1.本发明属于空间环境监测预报领域,涉及一种太阳活动指数——10.7厘米射电流量的长期预报方法。
背景技术:
2.灾害性太空环境事件是威胁航天装备安全、影响电子信息装备正常运行的核心环境因素,是遂行航天发射、太空攻防、在轨航天器管理等各类航天任务关注的重要空间环境信息。太阳爆发剧烈活动是灾害性太空环境事件发生的根源,因此及时了解、掌握太阳活动现状和发展趋势是预防灾害性太空环境事件、减小其对我航天任务影响的重要前提。在表征太阳活动水平的众多参数中,10.7厘米射电流量(f10.7)扮演着十分重要的角色,是综合衡量太阳色球、过渡区和日冕极紫外辐射强度的一种常用指数,被人们广泛研究。同时,f10.7也是大气密度模型和电离层模式的重要输入参数,影响着卫星定轨和导航通信等设备的正常运行。因此,一直以来f10.7预报方法的研究是太空环境应用研究和业务预报的重要课题。
3.目前,多数关于f10.7预报的研究都聚焦在中短期预报中(一般为提前27天或者45天的预报)。美国业务型太阳活动预报软件包solar2000太阳大气辐射模型中包含有基于时间序列分析的f10.7中期预报模型。solar2000的第一代f10.7的中期预报模型直接采用取代的方法,在第一代改进版中加入了线性预报技术,对其他波段的辐射指数也是采用线性预报技术。中国科学院空间环境研究预报中心刘四清等人采用时间序列模型,以预报时刻之前的730天资料为基础,提出了54阶自回归模型(auto-regressive,ar)进行f10.7的中期预报。该模型平均误差为太阳活动低年5%、活动高年15%,与美国空军的预报结果精度基本相当。该模型现在也是中国科学院空间中心空间环境日常预报业务的基础方法。此外,中国的研究人员将小波分析、奇异谱分析、人工神经网络等方法应用到f10.7序列的周期分析中,并将自回归模型与奇异谱分析方法相结合试用于f10.7的中期预报。
4.相比之下,对f10.7长期预报(未来11年甚至更长时间的预报)的研究相对较少,主要有两类方法。第一类方法为人工经验预报,每一个新太阳活动周开始的时候,国际相关机构会组织该领域知名专家召开专题会议,每位专家结合自身知识经验对未来一个活动周的太阳活动水平进行预报,最后专家组讨论形成最终预报结果对外发布,预报的参数包括太阳黑子数和f10.7等。此类方法的优点是集成了全世界优秀的领域专家,因此准确率相对较高;其缺点是主观性强、专家知识依赖性强,时效性差,自主性弱。第二类方法为模式预报,主要以美国空间天气预报中心给出的计算公式为主。此类方法简单明了,可以对任意时间长度做出预报且计算速度快,但由于该公式只是固定参数的简单周期函数,其准确度很低且不能反应不同太阳活动周之间的差异性。
5.随着我国空间站建设进程的不断推进以及探月、探火等深空探测任务的深入发展,对f10.7长期预报的需求不断增加,对其预报精度和时效性的要求也日益提高,亟需一种f10.7长期预报方法,能够满足我国航天任务日益增长的需求,有效克服现有两类方法的
缺点。
技术实现要素:
6.为了克服现有技术的不足,本发明提供一种数据驱动的太阳10.7厘米射电流量长期预报方法,能够利用f10.7历史观测数据,预测未来一个太阳活动周(11年)的f10.7值,无需专家知识也能保证一定准确率,提高预报的自主性、时效性,有效支援相关航天任务。
7.本发明解决其技术问题所采用的技术方案包括以下步骤:
8.(1)设置差分阶数d的初始值为0,并对原始时间序列进行adf检验;如果adf检验结果为false,则表明数据无需差分,返回d=0,学习结束;如果检验结果为true,则表明需要进行一次差分,对序列进行差分操作并设置d=1;对差分后的序列继续进行adf检验,若结果为false,返回当前d;若结果为true,对当前序列再进行一次差分并设置d值加1;重复对序列进行adf检验直到检验结果为false,返回当前d值;
9.设置季节差分阶数d的初始值为0,并对原始序列进行ch检验;如果ch检验结果为false,则表明数据无需差分,返回d=0,学习结束;如果检验结果为true,则表明需要进行一次差分,对序列进行差分操作并设置d=1;对差分后的序列继续进行ch检验,若结果为false,返回当前d;若结果为true,对当前序列再进行一次差分并设置d值加1;重复对序列进行ch检验直到检验结果为false,返回当前d值;
