1.本技术涉及分类模型训练技术,尤其涉及一种标签分类模型训练方法、标签分类方法、装置及设备。
背景技术:
2.用户画像的概念最早由交互设计之父alan cooper提出,他指出,用户画像就是标签化的用户模型。具体来说就是将用户信息标签化,通过收集与分析消费者社会属性、消费习惯、兴趣爱好等数据,抽象出一个用户的全景画像,以帮助企业精准定位、精准营销、预测与决策。随着信用卡用户需求日益多样化以及信用卡营销管理的精细化,用户画像逐渐被信用卡行业广泛关注。用户画像不仅可以使发卡银行实现精准获取客户、精准营销、精准运营、精准管理,而且能够在极大程度上提升客户体验。
3.构建用户画像的核心就是给客户“贴标签”,即基于大数据分析和数据挖掘技术洞察客户行为、偏好,描绘用户不同类型特征,例如“白领精英”“境外消费者”“奢侈品爱好者”等。在数字化转型背景下,信用卡行业试图通过构建客户标签体系,多维度刻画用户特征,为用户提供更好的服务。
4.现有的技术方案需要人工给用户数据贴上相应的标签,然后将用户数据和关联的标签同时作为样本,训练得到一个分类模型,再利用这个分类模型对后续用户刷信用卡产生的用户数据进行标签分类。但是因为样本数量和样本的标签类型有限,该分类模型对用户数据进行标签分类的效果不是很好。因此,如何提升对用户消费数据的标签分类效果,仍然是值得研究的。
技术实现要素:
5.本技术提供一种标签分类模型训练方法、标签分类方法、装置及设备,用以提升对用户消费数据的标签分类效果。
6.一方面,本技术提供一种标签分类模型训练方法,包括:
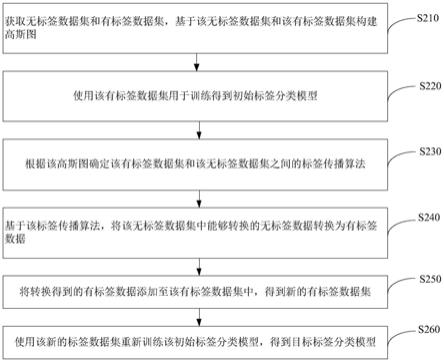
7.获取无标签数据集和有标签数据集,基于所述无标签数据集和所述有标签数据集构建高斯图;
8.使用所述有标签数据集训练得到初始标签分类模型;
9.根据所述高斯图确定所述有标签数据集和所述无标签数据集之间的标签传播算法;
10.基于所述标签传播算法,将所述无标签数据集中能够转换的无标签数据转换为有标签数据;
11.将转换得到的有标签数据添加至所述有标签数据集中,得到新的有标签数据集;
12.使用所述新的标签数据集重新训练所述初始标签分类模型,得到目标标签分类模型。
13.可选的,所述无标签数据集和所述有标签数据集中的数据均为二维数据,所述二
维数据中的第一维度数据表示消费数据,第二维度数据表示所述消费数据的标签,所述无标签数据集中的第二维度数据为空值,所述基于所述无标签数据集和所述有标签数据集构建高斯图包括:
14.基于所述无标签数据集和所述有标签数据集中的第一维度数据构建所述高斯图的顶点;
15.根据所述无标签数据集和所述有标签数据集中每个第一维度数据之间的相似性构建所述高斯图的边。
16.可选的,根据所述高斯图确定所述有标签数据集和所述无标签数据集之间的标签传播算法包括:
17.基于所述高斯图,获取关于所述高斯图中顶点和边的实值函数,所述实值函数包括无标签数据集的无标签实值函数和有标签数据集的有标签实值函数;
18.基于所述高斯图获取拉普拉丝矩阵,所述拉普拉丝矩阵包括对角矩阵和权重矩阵;
19.根据所述实值函数和所述拉普拉丝矩阵构建所述实值函数的能量函数;
20.最小化所述能量函数,得到所述无标签实值函数和所述有标签实值函数之间的关系算法,所述关系算法为所述标签传播算法。
21.可选的,所述最小化所述能量函数,得到所述无标签实值函数和所述有标签实值函数之间的关系算法为所述标签传播算法,包括:
22.根据所述对角矩阵和所述权重矩阵生成所述高斯图的转移矩阵;
23.最小化所述能量函数,得到初始关系算法,所述初始关系算法包含所述无标签实值函数、所述有标签实值函数、所述对角矩阵和所述权重矩阵;
24.以所述转移矩阵替换所述初始关系算法中的对角矩阵和权重矩阵,得到所述关系算法,所述关系算法包含所述转移矩阵、所述无标签实值函数和所述有标签实值函数。
25.可选的,所述标签传播算法的输出为无标签实值函数的值,所述基于所述标签传播算法,将所述无标签数据集中的无标签数据转换为有标签数据包括:
26.对所述无标签数据集中每个无标签数据执行以下步骤:
