1.本发明涉及一种领域专家行为轨迹的知识图谱构建方法,属于信息收集技术领域。
背景技术:
2.目前,我国科研事业繁荣发展,各个领域科研项目的数量随之增多,同时加大了对相关科研领域评审专家的需求。研究发现,同一领域的专家及项目申请者的行为轨迹中可能存在不同程度的交叉现象,彼此之间建立起密切的关系网络,为了保证评审专家团队的合理性与有效性,了解专家团队之间、专家与项目申请者之间的社会关系亲密度是保障项目评审公平公正的关键要素。
3.然而,领域专家人数众多,形成的关系网络错综复杂,难以进行系统性管理与清晰表示,进而造成了无法准确掌握关系信息的困难,消耗了大量的人工成本进行专家背景调查与社会关系统计的工作,严重影响评审专家团队的组建过程。近年来,知识图谱(knowledge graph,kg)的应用迅速发展,其中领域知识图谱的构建开始成为主流,作为描述海量知识实体关系的网络知识库,是存储社会关系网络的重要工具。整理全面的专家数据并针对领域专家在学习工作各个阶段的行为轨迹构建专家行为轨迹知识图谱,对了解彼此之间的关系亲密度,在评审专家的遴选过程中提供知识支撑具有重要研究意义。
4.2012年google公司提出了知识图谱的概念。其本质是一种表示实体之间关系的结构化语义网络,把海量的异构信息组织成有效知识的一种重要途径。构建的方式通常有自顶向下与自底向上两种方式。通用知识图谱大多采用自底向上的方式,便于融合更多的实体,而领域知识图谱面向特定领域,对知识的质量和准确度要求苛刻,因此要求领域知识图谱具有完备的本体层模式,通常采用自顶向下和自底向上相结合的构建方式。
5.领域知识图谱的构建主要面向医学行业,为智能问答的应用提供全面的知识基础。现有技术根据语义相似的问题模板及问题中的实体在知识图谱中搜索答案,实现了流水线式的原发性肝癌知识问答系统。也有基于知识图谱与关键词注意力机制,提出了中文医疗领域的问答匹配方法,解决了当前中文医疗领域高质量问答数据缺乏的问题。近年来,领域知识图谱的应用逐步扩展到交通、食品安全及专家推荐等各个行业,现有技术采用随机游走推理模型进行知识推理,构建高速公路风险车辆知识图谱,有效识别高速公路运行的潜在风险。文献利用食品安全案例知识图谱的关系结构和实体属性特征进行案例检索。还通过构建学术领域知识图谱、专家和论文候选关键词提取、图谱节点向量的加权映射及匹配相似度计算实现送审论文最佳匹配的专家推荐。
6.目前,在评审专家推荐的研究中,郑新宇等在《基于文本相似度的评审专家推荐方法研究》提出了一种基于内容的文本余弦相似度计算方法,曹涛宇等在《基于贪心搜素的分组项目评审专家遴选方法》中,在“项目-领域”与“专家-领域”两个相关性矩阵上应用科技项目评审专家多重匹配模型,利用待审科技项目与评审专家组合之间的匹配度遴选评审专家团队。两种推荐方法解决了人工遴选效率低、专家领域不吻合等问题。
bilstm-crf模型完成专家行为轨迹事件中地点名词的命名实体识别,基于bert提取字向量,输入bilstm层训练得到特征标签向量,crf层通过相邻标签的依赖关系获得识别序列。
25.进一步的,一种领域评审专家行为轨迹的知识图谱构建方法,其中,s32关系及关系属性抽取中,采用模式匹配、构建关系词库及词性标注的方法进行关系及关系属性的抽取,其中,专家行为轨迹知识图谱中存在专家实体间和专家地点实体间的两类关系,构成知识图谱中的边;
26.专家实体间的关系包含同事关系、校友关系、师生关系三种,从专家基本信息和专家论文信息中,利用模式匹配抽取关系及其属性;
27.专家地点实体间的关系包含学习关系、工作关系两种,基于预处理后的专家行为轨迹事件,首先构建学习行为和工作行为关系词库,根据两个关系词库抽取学习、工作关系及学习类型、工作职称属性;然后利用词性标注的方法完成时间类型属性的抽取。
28.进一步的,一种领域评审专家行为轨迹的知识图谱构建方法,其中,s4同名专家消歧,其中,分别进行s41基本信息特征相似度计算,s42专业领域特征相似度计算和s43行为轨迹特征相似度计算,并对计算结果进行求和,获得最终相似度。
