1.本发明属于网络安全技术领域,尤其涉及一种基于交叉指纹分析的公共组件库精确版本识别方法及系统。
背景技术:
2.现有的公共组件库检测技术,根据检测的精度和速度差异,主要包括白名单、相似性检测、聚类以及机器学习等方法。
3.基于白名单的公共组件库检测技术,常用的方法是人工辅助创建一个使用组件名称构成的数据库,通过比较目标文件名与数据库中的组件名,确定应用程中是否含有公共组件库。使用特征单一且基础,所以该技术检测速度非常快,但是存在两个明显的缺陷:1)组件种类覆盖率低;2)不能对抗含有名称混淆的程序。
4.相似性检测的检测技术需要对构建指纹特征库的数据源有先验的了解,即可先验数据源。其步骤通常为:1)获取源数据并从中提取指定的一个或一组特征; 2)提取的特征进行数据清洗,删除特征中冗余数据并赋予每种特征不同的权重,组构建指纹特征库;3)从目标文件中提取指定的特征组,使用相似度匹配算法计算目标文件与特征库中指纹的相似度,并给匹配结果。
5.聚类检测技术常用做法是,确定聚类所使用的特征,使用特征对解耦后的模块文件进行聚类识别,然后将识别的特征和结果存放到数据库中作为特征匹配的数据源,进而对目标文件进行识别。使用聚类技术存在以下前提:1)在无法明确主程序的情况下默认,解耦所获得的所有模块文件均为具有潜在危险的第三方组件;2)聚类处理的应用越多,数据库中的结果就越具备权威性,所以使用聚类方法的数据源通常具有上千个应用;3)使用聚类技术不需要有对数据源数据的先验知识。
6.基于机器学习技术来检测第三方组件时,通常会使用大量的已有的训练数据,根据指定的功能和特征,对目标模型进行训练,最终是模型具备更强大的功能。
7.然而,上述的公共组件库识别方法更适用于识别组件库的种类,针对具体的公共组件库漏洞,往往需要定位到组件库的具体版本,在此情形下,上述的检测技术已经难以适用于新的需求。
8.具体地,已有的公共组件识别技术,通过使用单一的特征,对组件库的种类进行识别,所使用的方法从白名单到机器学习都是区分组件库种类间的差异,由于开发的人员、风格以及开发环境的不同,所以不同种类的组件库之间的差异较大,容易进行区分。但是同种类别的组件库的不同版本,尤其是超近距离的版本,其开发人员、风格以及环境通常是相同的,而且由于版本距离较近,所以经常面临版本与版本之间的差距较小,例如只是对上一个版本所存在的漏洞打补丁,使用先前的方法提取到的特征极有可能是完全相同的,所以现有的识别技术并不能很好地完成组件版本的识别工作。
技术实现要素:
9.本发明针对已有的公共组件识别技术只能够识别公共组件库种类的问题,提出一种基于交叉指纹分析的公共组件库精确版本识别方法及系统,通过从源代码中提取字符串常量及导出函数列表,并且利用相应二进制特征数据进行反向增强训练的方法构建公共组件特征指纹数据库,增强同类不同版本间的公共组件库指纹差异,从而克服先前方法只能够识别公共组件库种类的缺陷,达到识别公共组件库精确版本的要求。
10.为了实现上述目的,本发明采用以下技术方案:
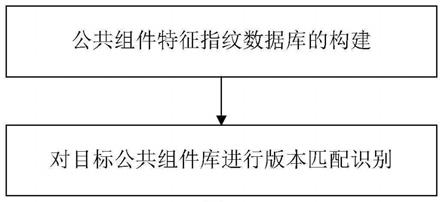
11.本发明一方面提出一种基于交叉指纹分析的公共组件库精确版本识别方法,包括:
12.公共组件特征指纹数据库的构建;包括:通过爬虫爬取开源平台以及公共组件库官网中的所有公共组件库历史版本的源代码;提取源代码中不同版本公共组件库的字符串常量及导出函数列表,将字符串常量划分成版权信息、调试信息、函数名以及其他字符常量,将导出函数列表及清洗过的字符串常量作为指纹数据存储到特征指纹数据库中;将特征指纹数据库中的指纹数据作为主体指纹,并提取收集到的真实环境中编译后的二进制公共组件库中对应的指纹数据,使用二进制公共组件库的指纹数据对特征指纹数据库进行反向增强训练;
13.对目标公共组件库进行版本匹配识别;包括:从目标二进制公共组件库中提取字符串常量以及导出函数列表,将清洗过的目标二进制公共组件库的字符串常量以及导出函数列表与特征指纹数据库中的数据进行匹配,通过导出函数列表判断待识别公共组件库的种类,通过带权重的字符串常量匹配公共组件库的精确版本,并输出最终的识别结果。
14.进一步地,按照如下方式对字符串常量进行划分:
15.提取源代码中所有的非注释可打印字符串,并把其中带有copyright、库名和版本组合的字符串定义为版权信息,将代码中含有error、debug、warning调试特征的字符串定义为调试信息,并提取源代码中所有的函数名,其余字符串归类为其他字符常量。
