技术特征:
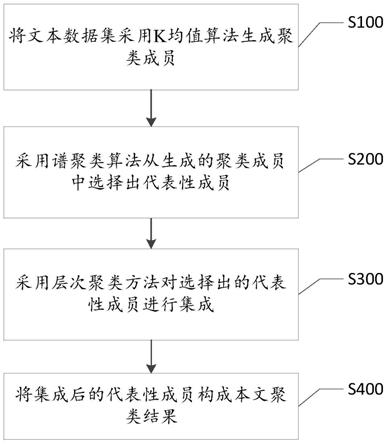
1.一种基于谱图理论的选择性文本聚类集成方法,其特征在于,包括:s100,将文本数据集采用k均值算法生成聚类成员;s200,采用谱聚类算法从生成的聚类成员中选择出代表性成员;s300,采用层次聚类方法对选择出的代表性成员进行集成;s400,将集成后的代表性成员构成本文聚类结果。2.根据权利要求1所述的基于谱图理论的选择性文本聚类集成方法,其特征在于,所述s200包括:s201,计算生成的聚类成员之间的相似度;s202,根据计算出的相似度,使用谱聚类算法对所述聚类成员进行聚类处理,获得聚类结果;所述聚类结果包括若干个聚类成员集合;s203,在所述聚类结果中,确定每个聚类成员集合中与其他聚类成员之间的归一化互信息值之差的绝对值之和最小的聚类成员;s204,该确定出的聚类成员作为代表性成员。3.根据权利要求2所述的基于谱图理论的选择性文本聚类集成方法,其特征在于,所述s202包括:s2021,确定要选出代表性成员的数量r0;s2022,根据计算出的聚类成员之间的相似度构造邻接矩阵,把邻接矩阵的每一列元素放加起来得到n个数,将每一列元素放在对角线上组成一个n*n阶的对角矩阵,称为度矩阵,基于所述邻接矩阵和度矩阵形成拉普拉斯矩阵;s2023,计算出拉普拉斯矩阵的前r0个特征值及对应的特征向量;s2024,将r0个特征向量中的列排列在一起形成n*r0阶矩阵,采用k-means算法对形成的n*r0阶矩阵进行聚类处理。4.根据权利要求1所述的基于谱图理论的选择性文本聚类集成方法,其特征在于,所述s100包括:s101,设置每个聚类中聚类成员个数r和聚类个数k;所述聚类个数k设置为真实类别数;s102,设置控制参数i的初始值为1;s103,判断所述控制参数i的值是否小于或等于聚类成员个数r;若是,则执行步骤s104,若否则执行步骤s107;s104,随机生成k个均值向量,作为k均值算法的初始质心,使用k均值算法对文本数据集进行划分;s105,根据划分结果得到聚类结果s106,将所述控制参数i的值加1,执行步骤s103;s107,构建聚类成员的集合p
′
={p
(1)
,p
(2)
,
…
,p
(r)
}。5.根据权利要求1所述的基于谱图理论的选择性文本聚类集成方法,其特征在于,所述s300包括:s301,将选择出的每一个代表性成员归为一类,基于每一类之间的距离确定类与类之间的相似度;
s302,基于层次聚类方法确定的类与类之间的相似度对类进行合并,形成新的类的集合;s303,再次计算新的类的结合中类与类之间的相似度,并基于相似度对类进行再次合并;s304,重复步骤s303,直至满足终止条件时,停止类的合并;s305,将满足终止条件时的类的合并结果作为代表性成员的集成结果。6.根据权利要求1所述的基于谱图理论的选择性文本聚类集成方法,其特征在于,所述s100之前包括:s500,将所有文本进行分词处理,以及无效词筛除处理,形成文本的有效分词特征;s600,将所有文本进行词义提取,获得词义特征;s700,计算所述分词特征与相应的词义特征之间的匹配关系,将所述分词特征和词义特征以及两者之间的匹配关系构建为文本特征,将所述文本特征形成文本数据集。7.根据权利要求4所述的基于谱图理论的选择性文本聚类集成方法,其特征在于,所述s104中使用k均值算法对文本数据集进行划分包括:s1041,计算所述文本数据集中每个文本与k个初始质心之间的余弦距离;s1042,基于所述余弦距离,将每一个文本划分入余弦距离最近的簇类中;s1043,重新计算每个簇类的质心以获得新的k个聚类质心;重复基于余弦距离,将每一个簇类划分入余弦距离最近的类中,直至k个聚类质心不再改变为止,停止划分,形成对文本数据集进行划分结果。8.根据权利要求7所述的基于谱图理论的选择性文本聚类集成方法,其特征在于,所述s1043中重新计算每个簇类的质心以获得新的k个聚类质心,包括:s1043-1,设定目标函数,所述目标函数标识簇类内余弦相似度和,以及设定目标函数中极大值点为中心的聚类质心;s1043-2,基于欧式距离与余弦相似度计算的函数转换关系,将目标函数的余弦相似度计算转换为欧式距离计算;s1043-3,对转换后的目标函数确定极小值点;s1043-4,根据极小值点的计算过程,确定极值点,所述极值点即为新的聚类质心。9.根据权利要求4所述的基于谱图理论的选择性文本聚类集成方法,其特征在于,所述s101之前包括:s108,对文本数据集中的文本向量进行标准化处理;s109,经过标准化处理的长文本在计算相似度时侧重于方向的变化,而不是数值的变化,采用余弦相似度更紧接文本向量之间的相似程度。10.根据权利要求1所述的基于谱图理论的选择性文本聚类集成方法,其特征在于,所述s100还包括:s110,从文本数据集中任意选择若干个文本向量作为初始聚类中心;s111,对于文本数据集中每个文本向量,计算每个文本向量与所有初始聚类中心之间的余弦相似度;s112,将所述余弦相似度值从最高到最低排序;s113,将文本向量分配给具有最高相似度的簇中;
s114,在满足限制条件的情况下,将文本向量按照顺序分配给相似高的合格簇;所述限制条件包括:最大可分配簇和相似度比值界限;所述最大可分配簇使每个样本点同时分配给的簇的数量不大于第一预设值;所述相似度比值界限是当某个文本向量与簇中心的距离大于离簇中心距离最小的文本向量于簇中心的距离乘以第二预设值;所述第二预设值小于1;s115,根据分配给各簇的文本重新计算若干各簇中心;s116,重复步骤s111至s115,直至算法收敛。
技术总结
本发明公开了一种基于谱图理论的选择性文本聚类集成方法,将文本数据集采用K均值算法生成聚类成员;采用谱聚类算法从生成的聚类成员中选择出代表性成员;采用层次聚类方法对选择出的代表性成员进行集成;将集成后的代表性成员构成本文聚类结果。解决了谱聚类方法直接应用于高维、稀疏、海量的文本数据集上时导致的计算量大的问题,因此,采用本方案显著降低文本聚类的计算时间,有效提高了文本聚类的准确性。另外,本实施例使用K均值算法作为基聚类器随机选取初始质心,算法复杂度低,提升算法的鲁棒性。法的鲁棒性。法的鲁棒性。
技术研发人员:徐森 陈明权 徐秀芳 花小朋 皋军 安晶 王江峰 嵇宏伟 姜陈雨 陆湘文
受保护的技术使用者:盐城工学院技术转移中心有限公司
技术研发日:2021.12.28
技术公布日:2022/4/12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。