1.本发明涉及信息技术领域,具体涉及一种推送信息的方法和装置,特别涉及一种召回信息的方法和装置。
背景技术:
2.目前,互联网已成为大多数人或许资讯的主要渠道,而相应的,互联网上的资讯数量也成指数级爆炸。特别是随着移动设备的普及和发展,在资讯数量越来越丰富的同时,用户的关注点也被过分的分散,难以获取到有效的信息。
3.搜索引擎提供了解决上述问题的一种手段,但是,现有技术中,搜索引擎有赖于用户自身输入关键词进行主动检索,特别是在移动互联网终端下,用户体验不佳,同时也不能解决系统自动获取用户兴趣并完成推送。
4.目前,尽管通过前置的特征工程等手段,已经以用户兴趣点为中心,初步构建了分类的数据体系。但是,这些信息在服务器内仍然数量庞大,不能够直接推送给用户。通常,在信息推荐场景中,向用户推荐信息会分为召回阶段和排序(推荐)阶段,分别由召回子系统和排序(推荐)子系统完成。
5.召回系统主要实现从特征工程子系统处理完成并存储在服务器的候选信息中,筛选部分信息作为召回信息。技术上则主要基于用户画像和候选推荐信息,采用特征匹配的方式,按照相似程度排序的方式筛选召回信息。具体的,有搜索行为粒度的i2i方式和用户层次的u2i方式。但是,i2i方式,由于采用用户的当前搜索行为作为召回依据,往往召回信息的整体质量偏低,噪音多,包含较多用户不感兴趣的内容;u2i方式中,则由于主要采用一个特征向量召回,所以召回信息往往只能命中用户一个兴趣点,多样性差。
6.针对现有技术中的上述问题,目前还没有很好的解决方案,需要一种更为精准高效的召回方式。
技术实现要素:
7.本发明公开了一种推送信息的方法和装置,特别涉及一种召回信息的方法和装置。
8.本发明公开了一种推送信息的装置,其特征在于:所述装置包括特征筛选系统、召回系统,和/或,排序系统,所述召回系统从特征筛选系统获取有关信息;
9.所述特征筛选系统对从客户端获取的信息进行处理,处理结果作为召回系统的输入信息;
10.所述召回系统包括用户和文章向量处理子系统,所述用户和文章向量子系统通过对一个打分矩阵做矩阵分解对所述输入信息进行处理。
11.一种推送信息的方法,其特征在于:包括以下步骤:
12.步骤a1:用户在客户端首页下拉刷新发起请求;
13.步骤a2:所述请求由客户端传递给服务端接口,同时,客户端还向所述服务端接口
发送用户和上下文特征;
14.步骤a3:所述服务端接收到客户端发来的请求后,再调用推荐系统接口,并向所述推荐系统发送推荐算法模型需要的特征;
15.步骤a4:所述推荐系统接收到服务端发来的请求后,会向召回系统请求所要给用户推荐的内容;
16.步骤a5:服务端接收到召回系统分别返回的内容集合后,进行排序处理。
17.步骤a4中所述数据库优选redis数据库。
18.所述步骤a4进一步包括:用户和文章向量通过对一个打分矩阵做矩阵分解得到的,具体包括:
19.步骤a4-1:采用用户协同过滤算法,根据站内所有用户的点击日志采用内容相似度算法计算得到每个内容的协同内容列表;
20.步骤a4-2:用户热点召回,所述用户热点召回是指依照热度值计算公式,对用户召回最感兴趣的分类的分类中当前最热的内容,计算内容的热度;
21.步骤a4-3:算法模型召回,所述算法模型召回是指通过矩阵分解算法将用户和内容分别进行向量化;
22.步骤a4-4:冷启动曝光,所述冷启动曝光是指采用多级流量池模型对新增入库内容进行处理;
23.优选的,步骤a4-1中所述相似度算法的计算公式为:
[0024][0025]
其中n(a)表示点击内容a的用户数,n(b)表示点击内容b的用户数,n(a)∩n(b)表示既点击a又点击了b的用户数。
[0026]
所述步骤a4-2中的热度值计算公式为:
[0027]
