技术特征:
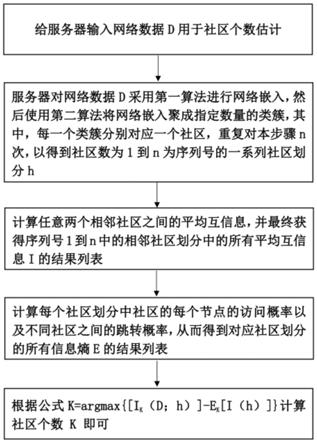
1.一种复杂网络中社区个数估计方法,其特征在于,该方法包括如下步骤:1.1、给服务器输入网络数据d用于社区个数估计;1.2、服务器对网络数据d采用第一算法进行网络嵌入,然后使用第二算法将网络嵌入聚成指定数量的类簇,其中,每一个类簇分别对应一个社区,重复对本步骤n次,以得到社区数为1到n为序列号的一系列社区划分h;1.3、计算任意两个相邻社区之间的平均互信息,并最终获得序列号1到n中的相邻社区划分中的所有平均互信息i的结果列表;1.4、计算每个社区划分中社区的每个节点的访问概率以及不同社区之间的跳转概率,从而得到对应社区划分的所有信息熵e的结果列表;1.5、根据如下公式计算社区个数k即可,公式如下:k=argmax{[i
k
(d;h)]-e
k
[i(h)]}
ꢀꢀꢀꢀꢀ
公式(1)在公式(1)中,i
k
(d;h)为i的结果列表的序列号为k时的最大平均互信息,e
k
[i(h)]为e的结果列表的序列号为k时的最小信息熵。2.根据权利要求1所述的一种复杂网络中社区个数估计方法,其特征在于:在步骤1.2中,预先定义初始化计数为i,聚类结果集为p,并且,初始化计数值i=0,聚类次数为n,所述步骤1.2还包括:1.2.1、将初始化计数值i与聚类次数n进行比对,当i大于或者等于n时,执行步骤1.3;当i小于n时,执行如下步骤:1.2.2、服务器对网络数据d采用第一算法进行网络嵌入;1.2.3、通过第二算法将步骤1.2.2的网络嵌入聚成i 1类的类簇,从而得到数量为i 1的聚类结果集p,并以此循环,进而得到社区数为1到n为序列号的一系列社区划分h的聚类结果集p。3.根据权利要求2所述的一种复杂网络中社区个数估计方法,其特征在于:在步骤1.3中,令i=0,准备计算社区数为1到n为序列号的一系列社区划分h的相邻划分间的平均互信息i的结果列表i1、i2......i
n
,将i与n-1进行比对:1.3.1、当i大于或者等于n-1时,得到最终的平均互信息i的结果列表,执行步骤1.4;1.3.2、当i小于n-1时,计算相邻两个社区划分之间的平均互信息,并以此循环,进而获得序列号1到n的社区划分h的最终平均互信息i的结果列表,再执行步骤1.4。4.根据权利要求3所述的一种复杂网络中社区个数估计方法,其特征在于:在步骤1.3中,从社区数为1到n为序列号的一系列社区划分h的聚类结果集p提取任意节点数据,通过如下公式计算平均互信息i:ω
ij
=p(x
i
,y
j
)
ꢀꢀꢀꢀꢀꢀ
公式(3)其中,i(xi;yj)为社区xi和社区yj的互信息,p(xi,yj)为社区xi和社区yj的关联性,n
为网络中节点总数,为社区xi和社区yj共同节点的数量。5.根据权利要求3所述的一种复杂网络中社区个数估计方法,其特征在于:在步骤1.4中,其还包括如下步骤:1.4.1、通过预设的随机游走算法来计算每个划分社区h的每个节点的转移概率矩阵m;1.4.2、令i=0,准备利用各转移概率矩阵m内的每个划分社区的每个节点的访问概率以及不同划分社区之间的跳转概率进行计算,从而得到序列号1到n的划分社区h的信息熵e的结果列表e1、e2......e
n
