1.本发明涉及信息处理技术领域,具体的说,涉及一种术后风险预测自然语言数据增强模型及方法。
背景技术:
2.术后风险预估通常被视为一个二分类的任务。统计机器学习模型被广泛地应用来解决这个问题,例如逻辑回归(logistic regression,ession,lr)和极致梯度提升(extreme gradient boosting,xgboost)。基于向量的lr方法将离散型和连续型变量都进行标准化处理后输入到模型,基于树模型的xgboost模型直接利用结构化的数据进行训练。
3.在最近的研究工作中,因为深度学习其自身的复杂的特征表达能力和预测性能,有许多研究人员开始利用深度学习来解决预测病人术后风险的问题。在这些研究当中,围术期的表格数据是主要的数据来源,它包含了患者的基本信息、实验室检查值以及许多其他的离散型和数值型特征。通常对于离散型变量的处理是进行向量化处理将其变成独热向量或者分布式向量,对于连续型则是进行一个批标准化的处理方式。最后将连续型和离散型一起拼接输入到深度神经网络中进行训练。其中连续型变量作为单纯的数值型数值并未包含医学上的语义,例如“收缩压156”不能体现出高血压的语义。因此,对于连续型的处理通常会进行离散化的操作将其变为离散型变量。
4.但是,文本数据,例如术前诊断在目前的预测方法中没有得到充分的应用。实际上,术前诊断信息对于患者的术后风险评估相当重要。例如,术前诊断中含有“癌”和“高危”字样的患者相比于其他患者有更大的概率产生术后风险。为了更好地利用文本数据,通常采用词嵌入的方式来将文本数据转换为向量,而目前主流的研究方法则是采用预训练模型来获取基于上下文语义的动态词嵌入,例如bert。为了得到整体的句子嵌入,通常采用池化方式来处理词嵌入,常用方法有平均池化、最大池化和取cls向量。一般选取平均池化方式,因为其既快速又有效的特点。而有研究表明,不同领域数据训练得到的bert对于不同领域的效果也不一样,用医学语料集训练得到的medbert在医学领域下的性能更优秀。
5.在不同类型的数据融合技术方面,许多简单且朴素的方法是采用直接拼接的方式。而直接拼接的向量会存在信息冗余的问题,当含有无关信息的向量具有高纬度,而含有重要信息的向量具有低纬度时,拼接他们会使得冗余的信息占据大部分,导致真正关键的重要信息被忽略。
技术实现要素:
6.本发明的目的在于克服背景技术所提出的技术问题,提出了一种术后风险预测自然语言数据增强模型及方法。本发明主要基于在临床医疗领域内,利用深度学习模型,采用了医疗诊断文本记录以及实验室术前检查数据来对病人的术后风险做出评估,从而决定是否要为病人安排重症监护室床位以及其他医疗资源的分配,从而有效地减轻医院的医疗负担以及使得患者因术后并发症的死亡概率下降。
7.本发明的具体技术方案如下:根据本发明的第一技术方案,提供了一种术后风险预测自然语言数据增强模型,其特征在于,所述模型包括:离散化层,被配置为:将围术期下的表格数据的连续型特征转化为分类型特征;列嵌入层,被配置为:将围术期下的表格数据的离散型特征转换为离散型特征向量,以及将所述分类型特征转换为分类型特征向量,获得向量嵌入 ,其中指代离散型特征向量和分类型特征向量, 的范围属于1到m n,m为连续型特征数量,n为离散型特征数量;文本嵌入层,被配置为:基于术前诊断文本上下文来确定词嵌入;并将所述词嵌入通过一个平均池化的方式,得到一个完整的句子嵌入;特征交互层,被配置为:通过拼接将所述向量嵌入以及所述句子嵌入组合成一组向量;将输入的向量映射成三个向量矩阵,并将所述三个向量矩阵输入到注意力层中来获取两两特征之间注意力权重,得到一个语义向量。
8.优选的,所述三个向量矩阵均由查询向量、键向量和值向量组成。
9.优选的,所述离散化层,被配置为:根据数值特征的最大值和最小值将连续型特征转化为分类型特征。
10.优选的,所述文本嵌入层,被配置为:基于术前诊断文本,并利用预训练模型获取基于上下文语义的词嵌入,所述预训练模型的语料库根据实际的临床记录数据来调整更新。