10.(2)采用信息判据有学习自回归阶数p、滑动平均阶数q、季节自回归阶数p和季节滑动平均阶数q,其中,l为观测数据的似然值,n为数据中样本点的个数,选择使得aicc最小的一组值,即
11.(3)对原始时间序列进行d阶差分和d阶季节性差分,得到的时间序列记作{y
t
},其arima模型中包含下列参数:
12.a1,a2,...,a
p
13.α1,α2,...,α
p
14.b1,b2,...,bq15.β1,β2,...,βq16.其中,a1至a
p
为非季节性自回归系数,α1至α
p
为季节性自回归系数,b1和bq为非季节性滑动平均系数,β1和βq为季节性滑动平均系数;
17.(4)利用学习好的模型预测未来的f10.7年均值。
18.所述的步骤(1)中,采用the phillips
–
perron test或dickey pantula test替代adf或ch作为单位根检验的方式。
19.所述的步骤(2)首先设置各个参数的取值范围,分别为p∈[0,10],q∈[0,10],p∈[0,2],q∈[0,2],且所有参数均为整数。
[0020]
所述的步骤(2)采用网格搜索法、随机搜索或贝叶斯优化方法学习参数。
[0021]
所述的步骤(3)采用最大似然估计或者最小二乘法学习获得模型系数,具体计算
过程表示为a1,a2,...,a
p
,α1,α2,...,α
p
,b1,b2,...,bq,β1,β2,
…
,其中,y
t
为真实观测值,为模型预测值,n为观测值个数。
[0022]
所述的步骤(4)采用递归调用的方式预测未来多年的数值,即先预测未来一年,然后将该预测值作为模型的新输入预测未来第二年,以此类推。
[0023]
本发明的有益效果是:提出的f10.7长期预报方法是一种纯数据驱动的方法,克服了人工经验预报对专家知识依赖性强、时效性差、自主性弱等缺点,能够在探火、探月、空间站保障等重大航天任务中提供自主、及时、有效的f10.7长期预报值。
[0024]
与美国空间天气预报中心(space weather prediction center,swpc)提供的预报方法相比,本发明能够建模当前值与历史值之间的函数关系,从而提供了更加准确的预测值。swpc的预报模型如下式所示:
[0025]
f10.7=145 75cos(0.001696
×
t 0.35sin(0.001696
×
t)),t=mjd-44605,
[0026]
其中,mjd为约简儒略日。
[0027]
图2和图3分别给出了1999年至2010年和2011年至2020年两个太阳活动周本发明模型(记作arima)与美国空间天气预报中心预报模型(swpc)预测值对比结果。从图中可以看出,arima的预报结果更加贴近真实值,明显地优于swpc的预报结果,尤其是太阳活动高年这一点更为显著。
附图说明
[0028]
图1是1963年至2020年f10.7年平均值示意图;
[0029]
图2是1999年至2010年本发明模型(arima)与美国空间天气预报中心预报模型(swpc)预测值对比结果图;
[0030]
图3是2011年至2020年本发明模型(arima)与美国空间天气预报中心预报模型(swpc)预测值对比结果图;
[0031]
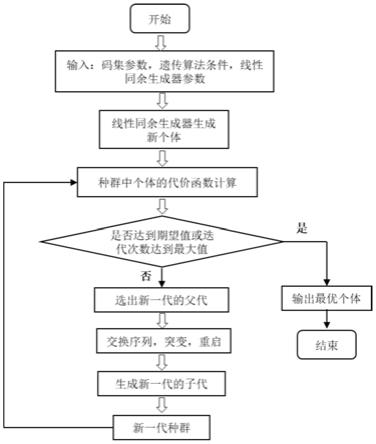
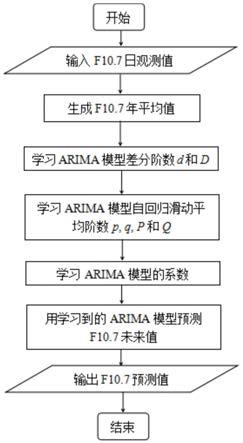
图4是数据驱动的f10.7长期预报方法建模和预报流程图。
具体实施方式
[0032]
下面结合附图和实施例对本发明进一步说明,本发明包括但不仅限于下述实施例。
[0033]
本发明的目的是利用f10.7历史观测数据,开发一种时间序列模型,用来预测未来一个太阳活动周(11年)的f10.7值。f10.7的原始观测数据是以日为分辨率的,即每天记录一个观测值,日观测值通常用于中短期预报。这里的研究对象为长期预报,关注的是f10.7的长期波动趋势,其波动周期约11年。因此首先对原始数据取年平均值,然后再建立时间序列预报模型,用于预测未来11年的年平均值。图1展示了1963年至2020年f10.7的年平均值。
[0034]
本发明拟建立的时间序列模型的本质是学习一个f10.7当前观测值与过去观测值之间的函数关系,前期研究表明,f10.7观测值之间的函数关系近乎线性,因此选择差分自回归滑动平均模型(auto-regressive integrated moving average model,arima)为基础预报模型,该模型是统计学中常用的一种线性时间序列建模方法,可表示为:
[0035]
arima(p,d,q)(p,d,q)m,
ꢀꢀꢀ
(1)
g.forecasting:principles and practice[j].london:bowker-saur.pharo,2014.);然后采用网格搜索的方式选取最优值,即遍历所有可能的组合方式并从中选择使得aicc最小的组合作为最终输出。
[0052]
(3)学习arima模型系数
[0053]
学习得到超参数之后,对原始时间序列进行d阶差分和d阶季节性差分,得到的时间序列记作{y
t
},其arima模型中包含下列参数:
[0054]
a1,a2,
…
,a
p
[0055]
α1,α2,...,α
p
[0056]
b1,b2,...,bq[0057]
β1,β2,...,βq[0058]
其中,a1至a
p
为非季节性自回归系数,α1至α
p
为季节性自回归系数,b1和bq为非季节性滑动平均系数,β1和βq为季节性滑动平均系数。
[0059]
模型系数的学习可采用最大似然估计(maximum likelihood estimation,mle)或者最小二乘法(least square,ls)来获得,两者本质上基本一致,具体计算过程表示为:
[0060][0061]
其中,y
t
为真实观测值,为模型预测值,n为观测值个数。
[0062]
(4)利用学习好的模型进行预报
[0063]
学习得到模型参数后即可得到最终预报模型,可以用于预测未来一年的f10.7年均值。
[0064]
为了预测未来多年的数值,可采用递归调用的方式,即先预测未来一年,然后将该预测值作为模型的新输入预测未来第二年,以此类推,即可实现未来多年的预测。
[0065]
在本技术方案的框架下,用户可在方法的使用中对某些步骤进行优化,来更好地适用于具体的问题。
[0066]
在步骤(1)中,采用了adf test作为单位根检验的方式,用户可以选择其他的方式,如the phillips
–
perron test和dickey pantula test。
[0067]
在步骤(2)中,对超参数的取值范围采用了经验主义设置方法,这能适用于大部分问题,但并不是对每一个具体问题都合适,用户可以适当增大该取值范围,增加解空间,以获取更优的解;同时,超参数的学习采用了网格搜索法,该方法虽然能确保得到最优解,但是时间复杂度较高,用户可根据实际情况选择其他方法,如随机搜索、贝叶斯优化等。
[0068]
本发明选择差分自回归滑动平均模型(auto-regressive integrated moving average model,arima)作为基础预报模型,该模型是统计学中常用的一种线性时间序列建模方法,可表示为:
[0069]
arima(p,d,q)(p,d,q)m,
[0070]
其中,p为自回归阶数,d为差分阶数,q为滑动平均阶数,p为季节(这里的季节指的是数据波动的一个周期)自回归阶数,d季节差分阶数,q为季节滑动平均阶数;m为每个季节包含的数据点数,即周期,对于f10.7年均值数据m=11。上述各个阶数称为超参数,在拟合模型前必须设定其值,可以人为地根据先验知识指定,也可以从数据中自动学习,本发明目的是建立完全数据驱动的模型,因此采用从数据中学习的方式设定。下述的步骤(1)和(2)
分别介绍差分阶数(d、d)和自回归滑动平均阶数(p、q、p、q)的学习方法,步骤(3)介绍指定了超参数之后如何学习模型的系数,步骤(4)介绍如何利用学习好的模型进行f10.7长期预报。本发明的建模和预报流程参见图4。
[0071]
(1)学习arima模型差分阶数d和d
[0072]
对原时间序列做差分的目的是使非平稳时间序列平稳化,差分阶数d和d指定了需要进行差分的次数,即需要进行多少次差分才能使原始时间序列平稳。这些参数可以利用单位根检验(unit root tests)的方法从数据中学习得到,下面以d的学习为例来讲述具体过程:
[0073]
①
对f10.7年均值序列进行augmented dickey fuller检验(此检验为单位根检验的一种,简称adf test),并设置d的初始值d=0;
[0074]
②