29.进一步的,一种领域评审专家行为轨迹的知识图谱构建方法,其中,s41基本信息特征相似度计算,采用编辑距离对基本信息特征进行相似度计算,包括
30.s411,将基本信息特征中的属性特征表示为一个四元组形式
31.b={sex,birth,mail,degree},其中,四种属性特征为性别、出生年月、邮箱和学历;
32.s412以相对值指标代表每种属性特征的相似度
[0033][0034]
公式中,levenshteindist(t1,t2)表示两个字符串t1和t2的编辑距离,max{len(t1),len(t2)}表示t1和t2中字符串长度的最大值;
[0035]
s413采用层次分析法求得四种属性特征权重值,对每种相似度计算结果线性加权,得到两位同名专家在该类相似度特征的相似度
[0036]
bas_sim(b1,b2)=w_b
·
sim_b
[0037]
w_b=(wb1,wb2,wb3,wb4)
[0038][0039]
其中w_b表示相似度权重,wbi(1≤i≤4)分别表示四种属性特征相似度的权重分量;sim_b表示四种属性特征编辑距离相似度的四维行向量;
[0040]
s42专业领域特征近似度计算,将s31抽取的专家研究方向构建成一个大型语料库,采用word2vec的cbow模型训练并获得n维句向量,然后采用余弦相似度的方法进行计算;
[0041]
s43行为轨迹特征相似度计算,其中,行为特征中的属性特征以三元组的集合形式
表示,其算法包括:行为轨迹相似度匹配算法,其输入两位专家的行为轨迹属性特征集合behavior1和behavior2,输出行为轨迹相似度beh_sim,
[0042]
其过程为,s431相同行为地点识别:采用字符串匹配的方法遍历behavior1和behavior2,得到包含相同行为地点的行为轨迹特征三元组列表sabehavior1和sabehavior2;
[0043]
s432重合时间计算:依据列表sabehavior1和sabehavior2中每个三元组的start_timei和end_timei获得以年为单位的每段行为重合时长timei;
[0044]
s433相似度计算:统计两位同名专家各自的所有行为轨迹总时长time1和time2,计算每段行为重合时长求和结果与总时长time1和time2中较短时间的比值,得到行为轨迹相似度beh_sim,公式如下:
[0045][0046]
s44同名专家实体融合
[0047]
以上三类相似度特征的相似度值域为[0,1],对其进行相加求和获得同名专家相似度,计算公式为
[0048]
sim=bas_sim pro_sim beh_sim,
[0049]
完成专家行为轨迹知识图谱的构建。
[0050]
进一步的,一种领域评审专家行为轨迹的知识图谱构建方法,其中,s5用neo4j图数据库实现存储中,采用neo4j图数据库及py2neo框架实现行为轨迹知识图谱的数据存储与可视化。
[0051]
进一步的,一种领域评审专家行为轨迹的知识图谱构建方法,其中,还包括s6根据领域评审专家行为轨迹的知识图谱构建方法获得的行为轨迹知识图谱进行亲密度计算的步骤,
[0052]
其中,抽取以两名目标专家实体为端点的所有关系路径,分为直接关系路径与间接关系路径,通过对两种关系路径的亲密度求和获得最终的专家亲密度;
[0053]
包括s61直接关系路径亲密度计算,和s62间接关系路径亲密度计算;
[0054]
其中s61直接关系路径亲密度计算中,其密度计算关系为
[0055][0056][0057]
其中,w表示关系稳定期权重,time为关系路径的行为重合时长,yj为直接关系类型j的关系稳定期;q为关系路径亲密度,qj为直接关系j的关系亲密值,t为置信度;
[0058]
s62间接关系路径亲密度计算中,对间接关系路径做分阶处理,采用直接关系亲密度的计算方法求得每阶关系亲密度,进行乘积运算,结果作为该条间接关系路径的亲密度值,计算公式为,qk=q
1j
·q2j
·q3j
·
...