16.进一步地,按照如下方式对导出函数列表进行提取:
17.对于存在导出函数关键字的情况,使用类预处理的方式加载所有可能存在关键字的文件,然后进行宏定义消除,找到公共组件库的导出函数列表;
18.对于不存在导出函数关键字的情况,通过构造正则表达式进行导出函数列表的提取。
19.进一步地,按照如下方式对字符串常量进行清洗:
20.删除源代码和二进制代码中提取出的长度小于12的字符串。
21.进一步地,通过导出函数列表判断组件库的种类,匹配规则如下:
22.m(efpools,ef
(target)
)=candidate_class
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0023][0024]
其中m()表示匹配函数,candidate_class表示同类别版本相近的公共组件库, efpools表示以类为单位的导出函数列表池,ef(target)表示目标二进制公共组件库中的导出函数列表,ef(candidate_class_n)表示candidate_class中第n个候选公共组件库的导出函数列表,ef_similarity表示目标二进制公共组件库中的导出函数列表与特征指纹
数据库中第n个候选公共组件库的导出函数列表的相似度。
[0025]
进一步地,在进行公共组件库的精确版本识别时,使用字符串常量的特征作为匹配特征,赋予不同类型字符串常量以不同的权重,其权重的计算公式为:
[0026]
st_weight=st_effective
×
stc_retention
ꢀꢀꢀꢀ
(4)
[0027]
其中,st_effective表示字符串常量的类别在判断具体版本时的有效程度, stc_retention表示字符串常量的类别在编译过程中的保留程度,st_weight表示字符串常量的类别权重;
[0028]
在匹配过程中所使用的字符串常量为目标二进制公共组件库中的字符串常量与特征指纹数据库中的字符串常量的交集,即:
[0029]
string_pool=sl
(database_n)
∩sl
(target)
ꢀꢀꢀꢀꢀꢀ
(5)
[0030]
其中string_pool为目标二进制公共组件库与特征指纹数据库中重合字符串常量的集合,sl
(database_n)
、sl
(target)
分别表示特征指纹数据库中的字符串常量集合、目标二进制公共组件库中的字符串常量集合,因此string_pool中的字符串常量的权重之和sum
(string_pool)
为:
[0031][0032]
其中len(string_pool)表示string_pool中的字符串常量个数,st_weight(i) 表示string_pool中第i个字符串常量的类别权重;
[0033]
最终的相似度为sum
(string_pool)
与特征指纹数据库中的字符串常量的权重之和sum
(database_n)
的比值,其计算方式如下:
[0034][0035]
通过计算目标二进制公共组件库与特征指纹数据库中各候选公共组件库中特征的相似度lib_similarity,把相似度结果最高的候选公共组件库作为结果输出。
[0036]
本发明另一方面还一种基于交叉指纹分析的公共组件库精确版本识别系统,包括:
[0037]
公共组件特征指纹数据库构建模块,用于公共组件特征指纹数据库的构建;包括:通过爬虫爬取开源平台以及公共组件库官网中的所有公共组件库历史版本的源代码;提取源代码中不同版本公共组件库的字符串常量及导出函数列表,将字符串常量划分成版权信息、调试信息、函数名以及其他字符常量,将导出函数列表及清洗过的字符串常量作为指纹数据存储到特征指纹数据库中;将特征指纹数据库中的指纹数据作为主体指纹,并提取收集到的真实环境中编译后的二进制公共组件库中对应的指纹数据,使用二进制公共组件库的指纹数据对特征指纹数据库进行反向增强训练;
[0038]
目标公共组件库版本匹配识别模块,用于对目标公共组件库进行版本匹配识别;包括:从目标二进制公共组件库中提取字符串常量以及导出函数列表,将清洗过的目标二进制公共组件库的字符串常量以及导出函数列表与特征指纹数据库中的数据进行匹配,通过导出函数列表判断待识别公共组件库的种类,通过带权重的字符串常量匹配公共组件库的精确版本,并输出最终的识别结果。
