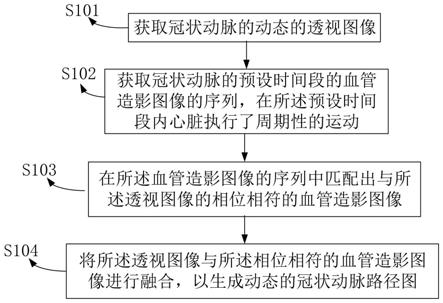
1.本发明属于监控视频
技术领域:
:,尤其是涉及一种基于深度神经网络的近重复视频大数据清洗方法。
背景技术:
::2.目前,随着网络上的视频数据规模不断增加,近重复视频数据大量涌现,这些近重复视频既会影响正常视频数据的使用,又会引起版权纠纷等社会问题,由此造成视频的数据质量问题越来越突出。因此目前产生了很多针对近重复视频检测与清洗的研究,以对视频数据进行清洗删除近重复视频数据,提高视频质量。3.现有的近重复视频检测方法包括基于低层特征的近重复视频检测方法、基于深度特征的近重复视频检测方法,但是现有的近重复视频检测方法只能识别出视频数据集中存在近重复视频,较难自动清洗和删除近重复视频这类数据,因此较难保证视频数据集的整体数据质量。4.另外,现有对近重复视频的清洗大多还停留在少量视频的检测阶段,较难在大数据规模的条件下,高效、自动的清洗近重复视频数据,这对视频大数据的质量造成了很大的影响。5.因此,现如今缺少一种基于深度神经网络的近重复视频大数据清洗方法,可以快速有效地自动清洗视频大数据中的近重复视频数据,改善视频大数据的数据质量。技术实现要素:6.本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于深度神经网络的近重复视频大数据清洗方法,其方法步骤简单,设计合理,可以快速有效地自动清洗视频大数据中的近重复视频数据,改善视频大数据的数据质量。7.为解决上述技术问题,本发明采用的技术方案是:一种基于深度神经网络的近重复视频大数据清洗方法,其特征在于,该方法包括以下步骤:步骤一、cnn-lstm神经网络对待处理视频的特征向量提取:采用计算机通过cnn-lstm神经网络分别对个待处理视频进行特征向量提取的方法均相同,其中对任一个待处理视频进行特征向量提取,具体过程如下:步骤101、采用计算机从任一个待处理视频中选取个视频帧,并将个视频帧分别输入vgg16神经网络中进行空间特征提取,得到个视频帧对应的空间特征向量;其中,为正整数;步骤102、采用计算机将步骤101中个视频帧对应的空间特征向量输入到lstm神经网络中,提取待处理视频的时空特征,得到一组初始特征向量;其中,第个初始特征向量为1024×1的向量,为正整数,且;步骤103、采用计算机调用pca主成分分析模块对步骤102中的一组初始特征向量进行降维处理,得到降维后特征向量,并存入hdfs中;其中,降维后特征向量为1024×1的向量,第个待处理视频的降维后特征向量记作第个特征向量,和均为正整数,且;步骤二、利用mapreduce框架对提取的特征向量进行局部敏感哈希映射并获取视频的二值化哈希码:步骤201、采用计算机利用hadoop分布式平台的mapreduce框架从hdfs中读取特征向量;步骤202、采用计算机利用mapreduce框架,在map阶段调用利用哈希函数族对第个特征向量进行哈希映射,得到第个特征向量对应的位二值化哈希码,并记作第个待处理视频的二值化哈希码向量;其中,为正整数;步骤203、多次重复步骤202,得到个待处理视频的二值化哈希码集合,且;步骤三、利用mapreduce框架归并具有相同二值化哈希码的数据点:步骤301、采用计算机利用mapreduce框架,在map阶段将个待处理视频的二值化哈希码集合中二值化哈希码向量赋值给关键字,将特征向量赋值给关键字值,则输出各个键值对;步骤302、采用计算机利用mapreduce框架,在map阶段,对各个键值对进行分区、合并,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对;步骤303、采用计算机利用mapreduce框架,在reduce阶段,将每个数据分区输出合并后键值对,根据关键字排序,并将相同的关键字对应的关键字值归并,得到归并后各个键值对并存入hdfs中;步骤四、根据归并后各个键值的欧式距离的分布情况得到近重复视频并删除,从而完成近重复视频的清洗:步骤401、采用计算机从hdfs中读取归并后各个键值,并将归并后每个键值的关键字值分别记作一个特征向量集合;步骤402、采用计算机对各个特征向量集合根据欧式距离的分布情况得到近重复视频,并将该近重复视频从待处理视频中删除,完成近重复视频的清洗。