27.对所述无标签数据集中每个无标签数据执行以下步骤:
28.将无标签数据代入至所述标签传播算法后得到无标签实值函数的值;
29.当所述无标签实值函数的值大于预设值时,确定所述标签传播算法计算时使用的有标签实值函数中的标签为所述无标签数据的标签;
30.为所述无标签数据添加标签。
31.可选的,所述获取无标签数据集包括:
32.获取初始无标签数据集;
33.将初始无标签数据集输入至所述初始标签分类模型后,获取所述初始无标签数据集中每个无标签数据的输出与所述初始标签分类模型之间的距离向量;
34.获取所述初始无标签数据集中距离向量最小的m个无标签数据构成所述无标签数据集,m为大于零的整数。
35.另一方面,本技术提供一种标签分类方法,包括:
36.获取待进行标签分类的无标签数据;
37.将所述待进行标签分类的无标签数据输入至如第一方面所述的目标标签分类模型,得到所述待进行标签分类的无标签数据的标签。
38.另一方面,本技术提供一种标签分类模型训练装置,包括:
39.获取模块,用于获取无标签数据集和有标签数据集,基于所述无标签数据集和所述有标签数据集构建高斯图;
40.训练模块,用于使用所述有标签数据集训练得到初始标签分类模型;
41.算法确定模块,用于根据所述高斯图确定所述有标签数据集和所述无标签数据集之间的标签传播算法;
42.数据转换模块,用于基于所述标签传播算法,将所述无标签数据集中能够转换的无标签数据转换为有标签数据;
43.样本构建模块,用于将转换得到的有标签数据添加至所述标签数据集中,得到新的标签数据集;
44.所述训练模块还用于使用所述新的标签数据集重新训练所述初始标签分类模型,得到目标标签分类模型。
45.另一方面,本技术提供一种标签分类装置,包括:
46.获取模块,用于获取待进行标签分类的无标签数据;
47.处理模块,用于将所述待进行标签分类的无标签数据输入至如第一方面所述的目标标签分类模型,得到所述待进行标签分类的无标签数据的标签。
48.另一方面,本技术提供一种电子设备,包括:处理器,以及与所述处理器通信连接的存储器;
49.所述存储器存储计算机执行指令;
50.所述处理器执行所述存储器存储的计算机执行指令,以实现如第一方面所述的标签分类模型训练方法。
51.另一方面,本技术提供一种电子设备,包括:处理器,以及与所述处理器通信连接的存储器;
52.所述存储器存储计算机执行指令;
53.所述处理器执行所述存储器存储的计算机执行指令,以实现如第二方面所述的标签分类方法。
54.另一方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当所述指令被执行时,使得计算机执行如第一方面所述的标签分类模型训练方法。
55.另一方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当所述指令被执行时,使得计算机执行如第二方面所述的标签分类方法。
56.另一方面,本技术提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的标签分类模型训练方法。
57.另一方面,本技术提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如第二方面所述的标签分类方法。
58.综上,本实施例提供的标签分类模型的训练方法是一种基于主动学习和半监督学
习的信用卡用户画像方法,可以先利用svm分类器和少量有标签数据训练得到一个初始标签分类模型。再通过标签传播算法和主动学习的方法,利用无标签数据对该初始标签分类模型的性能进行优化,更加精准得刻画出用户特点,从而提供个性化服务。
59.更进一步的,svm分类器的数量和对应的标签数量、类型等都可以根据实际需要设置,标签类型例如消费类别、消费级别、消费偏好(更喜欢旅游、更喜欢美食或其他)等。因此,本实施例提供的方法得到的标签分类模型可以对用户的深层特征进行充分挖掘,了解用户的消费偏好、成长预测、流失预警等,从而可以更好的提高用户体验,提供更精准的服务。
