1.本技术涉及自然语言处理技术领域,特别涉及一种长度损失确定方法。本技术同时涉及一种长度损失确定装置,一种计算设备,以及一种计算机可读存储介质。
背景技术:
2.自然语言处理是研究实现人与计算机之间用自然语言进行有效通信的各种理论和方法,而随着自然语言处理的飞速发展,作为自然语言处理领域中一个热门方向的机器阅读理解也受到了广泛关注,机器阅读理解是致力于教会机器阅读人类的语言并理解其内涵的研究,机器阅读理解任务更注重于对于篇章文本的理解,机器必须自己从篇章中学习到相关信息,而不是利用预设好的世界知识、常识来回答问题,所以更具有挑战性。
3.目前,训练机器去阅读理解人类语言的方法,重要的一种实现方式就是通过建立机器阅读理解模型,进一步通过对建立的机器阅读理解模型进行训练来获得想要的机器阅读理解模型,从而在训练获得的机器阅读理解模型的基础上在文本片段中找出问题的答案。但目前的机器阅读理解模型训练过程中考虑的损失不够精确,无法充分反映预测出答案的损失,最终预测出答案的准确率较低。
技术实现要素:
4.有鉴于此,本技术实施例提供了一种长度损失确定方法和一种阅读理解模型训练方法,以解决现有技术中存在的技术缺陷。本技术实施例同时提供了一种长度损失确定装置,一种阅读理解模型训练装置,一种计算设备,以及一种计算机可读存储介质。
5.本技术提供一种阅读理解模型训练方法,包括:
6.获取包含样本问题及其在样本文章中对应目标答案的训练样本;
7.通过将所述训练样本输入阅读理解模型生成所述样本问题的预测答案;
8.确定所述预测答案相对于所述目标答案的准确度损失;
9.基于所述准确度损失确定损失函数,利用所述损失函数对所述阅读理解模型进行优化。
10.可选的,所述确定所述预测答案相对于所述目标答案的准确度损失,包括:
11.确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失;
12.将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
13.基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失。
14.可选的,所述确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失,包括:
15.计算所述样本文章包含的字单元为所述预测答案的起始字的起始概率分布,以及
所述字单元为所述预测答案的结尾字的结尾概率分布;
16.基于所述起始概率分布和所述结尾概率分布确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;
17.基于所述起始概率分布中包含的所述预测起始位置对应的概率数值确定所述预测起始位置的起始位置损失,以及基于所述结尾概率分布中包含的所述预测结尾位置对应的概率数值确定所述预测结尾位置的结尾位置损失。
18.可选的,所述预测起始位置,包括:所述起始概率分布中包含的概率数值最大的字单元在所述样本文章中的位置;
19.所述预测结尾位置,包括:所述结尾概率分布中包含的概率数值最大的字单元在所述样本文章中的位置。
20.可选的,所述起始位置损失,包括:所述预测起始位置对应的概率数值与所述目标答案的起始位置对应的概率数值的差值;
21.所述结尾位置损失,包括:所述预测结尾位置对应的概率数值与所述目标答案的结尾位置对应的概率数值的差值。
22.可选的,所述将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失,包括:
23.确定所述样本文章对应的文章矩阵;所述样本文章中的字单元与所述文章矩阵中的元素一一对应;
24.确定所述预测答案的预测起始位置和预测结尾位置在所述文章矩阵中对应的预测起始元素和预测结尾元素,以及所述目标答案的起始位置和结尾位置在所述文章矩阵中对应的目标起始元素和目标结尾元素;
25.确定从所述预测起始元素到所述预测结尾元素的预测答案向量,以及从所述目标起始元素到所述目标结尾元素的目标答案向量;
26.计算所述预测答案向量与所述目标答案向量的距离,作为所述预测答案的长度损失。
27.可选的,所述将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失,包括:
28.确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;
29.计算所述预测起始位置到所述预测结尾位置的字节长度,作为所述预测答案的字节长度;
30.确定所述预测答案的字节长度与所述目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失。
31.可选的,所述基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失,包括:
32.计算所述起始位置损失、所述结尾位置损失和所述长度损失三者的加权和,作为所述预测答案的准确度损失。
33.可选的,所述确定所述预测答案相对于所述目标答案的准确度损失,包括:
34.确定所述预测答案在所述样本文章中预测起始位置和预测结尾位置的位置损失;
35.将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述
预测答案的语义损失;
36.将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
37.基于所述位置损失、所述语义损失和所述长度损失确定所述预测答案的准确度损失。
38.可选的,所述将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述预测答案的语义损失,包括:
39.计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义相似度;