8.上述的一种基于深度神经网络的近重复视频大数据清洗方法,其特征在于:步骤202具体步骤如下:步骤2021、设定哈希函数族由个哈希函数,第个哈希函数记作,为正整数且,第个哈希函数,如下:;其中,表示哈希映射投影中实轴量化宽度,为[0,]范围内的随机数,为1024维向量,且每一维是一个独立选自满足p-stable分布的随机变量,表示内积运算,表示向下取整操作;步骤2022、采用计算机利用mapreduce框架,在map阶段利用lsh算法哈希函数族对第个特征向量进行哈希映射,得到第个特征向量对应的位哈希码;其中,表示第个特征向量对应的第个哈希码,为正整数且;步骤2023、采用计算机利用mapreduce框架根据,得到第个特征向量对应的第个二值化哈希码;其中,表示第个特征向量对应的位哈希码的中位数。[0009]上述的一种基于深度神经网络的近重复视频大数据清洗方法,其特征在于:步骤302中采用计算机用mapreduce框架,在map阶段,对各个键值对进行分区、合并,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对,具体过程如下:步骤3021、采用计算机将各个键值对,利用数据分区算法根据关键字将关键字值对分为多个数据分区;步骤3022、采用计算机在每个数据分区分别根据关键字排序,并将相同的关键字对应的关键字值合并,则每个数据分区输出合并后键值对,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对。[0010]上述的一种基于深度神经网络的近重复视频大数据清洗方法,其特征在于:步骤402中采用计算机对各个特征向量集合根据欧式距离的分布情况得到近重复视频,具体过程如下:步骤4021、采用计算机将第个键值的关键字值记作第个特征向量集合,为正整数,且,表示第个特征向量集合中特征向量的总数;步骤4022、采用计算机判断第个特征向量集合中特征向量的数量是否为1,如果第个特征向量集合中特征向量的数量为1,则第个特征向量集合不存在近重复视频,否则,执行步骤4023至步骤4026;步骤4023、采用计算机设定第个特征向量集合中各个特征向量分别记作,...,,...,;其中,表示第个特征向量集合中第个特征向量,和均为正整数,且,;步骤4024、采用计算机获取第个特征向量集合中第个特征向量和原点之间的欧式距离,并将第个特征向量集合中个欧式距离进行均值处理,得到第个特征向量集合的欧式距离平均值;步骤4025、采用计算机根据公式,得到第个特征向量的欧氏距离偏移量,并将各个欧氏距离偏移量从大到小排列,获取最小欧氏距离偏移量;步骤4026、采用计算机将第个特征向量集合中大于的特征向量对应的视频记作近重复视频;步骤4027、多次按照步骤4022至步骤4026所述的方法,完成所有特征向量集合的判断,得到近重复视频。[0011]本发明与现有技术相比具有以下优点:1、本发明方法步骤简单,设计合理,首先是cnn-lstm神经网络对待处理视频的特征向量提取,接着是利用mapreduce框架对提取的特征向量进行局部敏感哈希映射并获取视频的二值化哈希码,然后利用mapreduce框架归并具有相同二值化哈希码的数据点,最后根据归并后各个键值的欧式距离的分布情况得到近重复视频并删除,从而完成近重复视频的清洗,适应近重复视频大数据清洗。[0012]2、本发明利用深度神经网络对视频帧提取特征向量,利用mapreduce框架在map阶段对提取的高维特征向量通过局部敏感哈希映射,并在map阶段和reduce阶段实现个键值对的合并、归并,便于根据欧式距离的分布情况进行近重复视频清洗,利用深度神经网络和mapreduce框架相结合,可实现分布式的近重复视频清洗工作,大大加快了视频数据的处理速度,从而高效的完成近重复视频大数据清洗。