11.优选的,所述模型还包括多层感知机,所述多层感知机被配置为:根据所述语义向量来得到术后风险的预测结果。根据本发明的第二技术方案,提供了一种术后风险预测自然语言数据增强方法,所述方法包括:将围术期下的表格数据的连续型特征转化为分类型特征;将围术期下的表格数据的离散型特征转换为离散型特征向量,以及将所述分类型特征转换为分类型特征向量,获得向量嵌入 ,其中 指代离散型特征向量和分类型特征向量,的范围属于1到m n,m为连续型特征数量,n为离散型特征数量;基于术前诊断文本上下文来确定词嵌入,并将所述词嵌入通过一个平均池化的方式,得到一个完整的句子嵌入;通过拼接将所述向量嵌入以及所述句子嵌入组合成一组向量;将输入的向量映射成三个向量矩阵,并将所述三个向量矩阵输入到注意力层中来获取两两特征之间注意力权重,得到一个语义向量。
12.优选的,所述三个向量矩阵均由由查询向量、键向量和值向量组成。
13.优选的,所述将连续型特征转化为分类型特征,具体包括:根据数值特征的最大值和最小值将连续型特征转化为分类型特征。
14.优选的,所述基于术前诊断文本上下文来确定词嵌入,具体包括:基于术前诊断文本,并利用预训练模型获取基于上下文语义的词嵌入,所述预训练模型的语料库根据实际的临床记录数据来调整更新。
15.优选的,在得到一个语义向量后,还包括步骤,根据所述语义向量来得到术后风险的预测结果。
16.根据本发明实施例的术后风险预测自然语言数据增强模型及方法,将自然语言数
据通过在医学领域数据集训练下得到的预训练模型medbert,通过这样的方式将其转换为向量。将表格数据中的离散型变量也通过实体嵌入的方式也转换为向量,而对于这两者不同类型的数据,选择了多头自注意力的方式来将其融合。注意力机制算法将特征之间的关联性提取得到,筛选出重要特征进行预测,从而能够将自然语言数据里的关键信息与表格数据的关键信息关联起来,达到了多类型信息融合的目的,首次地将自然语言数据纳入到了对术后风险预测的任务中来。
附图说明
17.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
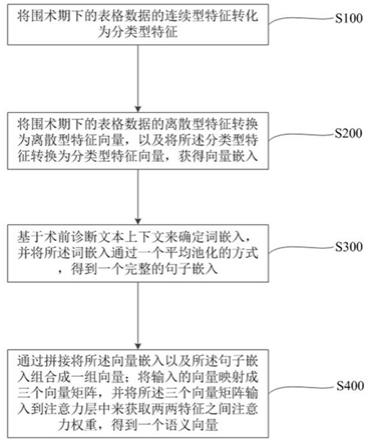
18.图1示出了根据本发明实施例的一种术后风险预测自然语言数据增强方法的流程图。
具体实施方式
19.下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
20.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定发明。
21.现在结合说明书附图对本发明做进一步的说明。
22.本发明实施例提供一种术后风险预测自然语言数据增强模型。该模型主要包含了离散化层、列嵌入层、文本嵌入层、连接层、特征交互层以及一个多层感知机。本文中,定义作为特征目标对。其中包含有、和.指代数量为m的连续型特征,指代数量为n的离散型特征,指代长度为l的术前诊断语句。
23.围术期下的表格数据中的某一特征通常含有医学上的语义。而数值型的特征,在医学领域内可能有不同的离散化区间标准。本发明实施例根据数值特征的最大值 和最小值
ꢀꢀ
将连续值划分为数量为b的离散值区间。这个离散化层的作用将连续型特征转化为分类型特征,使得特征含有了医学语义,并将转换后的特征定义为
ꢀꢀ
.列嵌入层的作用是将离散型特征转换为向量。本发明实施例中,不仅将离散型变量转换为向量,同时也将转换后的转换为’,和
ꢀ’
都是维度为d的向量。定义为向量嵌入,其中指代和’具体的特征向量,的范围属于1到m n。
24.文本嵌入层的作用是将非结构化的文本数据转换为向量的形式,方便深度学习模型利用。目前的最前沿获取文本嵌入的方法是利用预训练模型获取基于上下文语义的动态词嵌入,其中最具代表性的便是bert模型。bert模型是在一个非常巨大的语料库上通过无
监督的预训练得到的,可以用来生成基于上下文语义的词嵌入。除此之外,通过微调的方式可以大大提高预训练模型在特定领域下的词嵌入质量。因此,本发明可以利用在临床诊疗过程中产生的临床记录对通用领域的bert进行微调,获得针对医学领域的medbert。本发明实施例利用medbert来获取d
ꢀ’