对于分享、传播率等数值满足第一特征向量的情形,所述热度值=ctr*a 当天整体传播率*b,
[0028]
否则,热度值=ctr*c 当天整体传播率*d;
[0029]
所述传播率是指站外点击数/分享数;
[0030]
所述a、b、c、d为大于1的自然数。
[0031]
所述第一特征向量是指ctr、分享数和传播率的组合;优选的,所述第一特征向量是指ctr》e%、分享数大于f且传播率大于g。
[0032]
所述e为大于等于5的实数,所述f为大于20的自然数,所述g为大于等于1的实数。
[0033]
进一步的,优选的,所述热度值计算公式为:
[0034]
如果内容满足累计ctr》8%、分享数大于30且传播率大于1,则热度值=ctr*10000 当天整体传播率*600,
[0035]
否则,热度值=ctr*1000 当天整体传播率*60;
[0036]
所述传播率是指站外点击数/分享数;
[0037]
优选的,对于一些时效性较强的内容,比如早安、午安、晚安,或者比赛直播这种内
容,通过指定曝光时间段及时将这部分内容下线。还有一些异常值的处理,比如ctr做如下规范:
[0038]
ctr超过20%设置为20%;
[0039]
ctr超过100%的异常数据设置为10%;
[0040]
ctr低于3%设置为3%。
[0041]
所述步骤a4-3的矩阵分解算法具体包括:
[0042]
步骤a4-3-1:用户和内容分别进行向量化,给用户召回时则采用用户向量与内容向量算内积求相似度的方式,打分矩阵分解形式如下:
[0043][0044]
其中,m
(m
×
n)
打分矩阵中每个元素的生成方法是按照用户-内容行为对应表所指定的权值,生成用户对每个内容的一个最终权值,其中,m是代表用户数量的自然数,n是代表内容数量的自然数:;
[0045]
步骤a4-3-2:以将用户的评分和矩阵相乘的评分的平方差尽可能小为目标,以平方差损失作为损失函数,采用线性回归算法进行矩阵分解计算。
[0046]
优选的,步骤a4-3-2中所述损失函数是具体计算方法是通过梯度下降法对损失函数分别对pi和qj求导:
[0047][0048][0049]
同时,由于训练时不是单个样本,因此需要迭代更新,pi和qj的迭代公式为:
[0050][0051][0052]
优选的,在训练过程中,所述文章的模型更新频率为小时级,用户的模型更新频率为天级。
[0053]
优选的,所述步骤a4-4中的多级流量池具体包括:
[0054]
步骤a4-4-1:初始曝光流量池,取最近24小时发布的请求数小于请求特征值或曝光数小于曝光特征值的内容按照源指数倒序出,其中源指数的计算公式为:
[0055][0056]
其中,所述请求特征值、曝光特征值均为大于1的自然数;优选的,所述请求特征值选择500-800之间的自然数,所述曝光特征值选择50-200之间的自然数;
[0057]
所述倒序出是指将内容按照源指数数值从大到小的顺序输出;
[0058]
进一步的,所述请求特征值选择700,所述曝光特征值选择100。作为一种优选的实施例,由于曝光有延迟,因此选择判断请求数作为判断标准。所述曝光有延迟是指用户虽然
发起了请求,但是由于内容没有在当前屏幕曝光,进而导致曝光数延迟。
[0059]
a为权重系数。优选的,默认为1;进一步的,作为一种优选的设置,如果源阅读数小于100,a=0.001;如果源阅读数小于500,a=0.05;如果源阅读数大于2000,a=源阅读数/10000;
[0060]
b为提权系数。优选的,b的数值默认为1,对于优质内容,b的数值选择大于5的自然数。
[0061]
c为分类提权系数。优选的,默认为1,当频道为动漫、汽车、美文、游戏等分类时,c=0.5;
[0062]
