1.本发明涉及说话人识别领域,尤其涉及一种基于性别和语言的说话人识别方法及系统。
背景技术:
2.随着人工智能的不断发展,越来越多的智能身份识别技术被应用在了生活中,包括了人脸识别、指纹识别以及近些年来兴起的声纹识别。声纹识别又称为说话人识别,通过分析一段音频内容来识别该音频是属于哪一位说话人的。说话人可以被用来进行身份认证,因为其便捷的特性而被广泛关注。
3.现有技术中,对于说话人识别的方法大多关注单一因素即说话人本身的识别,这种方式要求说话人在注册声纹以及识别声纹两个阶段,需要保持说话的方式相似,当说话人使用不同音调时,会导致识别准确度下降。
技术实现要素:
4.本发明要解决的技术问题,在于提供一种基于性别和语言的说话认识别方法及系统,结合语音内容中包含的性别信息以及语言信息进行说话人识别,解决当语言音调变化情况下,单一因素识别方法的准确率下降的技术问题。
5.为实现上述目的,本发明采用下述技术方案:
6.本发明的第一个目的在于提供一种基于性别和语言的说话人识别方法,所述方法包括:
7.获取待识别语音数据,所述的语音数据为包含有效说话人音频的wav格式的音频文件;
8.将音频文件通过降噪处理得到低噪声的语音音频;
9.将语音音频通过smac特征提取得到语音频谱特征图;
10.将语音频谱特征图输入resnet模型中得到语音特征向量;
11.将语音特征向量输入到多目标学习模型中,识别得到说话人身份、说话人性别以及说话人使用的语言信息;
12.通过将识别得到的说话人身份、说话人性别以及说话人使用的语言信息进行加权融合,得到待识别语音数据对应的说话人识别结果。
13.进一步的,所述的多目标学习模型包含三个识别任务:说话人身份识别、说话人性别识别以及说话人使用的语言信息识别,由n层共享层、三层隐含层和一层融合层构成;
14.所述的n层共享层依次连接,在训练过程中,共享层的参数受三个任务的识别结果影响;三层隐含层的输入分别连接第n层共享层的输出,三层隐含层的输出分别为说话人身份、说话人性别以及说话人使用的语言信息识别结果,在训练过程中,隐藏层的参数只受到相应识别任务的影响;
15.所述的融合层用于融合三个识别任务的输出结果,每一个识别任务的输出结果设
有可训练权重参数,融合层将三个识别任务的加权结果作为最终识别结果。
16.本发明的第二个目的在于提供一种基于性别和语言的说话人识别系统,用于实现上述的说话人识别方法;所述系统包括:
17.声音采集模块,用于采集说话人的语音音频数据;
18.音频滤波模块,用于对采集的语音音频数据进行滤波,消除噪音;
19.说话人识别模块,用于对滤波处理后的语音音频数据进行说话人识别;
20.识别结果展示模块,用于将识别结果进行可视化处理。
21.本发明的有益效果在于:本发明综合利用了语音中带有的性别信息和语言信息,有效的提高了说话认识别的鲁棒性,特别是在说话人语音变化的情况下,识别精度高。
附图说明
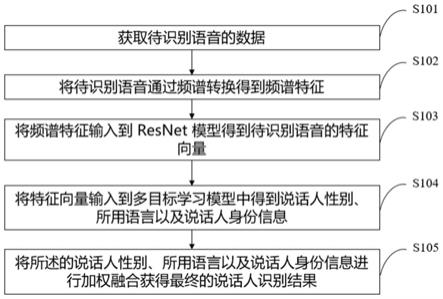
22.图1为本发明提供的一种基于性别和语言的说话人识别方法及系统的流程框图。
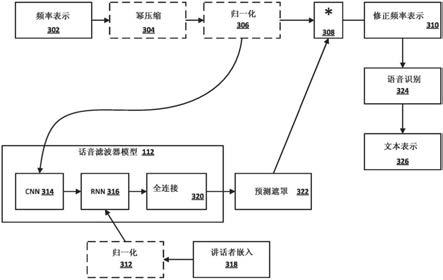
23.图2为本发明提供的一个示例中说话人识别框架的结构示意图。
24.图3为本发明提供的一种基于语音和文字的说话人识别系统的示意图。
具体实施方式
25.下面结合附图对发明的技术框架进行说明。
26.现有技术中,对于说话人识别的方法大多关注单一因素即说话人本身的识别,这种方式要求说话人在注册声纹以及识别声纹两个阶段,需要保持说话的方式相似,当说话人使用不同音调时,会导致识别准确度下降。
27.为了能够解决现有技术中大多数基于单一因素即说话人本身的识别,导致说话人识别鲁棒性较低的技术问题,本发明实施例提供一种基于性别和语言的说话人识别方法及系统。
28.以下结合附图,详细说明本发明中各实施例提供的技术方案。
29.一种基于语音和文字的说话人识别方法,如附图1所示,所述方法包括:
30.步骤s101,获取待识别语音的数据。
31.所述的语音数据为包含有效说话人音频的wav格式的音频文件。
32.步骤s102,将音频文件通过降噪处理得到低噪声的语音音频,将降噪后的语音音频通过频谱转换得到语音频谱特征图;
33.步骤s103,将语音频谱特征图输入resnet模型中得到语音特征向量;
34.步骤s104,将语音特征向量输入到多目标学习模型中,识别得到说话人身份、说话人性别以及说话人使用的语言信息;