40.基于所述语义相似度计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义损失并求和,获得所述预测答案的语义损失。
41.本技术提供一种长度损失确定方法,包括:
42.确定预测答案在样本文章中的预测起始位置和预测结尾位置;
43.计算所述预测起始位置到所述预测结尾位置的字节长度,作为所述预测答案的字节长度;
44.确定所述预测答案的字节长度与目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失。
45.可选的,所述确定预测答案在样本文章中的预测起始位置和预测结尾位置之前,还包括:
46.确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失。
47.可选的,所述确定所述预测答案的字节长度与所述目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失之后,还包括:
48.基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失。
49.可选的,所述确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失之前,还包括:
50.获取包含样本问题及其在样本文章中对应目标答案的训练样本;
51.通过将所述训练样本输入阅读理解模型生成所述样本问题的预测答案。
52.可选的,所述基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失之后,还包括:
53.基于所述准确度损失确定损失函数,利用所述损失函数对阅读理解模型进行优化。
54.可选的,所述阅读理解模型为attentive reader、attention sum reader、stanfordattentive reader和gatedattention reader中的任意一种。
55.可选的,所述确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失,包括:
56.计算所述样本文章包含的字单元为所述预测答案的起始字的起始概率分布,以及所述字单元为所述预测答案的结尾字的结尾概率分布;
57.基于所述起始概率分布和所述结尾概率分布确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;
58.基于所述起始概率分布中包含的所述预测起始位置对应的概率数值确定所述预测起始位置的起始位置损失,以及基于所述结尾概率分布中包含的所述预测结尾位置对应的概率数值确定所述预测结尾位置的结尾位置损失。
59.可选的,所述预测起始位置,包括:所述起始概率分布中包含的概率数值最大的字单元在所述样本文章中的位置;
60.所述预测结尾位置,包括:所述结尾概率分布中包含的概率数值最大的字单元在所述样本文章中的位置。
61.可选的,所述起始位置损失,包括:所述预测起始位置对应的概率数值与所述目标答案的起始位置对应的概率数值的差值;
62.所述结尾位置损失,包括:所述预测结尾位置对应的概率数值与所述目标答案的结尾位置对应的概率数值的差值。
63.可选的,所述计算所述样本文章包含的字单元为所述预测答案的起始字的起始概率分布,以及所述字单元为所述预测答案的结尾字的结尾概率分布,包括:
64.将所述样本文章和样本问题输入预先配置好的分类器,在所述分类器中计算所述样本文章包含的字单元为所述预测答案的起始字的起始概率分布,以及所述字单元为所述预测答案的结尾字的结尾概率分布;
65.计算完毕后由所述分类器输出所述起始概率分布和所述结尾概率分布。
66.可选的,所述基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失,包括:
67.计算所述起始位置损失、所述结尾位置损失和所述长度损失三者的加权和,作为所述预测答案的准确度损失。
68.可选的,所述确定预测答案在样本文章中的预测起始位置和预测结尾位置之后,还包括:
69.确定所述预测答案在所述样本文章中预测起始位置和预测结尾位置的位置损失;
70.将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述预测答案的语义损失。
71.可选的,所述确定所述预测答案的字节长度与所述目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失之后,还包括:
72.基于所述位置损失、所述语义损失和所述长度损失确定所述预测答案的准确度损失。
73.可选的,所述将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述预测答案的语义损失,包括:
74.计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义相似度;
75.基于所述语义相似度计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义损失并求和,获得所述预测答案的语义损失。
76.可选的,所述位置损失等于所述预测起始位置的起始位置损失和所述预测结尾位
置的结尾位置损失之和。
77.本技术提供一种阅读理解模型训练装置,包括:
78.训练样本获取模块,被配置为获取包含样本问题及其在样本文章中对应目标答案的训练样本;
79.预测答案生成模块,被配置为通过将所述训练样本输入阅读理解模型生成所述样本问题的预测答案;
80.准确度损失确定模块,被配置为确定所述预测答案相对于所述目标答案的准确度损失;
81.模型优化模块,被配置为基于所述准确度损失确定损失函数,利用所述损失函数对所述阅读理解模型进行优化。
