训练基于对基于估计的用户区的波束形成或麦克风选择的成功的隐式反馈。
15.根据权利要求14所述的方法,其中所述隐式反馈包含以下至少一者:用户异常地终止语音助手的响应的确定;或命令辨识器返回低置信度结果;或第二遍追溯唤醒词检测器返回说出唤醒词的低置信度。16.根据权利要求1到15中任一权利要求所述的方法,其进一步包括根据所述估计的用户区选择至少一个扬声器,并控制所述至少一个扬声器以将声音提供到所述估计的用户区。17.根据权利要求1到16中任一权利要求所述的方法,其进一步包括根据所述估计的用户区选择至少一个麦克风,并将由所述至少一个麦克风输出的信号提供到智能音频装置。18.根据权利要求1到17中任一权利要求所述的方法,其中所述多个麦克风中的第一麦克风根据第一采样时钟对音频数据进行采样,且所述多个麦克风中的第二麦克风根据第二采样时钟对音频数据进行采样。19.一种设备,其包括:接口系统,其经配置用于从环境中的多个麦克风中的每一麦克风接收输出信号,所述多个麦克风中的至少两个麦克风被包含在所述环境中的单独位置处的单独装置中,所述输出信号对应于用户的当前话语;及控制系统,其经配置用于:从每一麦克风的所述输出信号确定多个当前声学特征;将分类器应用于所述多个当前声学特征,其中应用所述分类器涉及应用针对先前确定的声学特征进行训练的模型,所述先前确定的声学特征源自所述用户在所述环境中的多个用户区中说出的多个先前话语,其中所述模型将所述环境中的所述多个用户区与所述多个声学特征关联,其中所述分类器的输出提供所述用户当前所在的所述用户区的估计,其中所述当前话语及所述先前话语包括唤醒词话语,且所述声学特征包含唤醒词置信度度量及/或唤醒词持续时间度量。20.一种系统,其经配置以执行根据权利要求1到18中任一权利要求所述的方法。21.一种或多种非暂时性媒体,其具有存储在其上的软件,所述软件包含用于控制一或多个装置以执行根据权利要求1到18中任一权利要求所述的方法的指令。22.一种训练方法,其包括:提示用户在环境的第一用户区内的多个位置中的每一者中说出至少一次训练话语;从所述环境中的多个麦克风中的每一者接收第一输出信号,所述多个麦克风中的至少两个麦克风被包含在所述环境中的单独位置处的单独装置中,所述第一输出信号对应于从所述第一用户区接收的所检测的训练话语的例项;从所述第一输出信号中的每一者确定第一声学特征;及训练分类器模型以在所述第一用户区与所述第一声学特征之间进行关联,其中所述分类器模型是在不参考所述多个麦克风的几何位置的情况下训练的。23.根据权利要求22所述的训练方法,其中所述训练话语包括唤醒词话语。24.根据权利要求23所述的训练方法,其中所述第一声学特征包括归一化唤醒词置信度、归一化平均接收电平或最大接收电平中的一或多者。
25.根据权利要求22到24中任一权利要求所述的训练方法,其进一步包括:提示用户在所述环境的第二到第k个用户区内的多个位置中的每一者中说出所述训练话语;从所述环境中的多个麦克风中的每一者接收第二到第h个输出信号,所述第二到第h个输出信号分别对应于从所述第二到第k个用户区接收的所检测的训练话语的例项;从所述第二到第h个输出信号中的每一者确定第二到第g个声学特征;及训练所述分类器模型以分别在所述第二到第k个用户区与所述第二到第g个声学特征之间进行关联。26.根据权利要求22到25中任一权利要求所述的方法,其中所述多个麦克风中的第一麦克风根据第一采样时钟对音频数据进行采样,且所述多个麦克风中的第二麦克风根据第二采样时钟对音频数据进行采样。27.一种系统,其经配置以执行根据权利要求22到26中任一权利要求所述的方法。28.一种设备,其包括:用户接口系统,其包括显示器或扬声器中的至少一者;及控制系统,其经配置用于:控制所述用户接口系统用于提示用户在环境的第一用户区内的多个位置中的每一者中说出至少一次训练话语;从所述环境中的多个麦克风中的每一者接收第一输出信号,所述多个麦克风中的至少两个麦克风被包含在所述环境中的单独位置处的单独装置中,所述第一输出信号对应于从所述第一用户区接收的所检测的训练话语的例项;从所述第一输出信号中的每一者确定第一声学特征;及训练分类器模型以在所述第一用户区与所述第一声学特征之间进行关联,其中所述分类器模型是在不参考所述多个麦克风的几何位置的情况下训练的。
技术总结
一种用于估计用户在环境中的位置的方法可涉及从所述环境中的多个麦克风中的每一麦克风接收输出信号。所述多个麦克风中的至少两个麦克风可被包含在所述环境中的单独位置处的单独装置中,且所述输出信号可对应于用户的当前话语。所述方法可涉及从每一麦克风的所述输出信号确定多个当前声学特征,及将分类器应用于所述多个当前声学特征。应用所述分类器可涉及应用针对先前确定的声学特征进行训练的模型,所述先前确定的声学特征源自由所述用户在所述环境中的多个用户区中说出的多个先前话语。所述方法可涉及至少部分地基于来自所述分类器的输出确定所述用户当前所在的所述用户区的估计。户区的估计。户区的估计。
技术研发人员:M
受保护的技术使用者:杜比实验室特许公司
技术研发日:2020.07.28
技术公布日:2022/4/26
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。