[0039]
进一步地,按照如下方式对字符串常量进行划分:
[0040]
提取源代码中所有的非注释可打印字符串,并把其中带有copyright、库名和版本组合的字符串定义为版权信息,将代码中含有error、debug、warning调试特征的字符串定义为调试信息,并提取源代码中所有的函数名,其余字符串归类为其他字符常量。
[0041]
进一步地,按照如下方式对导出函数列表进行提取:
[0042]
对于存在导出函数关键字的情况,使用类预处理的方式加载所有可能存在关键字的文件,然后进行宏定义消除,找到公共组件库的导出函数列表;
[0043]
对于不存在导出函数关键字的情况,通过构造正则表达式进行导出函数列表的提取。
[0044]
进一步地,按照如下方式对字符串常量进行清洗:
[0045]
删除源代码和二进制代码中提取出的长度小于12的字符串。
[0046]
进一步地,通过导出函数列表判断组件库的种类,匹配规则如下:
[0047]
m(efpools,ef
(target)
)=candidate_class
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0048][0049]
其中m()表示匹配函数,candidate_class表示同类别版本相近的公共组件库, efpools表示以类为单位的导出函数列表池,ef(target)表示目标二进制公共组件库中的导出函数列表,ef(candidate_class_n)表示candidate_class中第n个候选公共组件库的导出函数列表,ef_similarity表示目标二进制公共组件库中的导出函数列表与特征指纹数据库中第n个候选公共组件库的导出函数列表的相似度。
[0050]
进一步地,在进行公共组件库的精确版本识别时,使用字符串常量的特征作为匹配特征,赋予不同类型字符串常量以不同的权重,其权重的计算公式为:
[0051]
st_weight=st_effective
×
stc_retention
ꢀꢀꢀꢀ
(4)
[0052]
其中,st_effective表示字符串常量的类别在判断具体版本时的有效程度,stc_retention表示字符串常量的类别在编译过程中的保留程度,st_weight表示字符串常量的类别权重;
[0053]
在匹配过程中所使用的字符串常量为目标二进制公共组件库中的字符串常量与特征指纹数据库中的字符串常量的交集,即:
[0054]
string_pool=sl
(database_n)
∩sl
(target)
ꢀꢀꢀꢀꢀꢀ
(5)
[0055]
其中string_pool为目标二进制公共组件库与特征指纹数据库中重合字符串常量的集合,sl
(database_n)
、sl
(target)
分别表示特征指纹数据库中的字符串常量集合、目标二进制公共组件库中的字符串常量集合,因此string_pool中的字符串常量的权重之和sum
(string_pool)
为:
[0056][0057]
其中len(string_pool)表示string_pool中的字符串常量个数,st_weight(i) 表示string_pool中第i个字符串常量的类别权重,tf-idf(i)表示第i个字符串常量的tf-idf值;
[0058]
最终的相似度为sum
(string_pool)
与特征指纹数据库中的字符串常量的权重之和sum
(database_n)
的比值,其计算方式如下:
[0059][0060]
通过计算目标二进制公共组件库与特征指纹数据库中各候选公共组件库中特征的相似度lib_similarity,把相似度结果最高的候选公共组件库作为结果输出。
[0061]
与现有技术相比,本发明具有的有益效果:
[0062]
本发明以字符串和函数信息两个大的特征为基础,通过对两个特征进行角色的分类以及权重赋予,使得其在不同版本之间的识别工作上,展现出了更强的差异性,从而使得近距离版本识别工作得以进行,并且通过使用真实环境中的二进制公共组件库的特征进行反向增强,进一步增加了版本识别的准确性。除此以外本发明通过两种粒度的匹配模式,在提升了可扩展性的同时,提高了识别的精度和速度。
附图说明
[0063]