82.可选的,所述准确度损失确定模块,包括:
83.位置损失确定子模块,被配置为确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失;
84.长度损失确定子模块,被配置为将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
85.准确度损失确定子模块,被配置为基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失。
86.本技术提供一种长度损失确定装置,包括:
87.预测位置确定子单元,被配置为确定预测答案在样本文章中的预测起始位置和预测结尾位置;
88.字节长度确定子单元,被配置为计算所述预测起始位置到所述预测结尾位置的字节长度,作为所述预测答案的字节长度;
89.第二长度损失确定子单元,被配置为确定所述预测答案的字节长度与目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失。
90.本技术提供一种计算设备,包括:
91.存储器和处理器;
92.所述存储器用于存储计算机可执行指令,所述处理器执行所述计算机可执行指令时实现所述阅读理解模型训练方法的步骤。
93.本技术提供一种计算机可读存储介质,其存储有计算机指令,该指令被处理器执行时实现所述阅读理解模型训练方法的步骤。
94.与现有技术相比,本技术具有如下优点:
95.本技术提供一种阅读理解模型训练方法,包括:获取包含样本问题及其在样本文章中对应目标答案的训练样本;通过将所述训练样本输入阅读理解模型生成所述样本问题的预测答案;确定所述预测答案相对于所述目标答案的准确度损失;基于所述准确度损失确定损失函数,利用所述损失函数对所述阅读理解模型进行优化。
96.本技术提供的阅读理解模型训练方法,在阅读理解模型训练过程中,通过将训练样本输入阅读理解模型生成该阅读理解模型对样本问题的预测答案,并将样本问题的预测答案与实际的目标答案进行比对来确定预测答案相对于实际的目标答案的损失,从而在确定损失的基础上对阅读理解模型的训练过程进行指导,提高阅读理解模型的训练效率,使
训练获得的阅读理解模型的预测准确率更高。
97.本技术提供一种长度损失确定方法,包括:确定预测答案在样本文章中的预测起始位置和预测结尾位置;计算所述预测起始位置到所述预测结尾位置的字节长度,作为所述预测答案的字节长度;确定所述预测答案的字节长度与目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失。
98.本技术提供的长度损失确定方法,在确定长度损失的过程中,通过预测答案在样本文章中的预测起始位置和预测结尾位置,并计算预测结尾位置的字节长度,进而根据预测答案的字节长度与目标答案的字节长度得到预测答案的长度损失,不仅提高了长度损失的准确度,还充分反映预测出答案的损失;此外,还可以根据长度损失计算预测答案的准确度损失,能够提高准确度损失的准确度,从而基于该准确度损失对阅读理解模型的训练过程进行指导,也即有利于提高阅读理解模型的训练效率,使训练获得的阅读理解模型的预测准确率更高。
附图说明
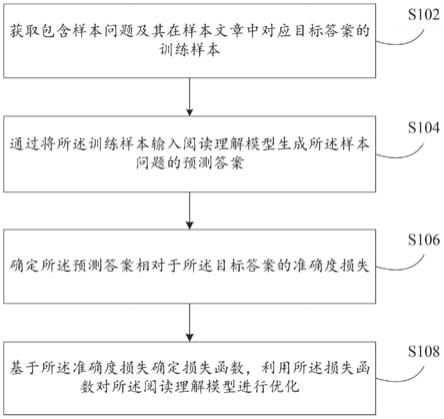
99.图1是本技术实施例提供的一种阅读理解模型训练方法处理流程图;
100.图2是本技术实施例提供的一种阅读理解模型训练装置的结构示意图;
101.图3是本技术实施例提供的一种计算设备的结构框图。
具体实施方式
102.在下面的描述中阐述了很多具体细节以便于充分理解本技术。但是本技术能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本技术内涵的情况下做类似推广,因此本技术不受下面公开的具体实施的限制。
103.在本说明书一个或多个实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本说明书一个或多个实施例。在本说明书一个或多个实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本说明书一个或多个实施例中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
104.应当理解,尽管在本说明书一个或多个实施例中可能采用术语第一、第二等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本说明书一个或多个实施例范围的情况下,第一也可以被称为第二,类似地,第二也可以被称为第一。取决于语境,如在此所使用的词语“如果”可以被解释成为“在
……
时”或“当
……
时”或“响应于确定”。
105.本技术提供一种阅读理解模型训练方法,本技术还提供一种阅读理解模型训练装置,一种计算设备,以及一种计算机可读存储介质。以下分别结合本技术提供的实施例的附图逐一进行详细说明,并且对方法的各个步骤进行说明。
106.本技术提供的一种阅读理解模型训练方法实施例如下:
107.参照附图1,其示出了本实施例提供的一种阅读理解模型训练方法处理流程图。
108.步骤s102,获取包含样本问题及其在样本文章中对应目标答案的训练样本。
109.模型的生命周期主要包含3个主要阶段:构建阶段、训练阶段和应用阶段;本技术
提供的阅读理解模型训练方法是在模型构建阶段对已经构建好的阅读理解模型进行训练,以使训练后的阅读理解模型在应用时预测出更加准确的答案。
110.除此之外,本技术提供的阅读理解模型训练方法,还可在阅读理解模型的应用过程中对其进行训练,比如每向阅读理解模型输入一次问题和文章进行问题在文章中答案的预测,通过将这一次预测的问题、文章和问题在文章中预测的答案作为训练样本,对阅读理解模型进行优化,不仅能够使阅读理解模型应用过程中的预测准确率更高,同时也能使针对阅读理解模型的优化调整更加贴近应用该阅读理解模型的实际业务。