60.本实施例的方法利用标签传播算法将无标签数据转换为有标签数据,再将转换得到的有标签数据添加至原来的有标签数据集中,利用新的有标签数据集重新训练该初始标签分类模型,得到目标标签分类模型。该目标标签分类模型相比于该初始标签分类模型而言,由于其训练样本数量更多更多样化,所以性能比该初始标签分类模型更佳。
附图说明
61.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
62.图1为本技术提供的标签分类模型训练方法的一种应用场景示意图。
63.图2为本技术的一个实施例提供的标签分类模型训练方法的流程示意图。
64.图3为本技术的另一个实施例提供的标签分类模型训练方法的示意图。
65.图4为本技术的一个实施例提供的标签分类方法的流程示意图。
66.图5为本技术的一个实施例提供的标签分类模型训练装置的示意图。
67.图6为本技术的一个实施例提供的标签分类装置的示意图。
68.图7为本技术的一个实施例提供的电子设备的示意图。
69.图8为本技术的另一个实施例提供的电子设备的示意图。
70.通过上述附图,已示出本公开明确的实施例,后文中将有更详细的描述。这些附图和文字描述并不是为了通过任何方式限制本公开构思的范围,而是通过参考特定实施例为本领域技术人员说明本公开的概念。
具体实施方式
71.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
72.下面对本技术涉及到的名词进行解释:
73.用户画像:用户画像的概念最早由交互设计之父alan cooper提出。他指出,用户画像就是标签化的用户模型。具体来说就是将用户信息标签化,通过收集与分析消费者社会属性、消费习惯、兴趣爱好等数据,对用户进行分类,抽象出一个用户的全景画像,以帮助企业精准定位、精准营销、预测与决策。
74.主动学习:主动学习是一种基于迭代思想的模型,它的基本原理是根据特定的选
择策略,试图从无标签样本中对分类器性能的提高最有价值的样本,利用专家知识,通过人工标记分类后加入到初始训练样本集,对分类器进行迭代训练,直到循环达到终止条件后停止。主动学习需要利用现有的有标签样本监督训练一个分类模型,再用无标签样本来询问监督者,对样本的标签进行预测,再加入到训练中。如果每次询问都能够选择对模型性能提高最具信息量的样本,就可以在尽可能少的询问次数下得到一个性能良好模型,从而降低对大量有标签样本的依赖程度。
75.监督学习、半监督学习、无监督学习:监督学习是指,在模型训练(又称分类器)的样本中,样本同时具备特征和标签两个信息,模型只需要训练一个映射函数,通过这些样本的学习,把新样本的特征映射成标签。无监督学习是指,样本只有特征信息没有标签信息,通常要进行聚类,寻找样本之间的相似性,根据这些相似性划分成相同标签。半监督学习是介于监督学习和无监督学习之间,样本中有少量数据具备特征和标签信息,剩下的大多数数据只存在特征信息,利用这些有限的有标签数据和无标签数据的相似性,改进模型的性能。
76.标签传播算法(lpa):一种基于图的半监督学习方法,根据无标签数据和有标签数据之间的特征相似性,构造图模型(例如高斯图),用图的边构造加权矩阵,实现有标签数据和无标签数据之间的标签传播。
77.支持向量机(svm):一种机器学习算法,原理是在样本空间寻找一个划分超平面,这个超平面具有最大化间隔的特点,根据这个超平面将样本分为两部分,能够有效地解决高维数据问题,且在较小的训练数据集的情况下也表现出较好的分类效果。
78.用户画像的概念最早由交互设计之父alan cooper提出。他指出,用户画像就是标签化的用户模型。具体来说就是将用户信息标签化,通过收集与分析消费者社会属性、消费习惯、兴趣爱好等数据,抽象出一个用户的全景画像,以帮助企业精准定位、精准营销、预测与决策。随着信用卡用户需求日益多样化以及信用卡营销管理的精细化,用户画像逐渐被信用卡行业广泛关注。用户画像不仅可以使发卡银行实现精准获取客户、精准营销、精准运营、精准管理,而且能够在极大程度上提升客户体验。