[0013]综上所述,本发明方法步骤简单,设计合理,可以快速有效地自动清洗视频大数据中的近重复视频数据,改善视频大数据的数据质量。[0014]下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。附图说明[0015]图1为本发明的方法流程框图。具体实施方式[0016]如图1所示的一种基于深度神经网络的近重复视频大数据清洗方法,该方法包括以下步骤:步骤一、cnn-lstm神经网络对待处理视频的特征向量提取:采用计算机通过cnn-lstm神经网络分别对个待处理视频进行特征向量提取的方法均相同,其中对任一个待处理视频进行特征向量提取,具体过程如下:步骤101、采用计算机从任一个待处理视频中选取个视频帧,并将个视频帧分别输入vgg16神经网络中进行空间特征提取,得到个视频帧对应的空间特征向量;其中,为正整数;步骤102、采用计算机将步骤101中个视频帧对应的空间特征向量输入到lstm神经网络中,提取待处理视频的时空特征,得到一组初始特征向量;其中,第个初始特征向量为1024×1的向量,为正整数,且;步骤103、采用计算机调用pca主成分分析模块对步骤102中的一组初始特征向量进行降维处理,得到降维后特征向量,并存入hdfs中;其中,降维后特征向量为1024×1的向量,第个待处理视频的降维后特征向量记作第个特征向量,和均为正整数,且;步骤二、利用mapreduce框架对提取的特征向量进行局部敏感哈希映射并获取视频的二值化哈希码:步骤201、采用计算机利用hadoop分布式平台的mapreduce框架从hdfs中读取特征向量;步骤202、采用计算机利用mapreduce框架,在map阶段调用利用哈希函数族对第个特征向量进行哈希映射,得到第个特征向量对应的位二值化哈希码,并记作第个待处理视频的二值化哈希码向量;其中,为正整数;步骤203、多次重复步骤202,得到个待处理视频的二值化哈希码集合,且;步骤三、利用mapreduce框架归并具有相同二值化哈希码的数据点:步骤301、采用计算机利用mapreduce框架,在map阶段将个待处理视频的二值化哈希码集合中二值化哈希码向量赋值给关键字,将特征向量赋值给关键字值,则输出各个键值对;步骤302、采用计算机利用mapreduce框架,在map阶段,对各个键值对进行分区、合并,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对;步骤303、采用计算机利用mapreduce框架,在reduce阶段,将每个数据分区输出合并后键值对,根据关键字排序,并将相同的关键字对应的关键字值归并,得到归并后各个键值对并存入hdfs中;步骤四、根据归并后各个键值的欧式距离的分布情况得到近重复视频并删除,从而完成近重复视频的清洗:步骤401、采用计算机从hdfs中读取归并后各个键值,并将归并后每个键值的关键字值分别记作一个特征向量集合;步骤402、采用计算机对各个特征向量集合根据欧式距离的分布情况得到近重复视频,并将该近重复视频从待处理视频中删除,完成近重复视频的清洗。[0017]本实施例中,步骤202具体步骤如下:步骤2021、设定哈希函数族由个哈希函数,第个哈希函数记作,为正整数且,第个哈希函数,如下:;其中,表示哈希映射投影中实轴量化宽度,为[0,]范围内的随机数,为1024维向量,且每一维是一个独立选自满足p-stable分布的随机变量,表示内积运算,表示向下取整操作;步骤2022、采用计算机利用mapreduce框架,在map阶段利用lsh算法哈希函数族对第个特征向量进行哈希映射,得到第个特征向量对应的位哈希码;其中,表示第个特征向量对应的第个哈希码,为正整数且;步骤2023、采用计算机利用mapreduce框架根据,得到第个特征向量对应的第个二值化哈希码;其中,表示第个特征向量对应的位哈希码的中位数。