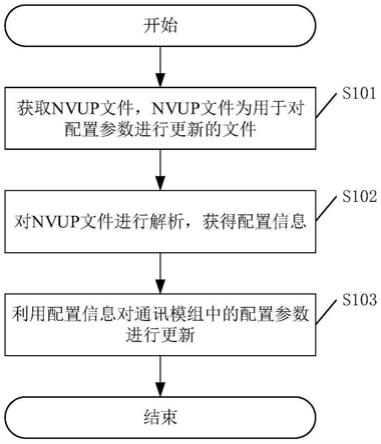
1.本发明属于网络安全技术领域,尤其涉及一种基于同质性预测的有向社交网络虚假用户检测方法。
背景技术:
2.虽然在社交网络中有着巨大的影响力网络名人追随者众多,但并非所有这些追随者都是屏幕另一边的真实人类。据报道,9%-15%的活跃twitter用户是机器人。社交网络中的恶意攻击者通过创建和控制此类机器人或sybil,进行垃圾邮件、网络钓鱼诈骗、引荐流量或操纵舆论,从而引发一系列安全问题和信任危机。
3.为了对抗社交网络中的这种乱象,多种sybil检测方法应运而生。其中,基于特征的和基于结构的方法是主流。基于特征的方法使用目标用户的各种信息,如用户资料、ip地址以及各种行为和内容特征来检测sybil。而基于结构的方法仅利用社交图的全局结构,其检测依赖于利用实体之间的相互关系(例如,facebook上的“朋友”关系或twitter上的“关注-被关注”关系)。因此,近年来基于结构的方法以其相对轻量的算法设计和良好的可移植性而被广泛应用。
4.基于结构的方法通常从训练集中的一些已经标记为“sybil”或“良性用户”的节点开始,沿着节点之间的社交关系迭代地传播节点的影响、信任度或声誉,直到整个网络收集到足够的信息进行标签预测。大多数基于结构的方法可以分为基于随机游走(rw)的和基于环路信任传播(lbp)的方法。不计空间和时间效率,基于lbp的方法总体上准确率优于基于rw的方法,因为它们可以同时利用标记的良性用户和sybil两方面的数据,并且其非线性特性赋予了对标签噪声的鲁棒性。理论上,基于结构的sybil检测方法的一个基本假设是良性社区和sybil社区之间是稀疏连接的,因此节点之间的关系整体上也遵循同质性,即相邻节点倾向于共享相同的标签。
5.然而,现有的基于lbp的方法存在以下问题:
6.1)现有方法假设全局边权重(e.g.,gang[文献1:binghui wang,neil zhenqiang gong,and hao fu.2017.gang:detecting fraudulent users in online social networks via guilt-by-association on directed graphs.in 2017ieee international conference on data mining(icdm).ieee,465
–
474.])或预定义权重(e.g.,sybilscar-d[文献2:binghui wang,le zhang,and neil zhenqiang gong.2017.sybilscar:sybil detection in online social networks via local rule based propagation.in ieee infocom 2017-ieee conference on computer communications.ieee,1
–
9.])作为节点之间的同质强度,而这种假设要么忽略了边的局部同质差异,要么无法表征行为节点模式。一个明显的例子是,同样都是良性用户,但两人可能有不同的关注偏好,因此与之相关边的同质性也不同。
[0007]
2)现有方法主要是为无向(对称)社交图模型设计的,而许多现实世界的平台,如twitter,通过“关注”、“转发”或“点赞”这些不对称的关系建立网络。直接应用这些方法不
能充分利用边信息,甚至由于单向边的在良性和sybil社区之间的稀疏性不显著而导致失效。文献1针对有向图设计了基于lbp的方法,但在消息传递过程中,其边势函数仍然为有向的一对节点之间的互相传递相同的值。
技术实现要素:
[0008]
本发明针对现有基于lbp的方法忽略了边的局部同质差异、无法表征行为节点模式以及不能充分利用边信息的问题,提出一种基于同质性预测的有向社交网络虚假用户检测方法。
[0009]
为了实现上述目的,本发明采用以下技术方案:
[0010]
一种基于同质性预测的有向社交网络虚假用户检测方法,包括:
[0011]
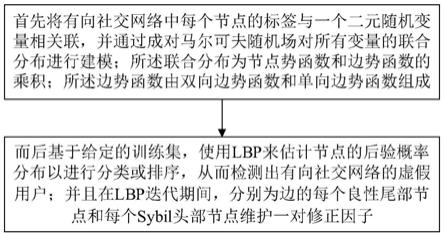
首先将有向社交网络中每个节点的标签与一个二元随机变量相关联,并通过成对马尔可夫随机场对所有变量的联合分布进行建模;所述联合分布为节点势函数和边势函数的乘积;所述边势函数由双向边势函数和单向边势函数组成;
[0012]
而后基于给定的训练集,使用lbp来估计节点的后验概率分布以进行分类或排序,从而检测出有向社交网络的虚假用户;并且在lbp迭代期间,分别为边的每个良性尾部节点和每个sybil头部节点维护一对修正因子。
[0013]
进一步地,所述双向边势函数为:
[0014][0015]
式中,
[0016][0017]
其中,表示双向边势函数;xu、xv分别表示与节点u和v标签相对应的二元随机变量;wo表示同质强度;e
t
表示训练集t的边集;c
bt
(u)、c
sh
(v)分别表示节点u和v的修正因子。
[0018]
进一步地,所述单向边势函为:
[0019][0020]
[0021]
其中表示单向边势函数;x
t
、xh分别表示与节点t和h标签相对应的二元随机变量;wo表示同质强度;c
bt
(t)、c
sh
(h)分别表示节点t和h的修正因子;w
st
、w
bh
分别表示:
[0022]wst
:
[0023][0024]wbh
:
[0025][0026]
进一步地,所述修正因子为:
[0027][0028][0029]
其中,n
out
(t)表示节点t的出边邻居集;n
in
(t)、n
in
(h)分别表示节点t和h的入边邻居集;post(
·
)是从上次迭代计算的后验概率分布。
[0030]
与现有技术相比,本发明具有的有益效果:
[0031]
本发明提出了一种基于同质性预测的有向社交网络虚假用户检测方法,首先将社交网络中每个节点的标签与一个二元随机变量相关联,并通过成对马尔可夫随机场(pmrf)对所有变量的联合分布进行建模;而后基于给定的训练集,使用lbp来估计节点的后验概率分布以进行分类或排序。通过边势函数的独特设计控制有向边上的信任传播来适应有向图,该设计集成了节点的关注偏好和边的方向性。具体来说,边势函数自适应地调节了用于估计同质性的边权重,该权重将随着置信度传播而迭代更新;此外,本发明的边势函数纳入方向敏感机制,以更好地捕捉关注者和被关注者之间的非对称相互作用。
[0032]
并且分析和评估了本发明方法在不同条件下的性能,包括不同的参数设置、攻击稀疏性和标签噪声。实验表明,收敛性、准确性和鲁棒性在合成社交网络上都表现良好。进一步的评估将本发明方法在大规模twitter数据集上与多种先进方法进行比较。结果表明,在分类和排名结果方面,本发明方法的auc明显优于现有方法。
附图说明
[0033]
图1为本发明实施例一种基于同质性预测的有向社交网络虚假用户检测方法的基本流程图;
[0034]
图2为sybil攻击模型示意图;
[0035]
图3为预测具有良性尾部或sybil头部的关注和被关注行为示例图;
[0036]
图4为不同攻击边数下的分类准确率折线图;
[0037]
图5为模型参数的影响折线图;
[0038]
图6为不同参数配置下的检测性能折线图;
[0039]
图7为不同方法的auc柱状图;
[0040]
图8为前80k正响应节点的每10k间隔中的sybil比例折线图。
具体实施方式
[0041]
下面结合附图和具体的实施例对本发明做进一步的解释说明:
[0042]
如图1所示,一种基于同质性预测的有向社交网络虚假用户检测方法,包括:
[0043]
首先将有向社交网络中每个节点的标签与一个二元随机变量相关联,并通过成对马尔可夫随机场对所有变量的联合分布进行建模;所述联合分布为节点势函数和边势函数的乘积;所述边势函数由双向边势函数和单向边势函数组成;
[0044]
而后基于给定的训练集,使用lbp来估计节点的后验概率分布以进行分类或排序,从而检测出有向社交网络的虚假用户;并且在lbp迭代期间,分别为边的每个良性尾部节点和每个sybil头部节点维护一对修正因子。
[0045]