维度的基于上下文的词嵌入,是指术前诊断文本中的第k个单词,k的范围是1到l。这些基于术前诊断文本获取的动态词嵌入通过一个平均池化的方式,最终得到一个完整的代表术前诊断的句子嵌入 .在进入到特征交互层之前,表格数据的嵌入都会通过列嵌入层得到,文本数据的嵌入通过文本嵌入得到。接着通过拼接的操作将他们组合成一组向量。将输入的向量 映射成三个矩阵q, k和v.,这三个向量矩阵分别是由查询向量k、键向量q和值向量v组成 。将其输入到注意力层中来获取两两特征之间注意力权重,在这个过程中,会有多个注意力头同时计算。通过计算,会将术前诊断中的语义信息和表格数据中的信息融合在一起,得到一个由文本数据信息增强的语义向量,再将其输入到一个多层感知机当中来得到术后风险的预测结果。
25.表格数据通常分为连续型和离散型,在医学领域中,连续型变量不能准确地反映出医学上的语义。因此,本发明实施例选择了采用离散化的方式将连续型变量转换为离散型变量,从而让每一个特征都展现出医学上的语义。本发明实施例实验了等距、等频和k-means三种离散化方式,等距离散化指依据最大值和最小值然后划分指定区间,等频离散化指离散化后每个区间的实例数量保持一致,k-means离散化指采用k-means聚类算法来将数据进行离散化。通过实验,发现离散化会赋予数据医学语义,同时使得数据更符合模型的输入形式,提升了模型的性能。通过实验比较发现,等距离散化是提升效果最大的离散化方式。
26.为了给表格数据补充其他语义信息,同时采用未被充分利用的自然语言数据信息。本发明实施例将自然语言数据通过在医学领域数据集训练下得到的预训练模型medbert,通过这样的方式将其转换为向量。将表格数据中的离散型变量也通过实体嵌入的方式也转换为向量,而对于这两者不同类型的数据,可以选择了多头自注意力的方式来将其融合。注意力机制算法将特征之间的关联性提取得到,筛选出重要特征进行预测,从而能够将自然语言数据里的关键信息与表格数据的关键信息关联起来,达到了多类型信息融合的目的,首次地将自然语言数据纳入到了对术后风险预测的任务中来。
27.图1示出了根据本发明实施例的一种术后风险预测自然语言数据增强方法的流程图。如图1所示,本发明实施例提供一种术后风险预测自然语言数据增强方法。该方法包括以下步骤:s100、将围术期下的表格数据的连续型特征转化为分类型特征。
28.在一些实施例中,根据数值特征的最大值和最小值将连续型特征转化为分类型特征。
29.s200、将围术期下的表格数据的离散型特征转换为离散型特征向量,以及将所述分类型特征转换为分类型特征向量,获得向量嵌入,其中指代离散型特征向量和分
类型特征向量,的范围属于1到m n,m为连续型特征数量,n为离散型特征数量。
30.s300、基于术前诊断文本上下文来确定词嵌入,并将所述词嵌入通过一个平均池化的方式,得到一个完整的句子嵌入。
31.在一些实施例中,基于术前诊断文本,并利用预训练模型获取基于上下文语义的词嵌入,所述预训练模型的语料库根据实际的临床记录数据来调整更新。
32.s400、通过拼接将所述向量嵌入以及所述句子嵌入组合成一组向量;将输入的向量映射成三个向量矩阵,并将所述三个向量矩阵输入到注意力层中来获取两两特征之间注意力权重,得到一个语义向量。
33.在一些实施例中,在得到一个语义向量后,还包括步骤,根据所述语义向量来得到术后风险的预测结果。
34.本发明实施例中方法的各个步骤所能达到的技术效果与模型的效果一致,在此不再累述。
35.本发明实施例针对于三个不同的术后风险分别进行了实验,分别是:肺部并发症、心血管不良和icu入室。首先在机器学习模型上进行了增加文本实验,两个机器学习模型分别是逻辑回归模型(logistic regression, lr)和极致梯度提升模型(extreme gradient boosting,xgb)。接着在深度学习模型实现了离散化和加入文本实验,wd指深度学习模型widedeep模型,同时为了检验本发明实施例模型方法的有效性,剔除了自身离散化方法和加入文本方法来进行实验。实验结果如表1所示,通过实验可以看出,在基于向量的方法的lr、wd和net中,加入文本都会提升模型的性能,但是在基于树模型的xgb中,加入文本反而会使得模型的效果下降。最终,通过实验结果的比较可以看出我们的net模型的效果是最好的。
36.表1 实验结果表以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其
均应涵盖在本发明的权利要求和说明书的范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