79.构建用户画像的核心就是给客户“贴标签”,即基于大数据分析和数据挖掘技术洞察客户行为、偏好,描绘用户不同类型特征,例如“白领精英”“境外消费者”“奢侈品爱好者”等。在数字化转型背景下,信用卡行业试图通过构建客户标签体系,多维度刻画用户特征,为用户提供更好的服务。
80.现有的技术方案大多以监督学习方法为主,基于监督学习的用户画像方法需要预先了解用户的特点,人工对用户进行标签分类后才能作为训练样本,从而得到一个比较良好的用户画像模型。人工对用户进行标签分类需要耗费大量人力物力,只有少量的样本通过人工划分的方式具有自己的标签,大多数的样本仅存在着特征信息,因此使用少量样本通过监督学习后得到的模型性能有一定的局限性。因为样本数量和样本的标签类型有限,这个分类模型对用户数据进行标签分类的效果不是很好。因此,如何提升对用户数据的标签分类效果,仍然是值得研究的。
81.基于此,本技术提供一种标签分类模型训练方法、标签分类方法、装置及设备。该标签分类模型训练方法利用标签传播算法对无标签数据添加标签,再将添加了标签的无标签数据增加至初始标签分类模型的训练样本中,基于新的训练样本对初始标签分类模型进
行训练,以提高初始标签分类模型对无标签数据的标签分类能力,提升初始标签分类模型对用户数据(无标签数据)的标签分类效果。
82.本技术提供的标签分类模型训练方法应用于电子设备,该电子设备例如银行使用的后台服务器、计算机等。图1为本技术提供的标签分类模型训练方法的应用示意图,图中,该后台服务器获取无标签数据集和有标签数据集,再基于该无标签数据集和该有标签数据集构建高斯图。再根据该高斯图确定该有标签数据集和该无标签数据集之间的标签传播算法,基于该标签传播算法将无标签数据集中能够转换的无标签数据转换为有标签数据。将转换得到的有标签数据添加至该有标签数据集中,得到新的有标签数据集。以该新的标签数据集重新训练该初始标签分类模型,得到目标标签分类模型。
83.请参见图2,本技术其中一个实施例提供一种标签分类模型训练方法,包括:
84.s210,获取无标签数据集和有标签数据集,基于该无标签数据集和该有标签数据集构建高斯图。
85.可选的,该无标签数据集和该有标签数据集中的数据均为二维数据,该二维数据中的第一维数据代表消费数据,第二维数据代表该消费数据的标签。如,该有标签数据集d
l
={(x1,y1),(x2,y2),(x3,y3),......(x
l
,y
l
)},该无标签数据集du={(x
l 1
,y
l 1
),(x
l 2
,y
l 2
),(x
l 3
,y
l 3
),......(x
l u
,y
l u
)},其中,该无标签数据集中的第二维数据为空值。
86.在构建该高斯图时,是基于该无标签数据集和该有标签数据集中的第一维数据构建该高斯图的顶点。再根据该无标签数据集和该有标签数据集中第一维度数据之间的相似性构建该高斯图的边。即,基于d
l
∪du构建一个高斯图g=(v,e)。该高斯图的顶点集为v=(x1,x2,x3......x
l
,x
l 1
,x
l 2
,......,x
l u
),该高斯图的边(e)表示一个基于高斯函数定义的加权矩阵,该加权矩阵根据数据之间的特征相似性构造。例如顶点xi和顶点xj之间的边的长度取决于顶点xi和顶点xj之间的权重w
ij
,权重越大说明两个顶点上的数据之间的相似性越小,则边就越长。其中,n代表xi中有n个元素(元素例如消费数据中的消费金额、消费次数、消费目标等),x
id
是xi的第d个元素,δd为第d个元素的高斯带宽参数(高斯带宽参数由用户自定义)。
87.s220,使用该有标签数据集用于训练得到初始标签分类模型。
88.先基于主动学习的方式,使用该有标签数据集训练一个初始标签分类模型。主动学习是一种基于迭代思想的模型,它的基本原理是根据特定的选择策略,从无标签样本中通过人工标记出标签的方式构建训练样本(有标签数据集),再用有标签数据集迭代训练至终止条件后停止,得到初始标签分类模型。主动学习需要利用现有的有标签数据集监督训练一个分类模型,再用该分类模型对无标签数据的标签进行预测,将预测后的无标签数据再加入到训练中。主动学习需要引入额外的专家知识,通过人工分类标注的方式将无标签样本转变成有标签样本,这种方式不仅会浪费大量的人力成本,也存在分类模型的训练样本过少而导致分类模型分类效果不佳的问题。