·qkj
[0059]
qk表示一条k阶间接关系路径亲密度,k表示关系阶数,q
tj
表示该条路径第t阶j类直接关系亲密度。
[0060]
进一步的,一种领域评审专家行为轨迹的知识图谱构建方法,其中,s61直接关系路径亲密度计算中,对于专家间存在的多条直接关系路径,从路径长度(关系边数)和关系类型两个角度出发,将长度相等且关系类型相同的关系路径亲密度求和,并控制其求和亲密度不超过关系亲密度qj,对长度相等的关系路径,依据关系类型做亲密度求和收束运算,qj为收束临界值,进而求得所有直接关系路径亲密度,收束公式为,
[0061][0062]
所有直接关系路径亲密度公式为
[0063][0064]
其中,e为关系路径长度,j为直接关系类型,r为e长度的j类直接关系路径数量,q
rej
表示第r条长度为e的j类直接关系路径亲密度,s
ej
表示所有关系路径长度为e的j类直接关系亲密度收束结果;qd为所有直接关系路径亲密度结果;
[0065]
s62间接关系路径亲密度计算中,从关系阶数和关系类型两个角度出发,将阶数相等且关系类型相同的关系路径亲密度做求和收束处理,收束临界值以关系路径中存在的一阶关系类型的最高亲密值qj为准,收束运算公式为
[0066][0067]
其中,s
kh
表示k阶h类间接关系路径的亲密度收束结果,q
rkh
表示第r条k阶h类间接关系路径亲密度,r为k阶h类间接关系路径数量,qj为收束临界值;
[0068]
对所有阶关系路径的亲密度收束结果做衰减计算后求和,得到所有间接关系路径亲密度,计算公式如下:
[0069][0070][0071]
其中,q
id
为所有间接关系路径亲密度,dk为衰减比重,k为专家间关系的最高阶数,sk为专家间k阶间接关系的所有间接关系类型亲密度,c为k阶所有间接关系类型数量,c为间接关系类型。
[0072]
本发明采用上述方案,取得了如下的技术效果。
[0073]
本发明针对难以掌握领域评审专家亲密度的问题,采用自顶向下与自底向上相结合的方法,构建了计算机科学领域评审专家行为轨迹的知识图谱,创新性的提出了基于行为轨迹的亲密度计算方法。首先,进行了专家信息的数据源采集与专家行为轨迹事件抽取;然后,基于领域本体确定知识图谱模式结构,利用自然语言处理技术完成知识抽取;最后,在利用编辑距离和余弦相似度计算方法的同时,提出了一种基于地点一致性与时间重合性相结合的行为轨迹相似度匹配算法,解决了同名专家歧义问题,实现了知识图谱的知识融
合。在同名专家消歧的实验中,与仅利用基础信息特征和专业领域特征相似度的消歧效果相比,融合了行为轨迹特征相似度的消歧效果有明显提升。
[0074]
本发明在行为轨迹的知识图谱中,通过同一领域专家行为轨迹中地点与时间的交叉联系,在专家直接关系的基础上推理出间接关系,对两种关系的亲密度求和,获得最终的专家亲密度,保证了专家亲密度计算的全面性。
附图说明
[0075]
为了更清楚地说明本发明的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定。
[0076]
图1为本发明的一种领域评审专家行为轨迹的知识图谱构建方法的构建框架示意图;
[0077]
图2为本发明的专家行为轨迹事件抽取示例;
[0078]
图3为本发明的专家行为轨迹图谱模式层结构示意图;
[0079]
图4为本发明的专家地点实体间关系及关系属性抽取举例;
[0080]
图5为采用本发明的一种领域评审专家行为轨迹的知识图谱构建方法构建专家行为轨迹知识图谱示例图;
[0081]
图6为本发明的直接关系路径模型示例图;
[0082]
图7为本发明的间接关系路径模型示意图;
[0083]
图8为同名专家消歧实验结果图;
[0084]
图9为本发明的亲密度计算实验结果图。
具体实施方式
[0085]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
[0086]
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0087]
在本发明实施例的描述中,需要说明的是,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
[0088]
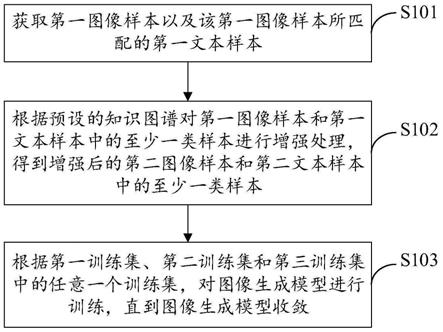
