技术特征:
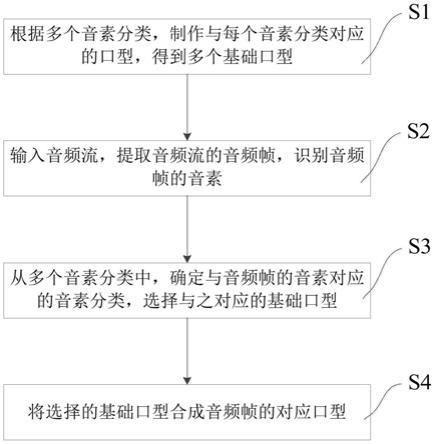
1.一种模拟虚拟人物说话的方法,其特征在于,所述方法包括:根据多个音素分类,制作与每个所述音素分类对应的口型,得到多个基础口型;输入音频流,提取所述音频流的音频帧,识别所述音频帧的音素;从所述多个音素分类中,确定与所述音频帧的音素对应的所述音素分类,选择与之对应的所述基础口型;将选择的所述基础口型合成所述音频帧的对应口型。2.根据权利要求1所述的方法,其特征在于,所述多个音素分类包括:(p,b,m)、(f,v)、(th)、(t,d)、(k,g)、(ts,dz,s)、(s,z)、(n,l)、(r)、(a)、(e)、(ih)、(oh)、(ou)。3.根据权利要求1所述的方法,其特征在于,在所述音频流中,提取2.5ms至60ms为单位的数据量为一帧音频。4.根据权利要求1所述的方法,其特征在于,所述方法还包括:制作虚拟人物模型,根据所述音频帧的对应口型,生成所述虚拟人物的口型。5.根据权利要求1所述的方法,其特征在于,所述多个基础口型还包括:嘴闭合口型和通用口型。6.根据权利要求5所述的方法,其特征在于,当从所述音频帧中识别的音素不在所述多个音素分类中时,选择所述通用口型作为基础口型;当从所述音频帧中未识别出音素时,选择所述嘴闭合口型作为基础口型。7.一种模拟虚拟人物说话的装置,其特征在于,所述装置包括:基础口型生成单元(102),用于根据多个音素分类,制作与每个所述音素分类对应的口型,得到多个基础口型;音素提取单元(104),用于输入音频流,提取所述音频流的音频帧,识别所述音频帧的音素;基础口型确定单元(106),用于从所述多个音素分类中,确定与所述音频帧的音素对应的所述音素分类,选择与之对应的所述基础口型;口型合成单元(108),用于将选择的所述基础口型合成所述音频帧的对应口型。8.一种计算机可读存储介质,其特征在于,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行权利要求1-6中任一项所述的方法。9.一种计算设备,其特征在于,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现权利要求1-6中任一项所述的方法。
技术总结
本发明实施例公开了一种模拟虚拟人物说话的方法及装置,方法包括以下步骤:根据多个音素分类,制作与每个音素分类对应的口型,得到多个基础口型;输入音频流,提取音频流的音频帧,识别音频帧的音素;从多个音素分类中,确定与音频帧的音素对应的音素分类,选择与之对应的基础口型;将选择的基础口型合成音频帧的对应口型。将真人口型通过音素分类,整理为14个基本口型,可以让计算机通过音素识别,驱动虚拟数字人口型同步。通过虚拟数字人口型专利,可以快速准确的实现虚拟数字人的语音口型同步。制定了口型标准化口型制作方案,极大的提高了虚拟数字人口型制作效率和口型的质量。让虚拟数字人更加接近于真人,极大的提升了用户的体验。户的体验。户的体验。
技术研发人员:余国军 耿俊怀
受保护的技术使用者:小哆智能科技(北京)有限公司
技术研发日:2022.01.17
技术公布日:2022/4/15
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。