[0018]本实施例中,步骤302中采用计算机用mapreduce框架,在map阶段,对各个键值对进行分区、合并,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对,具体过程如下:步骤3021、采用计算机将各个键值对,利用数据分区算法根据关键字将关键字值对分为多个数据分区;步骤3022、采用计算机在每个数据分区分别根据关键字排序,并将相同的关键字对应的关键字值合并,则每个数据分区输出合并后键值对,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对。[0019]本实施例中,步骤402中采用计算机对各个特征向量集合根据欧式距离的分布情况得到近重复视频,具体过程如下:步骤4021、采用计算机将第个键值的关键字值记作第个特征向量集合,为正整数,且,表示第个特征向量集合中特征向量的总数;步骤4022、采用计算机判断第个特征向量集合中特征向量的数量是否为1,如果第个特征向量集合中特征向量的数量为1,则第个特征向量集合不存在近重复视频,否则,执行步骤4023至步骤4026;步骤4023、采用计算机设定第个特征向量集合中各个特征向量分别记作,...,,...,;其中,表示第个特征向量集合中第个特征向量,和均为正整数,且,;步骤4024、采用计算机获取第个特征向量集合中第个特征向量和原点之间的欧式距离,并将第个特征向量集合中个欧式距离进行均值处理,得到第个特征向量集合的欧式距离平均值;步骤4025、采用计算机根据公式,得到第个特征向量的欧氏距离偏移量,并将各个欧氏距离偏移量从大到小排列,获取最小欧氏距离偏移量;步骤4026、采用计算机将第个特征向量集合中大于的特征向量对应的视频记作近重复视频;步骤4027、多次按照步骤4022至步骤4026所述的方法,完成所有特征向量集合的判断,得到近重复视频。[0020]本实施例中,为大于1的正整数。[0021]本实施例中,个视频帧的大小均为w×h×c,w×h表示视频帧的大小,c表示视频帧的通道数,且w和h均为224,c=3。[0022]本实施例中,vgg16神经网络由于其网络的深度,可以用于提取空间特征和高精度的图像识别,在解决图像定位与分类问题中表现出优异的性能。但是,vgg16神经网络较难准确地表示输入视频序列的时序关系。为了克服这种局限性,采用lstm网络来提取视频流中的动态时序行为特征。[0023]本实施例中,vgg16神经网络包括13个卷积层和3个全连接层,卷积层和全连接层的激活函数均为relu激活函数,3个全连接层分别为fc1全连接层,fc2全连接层和fc3全连接层,fc1全连接层,fc2全连接层和fc3全连接层的神经元个数分别为4096,4096,1000,每个卷积层的滑动步长为1,每个卷积层的卷积核为3×3×3。[0024]本实施例中,实际使用时,fc3全连接层用于分类任务,本发明只需要提取特征不用分类,因此经过fc1全连接层和fc2全连接层后得到空间特征向量,且各个视频帧对应的空间特征向量均为4096维的空间特征向量。[0025]本实施例中,哈希函数族采用局部敏感哈希函数,lsh算法即局部敏感哈希(localitysensitivehashing,lsh)算法。[0026]本实施例中,例如设=12,则映射得到12位哈希码,假设映射得到12位哈希码,如果按照从大到小排序后为n1》n3》n5》n7》n9》n11》n2》n4》n6》n8》n10》n12,那么二值化哈希码向量为(1,0,1,0,1,0,1,0,1,0,1,0)。[0027]本实施例中,本发明的目的是进行近重复视频的清洗,所以关键在于找到数据中的近重复视频,所以本方法采用欧式距离的分布情况分析,找到近重复视频,完成近重复视频的清洗。[0028]综上所述,本发明方法步骤简单,设计合理,可以快速有效地自动清洗视频大数据中的近重复视频数据,改善视频大数据的数据质量。[0029]以上所述,仅是本发明的较佳实施例,并非对本发明作任何限制,凡是根据本发明技术实质对以上实施例所作的任何简单修改、变更以及等效结构变化,均仍属于本发明技术方案的保护范围内。当前第1页12当前第1页12