exp(-kt)为牛顿冷却函数,k为冷却系数;优选取大于0且小于1区间范围内的任意数值。
[0063]
进一步的,所述k取0.05,t为文章发布时间距离当前时间的小时数;
[0064]
s代表来源提权系数,基于不同源站内容在站内的真实数据表现制定不同的提权系数,该系数取值范围是0~100;优选的,系数取值与所述源站的可信程度成正比;例如,当来源为人民日报等国家级媒体客户端时,s取值为100。
[0065]
优选的,当文章为编辑上传时,直接随机设置源指数为20000到30000之间的任意值;
[0066]
步骤a4-4-2:二级流量池,进入二级流量池的内容按照ctr倒排持续给其请求,使其达到特定请求次数或曝光次数后,ctr大于第一特征值的内容会进入三级流量池,否则进入二级待定池,每隔一分钟将二级待定池中ctr大于第一特征值的内容转移到三级流量池中;
[0067]
步骤a4-4-3:进入三级流量池的内容按照ctr排序推荐给用户,当其请求书或曝光数达到特定次数后,判断ctr是否大于第二特征值,如果满足则打上冷启动结束的标识并结束冷启动。
[0068]
进一步的,所述步骤a4-4-2的特定请求次数选择大于1400的自然数,所述曝光次数选择大于200的自然数;所述第一特征值取大于25%,且小于70%范围的百分数;
[0069]
所述步骤a4-4-3中请求数选择大于4200的自然数,所述曝光次数选择大于600的自然数;所述第二特征值取大于25%,且小于70%范围的百分数;
[0070]
所述第二特征值大于所述第一特征值。
[0071]
本发明的有益效果是:
[0072]
由于新闻类的应用中用户和内容量级比较大,需要将打分矩阵分解成两个矩阵;特别是在用户模型采用天级训练更新的前提下,通过测试发现,用户的兴趣更为稳定,所以相比用户模型采用小时级更新的方案,训练指标上并没有下降,反而节省了两个core节点的计算机资源。同时,文章需要比较多的曝光才能将向量学习的更准确,所以设计成小时级更新,这里的矩阵分解算法有两处直接带来提升的优化点:一个是梯度更新中的学习率可以实现动态调整,程序可以根据loss不断变化学习率,从而可以做到快速收敛,5000万条训练数据时,训练速度从之前的50分钟减少到35分钟,节省大量的服务器计算资源;第二个=是控制模型中用户和文章的训练次数实现模型的准确性(用户侧迭代次数没有达到200次的不会用该算法召回,文章侧迭代次数没有达到1500次的不会进入召回池),在此优化之前该路召回曝光占比40%的情况下ctr(点击率)为31%,优化之后曝光占比为33%,ctr可以
达到45%,站内整体的ctr从21%提升到24%,提升了15%,人均阅读数从10.8提升到13.2,提升了22%。
[0073]
采用多级流量池的冷启动方式,通过每次只给内容少量曝光并及时观察点击率的方式,能够及时过滤掉点击率低的内容,从而把有限的曝光资源集中到优质内容。
附图说明
[0074]
图1是一种热点分类步骤示意图;
[0075]
图2是某用户的用户向量在系统中的表示;
[0076]
图3是某内容的内容向量在系统中的表示;
[0077]
图4是实施例3的步骤示意图;
具体实施方式
[0078]
实施例1
[0079]
本发明公开了一种推送信息的方法和装置。
[0080]
本发明公开了一种推送信息的装置,其特征在于:所述装置包括特征筛选系统、召回系统,和/或,排序系统,所述召回系统从特征筛选系统获取有关信息;
[0081]
所述特征筛选系统对从客户端获取的信息进行处理,处理结果作为召回系统的输入信息;
[0082]
所述召回系统包括用户和文章向量处理子系统,所述用户和文章向量子系统通过对一个打分矩阵做矩阵分解对所述输入信息进行处理。
[0083]
一种推送信息的方法,其特征在于:包括以下步骤:
[0084]
步骤a1:用户在客户端首页下拉刷新发起请求;
[0085]
步骤a2:所述请求由客户端传递给服务端接口,同时,客户端还向所述服务端接口发送用户和上下文特征;
[0086]
步骤a3:所述服务端接收到客户端发来的请求后,再调用推荐系统接口,并向所述推荐系统发送推荐算法模型需要的特征;
[0087]
步骤a4:所述推荐系统接收到服务端发来的请求后,会向召回系统请求所要给用户推荐的内容;
[0088]
步骤a5:服务端接收到召回系统分别返回的内容集合后,进行排序处理。
[0089]
步骤a4中所述数据库优选redis数据库。
[0090]
所述步骤a4进一步包括:用户和文章向量是通过对一个打分矩阵做矩阵分解得到的,矩阵分解的方法和公式部分对应下面步骤a4-3-1和步骤a4-3-2。
[0091]
步骤a4-1:采用用户协同过滤算法,根据站内所有用户的点击日志采用内容相似度算法计算得到每个内容的协同内容列表;
[0092]
步骤a4-2:用户热点召回,所述用户热点召回是指依照热度值计算公式,对用户召回最感兴趣的分类的分类中当前最热的内容,计算内容的热度;
[0093]
步骤a4-3:算法模型召回,所述算法模型召回是指通过矩阵分解算法将用户和内容分别进行向量化;
[0094]
步骤a4-4:冷启动曝光,所述冷启动曝光是指采用多级流量池模型对新增入库内
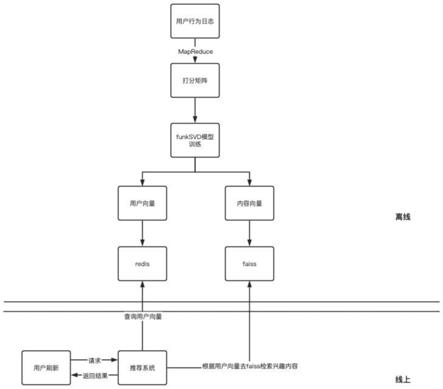
容进行处理;
[0095]
优选的,步骤a4-1中所述相似度算法的计算公式为:
[0096][0097]
其中n(a)表示点击内容a的用户数,n(b)表示点击内容b的用户数,n(a)∩n(b)表示既点击a又点击了b的用户数。
[0098]
所述步骤a4-2中的热度值计算公式为:
[0099]
对于分享、传播率等数值满足第一特征向量的情形,所述热度值=ctr*a 当天整体传播率*b,
[0100]
否则,热度值=ctr*c 当天整体传播率*d;
[0101]
所述传播率是指站外点击数/分享数;
[0102]
所述a、b、c、d为大于1的自然数。
[0103]
所述第一特征向量是指ctr、分享数和传播率的组合;优选的,所述第一特征向量是指ctr》e%、分享数大于f且传播率大于g。
[0104]
所述e为大于等于5的实数,所述f为大于20的自然数,所述g为大于等于1的实数。
[0105]
进一步的,优选的,所述热度值计算公式为:
[0106]
如果内容满足累计ctr》8%、分享数大于30且传播率大于1,则热度值=ctr*10000 当天整体传播率*600,
[0107]
否则,热度值=ctr*1000 当天整体传播率*60;
[0108]
所述传播率是指站外点击数/分享数;
[0109]
优选的,对于一些时效性较强的内容,比如早安、午安、晚安,或者比赛直播这种内容,通过指定曝光时间段及时将这部分内容下线。还有一些异常值的处理,比如ctr做如下规范:
[0110]
ctr超过20%设置为20%;
[0111]
ctr超过100%的异常数据设置为10%;
[0112]
ctr低于3%设置为3%。
[0113]
所述步骤a4-3的矩阵分解算法具体包括:
[0114]
步骤a4-3-1:用户和内容分别进行向量化,给用户召回时则采用用户向量与内容向量算内积求相似度的方式,打分矩阵分解形式如下:
[0115][0116]
其中,m
(m
×
n)
打分矩阵中每个元素的生成方法是按照用户-内容行为对应表所指定的权值,生成用户对每个内容的一个最终权值,其中,m是代表用户数量的自然数,n是代表内容数量的自然数:;
[0117]
步骤a4-3-2:以将用户的评分和矩阵相乘的评分的平方差尽可能小为目标,以平方差损失作为损失函数,采用线性回归算法进行矩阵分解计算。