具体地,基于结构的虚假用户检测通常指仅使用社交图结构数据进行虚假用户检测。我们将社交图建模为g(v,e),其中我们将每个用户作为节点u∈v,将用户u和v之间的有向关系作为有向边(u,v)。例如,在twitter上“关注”、“转推”或在facebook上发送好友请求可以被视为形成从一个用户到另一个用户的直接关系。我们将边分为单向边(例如,图2中的(b1,b2))和双向边(例如,图2中的(b1,s1))。请注意,我们区别对待传入邻居、传出邻居和双向邻居。
[0046]
g中的每个节点都应该被标记为sybil(即虚假用户)或良性,而我们只知道一部分节点的信息,即由一些标记的sybil和良性节点组成的标记训练集t={ls,lb}。基于结构的sybil检测的目标是用训练集t预测那些剩余的未标记节点。
[0047]
图2显示了社交网络中的sybil攻击,一个在社交网络中被sybil攻击的良性社区,其中b1,b2是被s1,s2攻击的妥协节点,离群节点b3只有指向良性社区的出边。通常sybil社区和良性社区是g的相对稠密的子图,我们称其为sybil区域和良性区域。并且希望良性和sybil用户是稀疏连接的。换言之,如果良性和sybil区域之间的边密度相对它们之间的边小,那么这种相对的稀疏性可以通过两个相邻节点共享相同的标签的趋势进行量化,即同质性。但值得注意的是,有效的sybil攻击可以显着削弱同质性(例如,图2中的节点s1)。表1包含了本发明所用到的符号含义。
[0048]
表1:本发明符号
[0049]
[0050][0051]
为更详细地阐述本发明的改进所在,简要介绍基于lbp的sybil检测模型。在本节中,我们简要回顾基于lbp的方法的基本组成部分,这些方法首先将社交图建模为成对马尔可夫随机场(pmrf),而后通过环路信任传播(lbp)算法学习节点的后验概率。
[0052]
a.将社交图建模为pmrf
[0053]
我们将每个节点u∈v对应一个二进制随机变量xu,其状态可以是-1或1,分别对应节点标签是良性或是sybil。pmrf将所有二元随机变量x={xu}
u∈v
的联合概率分布建模为p(x)。该联合分布可分解为一系列一元和二元势函数的乘法:
[0054][0055]
其中是用于概率归一化的配分因子。节点势函数φv(xv)和边势函数包含了关于节点和边的先验知识。节点势函数φv(xv)基本上刻画了节点xv的先验分布。例如,如果v已经确定是sybil了,那么就给v指定一个接近1(并非1,因为假设存在了标签噪声)的概率qv,例如,φv(xv=1)=qv,φv(xv=-1)=1-qv。但如果我们对v的标签一无所知,那就索性设φv(xv=1)=0.5。边势函数部分地反映了xu和xv的联合分布。例如,在最初版本的基于lbp的检测方法中编码了u和v的耦合强度。具体来讲,当xuxv=1时(即xu和xv状态相同时),取一个预定义的,大小在0.5到1之间的同质性强度w
uv
,该值的大小表示xu与xv取值相同的概率。类似地,当xuxv=-1时,应当取值xu和xv的异质性强度,即1-w
uv
。
[0056]
原始版本的lbp方法有以下对势函数的正式表述:
[0057][0058][0059]
通过根据关于边和节点的先验知识设置适当的pmrf参数(例如w
uv
,qv,v∈t),然后利用lbp算法来估计未标记节点∑
x∈v\u
p(xu)作为其后验分布p(xu=s|x
t
),记为pu,由此我们可以获得节点成为sybil进行分类或排序的概率估计。
[0060]
b.通过lbp算法学习pmrf的边缘分布
[0061]
信任传播是相邻变量节点迭代交换消息的过程。经过足够的迭代次数,这些消息交换收敛后,可估计所有变量的边缘概率。pmrf上的lbp算法可以概括为以下两步,即更新消息直到收敛,然后为每个节点计算信任,即后验概率。
[0062]
1.在迭代中从u发送到v的消息是:
[0063][0064]
它总结了从u接收到的消息,同时涵盖了节点u和边(u,v)的先验信息。当和之间的差异可以忽略不计时,消息传递过程停止。
[0065]
