1.本发明涉及计算机视觉技术领域,具体涉及一种行人再识别系统中无感噪声攻击的防御方法。
背景技术:
2.随着深度学习的发展,深度神经网络已经被应用到生活中的各个领域,在行人再识别方面的应用近几年也被广泛研究。
3.行人再识别是计算机视觉方向的一个任务,它是指在非重叠的摄像机中识别出感兴趣的行人。基于深度学习的行人再识别方法已经取得了显著的进展。尽管如此,由于当前深度神经网络面对对抗样本的脆弱性,基于深度神经网络的应用容易受到各类攻击,例如在图像上添加一些微小的扰动,就会使得模型被欺骗,输出完全相反的结果。在自动驾驶领域,如图1所示,对手可以在路标上添加对抗性贴片误导自动驾驶系统做出错误的判断,造成交通事故,从而趁着这个混乱时期逃脱追捕。在行人再识别领域,基于深度神经网络的行人再识别模型也被发现容易受到对抗样本的攻击,如图2所示,通过添加人类视觉无法感知的噪声,不同相机中同一行人的图像相似度急剧下降,从82.9%下降到10.5%,不同行人的图像相似度反而从12.0%上升到82.3%,这个结果表明了现有的行人再识别模型具有较大的安全隐患。这可能会造成巨大的损失,例如犯罪分子可能会利用这种对抗攻击来逃脱或者误导监控系统的搜索,这将会给社会带了很大危险。因此,研究行人再识别模型中这类无感噪声攻击的防御方法是目前面临的一项重要任务。
4.现有的研究大都集中在行人再识别模型的攻击方法。由于行人再识别问题一般被认为是图像检索的子问题,是一种排序类问题,不属于图像分类问题,因此图像分类任务中的防御方法并不适用于行人再识别领域。对于行人再识别模型防御方法的研究较少,目前仅见两篇针对度量攻击的防御方法,通过对抗训练,使用不同的攻击方法生成新的对抗例子,从而使得行人再识别模型针对度量攻击有更好的防御效果。这种是针对度量攻击的防御方法,而无感噪声攻击是指微小的、可转移的、人类视觉无法感知的对抗攻击,在行人再识别系统中针对无感噪声攻击的防御方法目前还未发现相关研究。
技术实现要素:
5.为了克服上述的技术问题,本发明目的在于提供一种行人再识别系统中无感噪声攻击的防御方法,能够有效解决无感噪声攻击造成的行人再识别模型识别精度急剧下降的问题,提高了模型抵御无感噪声攻击的能力,提升了模型鲁棒性。
6.本发明的目的可以通过以下技术方案实现:一种行人再识别系统中无感噪声攻击的防御方法,包括以下步骤:步骤1,构建行人再识别模型,并对行人再识别模型进行训练;步骤2,获取待识别图像;步骤3,将待识别图像输入盲降噪网络结构进行降噪处理得到降噪图像;步骤4,将干净图像输入训练完成的行人再识别模型,经过内外结合的防御后,进行行人再识别,其中,降噪网络包括条件编码器
和主干网络,条件编码器通过接收预设的降噪程度作为输入条件,采用cnn条件估计网络,给定一个随机变量,基于该随机变量的点估计及cnn网络的推理方式,得到输出的条件参数α、β,主干网络采用残差学习的方式,由多个条件变换块级联的方式构成,每个条件变换块含有多个残差块,在一个条件变换块中,设经过多个残差块后输出的特征为fi,经过条件参数α、β调整后的输出特征为fo,则经过该条件变换块后输出特征,在级联多个条件变换块后得到最终的输出特征,从而输出降噪图像。
7.进一步地,在步骤3中,先将待识别图像的尺寸重置为与训练集中的行人图像尺寸相同,再输入到盲降噪网络结构进行降噪处理得到降噪图像。
8.进一步地,在步骤4中,将降噪图像输入训练完成的行人再识别模型中经过内外结合的防御后进行行人再识别,内外结合的防御为:行人再识别模型将降噪图像的尺寸缩放至预定尺寸,再在推理阶段将缩放后的降噪图像尺寸重置为与行人再识别系统模型训练时送入的图像尺寸相同。
9.更进一步地,预定尺寸为50*100。
10.进一步地,行人再识别模型的训练方法包括以下步骤:步骤1-1,采集行人图像样本集,将采集到的行人图像样本集处理后分为训练集和测试集;步骤1-2,构建行人再识别模型;步骤1-3,使用全局灰度补丁替换方法对所述训练集中的行人图像进行数据增强处理,所述全局灰度补丁替换方法为在所述训练集中随机抽取预定比例的图像并将该抽取预定比例的图像记为抽取图像子集,将所述抽取图像子集进行灰度化处理得到灰度化图像子集,在所述训练集中将所述抽取图像子集替换为所述灰度化图像子集,将替换后的所述训练集记为增强数据集;步骤1-4,采用增强数据集对行人再识别模块训练预定次数,得到训练完成的行人再识别模型。
11.更进一步地,预定比例为5%。
12.进一步地,条件编辑器由cnn卷积网络构成,所有层均采用1*1卷积层组成。
13.更进一步地,主干网络中的所有卷积层均采用3*3卷积层组成。
14.进一步地,采集行人图像样本集的方法为采用多个拍摄设备,以不同角度拍摄行人图像得到行人图像样本集。
