1.本发明涉及数据处理技术领域,尤其是涉及一种数据表格扫描图像的结构化转换方法。
背景技术:
2.目前信息可以划分为两大类,一类信息能够用数字或统一的结构加以表示,称之为结构化数据;另一类无法用数字或统一的结构表示,如文本、图像、声音、网页等,称之为非结构化数据。现今企业存储的非结构化数据大量堆积,然而无法遵循标准的数据结构,一定程度上很难理解或者调动这些数据,将不能满足日益增长的应用需求,目前传统的结构化转换方法是对非结构化数据特征提取,进行命名实体、关系识别,并依据所需要处理的属性具体划分构建数据表,需要人工参与,效率低;
3.同时企业多以电子表格扫描件的方式存储非结构化数据,目前电子表格逻辑提取方法是通过表格识别算法,获取电子表格文档(如excel等表格软件)中所有表格进行布局分析。再根据分析结果从中抽取内容,并做对应的转换处理得到结构化信息。而相当一部分信息资料是以扫描版本与照片版本的表格为主,不如电子表格工整清晰,会产生倾斜或者不对齐的情况。
技术实现要素:
4.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种数据表格扫描图像的结构化转换方法,准确性高,实现自动结构化转换,效率高。
5.本发明的目的可以通过以下技术方案来实现:
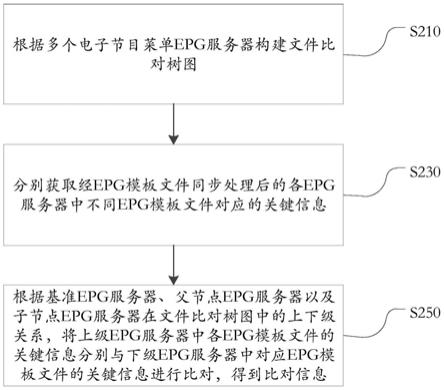
6.一种数据表格扫描图像的结构化转换方法,可用于电力系统变电设备试验报告的结构化转换,包括以下步骤:
7.1)获取数据表格的扫描图像;
8.2)提取扫描图像中的文字位置信息和表格位置信息;
9.3)根据文字位置信息和表格位置信息,获取文本在表格中的行列位置信息;
10.4)根据行列位置信息,逐一识别每一个表格中单元格内的文本识别信息;
11.5)重构包含文本识别信息和表格位置信息的电子表格文档;
12.6)将电子表格文档转化成字典形式的结构化数据。
13.进一步地,所述的文字位置信息包括文字的位置信息和文字所在单元格的边框位置信息。
14.进一步地,所述的文字位置信息的提取过程包括:
15.通过ocr深度学习算法提取扫描图像中文字的位置信息;
16.对扫描图像进行二值化处理,获得文字所在单元格的边框位置信息。
17.进一步地,所述的表格位置信息包括表格中横线和竖线的交点坐标;
18.所述的表格位置信息的提取过程包括:
19.利用腐蚀、膨胀操作对二值化处理后的扫描图像进行分割,获得表格中的横线和竖线位置,进而获得横线和竖线的交点坐标。
20.进一步地,所述的步骤6)包括:
21.对于电子表格文档的每个表格,判断该表格的行列是否对齐,若是则判定该表格为标准表格,否则判定该表格为非标准表格;
22.采用关键字填充的方式对标准表格进行结构化;
23.对于非标准表格,首先构建一组关键字库以及字库内文本信息的上下级关系,提取非标准表格内文本信息的隶属关系,根据隶属关系将文本信息转化成字典形式的结构化数据。
24.进一步地,所述的数据表格扫描图像的结构化转换方法包括:
25.将步骤1)获得的扫描图像、步骤5)获得的电子表格文档以及步骤6)获得的结构化数据保存至数据库。
26.进一步地,所述的数据表格扫描图像的结构化转换方法包括:
27.通过基于restful协议的接口开发,提供用于查询数据库的接口。
28.进一步地,所述的数据表格扫描图像的结构化转换方法包括:
29.根据文件名在数据库中查询相应的电子表格文档;
30.根据数据键值在数据库中查询结构化数据。
31.进一步地,所述的数据表格扫描图像的结构化转换方法包括:
32.接收已存数据查询指令,生成数据库中所有电子表格文档和结构化数据的数据清单。
33.进一步地,所述的数据表格扫描图像的结构化转换方法包括:
34.为数据库中的电子表格文档和结构化数据设置未读标记;
35.接收未读数据查询指令,生成数据库中所有未读的电子表格文档和结构化数据的数据清单。
36.与现有技术相比,本发明具有以如下有益效果:
37.(1)本发明在表格位置信息和文字位置信息的基础上,针对每一个表格内的文本信息进行排序,通过逐个表格提取文本信息的方式,将文本和表格复现在电子表格文档中,解决初始图像中表格内文本换行的问题,避免ocr识别时将换行文本当成两个文本的缺陷,解决了常规ocr跨行识别的错位问题;
38.(2)本发明结合单元格内文本识别和表格样式逻辑挖掘,实现试验报告的精准识别和自动结构化转换,效率高;
39.(3)本发明通过基于restful协议的接口开发,提供用户查询数据和文件接口,以便用户获取文件和数据清单,以及未读文件和数据清单,通过基于restful协议的接口开发,提供用户获取数据和文件的接口,以便用户通过文件名或者数据键值获取相应文件或者数据。
附图说明
40.图1为本发明的方法流程图。
具体实施方式
41.下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
42.一种数据表格扫描图像的结构化转换方法,如图1,包括以下步骤:
43.1)获取数据表格的扫描图像;
44.2)提取扫描图像中的文字位置信息和表格位置信息;
45.3)根据文字位置信息和表格位置信息,获取文本在表格中的行列位置信息;
46.4)根据行列位置信息,逐一识别每一个表格中单元格内的文本识别信息;
47.5)重构包含文本识别信息和表格位置信息的电子表格文档;
48.6)将电子表格文档转化成字典形式的结构化数据。
49.文本识别信息包括汉字、字符和符号。
50.文字位置信息包括文字的位置信息和文字所在单元格的边框位置信息。
51.步骤2)中,文字位置信息的提取过程包括:
52.通过ocr深度学习算法提取扫描图像中文字的位置信息;
53.对扫描图像进行二值化处理,获得文字所在单元格的边框位置信息。
54.表格位置信息包括表格中横线和竖线的交点坐标;
55.步骤2)中,表格位置信息的提取过程包括:
56.在二值化处理的基础上,利用腐蚀、膨胀操作对扫描图像进行分割,将一张扫描图像中的不同表格分割出来,提取这些表格中的横线和竖线位置,进而获得横线和竖线的交点坐标。
57.步骤3)通过这些交点坐标与文字位置信息对比,得到文本信息在原表格中的行列位置信息。
58.步骤4)在表格位置信息和文字位置信息的基础上,针对每一个表格内的文本信息进行排序,通过逐个表格提取文本信息的方法,将文本和表格复现在word文档,解决初始图像中表格内文本换行的问题,避免ocr识别时将换行文本当成两个文本的缺陷。
59.步骤6)包括:
60.对于电子表格文档的每个表格,判断该表格的行列是否对齐,若是则判定该表格为标准表格,否则判定该表格为非标准表格;
61.对于标准表格,采用关键字填充的方式对其进行结构化;
62.对于非标准表格,首先构建一组关键字库以及字库内文本信息的上下级关系,提取非标准表格内文本信息的隶属关系,根据隶属关系将文本信息转化成字典形式的结构化数据。非标准表格示例如表1所示:
63.表1非标准表格示例
64.65.将步骤1)获得的扫描图像、步骤5)获得的电子表格文档以及步骤6)获得的结构化数据保存至数据库。
66.数据表格扫描图像的结构化转换方法包括:
67.通过基于restful协议的接口开发,提供用于查询数据库的接口。
68.数据表格扫描图像的结构化转换方法包括:
69.根据文件名在数据库中查询相应的电子表格文档;
70.根据数据键值在数据库中查询结构化数据。
71.接收已存数据查询指令,生成数据库中所有电子表格文档和结构化数据的数据清单。
72.为数据库中的电子表格文档和结构化数据设置未读标记;
73.接收未读数据查询指令,生成数据库中所有未读的电子表格文档和结构化数据的数据清单。
74.本实施例提出了一种数据表格扫描图像的结构化转换方法,提供一种自动、高效的试验报告结构化转换、数据存储和服务的方法,便于数据资产的数字化管理、结构化存储和多源异构数据融合。
75.以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。