参见图1,本发明提供一种领域评审专家行为轨迹的知识图谱构建方法,包括以下步骤:
[0089]
s1领域专家信息的采集与预处理;
[0090]
s2构建领域本体及确定知识图谱模式结构;
[0091]
s3实体、属性和关系的知识抽取;
[0092]
s4同名专家消歧;
[0093]
s5用neo4j图数据库实现存储。
[0094]
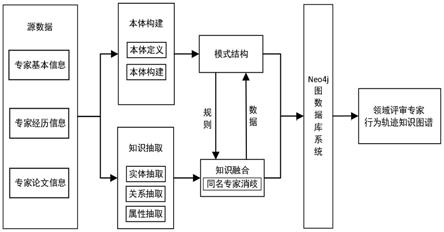
进一步的,本发明的一种领域评审专家行为轨迹的知识图谱构建方法,s1领域专家信息的采集与预处理中,对领域专家进行数据采集时,采用网络爬虫框架webmagic对数据源进行采集,采用ip代理池及处理机制,防止未知错误引起的爬虫程序中断。
[0095]
其中,所述的领域专家信息包括专家基本信息、专家经历信息与专家论文信息。更为细节的,专家基本信息包括专家姓名、性别、毕业院校、工作地点等;专家经历信息包括专家学习及工作经历中的行为轨迹,记录专家某段时间在某个地点进行的学习或工作行为;专家论文信息是专家发表的硕士或博士毕业论文及导师姓名。
[0096]
具体的,专家基本信息与专家经历信息主要基于专家的简历内容,且领域专家大多在高等院校任职,其采集的数据源包括高校教师主页、百度百科;专家论文信息采集的数据源包括知网博硕论文数据库、万方论文数据库。
[0097]
对采集的领域专家信息进行预处理时,对爬取的领域专家信息数据做词语替换词、去除停用词等预处理。
[0098]
其中专家基本信息与专家论文信息是一种半结构化形式的数据,内容中包含姓名等待提取字段的标识词,而专家经历信息的内容是一种文本式的非结构化数据。因此,本发明首先采用对专家基本信息与专家经历信息做分开处理,然后针对专家经历信息文本的特点做语句分割,利用触发词实现专家经历中行为轨迹的事件抽取。
[0099]
进一步的,本发明的一种领域评审专家行为轨迹的知识图谱构建方法,s2构建领域本体及确定知识图谱模式结构中,定义专家知识本体和地点知识本体两类知识本体,并基于两类知识本体定义两类本体间关系:专家与专家本体间关系以及专家与地点本体间关系。
[0100]
专家行为轨迹主要由行为开始时间、行为结束时间、行为地点及行为类型构成。相同领域的专家总是交汇于同一地点,进而建立关系网络,因此,本发明定义专家知识本体和地点知识本体两类知识本体。
[0101]
其中,参见表1,专家知识本体是指评审专家个人基本信息的描述,包括专家姓名、性别、毕业院校、工作地点等;地点知识本体是指评审专家每段行为的发生地点,包括地点名称。
[0102]
参见表2,专家与专家本体间关系类型包括同事关系、校友关系、师生关系等,关系属性分别对应为工作地点、毕业院校、发表论文等;专家与地点本体间关系类型包括学习关系和工作关系,关系属性分别对应为:开始时间,结束时间和学习类型,以及开始时间、结束时间和工作职称。
[0103]
参见下表1和表2,为专家行为轨迹本体定义信息和专家行为轨迹本体间定义信息表。
[0104]
表1专家行为轨迹本体定义信息
[0105][0106]
表2专家行为轨迹本体间关系定义信息
[0107][0108]
本发明中,本体的构建满足完整性、清晰性、一致性、可扩展性和兼容性的评价标准。依据构建的本体形成专家行为轨迹知识图谱的模式层,模式层结构设计如附图3所示。
[0109]
其中,本体形成轨迹知识图谱中的点,本体间关系形成轨迹知识图谱中的线。
[0110]
进一步的,本发明的一种领域评审专家行为轨迹的知识图谱构建方法,s3实体、属性和关系的知识抽取中,包括
[0111]
s31实体及实体属性抽取
[0112]
本发明基于模式匹配与命名实体识别的方法进行实体及实体属性的抽取,专家行为轨迹知识图谱中存在专家实体与地点实体两种实体。
[0113]
专家实体及其属性是从专家基本信息中,利用标识词模式匹配的方式抽取,形成结构化的数据。其中,实体的抽取模式为:专家实体=《专家姓名》,属性的抽取模式为:{name,sex,nationality,birthday,contact,mail,graduated,degree,career,title,research,unit,location}=《姓名,性别,国籍,出生日期,联系方式,邮箱,毕业院校,学历,职业,职称,研究方向,工作单位,工作地点》。