111.需要说明的是,本技术实施例所述阅读理解模型是指机器阅读理解模型,机器阅读理解研究领域出现非常多的具体模型,比如常见的机器阅读理解模型有:attentive reader、attention sum reader(as reader)、stanford attentive reader(stanfordar)以及gatedattention reader(gareader)等。
112.本技术实施例中,一个训练样本由三部分组成:文章、问题以及该问题在文章中真实的答案,为便于描述,下述将文章称之为样本文章,问题称之为样本问题,样本问题在样本文章中的真实答案称之为目标答案,样本问题和样本文章输入阅读理解模型进行预测获得的答案称之为预测答案。
113.步骤s104,通过将所述训练样本输入阅读理解模型生成所述样本问题的预测答案。
114.具体实施时,为了评价阅读理解模型获得的预测答案与目标答案之间的差距,需将所述训练样本输入阅读理解模型以获得该阅读理解模型预测出的预测答案,具体是将所述训练样本中包含的样本文章和样本问题输入阅读理解模型,由阅读理解模型针对所述样本问题在所述样本文章中进行预测计算,最终输出其针对所述样本问题在所述样本文章中预测出的预测答案。
115.步骤s106,确定所述预测答案相对于所述目标答案的准确度损失。
116.本技术实施例提供的一种优选实施方式中,确定所述预测答案相对于所述目标答案的准确度损失,具体采用如下方式:
117.1)确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失;
118.本技术实施例中,所述预测答案在所述样本文章中预测起始位置,优选通过计算所述样本文章包含的字单元为所述预测答案的起始字的起始概率分布,并基于所述起始概率分布确定所述预测答案在所述样本文章中的预测起始位置。
119.优选的,所述预测答案在所述样本文章中的预测起始位置,是指所述起始概率分布中包含的概率数值最大的字单元在所述样本文章中的位置。
120.可见,上述通过计算所述样本文章中每个字单元为所述预测答案的起始字的概率,从而将所述样本文章中概率最大的字单元作为所述预测答案的起始字,提升了预测答案的起始字的预测准确率。
121.与上述提供的所述预测答案在所述样本文章中预测起始位置相类似,所述预测答案在所述样本文章中预测结尾位置,同样是通过计算所述样本文章包含的字单元为所述预测答案的结尾字的结尾概率分布,并基于所述结尾概率分布确定所述预测答案在所述样本文章中的预测结尾位置。
122.优选的,所述预测答案在所述样本文章中的预测结尾位置,是指所述结尾概率分布中包含的概率数值最大的字单元在所述样本文章中的位置。
123.可见,上述通过计算所述样本文章中每个字单元是所述预测答案的结尾字的概率,将所述样本文章中概率最大的字单元作为所述预测答案的结尾字,同样能够提升预测答案的结尾字的预测准确率。
124.具体实施时,阅读理解模型在预测所述预测答案在所述样本文章中对应答案的过程中,如果阅读理解模型在预测过程中需要计算所述样本文章中每个字单元是所述预测答案的起始字的概率,以及计算所述样本文章中每个字单元是所述预测答案的结尾字的概率,则可通过在阅读理解模型中读取所述样本文章包含的字单元为所述预测答案的起始字的起始概率分布,以及所述样本文章包含的字单元为所述预测答案的结尾字的结尾概率分布。
125.此外,所述起始字的起始概率分布和所述结尾概率分布,还可通过将所述样本文章和所述样本问题输入预先配置好的分类器,在分类器中进行所述样本文章包含的字单元为所述预测答案的起始字或者结尾字的概率计算,计算完毕后由分类器输出所述起始概率分布和所述结尾概率分布。
126.在上述确定所述预测答案在所述样本文章中预测起始位置和预测结尾位置的基础上,进一步计算所述预测起始位置相比目标答案在所述样本文章中起始位置的损失,该损失即是指所述预测起始位置的起始位置损失。优选的,所述预测起始位置的起始位置损失是指所述预测起始位置对应的概率数值与所述目标答案的起始位置对应的概率数值的差值。
127.例如,样本文章中由100个字单元构成,计算每个字单元是预测答案的起始字的概率,然后将概率最大的一个字单元(概率数值为85%)在样本文章中的位置确定为预测答案的预测起始位置,若该预测起始位置也是目标答案在样本文章中的起始位置,则目标答案在样本文章中的起始位置对应的概率数值为1,该预测起始位置的损失等于样本文章中的起始位置对应的概率数值1减去预测起始位置的对应的概率数值85%,最终该预测起始位置的起始位置损失为1-85%=0.15。
128.与所述预测起始位置的起始位置损失的确定过程类似,在上述确定所述预测答案在所述样本文章中预测结尾位置和预测结尾位置的基础上,进一步计算所述预测结尾位置相比目标答案在所述样本文章中结尾位置的损失,该损失即是指所述预测结尾位置的结尾位置损失。所述预测结尾位置的结尾位置损失是指所述预测结尾位置对应的概率数值与所述目标答案的结尾位置对应的概率数值的差值。
129.例如,样本文章中由100个字单元构成,计算每个字单元是预测答案的结尾字的概率,然后将概率最大的一个字单元(概率数值为70%)在样本文章中的位置确定为预测答案的预测结尾位置,若该预测结尾位置也是目标答案在样本文章中的结尾位置,则目标答案在样本文章中的结尾位置对应的概率数值为1,该预测结尾位置的损失等于样本文章中的结尾位置对应的概率数值1减去预测结尾位置的对应的概率数值70%,最终该预测结尾位置的结尾位置损失为1-70%=0.3。
130.2)将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
131.本技术实施例提供的一种优选实施方式中,所述预测答案的长度损失具体采用如下方式确定:
132.(a)确定所述样本文章对应的文章矩阵;