89.通过标签传播算法的方式对无标签数据进行标签化属于一种基于图的半监督学习方法,无需以来人工就可以自动地利用有标签数据对无标签数据进行标签预测,以更新该初始标签分类模型的训练样本。由此可见,主动学习和标签传播算法可以差异互补,既可以利用无标签数据来提高该初始标签分类模型的泛化能力,又可以通过迭代训练提高该初
始标签分类模型的分类精度。
90.该初始标签分类模型可以包括多个支持向量机(support vector machines,svm)分类器。一个svm分类器对应一个标签,即一个分类器用于判断无标签数据是否属于一个标签的概率,可以根据实际需要训练得到n个svm分类器g1,g2,
……
,gn。
91.在一些实施例中,该无标签数据集可以是基于该n个svm分类器筛选得到的,在筛选时,先获取一些无标签数据作为初始无标签数据集,将该初始无标签数据集输入至该初始标签分类模型后,获取该初始无标签数据集中每个无标签数据的输出与该初始标签分类模型(与该初始标签分类模型中n个svm分类器)之间的距离向量(d1,d2,
……
,dn)。再获取该初始无标签数据集中距离向量最小的m个无标签数据构成该无标签数据集(m为大于零的整数)。距离向量越小,证明该无标签数据越无法被确认出准确的标签,因此,为了进一步提升训练效果,可以优先筛选出标签确认难度较大的无标签数据转换为有标签数据加入到训练样本中。
92.s230,根据该高斯图确定该有标签数据集和该无标签数据集之间的标签传播算法。
93.可选的,基于该高斯图可以获取一个关于该高斯图中顶点和边的实值函数(f:v
→
r),其中r是预测的标签,r是以上描述的d
l
和du中y的集合。通过该实值函数可以为无标签数据分配标签。但是该实值函数无法直接求解,因此需要再根据高斯图中特征相似的样本应该有相似的标签的原则,定义一个关于该实值函数的能量函数e(f)。
[0094][0095]
其中,f
l
=(f(x1);f(x2);......;f(xi))是实值函数f在该有标签数据集上的预测结果,fu=(f(x
l 1
);f(x
l 2
);......;f(x
l u
))是实值函数f在该无标签数据集上的预测结果。d=diag(d1,d2,......,d
l u
)是一个对角矩阵,对角元素为矩阵w第i行元素之和。矩阵w为基于w
ij
构建的权重矩阵。
[0096]
(d-w)为高斯图中的拉普拉丝矩阵,由e(f)的表达式可知,根据该实值函数和该拉普拉丝矩阵可以构建该实值函数的能量函数e(f),因此,基于该高斯图获取实值函数f和拉普拉斯矩阵后,就可以构建该实值函数的能量函数。由于直接求取f比较困难,而当能量函数e(f)最小化时得到的输出即为最优结果,因此只要最小化该能量函数e(f)就能求得该实值函数f,进而得到该无标签实值函数和该有标签实值函数之间的关系算法,该关系算法为该标签传播算法。
[0097]
进一步的,还可以根据该对角矩阵d和该权重矩阵w生成该高斯图的转移矩阵p,再最小化该能量函数e(f),得到初始关系算法,该初始关系算法包含该无标签实值函数f
l
、该有标签实值函数fu、该对角矩阵d和该权重矩阵w。
[0098]
具体的,该对角矩阵d和该权重矩阵w都为u行u列的矩阵,以第l行第l列为界,采用分块矩阵表示时,带入能量函数后可将能量函数改写为最小化该能
量函数e(f),即令得到fu=(d
uu-w
uu
)-1wulfl
。令转移矩阵。令转移矩阵因此可将函数fu改写为fu=(d
uu-w
uu
)-1wulfl
=(i-p
uu
)-1
p
ulfl
,此时得到的该无标签实值函数和该有标签实值函数的关系算法包含该转移矩阵、该无标签实值函数和该有标签实值函数。此时,该关系算法为该标签传播算法,即,该标签传播算法的最终表达式为fu=(i-p
uu
)-1
p
ulfl
。
[0099]
s240,基于该标签传播算法,将该无标签数据集中能够转换的无标签数据转换为有标签数据。
[0100]