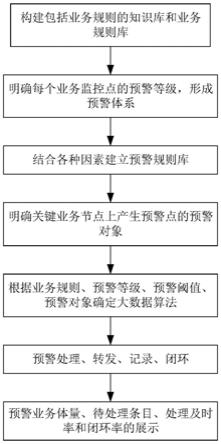
图1为本发明实施例一种基于交叉指纹分析的公共组件库精确版本识别方法的基本流程图;
[0064]
图2为源代码字符串角色图;
[0065]
图3为导出函数在编译后的保留程度;
[0066]
图4为调试信息在编译后的保留程度;
[0067]
图5为源代码函数在二进制公共组件库字符中的占比;
[0068]
图6为不同长度字符串占比;
[0069]
图7为删除定长字符串后的字符串重合度情况;
[0070]
图8为数据库结构图;
[0071]
图9为本发明实施例一种基于交叉指纹分析的公共组件库精确版本识别系统的架构示意图。
具体实施方式
[0072]
下面结合附图和具体的实施例对本发明做进一步的解释说明:
[0073]
如图1所示,一种基于交叉指纹分析的公共组件库精确版本识别方法,包括:
[0074]
公共组件特征指纹数据库的构建;包括:通过爬虫爬取开源平台以及公共组件库官网中的所有公共组件库历史版本的源代码;提取源代码中不同版本公共组件库的字符串常量及导出函数列表,将字符串常量划分成版权信息、调试信息、函数名以及其他字符常量,将导出函数列表及清洗过的字符串常量作为指纹数据存储到特征指纹数据库中;将特征指纹数据库中的指纹数据作为主体指纹,并提取收集到的真实环境中编译后的二进制公共组件库中对应的指纹数据,使用二进制公共组件库的指纹数据对特征指纹数据库进行反向增强训练;
[0075]
对目标公共组件库进行版本匹配识别;包括:从目标二进制公共组件库中提取字符串常量以及导出函数列表,将清洗过的目标二进制公共组件库的字符串常量以及导出函数列表与特征指纹数据库中的数据进行匹配,通过导出函数列表判断待识别公共组件库的
种类,通过带权重的字符串常量匹配公共组件库的精确版本,并输出最终的识别结果。
[0076]
具体地,在公共组件特征指纹数据库的构建阶段,使用python开发了一个多线程源代码采集器,该采集器通过github的graphql api或者公共组件库(基础库)官网(不同种类的公共组件库的官网,如freeimage的官网the freeimageproject(sourceforge.io)等)的下载信息获取公共组件库的所有历史版本信息,并调用linux中的wget工具进行多线程下载公共组件库源代码。
[0077]
具体地,本发明下载了联想应用商店平台中下载量超过50,000的软件,将下载的软件进行安装操作,并且提取安装路径中所有的二进制文件形式的公共组件库,然后根据特定库(特征指纹数据库中对应公共组件库历史版本)的版权信息对提取的二进制文件形式的公共组件库进行版本识别,并且使用ida pro对这些二进制文件中的字符串和函数的特征进行提取,然后以《库名,版本,二进制文件公共组件库指纹》的标签形式记录下来。然后使用这些标签对特征指纹数据库中的数据进行反向增强训练。反向增强训练的具体操作是,把标签中存在但是特征指纹数据库中没有的数据添加到特征指纹数据库中。
[0078]
考虑到编译和优化对特征的影响,我们做对比实验来决定使用的特征。
[0079][0080]
如公式(1)所示,源代码在编译过程中,其特征会有不同程度的变异或者磨损,并且可能会产生新的特征,这些信息受编译优化、混淆的程度以及平台等环境不同而造成较大差异。公式(1)中,ff,ef,sfn(n=1,2,
……
)指代源代码中不同类型的特征,ff
′
,ef
′
,sfn
′
指代经过磨损或者变异的特征,nfn指代编译后产生的新的特征。
[0081]
根据字符串常量的特征以及在编译中的表现,把源代码中的字符串常量分为如图2所示的角色。其中,版权信息由于携带的版本识别信息非常关键,且在版本之间出现的频率差异巨大,所以纳入了特征采集的范畴。
[0082]
该实验通过随机抽样调查41806个真实的公共组件库,抽取特征指纹数据库中对应的候选公共组件库进行测试。实验发现导出函数在编译过程中的平均存留程度达到了86.93%(如图3所示),调试信息的保留程度70.52%(如图4所示)。
[0083]
此外通过实验调查,即使用专业反汇编工具ida对二进制公共组件库进行字符串提取后,发现其中出现了比例不低的函数名,平均占比达到22.52%,结果如图5所示,因此把源代码中提取的函数名归类为字符串信息,最终字符串常量被划分为版权信息、调试信息、函数名以及其他字符常量四种类别。