133.所述样本文章中的字单元与所述文章矩阵中的元素具有一一对应关系,每一个字单元对应文章矩阵中的一个元素;
134.(b)确定所述预测答案的预测起始位置和预测结尾位置在所述文章矩阵中对应的预测起始元素和预测结尾元素,以及所述目标答案的起始位置和结尾位置在所述文章矩阵中对应的目标起始元素和目标结尾元素;
135.(c)确定从所述预测起始元素到所述预测结尾元素的预测答案向量,以及从所述目标起始元素到所述目标结尾元素的目标答案向量;
136.(d)计算所述预测答案向量与所述目标答案向量的距离,作为所述预测答案的长度损失。
137.例如,样本文章中由100个字单元构成,具体在样本文章中展示为5行,每行20个字,通过将样本文章中的行与矩阵的行建立映射关系,以及将样本文章中的列与矩阵的列建立映射关系,从而针对样本文章构建一个对应的矩阵,矩阵中的每一个元素对应样本文章中的一个字单元;
138.然后预测起始位置和预测结尾位置在矩阵中对应的预测起始元素和预测结尾元素,并进一步确定从预测起始元素到预测结尾元素的预测答案向量;类似的,确定目标答案的起始位置和结尾位置在矩阵中对应的目标起始元素和目标结尾元素,并进一步确定从目标起始元素到目标结尾元素的目标答案向量;
139.最后计算预测答案向量与所述目标答案向量二者的欧式距离,作为预测答案相对于目标答案的长度损失。
140.除上述提供的所述预测答案的长度损失的确定方式之外,所述预测答案的长度损失还可以采用其他方式确定,比如优选采用下述方式确定所述预测答案的长度损失:首先,确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;然后,计算所述预测起始位置到所述预测结尾位置的字节长度,作为所述预测答案的字节长度;最后,确定所述预测答案的字节长度与所述目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失。
141.3)基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失。
142.所述预测答案的准确度损失,优选通过计算所述起始位置损失、所述结尾位置损失和所述长度损失三者的加权和确定。
143.例如,预测答案的准确度损失loss为:
144.loss=loss_start loss_end loss_length
145.其中,loss_start为起始位置损失,loss_end为结尾位置损失,loss_length为长度损失。
146.步骤s108,基于所述准确度损失确定损失函数,利用所述损失函数对所述阅读理解模型进行优化。
147.根据确定的所述预测答案相对于所述目标答案的准确度损失,确定对阅读理解模
型进行训练的损失函数(评价函数),然后利用损失函数对阅读理解模型进行优化,比如对阅读理解模型的参数或者权重系数进行调整,最终在阅读理解模型训练完毕后,获得的阅读理解模型对预测答案的预测准确率更高。
148.本实施例确定所述预测答案相对于所述目标答案的准确度损失的过程中,优选根据所述起始位置损失、所述结尾位置损失和所述长度损失来确定最终所述预测答案相对于所述目标答案的准确度损失,除此之外,所述准确度损失确定过程中还可以采用其他与准确度相关的损失参与确定,比如下述提供的采用位置损失、语义损失和长度损失确定所述准确度:
149.1)确定所述预测答案在所述样本文章中预测起始位置和预测结尾位置的位置损失;
150.其中,所述位置损失等于所述预测起始位置的起始位置损失和所述预测结尾位置的结尾位置损失之和;
151.2)将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述预测答案的语义损失;
152.具体的,所述语义损失优选通过计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义相似度,并基于所述语义相似度计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义损失并求和,最终获得所述预测答案的语义损失;
153.3)将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
154.4)基于所述位置损失、所述语义损失和所述长度损失确定所述预测答案的准确度损失。
155.在上述采用位置损失、语义损失和长度损失确定所述准确度损失的基础上,进一步确定对阅读理解模型进行训练的损失函数(评价函数),然后利用损失函数对阅读理解模型进行优化,从而获得预测准确率更高的阅读理解模型。
156.综上所述,本技术提供的阅读理解模型训练方法,在阅读理解模型训练过程中,通过将训练样本输入阅读理解模型生成该阅读理解模型对样本问题的预测答案,并将样本问题的预测答案与实际的目标答案进行比对来确定预测答案相对于实际的目标答案的损失,从而在确定损失的基础上对阅读理解模型的训练过程进行指导,提高阅读理解模型的训练效率,使训练获得的阅读理解模型的预测准确率更高。
157.本技术提供的一种阅读理解模型训练装置实施例如下:
158.在上述的实施例中,提供了一种阅读理解模型训练方法,与之相对应的,本技术还提供了一种阅读理解模型训练装置,下面结合附图进行说明。
159.参照附图2,其示出了本技术实施例提供的一种阅读理解模型训练装置的结构示意图。
160.由于装置实施例基本相似于方法实施例,所以描述得比较简单,相关的部分请参见上述提供的方法实施例的对应说明即可。下述描述的装置实施例仅仅是示意性的。
161.本技术提供一种阅读理解模型训练装置,包括:
162.训练样本获取模块202,被配置为获取包含样本问题及其在样本文章中对应目标
答案的训练样本;
163.预测答案生成模块204,被配置为通过将所述训练样本输入阅读理解模型生成所述样本问题的预测答案;