通过调和解fu,即可利用有标签数据集的信息,通过该标签传播算法对该无标签数据集进行预测。具体的,该标签传播算法的输出为无标签实值函数的值(fu),基于该标签传播算法,将该无标签数据集中的无标签数据转换为有标签数据时,对该无标签数据集中每个无标签数据执行步骤a至步骤c。
[0101]
步骤a:将无标签数据代入至该标签传播算法后得到无标签实值函数的值。
[0102]
步骤b:当该无标签实值函数的值大于预设值时,确定该标签传播算法计算时使用的有标签实值函数中的标签为该无标签数据的标签。
[0103]
步骤c:为该无标签数据添加标签。
[0104]
该无标签数据代入至该标签传播算法的是第一维数据xi,得到的无标签实值函数的值为f(xi)。该预设值例如为0.5,则f(xi)》0.5时,则sign(f(xi))=1,证明确定f(xi)的值时使用的有标签实值函数中的标签为该无标签数据的标签。如果f(xi)《0.5或f(xi)=0.5,则无法确定该无标签数据的标签。
[0105]
s250,将转换得到的有标签数据添加至该有标签数据集中,得到新的有标签数据集。
[0106]
如果某个无标签数据无法添加上标签,则不会将这个无标签数据转换为有标签数据,也不会将这个无标签数据添加至该有标签数据集中。
[0107]
s260,使用该新的标签数据集重新训练该初始标签分类模型,得到目标标签分类模型。
[0108]
在以该新的标签数据集重新迭代训练该初始标签分类模型时,迭代训练的次数可以根据实际需要选择。优选的,迭代训练的次数是直到du={(x
l 1
,y
l 1
),(x
l 2
,y
l 2
),(x
l 3
,y
l 3
),......(x
l u
,y
l u
)到最大迭代次数,最终得到该目标标签分类模型。
[0109]
该目标标签分类模型中每个svm分类器的输出是0或1,0代表输入的无标签数据不具备svm分类器对应的标签,1代表输入的无标签数据具备svm分类器对应的标签。例如svm分类器对应的标签是美食,而输入的无标签数据是在购买衣物时产生的消费数据,则svm分类器输出的结果是0,如果输入的无标签数据是在购买食物时产生的消费数据,则svm分类器输出的结果是1。
[0110]
图3是对步骤s210至步骤s250的进一步示意,也是添加了半监督学习(标签传播算法)后的主动学习的流程示意图。
[0111]
如图3所示,首先初始化训练样本集(获取有标签数据集),再用训练样本集进行学习得到分类器(即以上描述的利用有标签数据集迭代训练得到包含多个svm分类器的初始标签分类模型)。当该初始标签分类模型的训练结果达到终止条件时(即迭代训练次数达到
预设的次数时),得到最终分类器。如果该初始标签分类模型的迭代训练次数还没有达到预设的次数,则可以采集无标签样本(无标签数据集)后,对无标签样本进行标记(即添加无标签数据集中无标签数据的标签)。将添加了标签的无标签数据加入到训练样本集中,用新的训练样本集重新进行学习,一直到迭代训练的次数达到预设的次数后得到最终分类器(即以上描述的该目标标签分类模型)。
[0112]
综上,本实施例提供的标签分类模型的训练方法是一种基于主动学习和半监督学习的信用卡用户画像方法,可以先利用svm分类器和少量有标签数据训练得到一个初始标签分类模型。再通过标签传播算法和主动学习的方法,利用无标签数据对该初始标签分类模型的性能进行优化,更加精准得刻画出用户特点,从而提供个性化服务。
[0113]
更进一步的,svm分类器的数量和对应的标签数量、类型等都可以根据实际需要设置,标签类型例如消费类别、消费级别、消费偏好(更喜欢旅游、更喜欢美食或其他)等。因此,本实施例提供的方法得到的标签分类模型可以对用户的深层特征进行充分挖掘,了解用户的消费偏好、成长预测、流失预警等,从而可以更好的提高用户体验,提供更精准的服务。
[0114]
本实施例的方法利用标签传播算法将无标签数据转换为有标签数据,再将转换得到的有标签数据添加至原来的有标签数据集中,利用新的有标签数据集重新训练该初始标签分类模型,得到目标标签分类模型。该目标标签分类模型相比于该初始标签分类模型而言,由于其训练样本数量更多更多样化,所以性能比该初始标签分类模型更佳。