[0084]
所以本实验中使用导出函数列表进行粗粒度识别公共组件库的种类,进而使用字符串常量来识别基础库的具体版本。
[0085]
进一步地,按照如下方式对字符串常量进行划分:
[0086]
提取源代码中所有的非注释可打印字符串,并把其中带有'copyright'以及库名和版本组合的字符串定义为版权信息,将代码中含所有error、debug、warning 等调试特征的字符串定义为调试信息,其余字符串归类为其他,并提取代码中所有的函数名。
[0087]
进一步地,按照如下方式对导出函数列表进行提取:
[0088]
导出函数列表的提取方式主要有两种:关键字识别递归提取和特殊格式提取。关
键字识别递归是指存在'__declspec(dllexport)'等导出函数关键字的情况,一般通过宏定义指代,例如zlib库中的zexport,这种情况使用类预处理的方式加载所有可能存在关键字的文件,然后进行宏定义消除,找到库导出列表。特殊格式提取是指不存在导出函数关键字,一般出现在库早期的历史版本中,这种情况下导出函数可能存在extern前缀或者存在于配置文件的固定区域,需要构造正则表达式进行提取。
[0089]
进一步地,按照如下方式对字符串常量进行清洗:
[0090]
初步提取的字符串常量,存在很多冗余,匹配精度低,因此需要对其进行清洗,提高其有效程度。本专利对分类后的字符串进行了精简,即删除掉不可能通过编译或者无效程度较高的元素,例如仅仅出现在源代码中,并且不会参与编译的字符串常量等。根据实验对比源代码和二进制代码中的字符串,带有'
‑‑
','.h', '.c','.cpp','《filename:》'的字符串不会通过编译器,带有制表符或者换行符等元素的字符串在二进制代码中会被再次转义或者拆分。最后本专利删除了源代码和二进制代码中提取出的长度小于12的字符串,通过实验分析,长度小于12的字符串存在较大的冗余,并且容易在不同库之间重复出现,有效程度低。本专利统计了数据集中的源代码和二进制代码中的不同长度的字符串占比,其结果如图6 所示,长度较小的字符串均含有较高的占比。为了验证其有效程度,本专利设计了一个实验,通过删除不同长度的字符串来测量源代码和二进制代码中的字符串的重合程度,其结果如图7所示,在删除掉长度小于12的字符时,代码的重合度达到了最高值,因此本专利设定删除短小字符串的值为12。
[0091]
具体地,主要存储两种主要的数据,所有历史版本公共组件库的源代码及相关信息,以及所有公共组件库的特征指纹数据库。采用“文件系统 数据库”的方式存储源代码,特征指纹数据库使用mysql数据库进行存储,数据结构如图8 所示。
[0092]
具体地,需要存储公共组件库项目的各项信息,为了优化匹配查找的速度,首先需要把待存储的信息分为项目源码信息、常用匹配信息以及后备存储信息三种。项目源码信息包括项目的id,名称、版本、本地地址、平台地址、项目类别等信息。其中前三项信息与常用匹配信息的前三项对应,常用匹配信息表中字符串md5列表以及字符串类型列表均来自于后备存储信息表中。这种存储结构根据信息的性质和使用频率进行分类,可以在存储大量信息的前提下保持较高的查询速度。
[0093]
进一步地,本专利设计了一套匹配算法用来计算目标公共组件库对应的二进制公共组件库与特征指纹数据库中的候选公共组件库之间的相似度。
[0094]
在粗粒度阶段,使用导出函数列表作为筛选特征,可以快速排除掉不同种类的候选公共组件库以及同类库的差异较大的版本。匹配规则如下:
[0095]
m(efpools,ef
(target)
)=candidate_class
ꢀꢀꢀꢀꢀꢀꢀ
(2)
[0096][0097]
其中m()表示匹配函数,candidate_class表示同类别版本相近的公共组件库 (匹配的结果),efpools表示以类为单位的导出函数列表池,ef(target)表示目标二进制公共组件库中的导出函数列表,ef(candidate_class_n)表示 candidate_class中第n个候选公共组件库的导出函数列表,ef_similarity表示目标二进制公共组件库中的导出函数列表与特征指纹数据库中第n个候选公共组件库的导出函数列表的相似度。
[0098]