如果adf检验结果为false,则表明数据无需差分,返回d=0,学习结束;如果检验结果为true,则表明需要进行一次差分,对序列进行差分操作并设置d=1;
[0075]
③
对差分后的序列继续进行adf检验,若结果为false,返回当前d;若结果为true,对当前序列再进行一次差分并设置d=d 1;
[0076]
④
重复步骤
③
直到检验结果为false,返回d。
[0077]
d的学习流程与d类似,区别在于采用的单位根检验方式为canova hansen检验(ch test),这是一种专门用于检验季节性序列的统计测试方式。adf检验和ch检验在python或者r语言中均有预定义的函数,用户可以很方便地实现这两种测试方法。
[0078]
(2)学习arima模型自回归滑动平均阶数p、q、p和q
[0079]
p、q、p和q的学习采用最小化信息判据的方式,常用的信息判据有akaike’sinformation criterion(aic)、corrected aic(aicc)、bayesian information criterion(bic),根据经验,aicc的实际效果较好,故采用aicc作为本步骤的判据,其定义为:
[0080][0081]
其中,l为观测数据的似然,n为数据中样本点的个数。从定义中可以看出,aicc是p、q、p和q的函数,对于每一组p、q、p和q的值,都可以计算出对于的aicc。这里的目标是选择使得aicc最小的一组值,即:
[0082][0083]
为了解决上述优化问题,在f10.7长期预报模型构建中,首先设置各个参数的取值范围,分别为:
[0084]
p∈[0,10],q∈[0,10],p∈[0,2],q∈[0,2],
[0085]
且所有参数均为整数;然后采用网格搜索的方式选取最优值,即遍历所有可能的组合方式并从中选择使得aicc最小的组合作为最终输出。
[0086]
(3)学习arima模型系数
[0087]
将1963年至2020年f10.7的年平均值作为研究对象,历经步骤(1)和(2)的计算得出
[0088]
d=0,d=0,p=5,q=0,p=2,q=0.
[0089]
学习得到上述超参数之后,公式(1)所示模型简化为arima(5,0,0)(2,0,0)
11
,可显示表示为:
[0090]yt
=a1y
t-1
a2y
t-2
a3y
t-3
a4y
t-4
a5y
t-5
b1y
t-11
b2y
t-22
c e
t
,
ꢀꢀꢀ
(2)
[0091]
其中,{y
t
}表示f10.7年平均值时间序列;等式右侧前5项(p=5)为非季节性自回归部分,a1至a5为非季节性自回归系数;接下来2项(p=2)为季节性自回归部分,b1和b2为季节性自回归系数;c为常数项,也称截距;e
t
为误差项,通常假定为均值为0的正态分布。
[0092]
模型系数的学习可采用最大似然估计(maximum likelihood estimation,mle)或者最小二乘法(least square,ls)来获得,两者本质上基本一致,具体计算过程表示为:
[0093][0094]
表1展示了将1963年至2020年f10.7年平均值作为输入,采用上述计算过程学习得到的模型系数。
[0095]
表1f10.7年平均值arima(5,0,0)(2,0,0)
11
模型系数最大似然估计值
[0096]
a1a2a3a4a5b1b2c0.9004-0.0042-0.1955-0.34310.11500.1304-0.036656.6978
[0097]
(4)利用学习好的模型进行预报
[0098]
将表1所示参数代入到公式(2)并将误差项去除,即可得到最终预报模型,如下式所示:
[0099]yt
=0.9004y
t-1-0.0042a2y
t-2-0.1955y
t-3-0.3431y
t-4
0.115y
t-5
[0100]
0.1304y
t-11-0.0366y
t-22
56.6978,
[0101]
利用此模型,可以预测未来一年的f10.7年均值。例如若t时刻设置为2021年,则将2016-2020、2010、1999年的数值输入到预报模型即可得到预测值。为了预测未来多年的数值,可采用递归调用的方式,即先预测未来一年,然后将该预测值作为模型的新输入预测未来第二年,以此类推,即可实现未来多年的预测。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。