技术领域:
:,尤其是涉及一种基于深度神经网络的近重复视频大数据清洗方法。
背景技术:
::2.目前,随着网络上的视频数据规模不断增加,近重复视频数据大量涌现,这些近重复视频既会影响正常视频数据的使用,又会引起版权纠纷等社会问题,由此造成视频的数据质量问题越来越突出。因此目前产生了很多针对近重复视频检测与清洗的研究,以对视频数据进行清洗删除近重复视频数据,提高视频质量。3.现有的近重复视频检测方法包括基于低层特征的近重复视频检测方法、基于深度特征的近重复视频检测方法,但是现有的近重复视频检测方法只能识别出视频数据集中存在近重复视频,较难自动清洗和删除近重复视频这类数据,因此较难保证视频数据集的整体数据质量。4.另外,现有对近重复视频的清洗大多还停留在少量视频的检测阶段,较难在大数据规模的条件下,高效、自动的清洗近重复视频数据,这对视频大数据的质量造成了很大的影响。5.因此,现如今缺少一种基于深度神经网络的近重复视频大数据清洗方法,可以快速有效地自动清洗视频大数据中的近重复视频数据,改善视频大数据的数据质量。技术实现要素:6.本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于深度神经网络的近重复视频大数据清洗方法,其方法步骤简单,设计合理,可以快速有效地自动清洗视频大数据中的近重复视频数据,改善视频大数据的数据质量。7.为解决上述技术问题,本发明采用的技术方案是:一种基于深度神经网络的近重复视频大数据清洗方法,其特征在于,该方法包括以下步骤:步骤一、cnn-lstm神经网络对待处理视频的特征向量提取:采用计算机通过cnn-lstm神经网络分别对个待处理视频进行特征向量提取的方法均相同,其中对任一个待处理视频进行特征向量提取,具体过程如下:步骤101、采用计算机从任一个待处理视频中选取个视频帧,并将个视频帧分别输入vgg16神经网络中进行空间特征提取,得到个视频帧对应的空间特征向量;其中,为正整数;步骤102、采用计算机将步骤101中个视频帧对应的空间特征向量输入到lstm神经网络中,提取待处理视频的时空特征,得到一组初始特征向量;其中,第个初始特征向量为1024×1的向量,为正整数,且;步骤103、采用计算机调用pca主成分分析模块对步骤102中的一组初始特征向量进行降维处理,得到降维后特征向量,并存入hdfs中;其中,降维后特征向量为1024×1的向量,第个待处理视频的降维后特征向量记作第个特征向量,和均为正整数,且;步骤二、利用mapreduce框架对提取的特征向量进行局部敏感哈希映射并获取视频的二值化哈希码:步骤201、采用计算机利用hadoop分布式平台的mapreduce框架从hdfs中读取特征向量;步骤202、采用计算机利用mapreduce框架,在map阶段调用利用哈希函数族对第个特征向量进行哈希映射,得到第个特征向量对应的位二值化哈希码,并记作第个待处理视频的二值化哈希码向量;其中,为正整数;步骤203、多次重复步骤202,得到个待处理视频的二值化哈希码集合,且;步骤三、利用mapreduce框架归并具有相同二值化哈希码的数据点:步骤301、采用计算机利用mapreduce框架,在map阶段将个待处理视频的二值化哈希码集合中二值化哈希码向量赋值给关键字,将特征向量赋值给关键字值,则输出各个键值对;步骤302、采用计算机利用mapreduce框架,在map阶段,对各个键值对进行分区、合并,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对;步骤303、采用计算机利用mapreduce框架,在reduce阶段,将每个数据分区输出合并后键值对,根据关键字排序,并将相同的关键字对应的关键字值归并,得到归并后各个键值对并存入hdfs中;步骤四、根据归并后各个键值的欧式距离的分布情况得到近重复视频并删除,从而完成近重复视频的清洗:步骤401、采用计算机从hdfs中读取归并后各个键值,并将归并后每个键值的关键字值分别记作一个特征向量集合;步骤402、采用计算机对各个特征向量集合根据欧式距离的分布情况得到近重复视频,并将该近重复视频从待处理视频中删除,完成近重复视频的清洗。