[0114]
地点实体及其属性的抽取是在s1中预处理后的专家行为轨迹事件中,利用bert-bilstm-crf模型完成专家行为轨迹事件中地点名词的命名实体识别。基于bert提取字向量,输入bilstm层训练得到特征标签向量,crf层通过相邻标签的依赖关系获得识别序列。命名实体识别的结果如表3所示:
[0115]
表3专家行为轨迹事件地点识别结果
[0116]
专家行为轨迹事件识别地点2005年至2009年西安电子科技大学电子信息工程专业本科西安电子科技大学2009年至2012年清华大学自动化专业研究生清华大学2015年获东京大学信息科学与技术专业博士学位东京大学
2015至2016在东京大学从事博士后研究工作东京大学2016年到北京理工大学计算机学院工作北京理工大学
[0117]
s32关系及关系属性抽取
[0118]
本发明采用模式匹配、构建关系词库及词性标注的方法进行关系及关系属性的抽取,专家行为轨迹知识图谱中存在专家实体间和专家地点实体间的两类关系,构成知识图谱中的边。
[0119]
其中,专家实体间的关系包含同事关系、校友关系、师生关系三种。同事关系是指当前在相同工作地点工作的专家关系;校友关系是指在相同一所院校毕业的专家关系;师生关系是指共同发表过博硕毕业论文的专家关系。基于三种关系特征,从专家基本信息和专家论文信息中,利用模式匹配抽取关系及其属性。
[0120]
专家地点实体间的关系包含学习关系、工作关系两种。学习关系是指专家在该地点进行学习行为的关系;工作关系是指专家在该地点进行工作行为的关系。基于s1中预处理后的专家行为轨迹事件,首先构建学习行为(研究生、硕士学位等)和工作行为(讲师、教授等)关系词库,根据两个关系词库抽取学习、工作关系及学习类型、工作职称属性;然后利用词性标注的方法完成时间类型属性的抽取。
[0121]
进一步的,本发明的一种领域评审专家行为轨迹的知识图谱构建方法,s4同名专家消歧,具体包括以下内容。
[0122]
在获取专家数据的过程中,会出现大量相同姓名专家的现象。为了确保专家数据的准确性,避免知识图谱产生实体歧义的问题,本发明对同名专家的数据进行消歧处理,即识别出同名专家是否指代同一个人。
[0123]
具体的,本发明利用专家多种属性特征,分为三类相似度特征:基本信息特征、专业领域特征和行为轨迹特征。
[0124]
更为细节的,其中基本信息特征包括:性别、出生年月、邮箱、学历;专业领域特征为研究方向;行为轨迹特征包括:行为地点、开始时间和结束时间。
[0125]
针对三类相似度特征中的属性特点,采用三种不同的方法计算各个相似度特征的相似度,对其计算结果求和,获得最终相似度。对比最优效果阈值,完成同名专家消歧,实现实体融合。
[0126]
其中,s41基本信息特征相似度计算
[0127]
其中包括s411,将基本信息特征中的属性特征表示为一个四元组形式。
[0128]
采用编辑距离对基本信息特征进行字面相似度计算,基本信息特征中的属性特征表示为一个四元组形式,表示结构如计算公式(1)所示:
[0129]
b={sex,birth,mail,degree}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0130]
该四种属性特征为性别、出生年月、邮箱和学历,都是长度较短的短语,不需要考虑上下文的语义信息,因此采用编辑距离(levenshtein distance)对此类相似度特征进行字面相似度计算。编辑距离表示两个字符串序列之间,从一个转化为另一个所需要进行的最少编辑次数,编辑指对字符串序列进行替换、插入和删除的操作。
[0131]
s412以相对值指标代表每种属性特征的相似度
[0132]
编辑距离表示了字符串序列之间的绝对差异,但在属性特征的相似度匹配问题中,需要以一个相对的指标代表每种属性特征的相似程度,计算公式如(2)所示:
[0133][0134]
公式中,levenshteindist(t1,t2)表示两个字符串t1和t2的编辑距离,max{len(t1),len(t2)}表示t1和t2中字符串长度的最大值。
[0135]
s413采用层次分析法求得四种属性特征权重值,对每种相似度计算结果线性加权,得到两位同名专家在该类相似度特征的相似度
[0136]