164.准确度损失确定模块206,被配置为确定所述预测答案相对于所述目标答案的准确度损失;
165.模型优化模块208,被配置为基于所述准确度损失确定损失函数,利用所述损失函数对所述阅读理解模型进行优化。
166.可选的,所述准确度损失确定模块206,包括:
167.位置损失确定子模块,被配置为确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失;
168.长度损失确定子模块,被配置为将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
169.准确度损失确定子模块,被配置为基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失。
170.可选的,所述位置损失确定子模块,包括:
171.概率分布计算子单元,被配置为计算所述样本文章包含的字单元为所述预测答案的起始字的起始概率分布,以及所述字单元为所述预测答案的结尾字的结尾概率分布;
172.位置确定子单元,被配置为基于所述起始概率分布和所述结尾概率分布确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;
173.损失确定子单元,被配置为基于所述起始概率分布中包含的所述预测起始位置对应的概率数值确定所述预测起始位置的起始位置损失,以及基于所述结尾概率分布中包含的所述预测结尾位置对应的概率数值确定所述预测结尾位置的结尾位置损失。
174.可选的,所述预测起始位置,包括:所述起始概率分布中包含的概率数值最大的字单元在所述样本文章中的位置;
175.所述预测结尾位置,包括:所述结尾概率分布中包含的概率数值最大的字单元在所述样本文章中的位置。
176.可选的,所述起始位置损失,包括:所述预测起始位置对应的概率数值与所述目标答案的起始位置对应的概率数值的差值;
177.所述结尾位置损失,包括:所述预测结尾位置对应的概率数值与所述目标答案的结尾位置对应的概率数值的差值。
178.可选的,所述长度损失确定子模块,包括:
179.矩阵确定子单元,被配置为确定所述样本文章对应的文章矩阵;所述样本文章中的字单元与所述文章矩阵中的元素一一对应;
180.元素确定子单元,被配置为确定所述预测答案的预测起始位置和预测结尾位置在所述文章矩阵中对应的预测起始元素和预测结尾元素,以及所述目标答案的起始位置和结尾位置在所述文章矩阵中对应的目标起始元素和目标结尾元素;
181.向量确定子单元,被配置为确定从所述预测起始元素到所述预测结尾元素的预测答案向量,以及从所述目标起始元素到所述目标结尾元素的目标答案向量;
182.第一长度损失确定子单元,被配置为计算所述预测答案向量与所述目标答案向量
的距离,作为所述预测答案的长度损失。
183.可选的,所述长度损失确定子模块,包括:
184.预测位置确定子单元,被配置为确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;
185.字节长度确定子单元,被配置为计算所述预测起始位置到所述预测结尾位置的字节长度,作为所述预测答案的字节长度;
186.第二长度损失确定子单元,被配置为确定所述预测答案的字节长度与所述目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失。
187.可选的,所述准确度损失确定子模块,具体被配置为计算所述起始位置损失、所述结尾位置损失和所述长度损失三者的加权和,作为所述预测答案的准确度损失。
188.可选的,所述准确度损失确定模块206,包括:
189.第二位置损失确定子模块,被配置为确定所述预测答案在所述样本文章中预测起始位置和预测结尾位置的位置损失;
190.语义损失确定子模块,被配置为将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述预测答案的语义损失;
191.第二长度损失确定子模块,被配置为将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
192.第二准确度损失确定子模块,被配置为基于所述位置损失、所述语义损失和所述长度损失确定所述预测答案的准确度损失。
193.可选的,所述语义损失确定子模块,包括:
194.语义相似度计算子单元,被配置为计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义相似度;
195.语义损失确定子单元,被配置为基于所述语义相似度计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义损失并求和,获得所述预测答案的语义损失。
196.本技术提供的一种计算设备实施例如下:
197.图3是示出了根据本说明书一实施例的计算设备300的结构框图。该计算设备300的部件包括但不限于存储器310和处理器320。处理器320与存储器310通过总线330相连接,数据库350用于保存数据。
198.计算设备300还包括接入设备340,接入设备340使得计算设备300能够经由一个或多个网络360通信。这些网络的示例包括公用交换电话网(pstn)、局域网(lan)、广域网(wan)、个域网(pan)或诸如因特网的通信网络的组合。接入设备340可以包括有线或无线的任何类型的网络接口(例如,网络接口卡(nic))中的一个或多个,诸如ieee802.11无线局域网(wlan)无线接口、全球微波互联接入(wi-max)接口、以太网接口、通用串行总线(usb)接口、蜂窝网络接口、蓝牙接口、近场通信(nfc)接口,等等。
199.在本说明书的一个实施例中,计算设备300的上述部件以及图3中未示出的其他部件也可以彼此相连接,例如通过总线。应当理解,图3所示的计算设备结构框图仅仅是出于示例的目的,而不是对本说明书范围的限制。本领域技术人员可以根据需要,增添或替换其他部件。