粗粒度阶段分为两个步骤,第一步是通过导出函数序列池,筛选出目标二进制公共组件库对应的候选公共组件库类,第二步使目标二进制公共组件库与候选公共组件库的导出函数列表进行相似度匹配,对该相似度设定阈值,其匹配结果超过阈值的匹配指定为最终候选公共组件库。
[0099]
在细粒度阶段,使用字符串常量的特征作为匹配特征,赋予不同类型字符串常量以不同的权重,其权重的计算公式为:
[0100]
st_weight=st_effective
×
stc_retention
ꢀꢀꢀꢀ
(4)
[0101]
其中,st_effective表示字符串常量的类别在判断具体版本时的有效程度, stc_retention表示字符串常量的类别在编译过程中的保留程度,st_weight表示字符串常量的类别权重。
[0102]
并且计算过程中所使用的字符串常量为目标二进制公共组件库中的字符串常量与特征指纹数据库中的字符串常量的交集,即:
[0103]
string_pool=sl
(database_n)
∩sl
(target)
ꢀꢀꢀꢀꢀ
(5)
[0104]
其中string_pool为目标二进制公共组件库与特征指纹数据库中重合字符串常量的集合,sl
(database_n)
、sl
(target)
分别表示特征指纹数据库中的字符串常量集合、目标二进制公共组件库中的字符串常量集合,因此string_pool中的字符串常量的权重之和sum
(string_pool)
为:
[0105][0106]
其中len(string_pool)表示string_pool中的字符串常量个数,st_weight(i) 表示string_pool中第i个字符串常量的类别权重,tf-idf(i)表示第i个字符串常量的tf-idf值(即采用tf-idf算法,根据字符串在特征指纹数据库中出现的频率赋予其权重);
[0107]
最终的相似度为sum
(string_pool)
与特征指纹数据库中的字符串常量的权重之和sum
(database_n)
的比值,其计算方式如下:
[0108][0109]
sum
(database_n)
具体等于特征指纹数据库中所有字符串的权重相加。
[0110]
通过计算目标二进制公共组件库与特征指纹数据库中各候选公共组件库中特征的相似度lib_similarity,把相似度结果最高的候选公共组件库作为结果输出。
[0111]
在上述实施例的基础上,如图9所示,本发明还一种基于交叉指纹分析的公共组件库精确版本识别系统,包括:
[0112]
公共组件特征指纹数据库构建模块,用于公共组件特征指纹数据库的构建;包括:通过爬虫爬取开源平台以及公共组件库官网中的所有公共组件库历史版本的源代码;提取源代码中不同版本公共组件库的字符串常量及导出函数列表,将字符串常量划分成版权信息、调试信息、函数名以及其他字符常量,将导出函数列表及清洗过的字符串常量作为指纹数据存储到特征指纹数据库中;将特征指纹数据库中的指纹数据作为主体指纹,并提取收集到的真实环境中编译后的二进制公共组件库中对应的指纹数据,使用二进制公共组件库的指纹数据对特征指纹数据库进行反向增强训练;
[0113]
目标公共组件库版本匹配识别模块,用于对目标公共组件库进行版本匹配识别;包括:从目标二进制公共组件库中提取字符串常量以及导出函数列表,将清洗过的目标二进制公共组件库的字符串常量以及导出函数列表与特征指纹数据库中的数据进行匹配,通过导出函数列表判断待识别公共组件库的种类,通过带权重的字符串常量匹配公共组件库的精确版本,并输出最终的识别结果。
[0114]
进一步地,按照如下方式对字符串常量进行划分:
[0115]
提取源代码中所有的非注释可打印字符串,并把其中带有copyright、库名和版本组合的字符串定义为版权信息,将代码中含有error、debug、warning调试特征的字符串定义为调试信息,其余字符串归类为其他字符常量,并提取源代码中所有的函数名。
[0116]
进一步地,按照如下方式对导出函数列表进行提取:
[0117]
对于存在导出函数关键字的情况,使用类预处理的方式加载所有可能存在关键字的文件,然后进行宏定义消除,找到公共组件库的导出函数列表;
[0118]
对于不存在导出函数关键字的情况,通过构造正则表达式进行导出函数列表的提取。
[0119]
进一步地,按照如下方式对字符串常量进行清洗:
[0120]
删除源代码和二进制代码中提取出的长度小于12的字符串。