[0118]
优选的,步骤a4-3-2中所述损失函数是具体计算方法是
通过梯度下降法对损失函数分别对pi和qj求导:
[0119][0120][0121]
同时,由于训练时不是单个样本,因此需要迭代更新,pi和qj的迭代公式为:
[0122][0123][0124]
优选的,在训练过程中,所述文章的模型更新频率为小时级,用户的模型更新频率为天级。
[0125]
优选的,所述步骤a4-4中的多级流量池具体包括:
[0126]
步骤a4-4-1:初始曝光流量池,取最近24小时发布的请求数小于700(这里之所以判断请求数是因为曝光有延迟,用户虽然请求了但是由于内容没有在当前屏幕曝光所以曝光会有延迟)或曝光数小于100的内容按照源指数倒序出,其中源指数的计算公式为:
[0127][0128]
所述倒序出是指将内容按照源指数数值从大到小的顺序输出;
[0129]
其中,a为权重系数。优选的,默认为1;进一步的,作为一种优选的设置,如果源阅读数小于100,a=0.001;如果源阅读数小于500,a=0.05;如果源阅读数大于2000,a=源阅读数/10000;
[0130]
b为提权系数。优选的,b的数值默认为1,对于优质内容,b的数值选择大于5的自然数;
[0131]
c为分类提权系数。优选的,默认为1,当频道为动漫、汽车、美文、游戏等分类时,c=0.5;
[0132]
exp(-kt)为牛顿冷却函数,k为冷却系数;优选取大于0且小于1区间范围内的任意数值。
[0133]
进一步的,所述k取0.05,t为文章发布时间距离当前时间的小时数;
[0134]
s代表来源提权系数,基于不同源站内容在站内的真实数据表现制定不同的提权系数,该系数取值范围是0~100;优选的,系数取值与所述源站的可信程度成正比;例如,当来源为人民日报等国家级媒体客户端时,s取值为100;
[0135]
当文章为编辑上传时,直接随机设置源指数为20000到30000之间的任意值;
[0136]
步骤a4-4-2:二级流量池,进入二级流量池的内容按照ctr倒排持续给其请求,使其达到特定请求次数或曝光次数后,ctr大于第一特征值的内容会进入三级流量池,否则进入二级待定池,每隔一分钟将二级待定池中ctr大于第一特征值的内容转移到三级流量池中;
[0137]
步骤a4-4-3:进入三级流量池的内容按照ctr排序推荐给用户,当其请求数或曝光
数达到特定次数后,判断ctr是否大于第二特征值,如果满足则打上冷启动结束的标识并结束冷启动。
[0138]
进一步的,所述步骤a4-4-2的特定请求次数选择大于1400的自然数,所述曝光次数选择大于200的自然数;所述第一特征值取大于25%,且小于70%范围的百分数;
[0139]
所述步骤a4-4-3中请求数选择大于4200的自然数,所述曝光次数选择大于600的自然数;所述第二特征值取大于25%,且小于70%范围的百分数;
[0140]
所述第二特征值大于所述第一特征值。
[0141]
步骤a4-4-2和步骤a4-4-3具体包括:
[0142]
步骤a4-4-2:二级流量池,进入二级流量池的内容按照ctr倒排持续给其请求,使其达到1400次请求数或者200次曝光后,ctr大于25%的内容会进入三级流量池,否则进入二级待定池,每隔一分钟将二级待定池中ctr大于25%的内容转移到三级流量池中;
[0143]
步骤a4-4-3:进入三级流量池的内容按照ctr排序,先后推给用户曝光,当其请求数达到4200次或获得600次曝光后判断ctr是否大于25%,如果满足则打上冷启动结束的标识并结束冷启动,站内所有模块中展现的内容均是这些冷启动结束的内容。
[0144]
实施例2
[0145]