200.计算设备300可以是任何类型的静止或移动计算设备,包括移动计算机或移动计算设备(例如,平板计算机、个人数字助理、膝上型计算机、笔记本计算机、上网本等)、移动电话(例如,智能手机)、可佩戴的计算设备(例如,智能手表、智能眼镜等)或其他类型的移动设备,或者诸如台式计算机或pc的静止计算设备。计算设备300还可以是移动式或静止式的服务器。
201.本技术提供一种计算设备,包括存储器310、处理器320及存储在存储器上并可在处理器上运行的计算机指令,所述处理器320用于执行如下计算机可执行指令:
202.获取包含样本问题及其在样本文章中对应目标答案的训练样本;
203.通过将所述训练样本输入阅读理解模型生成所述样本问题的预测答案;
204.确定所述预测答案相对于所述目标答案的准确度损失;
205.基于所述准确度损失确定损失函数,利用所述损失函数对所述阅读理解模型进行优化。
206.可选的,所述确定所述预测答案相对于所述目标答案的准确度损失,包括:
207.确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失;
208.将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
209.基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失。
210.可选的,所述确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失,包括:
211.计算所述样本文章包含的字单元为所述预测答案的起始字的起始概率分布,以及所述字单元为所述预测答案的结尾字的结尾概率分布;
212.基于所述起始概率分布和所述结尾概率分布确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;
213.基于所述起始概率分布中包含的所述预测起始位置对应的概率数值确定所述预测起始位置的起始位置损失,以及基于所述结尾概率分布中包含的所述预测结尾位置对应的概率数值确定所述预测结尾位置的结尾位置损失。
214.可选的,所述预测起始位置,包括:所述起始概率分布中包含的概率数值最大的字单元在所述样本文章中的位置;
215.所述预测结尾位置,包括:所述结尾概率分布中包含的概率数值最大的字单元在所述样本文章中的位置。
216.可选的,所述起始位置损失,包括:所述预测起始位置对应的概率数值与所述目标答案的起始位置对应的概率数值的差值;
217.所述结尾位置损失,包括:所述预测结尾位置对应的概率数值与所述目标答案的结尾位置对应的概率数值的差值。
218.可选的,所述将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失,包括:
219.确定所述样本文章对应的文章矩阵;所述样本文章中的字单元与所述文章矩阵中
的元素一一对应;
220.确定所述预测答案的预测起始位置和预测结尾位置在所述文章矩阵中对应的预测起始元素和预测结尾元素,以及所述目标答案的起始位置和结尾位置在所述文章矩阵中对应的目标起始元素和目标结尾元素;
221.确定从所述预测起始元素到所述预测结尾元素的预测答案向量,以及从所述目标起始元素到所述目标结尾元素的目标答案向量;
222.计算所述预测答案向量与所述目标答案向量的距离,作为所述预测答案的长度损失。
223.可选的,所述将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失,包括:
224.确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;
225.计算所述预测起始位置到所述预测结尾位置的字节长度,作为所述预测答案的字节长度;
226.确定所述预测答案的字节长度与所述目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失。
227.可选的,所述基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失,包括:
228.计算所述起始位置损失、所述结尾位置损失和所述长度损失三者的加权和,作为所述预测答案的准确度损失。
229.可选的,所述确定所述预测答案相对于所述目标答案的准确度损失,包括:
230.确定所述预测答案在所述样本文章中预测起始位置和预测结尾位置的位置损失;
231.将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述预测答案的语义损失;
232.将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
233.基于所述位置损失、所述语义损失和所述长度损失确定所述预测答案的准确度损失。
234.可选的,所述将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述预测答案的语义损失,包括:
235.计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义相似度;
236.基于所述语义相似度计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义损失并求和,获得所述预测答案的语义损失。
237.本技术提供的一种计算机可读存储介质实施例如下:
238.本技术一实施例还提供一种计算机可读存储介质,其存储有计算机指令,该指令被处理器执行时以用于:
239.获取包含样本问题及其在样本文章中对应目标答案的训练样本;
240.通过将所述训练样本输入阅读理解模型生成所述样本问题的预测答案;