35.针对步骤s104,在一个示例中,如附图2所示,该多目标学习模型的模型框架包括多个识别任务:说话人识别(主要任务),性别识别以及语言识别,通过引入多个辅助的识别因素来提高说话人识别的准确性。另外,框架包含一组共享层,其中共享层中的参数为多个识别任务所共有的,体现在训练的过程中,每个识别任务都可以对该模型下的共享层的参数进行优化。框架包含多个任务特有的隐含层,隐含层是每个识别任务所特有的,体现在训练的过程中,只有相应的识别任务的结果才能影响隐含层的参数。
36.步骤s105,通过将识别得到说话人身份、说话人性别以及说话人使用的语言信息
进行加权融合得到待识别语音的说话人识别结果。本实施例中,通过在上述的多目标学习模型三个隐含层之后引入融合层实现,所述的融合层用于融合三个识别任务的输出结果,每一个识别任务的输出结果设有可训练权重参数,融合层将三个识别任务的加权结果作为最终识别结果。
37.在三者识别结果融合过程中选择最优的权重系数组合,该权重系数组合是在模型训练时测试不同权重系数组合的准确度,选择最高准确度的一组为最终的权重系数。权重系数受到识别任务的识别分辨率以及副任务与主要任务的相对关系影响。
38.在本发明的一项具体实施中,所述的语音频谱特征图由语音的smac特征构成,所述的smac特征提取方法为:
39.将语音音频通过滤波器处理:
[0040][0041]
xq(ω,t)=x(ω,t)hq(ω)
[0042]
q=1,2,...,q
[0043]
其中,t表示在第t帧时刻,ω是频谱的自变量,x(ω,t)表示的第t帧时刻频率为ω时的信息强度;hq(ω)表示第q个滤波器,α表示控制滤波器带宽宽度的参数,ωq是第q个滤波器的中心频率,q是滤波器的数量,xq(ω,t)表示第q个滤波器的滤波结果。
[0044]
计算滤波结果的0阶中心矩和1阶中心矩:
[0045][0046]
其中,m表示中心距的阶数,mm(q,t)表示滤波结果的m阶中心矩;
[0047]
将1阶中心矩和0阶中心矩的比值作为语音频谱特征:
[0048][0049]
其中,r1(q,t)表示第q个语音频谱特征,q个语音频谱特征构成语音频谱特征图。
[0050]
不同于一般的说话人识别方法,本发明针对音调可变的说话人识别进行了优化,使用了smac特征而不是普通的mfcc特征,该特征具有音调鲁棒的特性,可以满足说话人在音调变化场景下的身份认证。一种基于语音和文字的说话人识别系统,如附图3所示,所述系统包括:
[0051]
声音采集模块,采集说话人的音频数据;
[0052]
音频滤波模块,对采集的声音音频进行滤波,消除噪音;
[0053]
说话人识别模块,对滤波处理过后的音频进行说话人识别;该模块包括了:
[0054]
音频频谱转换模块,用于对输入的音频进行频谱分析,通过输入原始音频,对其进行smac特征提取得到语音频谱特征图;
[0055]
频谱特征提取模块,用于提取语音频谱特征图的特征向量。;输入语音频谱特征图,经过深度网络提取特征向量;
[0056]
多目标学习模型模块,其包含三个识别任务:说话人身份识别、说话人性别识别以及说话人使用的语言信息识别,由n层共享层、三层隐含层和一层融合层构成;所述的n层共
享层依次连接,在训练过程中,共享层的参数受三个任务的识别结果影响;三层隐含层的输入分别连接第n层共享层的输出,三层隐含层的输出分别为说话人身份、说话人性别以及说话人使用的语言信息识别结果,在训练过程中,隐藏层的参数只受到相应识别任务的影响;所述的融合层用于融合三个识别任务的输出结果,每一个识别任务的输出结果设有可训练权重参数,融合层将三个识别任务的加权结果作为最终识别结果。
[0057]
识别结果展示模块,将识别结果进行可视化的处理。该模块包含了:
[0058]
语音提示模块,通过语音播放识别到的结果,如果说话人不在注册者列表中,则播放警报声音;
[0059]
文字显示模块,通过文字显示识别到的说话人信息。如果在识别过程中出现问题,则在该模块上进行错误显示。
[0060]
本领域的技术人员应理解,上述描述及附图中所示的本发明的实施例只作为举例而并不限制本发明。本发明的目的已经完整有效地实现。本发明的功能及结构原理已在实施例中展示和说明,在没有背离所述原理下,本发明的实施方式可以有任何变形或修改。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。