[0121]
进一步地,通过导出函数列表判断组件库的种类,匹配规则如下:
[0122]
m(efpools,ef
(target)
)=candidate_class
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0123][0124]
其中m()表示匹配函数,candidate_class表示同类别版本相近的公共组件库, efpools表示以类为单位的导出函数列表池,ef(target)表示目标二进制公共组件库中的导出函数列表,ef(candidate_class_n)表示candidate_class中第n个候选公共组件库的导出函数列表,ef_similarity表示目标二进制公共组件库中的导出函数列表与特征指纹数据库中第n个候选公共组件库的导出函数列表的相似度。
[0125]
进一步地,在进行公共组件库的精确版本识别时,使用字符串常量的特征作为匹配特征,赋予不同类型字符串常量以不同的权重,其权重的计算公式为:
[0126]
st_weight=st_effective
×
stc_retention
ꢀꢀꢀꢀ
(4)
[0127]
其中,st_effective表示字符串常量的类别在判断具体版本时的有效程度, stc_retention表示字符串常量的类别在编译过程中的保留程度,st_weight表示字符串常量的类别权重;
[0128]
在匹配过程中所使用的字符串常量为目标二进制公共组件库中的字符串常量与特征指纹数据库中的字符串常量的交集,即:
[0129]
string_pool=sl
(database_n)
∩sl
(target)
ꢀꢀꢀꢀꢀꢀ
(5)
[0130]
其中string_pool为目标二进制公共组件库与特征指纹数据库中重合字符串常量的集合,sl
(database_n)
、sl
(target)
分别表示特征指纹数据库中的字符串常量集合、目标二进制公共组件库中的字符串常量集合,因此string_pool中的字符串常量的权重之和sum
(string_pool)
为:
[0131][0132]
其中len(string_pool)表示string_pool中的字符串常量个数,st_weight(i) 表示string_pool中第i个字符串常量的类别权重,tf-idf(i)表示第i个字符串常量的tf-idf值;
[0133]
最终的相似度为sum
(string_pool)
与特征指纹数据库中的字符串常量的权重之和sum
(database_n)
的比值,其计算方式如下:
[0134][0135]
通过计算目标二进制公共组件库与特征指纹数据库中各候选公共组件库中特征的相似度lib_similarity,把相似度结果最高的候选公共组件库作为结果输出。
[0136]
综上,本发明将重心放在公共组件库版本识别的工作上,由于导出函数具有不同种类的公共组件库差异非常大、而同类型的公共组件库版本之间的变化较小的特点,所以本发明使用导出函数列表来判断组件库的种类,然后使用版本之间的差异性数据,进行精确的版本识别,识别所使用的特征,根据其角色,频率以及所携带信息的重要性,赋予其不同的权重,例如版权信息,由于其直接携带版本信息,出现频率较小以及版本之间几乎没有重合而得到了较大的权重;而注释信息则会被直接删除掉。
[0137]
本发明对公共组件库进行精确的版本识别主要通过从公共组件库源代码中提取具有识别性的特征指纹,然后通过提取编译后的同版本二进制代码中的相同指纹进行逆向补充,增强对相近版本的组件库的差异性识别。通过使用粗细两种粒度的指纹进行识别,使用导出函数列表进行组件库种类识别,通过分类字符串常量进行精确的版本识别,以确保识别的精确度和可扩展性。
[0138]
本发明以字符串和函数信息两个大的特征为基础,通过对两个特征进行角色的分类以及权重赋予,使得其在不同版本之间的识别工作上,展现出了更强的差异性,从而使得近距离版本识别工作得以进行,并且通过使用真实环境中的二进制库的特征进行反向增强,进一步增加了版本识别的准确性。除此以外本发明通过两种粒度的匹配模式,在提升了可扩展性的同时,提高了识别的精度和速度。
[0139]
以上所示仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。