[0115]
请参见图4,本技术其中一个实施例提供一种标签分类方法,包括:
[0116]
s410,获取待进行标签分类的无标签数据。
[0117]
该无标签数据是用户刷信用卡产生的消费数据,例如用户购物时产生的消费数据。这些消费数据在生成后是没有标签的,传统方法是人工为这些无标签数据添加标签,这种方法费时费力。因此,将这些还没有进行标签分类的无标签数据输入至如上描述的目标标签分类模型后可以更快、更准确地得到该无标签数据的标签。
[0118]
s420,将该待进行标签分类的无标签数据输入至如以上任一项实施例描述的目标标签分类模型,得到该待进行标签分类的无标签数据的标签。
[0119]
该目标标签分类模型中每个svm分类器的输出是0或1,0代表输入的无标签数据不具备svm分类器对应的标签,1代表输入的无标签数据具备svm分类器对应的标签。例如svm分类器对应的标签是美食,而输入的无标签数据是在购买衣物时产生的消费数据,则svm分类器输出的结果是0,如果输入的无标签数据是在购买食物时产生的消费数据,则svm分类器输出的结果是1。
[0120]
svm分类器的数量和对应的标签数量、类型等都可以根据实际需要设置,标签类型例如消费类别、消费级别、消费偏好(更喜欢旅游、更喜欢美食或其他)等。因此,本实施例提供的方法得到的标签分类结果可以对用户的深层特征进行充分挖掘,了解用户的消费偏好、成长预测、流失预警等,从而可以更好的提高用户体验,提供更精准的服务。
[0121]
请参见图5,本技术其中一个实施例提供一种标签分类模型训练装置10,包括:
[0122]
获取模块11,用于获取无标签数据集和有标签数据集,基于无标签数据集和有标签数据集构建高斯图;
[0123]
训练模块12,用于使用有标签数据集训练得到初始标签分类模型。
[0124]
算法确定模块13,用于根据该高斯图确定该有标签数据集和该无标签数据集之间的标签传播算法;
[0125]
数据转换模块14,用于基于该标签传播算法,将该无标签数据集中能够转换的无标签数据转换为有标签数据;
[0126]
样本构建模块15,用于将转换得到的有标签数据添加至该标签数据集中,得到新的标签数据集;
[0127]
该训练模块12还用于使用该新的标签数据集重新训练该初始标签分类模型,得到目标标签分类模型。
[0128]
该无标签数据集和该有标签数据集中的数据均为二维数据,该二维数据中的第一维度数据表示消费数据,第二维度数据表示该消费数据的标签,该无标签数据集中的第二维度数据为空值,该获取模块11具体用于:基于该无标签数据集和该有标签数据集中的第一维度数据构建该高斯图的顶点;根据该无标签数据集和该有标签数据集中每个第一维度数据之间的相似性构建该高斯图的边。
[0129]
该算法确定模块13具体用于基于该高斯图,获取关于该高斯图中顶点和边的实值函数,该实值函数包括无标签数据集的无标签实值函数和有标签数据集的有标签实值函数;基于该高斯图获取拉普拉丝矩阵,该拉普拉丝矩阵包括对角矩阵和权重矩阵;根据该实值函数和该拉普拉丝矩阵构建该实值函数的能量函数;最小化该能量函数,得到该无标签实值函数和该有标签实值函数之间的关系算法,该关系算法为该标签传播算法。
[0130]
该算法确定模块12具体用于根据该对角矩阵和该权重矩阵生成该高斯图的转移矩阵;最小化能量函数,得到初始关系算法,该初始关系算法包含该无标签实值函数、该有标签实值函数、该对角矩阵和该权重矩阵;以该转移矩阵替换该初始关系算法中的对角矩阵和权重矩阵,得到该关系算法,该关系算法包含该转移矩阵、该无标签实值函数和该有标签实值函数。
[0131]
该标签传播算法的输出为无标签实值函数的值,该数据转换模块13具体用于对该无标签数据集中每个无标签数据执行以下步骤:对无标签数据集中每个无标签数据执行以下步骤:将无标签数据代入至标签传播算法后得到无标签实值函数的值;当无标签实值函数的值大于预设值时,确定标签传播算法计算时使用的有标签实值函数中的标签为无标签数据的标签;为无标签数据添加标签。
[0132]