8.上述的一种基于深度神经网络的近重复视频大数据清洗方法,其特征在于:步骤202具体步骤如下:步骤2021、设定哈希函数族由个哈希函数,第个哈希函数记作,为正整数且,第个哈希函数,如下:;其中,表示哈希映射投影中实轴量化宽度,为[0,]范围内的随机数,为1024维向量,且每一维是一个独立选自满足p-stable分布的随机变量,表示内积运算,表示向下取整操作;步骤2022、采用计算机利用mapreduce框架,在map阶段利用lsh算法哈希函数族对第个特征向量进行哈希映射,得到第个特征向量对应的位哈希码;其中,表示第个特征向量对应的第个哈希码,为正整数且;步骤2023、采用计算机利用mapreduce框架根据,得到第个特征向量对应的第个二值化哈希码;其中,表示第个特征向量对应的位哈希码的中位数。[0009]上述的一种基于深度神经网络的近重复视频大数据清洗方法,其特征在于:步骤302中采用计算机用mapreduce框架,在map阶段,对各个键值对进行分区、合并,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对,具体过程如下:步骤3021、采用计算机将各个键值对,利用数据分区算法根据关键字将关键字值对分为多个数据分区;步骤3022、采用计算机在每个数据分区分别根据关键字排序,并将相同的关键字对应的关键字值合并,则每个数据分区输出合并后键值对,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对。[0010]上述的一种基于深度神经网络的近重复视频大数据清洗方法,其特征在于:步骤402中采用计算机对各个特征向量集合根据欧式距离的分布情况得到近重复视频,具体过程如下:步骤4021、采用计算机将第个键值的关键字值记作第个特征向量集合,为正整数,且,表示第个特征向量集合中特征向量的总数;步骤4022、采用计算机判断第个特征向量集合中特征向量的数量是否为1,如果第个特征向量集合中特征向量的数量为1,则第个特征向量集合不存在近重复视频,否则,执行步骤4023至步骤4026;步骤4023、采用计算机设定第个特征向量集合中各个特征向量分别记作,...,,...,;其中,表示第个特征向量集合中第个特征向量,和均为正整数,且,;步骤4024、采用计算机获取第个特征向量集合中第个特征向量和原点之间的欧式距离,并将第个特征向量集合中个欧式距离进行均值处理,得到第个特征向量集合的欧式距离平均值;步骤4025、采用计算机根据公式,得到第个特征向量的欧氏距离偏移量,并将各个欧氏距离偏移量从大到小排列,获取最小欧氏距离偏移量;步骤4026、采用计算机将第个特征向量集合中大于的特征向量对应的视频记作近重复视频;步骤4027、多次按照步骤4022至步骤4026所述的方法,完成所有特征向量集合的判断,得到近重复视频。[0011]本发明与现有技术相比具有以下优点:1、本发明方法步骤简单,设计合理,首先是cnn-lstm神经网络对待处理视频的特征向量提取,接着是利用mapreduce框架对提取的特征向量进行局部敏感哈希映射并获取视频的二值化哈希码,然后利用mapreduce框架归并具有相同二值化哈希码的数据点,最后根据归并后各个键值的欧式距离的分布情况得到近重复视频并删除,从而完成近重复视频的清洗,适应近重复视频大数据清洗。[0012]2、本发明利用深度神经网络对视频帧提取特征向量,利用mapreduce框架在map阶段对提取的高维特征向量通过局部敏感哈希映射,并在map阶段和reduce阶段实现个键值对的合并、归并,便于根据欧式距离的分布情况进行近重复视频清洗,利用深度神经网络和mapreduce框架相结合,可实现分布式的近重复视频清洗工作,大大加快了视频数据的处理速度,从而高效的完成近重复视频大数据清洗。