根据属性特征的消歧能力,采用层次分析法求得四种属性特征权重值,对每种相似度计算结果线性加权,得到两位同名专家在该类相似度特征《b1,b2》的相似度bas_sim(b1,b2),计算公式如(3)所示:
[0137]
bas_sim(b1,b2)=w_b
·
sim_b
ꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0138]
w_b=(wb1,wb2,wb3,wb4)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0139][0140]
其中w_b表示相似度权重,wbi(1≤i≤4)分别表示四种属性特征相似度的权重分量,其中性别为性别为0.19,出生年月为0.78,邮箱为0.015,学历为0.015;sim_b表示四种属性特征编辑距离相似度的四维行向量。
[0141]
参见表4,为基本信息特征消歧能力强弱表。
[0142]
表4基本信息特征消歧能力强弱表
[0143]
属性属性符号消歧能力强弱性别sex中出生年月bitrh强邮箱mail弱学历degree弱
[0144]
s42专业领域特征相似度计算
[0145]
专业领域特征中的研究方向大多是语句描述,为了准确计算其相似度,将s31抽取的专家研究方向构建成一个大型语料库,采用word2vec的cbow模型训练并获得n维句向量,然后采用余弦相似度的方法进行计算,计算公式如(6)所示:
[0146][0147]
公式中,pro_sim(p1,p2)表示两位同名专家在专业领域特征类中的相似度,p
1i
和p
2i
分别表示特征向量p1和p2的各分量。
[0148]
s43行为轨迹特征相似度计算
[0149]
行为轨迹特征中的属性特征以三元组的集合形式表示,表示结构如(7)所示:
[0150][0151]
从行为地点和行为时间两个角度的属性特征出发,本发明提出了一种基于地点一致性与时间重合性相结合的行为轨迹相似度匹配算法。根据两位同名专家经历的同一行为地点,计算两者在此停留的时间重合度,进而获得专家行为轨迹的相似程度。具体的算法描述过程如下:
[0152]
算法:行为轨迹相似度匹配算法
[0153]
输入:两位专家的行为轨迹属性特征集合behavior1和behavior2[0154]
输出:行为轨迹相似度beh_sim
[0155]
过程:
[0156]
s431相同行为地点识别:采用字符串匹配的方法遍历behavior1和behavior2,得到包含相同行为地点的行为轨迹特征三元组列表sabehavior1和sabehavior2;
[0157]
s432重合时间计算:依据列表sabehavior1和sabehavior2中每个三元组的start_timei和end_timei获得以年为单位的每段行为重合时长timei;
[0158]
s433相似度计算:统计两位同名专家各自的所有行为轨迹总时长time1和time2,计算每段行为重合时长求和结果与总时长time1和time2中较短时间的比值,得到行为轨迹相似度beh_sim,公式如(8)所示:
[0159][0160]
s44同名专家实体融合
[0161]
以上三类相似度特征的相似度值域为[0,1],对其进行相加求和,获得同名专家相似度,计算公式如(9)所示:
[0162]
sim=bas_sim pro_sim beh_sim
ꢀꢀ
(9)
[0163]
多特征融合的同名专家相似度计算方法,消除相同姓名造成的实体歧义问题,完成专家行为轨迹知识图谱的构建。
[0164]
进一步的,本发明的一种领域评审专家行为轨迹的知识图谱构建方法,s5用neo4j图数据库实现存储。
[0165]
知识图谱中包含11029个实体,53119条关系,本发明利用neo4j图数据库及py2neo框架实现行为轨迹知识图谱的数据存储与可视化,部分实例展示如图5所示。
[0166]
neo4j作为一种常用的图数据库,支持类似sql的cypher语言,提供有效的遍历算法来支持知识的多层复杂查询。通过实体和关系的属性,设置查询语句识别专家间存在的关系路径,从而指导专家的亲密度计算。
[0167]
进一步的,本发明还包括s6根据领域评审专家行为轨迹的知识图谱构建方法获得的行为轨迹知识图谱进行亲密度计算的步骤。
[0168]