对于热点召回的典型场景,针对用户对每个类别(比如美文、健康、家居等)内容的兴趣得分,结合用户的行为和打分规则,最终生成用户对不同类别内容的兴趣得分。所述用户兴趣得分是综合用户的点击、曝光、分享、评论、点赞和收藏等行为计算得到的。
[0146]
优选的,一种典型的实施方式如图1所示,根据打分规则,基于用户行为日志,计算每个用户对每个分类的兴趣分。例如,作为一种优选的示例,打分规则如下表:
[0147][0148]
优选的,依据上述打分规则,得到的某用户对不同类别内容的兴趣得分如下所示:
[0149]
[0150][0151]
优选的,上述结果存储在redis数据库中。
[0152]
进一步的,如图1所示,在获得了用户对每个分类的兴趣得分后,就可以给用户召回最感兴趣的分类下的热门内容,并存储在内容热度值数据库中。优选的,所述内容热度值数据库选择mysql数据库。
[0153]
优选的,采用如下计算公式计算内容热度值:
[0154]
如果内容满足ctr》8%、分享数大于30且传播率(传播率=朋友圈点击数/分享数)大于1,则热度值=ctr*10000 当天整体传播率*600,
[0155]
否则热度值=ctr*1000 当天整体传播率*60
[0156]
对于一些时效性较强的内容,比如早安、午安、晚安,或者比赛直播这种内容,通过指定曝光时间段及时将这部分内容下线。还有一些异常值的处理,比如ctr做如下规范:
[0157]
ctr超过20%设置为20%。
[0158]
ctr超过100%的异常数据设置为10%。
[0159]
ctr低于3%设置为3%。
[0160]
优选的,每两分钟计算一次所有内容的热度值,线上用户请求时,系统先查询用户最感兴趣的分类,然后返回该分类下热度值最大的topn的内容。所述n为大于1的自然数。
[0161]
实施例3
[0162]
对于采用funksvd向量化算法的情形,本方案有如下的一种优选的具体实施方式。需要说明的是,本实施方式只是展示本发明的一种优选的实现方式,其他类似的实现方式均是本发明保护的范围。
[0163]
具体实施方式如图4所示,具体包括:
[0164]
1.funksvd模型是每天更新一次,每隔特定时间通过mapreduce程序将前一天的用户行为数据基于用户id和内容id做汇总,并根据用户的点击、曝光、分享等行为计算得分矩阵;
[0165]
优选的,所述特定时间是以天为单位,每天凌晨1点汇总。
[0166]
2.对上面的得分矩阵进行分解,比如通过打分策略得出的分值是m
ij
,用户和文章评分矩阵是则我们期望损失函数尽可能的小,通过梯度下降法对损失函数分别对pi和qj求导:
[0167][0168][0169]
因为训练时不是单个样本,所以需要迭代更新,pi和qj的迭代公式为:
[0170][0171][0172]
这样就得到了p和q两个矩阵,这两个矩阵分别是对用户和内容的向量表示,也就是将用户和内容以向量的形式进行了数值表示。
[0173]
优选的,所述向量是一种以计算机能够理解的方式对事物的一种表述,用来在计算机中描述两个事物是否相似的数值形式。
[0174]
例如,某个用户侧向量在系统中的记录如图2所示,图2表示了用户id:41144989的用户向量。某个内容侧向量在系统中的记录如图3所示,图3表示了内容id:36844954的内容向量。
[0175]
3.用户向量会存到redis,内容向量则存到faiss中,faiss是facebook ai research开发的一款稠密向量检索工具,线上用户请求时先通过用户id到redis中查出用户的向量,然后去faiss中检索用户感兴趣的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