[0013]综上所述,本发明方法步骤简单,设计合理,可以快速有效地自动清洗视频大数据中的近重复视频数据,改善视频大数据的数据质量。[0014]下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。附图说明[0015]图1为本发明的方法流程框图。具体实施方式[0016]如图1所示的一种基于深度神经网络的近重复视频大数据清洗方法,该方法包括以下步骤:步骤一、cnn-lstm神经网络对待处理视频的特征向量提取:采用计算机通过cnn-lstm神经网络分别对个待处理视频进行特征向量提取的方法均相同,其中对任一个待处理视频进行特征向量提取,具体过程如下:步骤101、采用计算机从任一个待处理视频中选取个视频帧,并将个视频帧分别输入vgg16神经网络中进行空间特征提取,得到个视频帧对应的空间特征向量;其中,为正整数;步骤102、采用计算机将步骤101中个视频帧对应的空间特征向量输入到lstm神经网络中,提取待处理视频的时空特征,得到一组初始特征向量;其中,第个初始特征向量为1024×1的向量,为正整数,且;步骤103、采用计算机调用pca主成分分析模块对步骤102中的一组初始特征向量进行降维处理,得到降维后特征向量,并存入hdfs中;其中,降维后特征向量为1024×1的向量,第个待处理视频的降维后特征向量记作第个特征向量,和均为正整数,且;步骤二、利用mapreduce框架对提取的特征向量进行局部敏感哈希映射并获取视频的二值化哈希码:步骤201、采用计算机利用hadoop分布式平台的mapreduce框架从hdfs中读取特征向量;步骤202、采用计算机利用mapreduce框架,在map阶段调用利用哈希函数族对第个特征向量进行哈希映射,得到第个特征向量对应的位二值化哈希码,并记作第个待处理视频的二值化哈希码向量;其中,为正整数;步骤203、多次重复步骤202,得到个待处理视频的二值化哈希码集合,且;步骤三、利用mapreduce框架归并具有相同二值化哈希码的数据点:步骤301、采用计算机利用mapreduce框架,在map阶段将个待处理视频的二值化哈希码集合中二值化哈希码向量赋值给关键字,将特征向量赋值给关键字值,则输出各个键值对;步骤302、采用计算机利用mapreduce框架,在map阶段,对各个键值对进行分区、合并,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对;步骤303、采用计算机利用mapreduce框架,在reduce阶段,将每个数据分区输出合并后键值对,根据关键字排序,并将相同的关键字对应的关键字值归并,得到归并后各个键值对并存入hdfs中;步骤四、根据归并后各个键值的欧式距离的分布情况得到近重复视频并删除,从而完成近重复视频的清洗:步骤401、采用计算机从hdfs中读取归并后各个键值,并将归并后每个键值的关键字值分别记作一个特征向量集合;步骤402、采用计算机对各个特征向量集合根据欧式距离的分布情况得到近重复视频,并将该近重复视频从待处理视频中删除,完成近重复视频的清洗。[0017]本实施例中,步骤202具体步骤如下:步骤2021、设定哈希函数族由个哈希函数,第个哈希函数记作,为正整数且,第个哈希函数,如下:;其中,表示哈希映射投影中实轴量化宽度,为[0,]范围内的随机数,为1024维向量,且每一维是一个独立选自满足p-stable分布的随机变量,表示内积运算,表示向下取整操作;步骤2022、采用计算机利用mapreduce框架,在map阶段利用lsh算法哈希函数族对第个特征向量进行哈希映射,得到第个特征向量对应的位哈希码;其中,表示第个特征向量对应的第个哈希码,为正整数且;步骤2023、采用计算机利用mapreduce框架根据,得到第个特征向量对应的第个二值化哈希码;其中,表示第个特征向量对应的位哈希码的中位数。