241.确定所述预测答案相对于所述目标答案的准确度损失;
242.基于所述准确度损失确定损失函数,利用所述损失函数对所述阅读理解模型进行优化。
243.可选的,所述确定所述预测答案相对于所述目标答案的准确度损失,包括:
244.确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失;
245.将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
246.基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失。
247.可选的,所述确定所述预测答案在所述样本文章中预测起始位置的起始位置损失,以及所述预测答案在所述样本文章中预测结尾位置的结尾位置损失,包括:
248.计算所述样本文章包含的字单元为所述预测答案的起始字的起始概率分布,以及所述字单元为所述预测答案的结尾字的结尾概率分布;
249.基于所述起始概率分布和所述结尾概率分布确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;
250.基于所述起始概率分布中包含的所述预测起始位置对应的概率数值确定所述预测起始位置的起始位置损失,以及基于所述结尾概率分布中包含的所述预测结尾位置对应的概率数值确定所述预测结尾位置的结尾位置损失。
251.可选的,所述预测起始位置,包括:所述起始概率分布中包含的概率数值最大的字单元在所述样本文章中的位置;
252.所述预测结尾位置,包括:所述结尾概率分布中包含的概率数值最大的字单元在所述样本文章中的位置。
253.可选的,所述起始位置损失,包括:所述预测起始位置对应的概率数值与所述目标答案的起始位置对应的概率数值的差值;
254.所述结尾位置损失,包括:所述预测结尾位置对应的概率数值与所述目标答案的结尾位置对应的概率数值的差值。
255.可选的,所述将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失,包括:
256.确定所述样本文章对应的文章矩阵;所述样本文章中的字单元与所述文章矩阵中的元素一一对应;
257.确定所述预测答案的预测起始位置和预测结尾位置在所述文章矩阵中对应的预测起始元素和预测结尾元素,以及所述目标答案的起始位置和结尾位置在所述文章矩阵中对应的目标起始元素和目标结尾元素;
258.确定从所述预测起始元素到所述预测结尾元素的预测答案向量,以及从所述目标起始元素到所述目标结尾元素的目标答案向量;
259.计算所述预测答案向量与所述目标答案向量的距离,作为所述预测答案的长度损失。
260.可选的,所述将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失,包括:
261.确定所述预测答案在所述样本文章中的预测起始位置和预测结尾位置;
262.计算所述预测起始位置到所述预测结尾位置的字节长度,作为所述预测答案的字节长度;
263.确定所述预测答案的字节长度与所述目标答案的字节长度的字节长度差值,作为所述预测答案的长度损失。
264.可选的,所述基于所述起始位置损失、所述结尾位置损失和所述长度损失,确定所述预测答案的准确度损失,包括:
265.计算所述起始位置损失、所述结尾位置损失和所述长度损失三者的加权和,作为所述预测答案的准确度损失。
266.可选的,所述确定所述预测答案相对于所述目标答案的准确度损失,包括:
267.确定所述预测答案在所述样本文章中预测起始位置和预测结尾位置的位置损失;
268.将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述预测答案的语义损失;
269.将所述预测答案与所述目标答案在所述样本文章中进行比对,确定所述预测答案的长度损失;
270.基于所述位置损失、所述语义损失和所述长度损失确定所述预测答案的准确度损失。
271.可选的,所述将所述预测答案包含的字单元与所述目标答案包含的字单元进行比对,确定所述预测答案的语义损失,包括:
272.计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义相似度;
273.基于所述语义相似度计算所述预测答案包含的每个字单元与所述目标答案中对应字单元的语义损失并求和,获得所述预测答案的语义损失。
274.上述为本实施例的一种计算机可读存储介质的示意性方案。需要说明的是,该存储介质的技术方案与上述的阅读理解模型训练方法的技术方案属于同一构思,存储介质的技术方案未详细描述的细节内容,均可以参见上述阅读理解模型训练方法的技术方案的描述。
275.所述计算机指令包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
276.需要说明的是,对于前述的各方法实施例,为了简便描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某些步骤可以采用其它顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定都是本技术所必须的。
277.在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其它实施例的相关描述。
278.以上公开的本技术优选实施例只是用于帮助阐述本技术。可选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本技术的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本技术。本技术仅受权利要求书及其全部范围和等效物的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。