为清楚掌握评审专家之间以及评审专家与项目申请者之间的关系亲密度,保证专家团队评审结果的科学性与有效性,本发明依据构建的专家行为轨迹知识图谱,抽取以两
名目标专家实体为端点的所有关系路径,分为直接关系路径与间接关系路径,通过对两种关系路径的亲密度求和获得最终的专家亲密度。
[0169]
s61直接关系路径亲密度计算
[0170]
直接关系路径指无中间实体或存在一个中间地点实体的路径,其知识图谱路径模型如图6所示。采用实体间关系属性的知识推理识别专家直接关系类型,包括师生、校友、同事关系,分别赋予不同的亲密值,其中,师生关系为0.3,校友关系为0.2,同事关系为0.5。
[0171]
对于存在一个中间地点实体的路径,需考虑两位目标专家实体在此地的行为相处时长及可信度。本发明内引入关系稳定期比重与置信度的概念,对亲密值做加权处理,完成该条关系路径的亲密度计算。关系稳定期是指三种关系稳定建立的时间期限,关系稳定期比重计算公式如(10)所示,亲密度计算公式如(11)所示,关系类型信息见表5。
[0172]
表5直接关系类型信息
[0173]
关系类型关系名称关系稳定期(年)关系亲密值1师生关系y1q12校友关系y2q23同事关系y3q3[0174][0175][0176]
其中,w表示关系稳定期权重,time为关系路径的行为重合时长,yj为直接关系类型j的关系稳定期;q为关系路径亲密度,qj为直接关系j的关系亲密值,t为置信度。
[0177]
对于专家间存在的多条直接关系路径,从路径长度(关系边数)和关系类型两个角度出发,将长度相等且关系类型相同的关系路径亲密度求和,并控制其求和亲密度不超过关系亲密度qj。因此,对长度相等的关系路径,依据关系类型做亲密度求和收束运算,qj为收束临界值,进而求得所有直接关系路径亲密度。收束公式如(12)所示,所有直接关系路径亲密度如(13)所示:
[0178][0179][0180]
e为关系路径长度,j为直接关系类型,r为e长度的j类直接关系路径数量,q
rej
表示第r条长度为e的j类直接关系路径亲密度,s
ej
表示所有关系路径长度为e的j类直接关系亲密度收束结果;qd为所有直接关系路径亲密度结果。
[0181]
s62间接关系路径亲密度计算
[0182]
间接关系路径指存在中间专家实体或同时存在中间专家和中间地点实体的路径,其知识图谱路径模型如图7所示。间接关系是由以上3种直接关系,即一阶关系组合而成的
二阶或多阶专家关系,示例如表6所示。
[0183]
表6间接关系类型信息
[0184][0185]
对间接关系路径做分阶处理,采用直接关系亲密度的计算方法求得每阶关系亲密度,进行乘积运算,结果作为该条间接关系路径的亲密度值,计算公式如(14)所示:
[0186]
qk=q
1j
·q2j
·q3j
·
...
·qkj
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0187]
qk表示一条k阶间接关系路径亲密度,k表示关系阶数,q
tj
表示该条路径第t阶j类直接关系亲密度。
[0188]
同样,对于专家间存在的多条间接关系路径,从关系阶数和关系类型两个角度出发,将阶数相等且关系类型相同的关系路径亲密度做求和收束处理,收束临界值以关系路径中存在的一阶关系类型的最高亲密值qj为准,收束运算公式如(15)所示:
[0189][0190]skh
表示k阶h类间接关系路径的亲密度收束结果,q
rkh
表示第r条k阶h类间接关系路径亲密度,r为k阶h类间接关系路径数量,qj为收束临界值。
[0191]
在此基础上,本文引入衰减比重的概念,在专家的间接关系中,两者的关系阶数越大,亲密程度越弱,其衰减程度越大。对所有阶关系路径的亲密度收束结果做衰减计算后求和,得到所有间接关系路径亲密度,计算公式如(16)所示:
[0192][0193][0194]qid
为所有间接关系路径亲密度,dk为衰减比重,k为专家间关系的最高阶数,sk为专家间k阶间接关系的所有间接关系类型亲密度,c为k阶所有间接关系类型数量,c为间接关系类型。
[0195]
实验例及分析
[0196]
1、直接同名专家消歧实验与结果分析
[0197]