15.本发明的有益效果如下:(1)由于真实场景中,拍摄的行人图像存在光照不均匀的情况,因此需要考虑到拍摄行人图像较暗的问题,现有的数据增强方法虽然有很多,但研究发现这类情况并未被考虑到,本发明采用灰度补丁替换的数据增强方法,将原始图像灰度化,解决了现实场景中拍摄行人图像偏暗的问题,使得行人再识别模型精度更高,鲁棒性更强。
16.(2)现有的行人再识别研究中,并未考虑到尺寸不同对行人再识别模型的影响,如果对手利用这点对模型进行对抗攻击则会导致模型识别率急剧下降;本发明中采用内外结合的防御结构,先将待识别图像尺寸重置为与64*128,保证与训练阶段输入数据的一致性,测试验证表明很好地提升了模型鲁棒性;降噪后输入训练好的行人再识别模型,将该图像尺寸调整为50*100,在推理阶段将50*100的图像继续调整,调整为384*128。这个过程从模
型的外部破坏了对抗样本的图像结构,但不会显著破坏模型的性能。由于reid-strong-baseline基线模型在训练时送入图像的尺寸是384*128,因此最后在推理阶段将50*100的图像尺寸也调整为128*384。最后在推理阶段还原了图像尺寸,起到了保护模型内部结构的目的,解决了由于行人图像尺寸不同造成的识别精度下降问题,提升了模型抵御此类攻击的能力。
17.(3)采用盲降噪的网络结构对输入的无感噪声图像进行降噪处理,区别于传统的降噪方法,采用这种盲降噪的网络结构,通过改变输入条件来输出合适的条件参数,比传统的降噪方法有更好的降噪效果,提升模型鲁棒性。
18.(4)采用这种新的整体防御框架,有效解决了无感噪声攻击造成的行人再识别模型识别精度急剧下降的问题,提高了模型抵御无感噪声攻击的能力,提升了模型鲁棒性。
附图说明
19.下面结合附图对本发明作进一步的说明。
20.图1为自动驾驶路标对抗扰动图;图2为添加对抗无感噪声后的行人图像对比示意图;图3是本发明的实施例中一种行人再识别系统中无感噪声攻击的防御方法的动作流程图;图4是本发明的实施例中生成对抗样本集的动作流程图;图5是本发明的实施例中条件编码器流程图;以及图6是本发明的实施例中降噪网络流程图。
具体实施方式
21.下面将结合本发明实施例及附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
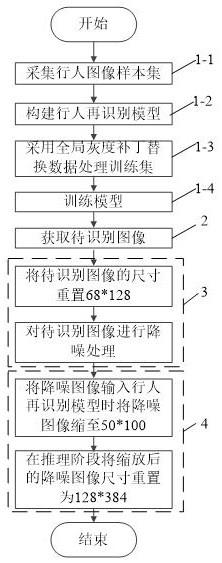
22.图3是本发明的实施例中一种行人再识别系统中无感噪声攻击的防御方法的动作流程图。
23.如图3所示,一种行人再识别系统中无感噪声攻击的防御方法包括以下步骤:步骤1,构建行人再识别模型,并对行人再识别模型进行训练,该步骤包括如下子步骤:步骤1-1,采用多个拍摄设备,以不同角度拍摄行人图像得到行人图像样本集,将采集到的行人图像样本集处理后分为训练集和测试集。
24.步骤1-2,构建行人再识别模型,模型采用resnet50网络结构,使用现有的行人再识别基线模型。
25.步骤1-3,使用全局灰度补丁替换方法对训练集中的行人图像进行数据增强处理,全局灰度补丁替换方法为在训练集中随机抽取预定比例的图像并将该抽取预定比例的图像记为抽取图像子集,将抽取图像子集进行灰度化处理得到灰度化图像子集,在训练集中将抽取图像子集替换为灰度化图像子集,将替换后的训练集记为增强数据集,其中,预定比
例为5%。
26.由于真实场景中,拍摄的行人图像存在光照不均匀的情况,因此需要考虑到拍摄的行人图像可能会有色彩不均匀的问题,或者是在光照较暗的地方以及阴雨天气拍摄到的行人图像较暗的问题。在训练过程中的数据处理阶段,使用全局灰度补丁替换方法对训练集中的行人图像进行数据增强处理,全局灰度补丁替换方法为随机对训练集中5%的行人图像进行灰度化处理,解决了现实场景中拍摄图像偏暗的问题。该部分使用图像处理库pil中的conver()函数实现。
27.步骤1-4,采用增强数据集对行人再识别模块进行训练,设置训练次数为预定次数,得到训练完成的行人再识别模型。在本实施例中,设置训练次数为300次。
28.步骤2,获取待识别图像。该待识别图像可以是增加有无感噪声的图像。
29.步骤3,先将待识别图像的尺寸重置为与训练集中的行人图像尺寸相同,即、64*128,再输入到盲降噪网络结构进行降噪处理得到降噪图像。
30.其中,盲降噪网络结构由条件编码器和主干网络组成。
31.图5是本发明的实施例中条件编码器流程图。图6是本发明的实施例中得到降噪图像流程图。
32.如图5所示,条件编码器采用cnn卷积网络,由简单的1*1的卷积层组成,通过接收预设的降噪程度作为输入条件输出条件参数α、β。
33.条件编码器采用cnn卷积网络,所有层均采用1*1卷积层组成。通过接收预设的降噪程度作为输入条件,给定一个随机变量,采用这个随机变量的点估计及cnn网络的推理方式,从而得到输出的条件参数α、β。