[0018]本实施例中,步骤302中采用计算机用mapreduce框架,在map阶段,对各个键值对进行分区、合并,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对,具体过程如下:步骤3021、采用计算机将各个键值对,利用数据分区算法根据关键字将关键字值对分为多个数据分区;步骤3022、采用计算机在每个数据分区分别根据关键字排序,并将相同的关键字对应的关键字值合并,则每个数据分区输出合并后键值对,并将每个数据分区输出合并后键值对作为reduce阶段的输入键值对。[0019]本实施例中,步骤402中采用计算机对各个特征向量集合根据欧式距离的分布情况得到近重复视频,具体过程如下:步骤4021、采用计算机将第个键值的关键字值记作第个特征向量集合,为正整数,且,表示第个特征向量集合中特征向量的总数;步骤4022、采用计算机判断第个特征向量集合中特征向量的数量是否为1,如果第个特征向量集合中特征向量的数量为1,则第个特征向量集合不存在近重复视频,否则,执行步骤4023至步骤4026;步骤4023、采用计算机设定第个特征向量集合中各个特征向量分别记作,...,,...,;其中,表示第个特征向量集合中第个特征向量,和均为正整数,且,;步骤4024、采用计算机获取第个特征向量集合中第个特征向量和原点之间的欧式距离,并将第个特征向量集合中个欧式距离进行均值处理,得到第个特征向量集合的欧式距离平均值;步骤4025、采用计算机根据公式,得到第个特征向量的欧氏距离偏移量,并将各个欧氏距离偏移量从大到小排列,获取最小欧氏距离偏移量;步骤4026、采用计算机将第个特征向量集合中大于的特征向量对应的视频记作近重复视频;步骤4027、多次按照步骤4022至步骤4026所述的方法,完成所有特征向量集合的判断,得到近重复视频。[0020]本实施例中,为大于1的正整数。[0021]本实施例中,个视频帧的大小均为w×h×c,w×h表示视频帧的大小,c表示视频帧的通道数,且w和h均为224,c=3。[0022]本实施例中,vgg16神经网络由于其网络的深度,可以用于提取空间特征和高精度的图像识别,在解决图像定位与分类问题中表现出优异的性能。但是,vgg16神经网络较难准确地表示输入视频序列的时序关系。为了克服这种局限性,采用lstm网络来提取视频流中的动态时序行为特征。[0023]本实施例中,vgg16神经网络包括13个卷积层和3个全连接层,卷积层和全连接层的激活函数均为relu激活函数,3个全连接层分别为fc1全连接层,fc2全连接层和fc3全连接层,fc1全连接层,fc2全连接层和fc3全连接层的神经元个数分别为4096,4096,1000,每个卷积层的滑动步长为1,每个卷积层的卷积核为3×3×3。[0024]本实施例中,实际使用时,fc3全连接层用于分类任务,本发明只需要提取特征不用分类,因此经过fc1全连接层和fc2全连接层后得到空间特征向量,且各个视频帧对应的空间特征向量均为4096维的空间特征向量。[0025]本实施例中,哈希函数族采用局部敏感哈希函数,lsh算法即局部敏感哈希(localitysensitivehashing,lsh)算法。[0026]本实施例中,例如设=12,则映射得到12位哈希码,假设映射得到12位哈希码,如果按照从大到小排序后为n1》n3》n5》n7》n9》n11》n2》n4》n6》n8》n10》n12,那么二值化哈希码向量为(1,0,1,0,1,0,1,0,1,0,1,0)。[0027]本实施例中,本发明的目的是进行近重复视频的清洗,所以关键在于找到数据中的近重复视频,所以本方法采用欧式距离的分布情况分析,找到近重复视频,完成近重复视频的清洗。[0028]综上所述,本发明方法步骤简单,设计合理,可以快速有效地自动清洗视频大数据中的近重复视频数据,改善视频大数据的数据质量。[0029]以上所述,仅是本发明的较佳实施例,并非对本发明作任何限制,凡是根据本发明技术实质对以上实施例所作的任何简单修改、变更以及等效结构变化,均仍属于本发明技术方案的保护范围内。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。