同名专家消歧是构建知识图谱的重要步骤,其消歧准确性直接影响专家亲密度计算的应用效果。专家的三类相似度特征中,基础信息特征和专业领域特征是同名专家消歧的常用特征,而行为轨迹特征具有的唯一性,在一定程度上也会影响同名专家的消歧效果。针对上述设想,本发明设计了两组对照实验,同时避免单一评价指标的偶然性,采用准确率(accuracy)、精确率(precision)、召回率(recall)和f1值(f-measure)对同名专家消歧进
行效果评价,指标计算公式如(18),(19),(20),(21)所示:
[0198][0199][0200][0201][0202]
其中,tp表示预测正确的同名不同人专家组合数量,tn表示预测正确的同名同人专家组合数量,fp和fn分别表示预测错误的同名同人专家组合数量和同名不同人专家组合数量;f1值为精确率和召回率二者的综合指标,其值越接近100%,说明消歧效果越好,反之效果越差。
[0203]
实验1:将专家数据中的同名专家两两组合,分别采用编辑距离和余弦相似度的方法完成其基本信息特征相似度和领域特征相似度计算。依据层次分析法,基本信息特征类中的4种属性特征的消歧权重如表7所示。经过反复实验,对两类相似度特征的计算结果求和,对比最优相似度阈值1.8,得到的评价指标结果如图8所示,其中同名专家消歧的f1值为77%。
[0204]
实验2:在实验1的基础上,计算每对专家行为轨迹特征相似度,对三类相似度特征的计算结果求和,对比最优相似度阈值1.8,得到的评价指标结果如图8所示,柱状图左边和右边分别代表实验1和实验2,其中融合了行为轨迹特征相似度的同名专家消歧f1值达93%,比实验1的方法提高了16%。
[0205]
表7基础信息特征消歧权重值
[0206]
属性权重值性别0.19出生年月0.78邮箱0.015学历0.015
[0207]
2基于行为轨迹的亲密度计算实验与结果分析
[0208]
行为轨迹反映了专家社会关系的建立过程,其直接关系与间接关系影响专家间亲密度的计算结果,从而影响专家间是否需要进行回避的判断。在进行基于行为轨迹的亲密度计算过程中,最优亲密度计算置信度为0.7,直接关系稳定期与亲密值如表8所示,间接关系衰减比重值如表9所示。从专家名单中随机选出5组专家,每组专家有10位成员,对五组专家设置以下两组对照实验,实验结果见图9,其中柱状图的左边和右边分别代表实验1和实验2。
[0209]
实验1:依据专家行为轨迹知识图谱,查询专家间直接关系路径,利用直接关系路径亲密度计算方法得到专家间直接关系亲密度。以师生关系的亲密值0.3作为关系亲密度阈值,将超过阈值的专家组合确定为回避专家组合。
[0210]
实验2:在实验1的基础上,查询专家间间接关系路径,利用间接关系路径亲密度计
算方法获得专家间间接关系亲密度。将直接关系亲密度与间接关系亲密度求和,进行阈值判断,确定回避专家组合结果。由图9可知,加入间接关系亲密度的回避专家组合数量明显高于实验1的回避专家组合数量。
[0211]
表8直接关系稳定期与亲密值
[0212]
关系类型关系名称关系稳定期(年)关系亲密值1师生关系30.32校友关系20.23同事关系20.5
[0213]
表9间接关系衰减比重值
[0214]
关系阶数关系衰减比重2阶关系100*0.93阶关系10-1
*0.9k阶关系10
2-k
*0.9
[0215]
针对难以掌握领域评审专家亲密度的问题,本发明采用自顶向下与自底向上相结合的方法,构建了计算机科学领域评审专家行为轨迹的知识图谱,创新性的提出了基于行为轨迹的亲密度计算方法。首先,进行了专家信息的数据源采集与专家行为轨迹事件抽取;然后,基于领域本体确定知识图谱模式结构,利用自然语言处理技术完成知识抽取;最后,在利用编辑距离和余弦相似度计算方法的同时,提出了一种基于地点一致性与时间重合性相结合的行为轨迹相似度匹配算法,解决了同名专家歧义问题,实现了知识图谱的知识融合。在同名专家消歧的实验中,与仅利用基础信息特征和专业领域特征相似度的消歧效果相比,融合了行为轨迹特征相似度的消歧效果有明显提升。
[0216]
在行为轨迹的知识图谱中,通过同一领域专家行为轨迹中地点与时间的交叉联系,在专家直接关系的基础上推理出间接关系,对两种关系的亲密度求和,获得最终的专家亲密度,保证了专家亲密度计算的全面性。
[0217]
本发明提供的技术方案,不受上述实施例的限制,凡是利用本发明的结构和方式,经过变换和代换所形成的技术方案,都在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。