该获取模块11具体用于获取初始无标签数据集;将初始无标签数据集输入至该初始标签分类模型后,获取该初始无标签数据集中每个无标签数据的输出与该初始标签分类模型之间的距离向量;获取该初始无标签数据集中距离向量最小的m个无标签数据构成该无标签数据集,m为大于零的整数。
[0133]
请参见图6,本技术其中一个实施例提供一种标签分类装置20,包括:
[0134]
获取模块21,用于获取待进行标签分类的无标签数据;
[0135]
处理模块22,用于将该待进行标签分类的无标签数据输入至如上任一项实施例描述的目标标签分类模型,得到该待进行标签分类的无标签数据的标签。
[0136]
请参见图7,本技术其中一个实施例提供一种电子设备30,包括:处理器31,以及与该处理器通信连接的存储器32;该存储器32存储计算机执行指令;该处理器31执行该存储器32存储的计算机执行指令,以实现如上任一项实施例描述的标签分类模型训练方法。
[0137]
请参见图8,本技术其中一个实施例提供一种电子设备40,包括:处理器41,以及与该处理器通信连接的存储器42;该存储器42存储计算机执行指令;该处理器41执行该存储器42存储的计算机执行指令,以实现如上任一项实施例描述的标签分类方法。
[0138]
本技术还提供一种计算机可读存储介质,该计算机可读存储介质中存储有计算机执行指令,当该指令被执行时,使得计算机执行指令被处理器执行时用于实现如上任一项实施例提供的该标签分类模型训练方法。
[0139]
本技术还提供一种另一种计算机可读存储介质,该计算机可读存储介质中存储有计算机执行指令,当该指令被执行时,使得计算机执行如上任一项实施例提供的标签分类方法。
[0140]
一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现如以上任一项实施例描述的标签分类模型训练方法。
[0141]
一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现如以上任一项实施例描述的标签分类方法。
[0142]
需要说明的是,上述计算机可读存储介质可以是只读存储器(read only memory,rom)、可编程只读存储器(programmable read-only memory,prom)、可擦除可编程只读存储器(erasable programmable read-only memory,eprom)、电可擦除可编程只读存储器(electrically erasable programmable read-only memory,eeprom)、磁性随机存取存储器(ferromagnetic random access memory,fram)、快闪存储器(flash memory)、磁表面存储器、光盘、或只读光盘(compact disc read-only memory,cd-rom)等存储器。也可以是包括上述存储器之一或任意组合的各种电子设备,如移动电话、计算机、平板设备、个人数字助理等。
[0143]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
[0144]
上述本技术实施例序号仅仅为了描述,不代表实施例的优劣。
[0145]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本技术各个实施例所描述的方法。
[0146]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0147]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0148]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0149]
以上仅为本技术的优选实施例,并非因此限制本技术的专利范围,凡是利用本技术说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本技术的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。