;1.4.3、将i与n进行比对,当i大于或者等于n时,执行步骤1.5,反之,当i小于n时,计算每个社区划分h的信息熵,以此循环,进而获得序列号1到n的划分社区h的最终信息熵e结果列表,再执行步骤1.5。6.根据权利要求5所述的一种复杂网络中社区个数估计方法,其特征在于:在步骤1.4.1中,其还包括如下步骤:1.4.1.1、给定网络g=(v,e),将网络中的边表示为其中节点u,v∈v;1.4.1.2、定义节点u的邻居为1.4.1.3、设源节点为u,目标节点为v,从节点u跳转到节点v的转移概率矩阵m为如果v∈n(a),则否则7.根据权利要求6所述的一种复杂网络中社区个数估计方法,其特征在于:在步骤1.4.2中,其还包括如下步骤:1.4.2.1、分别以网络g=(v,e)中的每个节点为源节点作n次长度为l的随机游走,设节点u的游走序列集合为其中,表示第i次随机游走所得的节点序列,则网络g=(v,e)总的随机游走序列集合为s={s
u
|u∈v};1.4.2.2、设节点u在中出现的次数为则节点u在s中出现的次数为因此,节点u的访问概率被定义为1.4.2.3、以社区i为例,社区跳转概率定义为8.根据权利要求7所述的一种复杂网络中社区个数估计方法,其特征在于:在步骤1.4.3中,从社区数为1到n为序列号的一系列社区划分h的聚类结果集p提取任意节点数据,通过如下公式计算信息熵e:通过如下公式计算信息熵e:
其中,为在网络中进行充分的随机游走过后节点α的出现概率,即在所有游走序列中节点α出现的次数与序列中所有节点出现次数的总和之比;为网络中社区i的出现概率,m为社区个数,为所有社区的出现概率和,h(q)为对所有社区进行编码所需的最短平均编码长度,h(p
i
)为每个社区i内节点的最短平均编码长度,为社区i中节点的概率之和与社区i出现的概率的叠加值。9.根据权利要求8所述的一种复杂网络中社区个数估计方法,其特征在于:通过如下公式计算网络中社区i的出现概率以及所有社区的出现概率和以及所有社区的出现概率和p
α
→
β
=1/d
α
ꢀꢀꢀꢀꢀꢀꢀ
公式(11)其中,p
α
→
β
为从节点α转移到节点β的概率,d
α
为节点α的邻居数。10.根据权利要求9所述的一种复杂网络中社区个数估计方法,其特征在于:在步骤1.5中,其还包括如下步骤:1.5.1、舍弃社区个数n=1的社区划分结果,令i=1,准备计算平均互信息i的结果列表与信息熵e的结果列表相对应数据的差值,从而得到社区个数估计所需要的i-e结果列表;1.5.2、将i与n-1进行比对,当i小于n-1时,将平均互信息i的结果列表的各个平均互信息数据与信息熵e的结果列表的各个信息熵数据分别代入社区个数计算公式中,通过步骤1.5的公式(1)对各平均互信息数据以及相应的信息熵数据进行计算得出i-e的结果列表;1.5.3、当i大于或者等于n时,则在步骤1.5.2的i-e结果列表数据中得到i-e的最大值i
k-e
k
,对应的序列号k即为社区个数k。
技术总结
本发明公开了一种复杂网络中社区个数估计方法,该方法包括如下步骤:给服务器输入网络数据D用于社区个数估计;服务器对网络数据D采用第一算法进行网络嵌入,然后使用第二算法将网络嵌入聚成指定数量的类簇,重复对网络嵌入采用本步骤n次,以得到社区数为1到n为序列号的一系列社区划分h;计算任意两个相邻社区之间的平均互信息,并最终获得平均互信息I的结果列表;计算得到对应社区划分的所有信息熵E的结果列表;根据公式计算社区个数K即可。本发明具有能够通过计算最大平均互信息与最小信息熵的差值来确定复杂网络中包含的社区个数,本发明能够有效提高社区个数估计的准确度。度。度。
技术研发人员:李凝思 李东
受保护的技术使用者:李凝思
技术研发日:2022.01.18
技术公布日:2022/4/22
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。