34.如图6所示,主干网络的所有卷积层均采用3*3卷积层组成。主干网络由多个条件变换块级联的方式构成,每个条件变换块含有多个残差块。
35.一个条件变换块中,设经过多个残差块后输出的特征为fi,经过条件参数调整后的输出特征为fo,那么,经过一个条件变换块后输出特征,在级联多个这样的条件变换块后得到最终的输出特征,从而输出降噪图像。
36.步骤4,将干净图像输入训练完成的行人再识别模型经过内外结合的防御后进行行人再识别。
37.其中,将降噪图像输入训练完成的行人再识别模型中,行人再识别模型将降噪图像的尺寸缩放至50*100,再在推理阶段将缩放后的降噪图像尺寸重置为128*384。
38.对本发明的增加了防御结构的行人再识别模型进行评估测试,包括以下步骤:步骤1:准备干净图像样本集,构建行人再识别模型,并对行人再识别模型进行训练。
39.干净图像样本集采用公开的market1501数据集。market1501数据集是由6个摄像机在清华大学的校园中所拍摄,该数据集中包含1501个不同的行人,共有32668张图像。其中训练集中包含751个不同的行人,共有12936张图像;画廊集中包含750个不同的行人,共有19732张图像;查询集共有3368张图像。
40.构建行人再识别模型,采用reid-strong-baseline行人再识别基线模型。
41.采用训练集对构建好的行人再识别模型进行训练,设置训练次数为300次,得到训练好的行人再识别模型m。数据处理阶段采用全局灰度补丁替换的方法,将训练数据中5%的
rgb图像转化为灰度图像,起到数据增强的作用。该部分使用图像处理库pil中的conver()函数实现。
42.步骤2:生成对抗样本集。
43.图4是本发明的实施例中生成对抗样本集的动作流程图。
44.如图4所示,采用2020年cvpr会议上提出来的mis-rank攻击方法对market1501数据集中的查询集进行无感噪声模拟攻击,通过该模拟攻击为查询集中的每个图像生成无感噪声扰动图像。用生成后的无感噪声扰动图像替换原market1501数据集中的查询集图像,得到对抗样本集a1。
45.步骤3:先将对抗样本集的尺寸均重置为64*128,再输入到盲降噪网络结构进行降噪处理得到降噪图像集a2。
46.步骤4:将降噪图像集a2输入到训练好的行人再识别模型m,进行对抗防御。
47.评价指标使用rank-1、rank-5、rank-10和map。
48.rank-k表示算法返回的排序列表中,前k位为存在检索目标则称为rank-k命中。例:rank-1表示首位为检索目标则rank-1命中。
49.map(mean average precision):反应检索的人在数据库中所有正确的图片排在排序列表前面的程度,能更加全面的衡量re-id算法的性能。例:假设检索行人在图库中有4张图片,在检索的列表中位置分别为1、2、5、7,则ap为(1 / 1 2 / 2 3 / 5 4 / 7) / 4 =0.793;ap较大时,该行人的检索结果都相对靠前,对所有查询的ap取平均值得到map。
50.实验结果如下表所示。 maprank-1rank-5rank-10reid-strong-baseline94.695.797.998.5mis-rankattack2.60.83.15.2oursdefense82.6( 80.0)83.5( 82.7)92.0( 88.9)94.4( 89.2)
51.在上表中可以看到,在不添加任何防御结构时,reid-strong-baseline基线模型在经过mis-rank攻击后,模型的map精度从94.6%下降到2.6%,rank-1精度从95.7%下降到0.8%,rank-5精度从97.9%下降到3.1%,rank-10精度从98.5%下降到5.2%,可以看到在经过攻击后模型识别结果急剧下降,而在加入本发明提出的防御结构后,map精度为82.6%,提升了80%,rank-1精度为83.5%,提升了82.7%,rank-5精度为92.0%,提升了88.9%,rank-10精度为94.4%,提升了89.2%。
52.对比实验结果可知,采用本发明提出的防御结构后,模型识别精度有很大的提升,说明了本发明对防御无感噪声攻击的有效性。
53.在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
54.以上内容仅仅是对本发明所作的举例和说明,所属本技术领域的技术人员对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,只要不偏离发明或者超越本发明所定义的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。