2.对于每个节点u,边缘概率分布可以通过从其邻居接收到的所有收敛消息的聚合来估计:
[0066][0067]
其中是关于xv状态的累加,用于概率归一化。
[0068]
本发明的一种基于同质性预测的有向社交网络虚假用户检测方法(简称为sybilhp)基于lbp框架推导出更精细的建模以适应有向社交图。首先,我们介绍在有向图中关于同质性的一些直觉,并将这些直觉量化为条件概率作为合理参数的初值估计。其次,我们提出了在信念传播过程中自适应调整这些参数的修正因子。最后,我们将这些估计合并到一个新的边势函数中,并展示sybilhp的完整算法。
[0069]
3.1重述同质性和边势参数的初始估计
[0070]
在本节中,我们将介绍sybilhp对与双向边和单向边关联的节点对的刻画。对于双向边(u,v),遵循公式3中定义的原始设计,我们还采用表示同质强度的单个参数wo来描述节点的共生关系。毕竟,相互关注的关系自然意味着节点之间具有较强的同质性。此外,如果训练集t有足够多的紧密链接的标记节点,并且它们张成g的一个联通子图,表示为g
t
=(v
t
,e
t
),那么就可以通过邻居节点中有相同标签的邻居的比例来估计的合理同质强度wo:
[0071][0072]
对于单向节点(t,h),其中t是尾部,h是头部,此时公式3中定义的不再适用。因为在不对称关系中,t的不同状态应对h的状态预测产生不同影响,反之亦然。因此我们考虑条件概率分布p(xh|x
t
)和p(x
t
|xh)来捕捉这些不对称关系:
[0073]
首先,它们可以部分反映x
t
,xh的联合分布,因为p(xh|x
t
)
∝
p(x
t
,xh)和p(x
t
|xh)
∝
p(x
t
,xh)。此外,bp让变量相互传递消息以交换他们对彼此的信念,因此在边上有两种消息:从关注者t到被关注者h的消息,以及从被关注者h到关注者t的消息,两者分别对应了p(xh|x
t
)和p(x
t
|xh)。
[0074]
具体来说,我们对这些分布有以下初值预测。首先是当给定尾节点状态时,预测头节点状态:
[0075]
p(xh|x
t
=1):如果给定的t是一个关注了h的sybil,那么很难推断h的状态,因为在twitter上发起关注关系(以及大多数基于“关注”的社交网络)不需要双向认证。然而,由于大多数sybil是集群控制的,我们假设这些sybil共享相似的“关注模式”。如果训练集t在其张成的子图g
t
=(v
t
,e
t
)中有足够多的连接相对稠密的标记节点,那么我们可以通过计算与另一个sybil链接的sybil的出边的比例来估计p(xh=1|x
t
=1):
[0076][0077]
将其记作w
st
,其中'st'表示sybil尾节点,即某条边的尾部节点是sybil时,对该边的同质性强度估计。
[0078]
p(xh|x
t
=-1):对于良性t,我们有很大把握说h也是良性的,其置信度与wo定义的同质强度一样高(即p(xh=1|x
t
=-1)≈wo),因为人类用户天生具有分辨sybil的能力,会更倾向于关注良性节点。
[0079]
另一方面,给定头部状态时的尾节点预测如下:
[0080]
p(x
t
|xh=-1):如果给定的良性h被未知的t关注,由于与p(xh|x
t
=1)中类似的原因,我们无法对其关注者给出明确的估计。我们同样寄期望于一个连接较为稠密的训练集:
[0081][0082]
并将此记为w
bh
,'bh'表示良性头部,即某条边的头部节点是良性时,对该边的同质性强度估计。
[0083]
p(x
t
|xh=1):如果sybilh被未知t关注,那么我们有与wo相同的把握说t也是sybil,即p(x
t
=1|xh=1)≈wo。因为大多数sybil几乎不会被人类用户主动关注。
[0084]
p(xh|x
t
)和p(x
t
|xh)的所有这些初始值汇总在表1中。
[0085]
表2:p(xh|x
t
)和p(x
t
|xh)的初值
[0086][0087]
在接下来的部分中,通过设计更精细的势函数来进一步改进消息传递过程中的这些初始预测。
[0088]
3.2边势参数修正系数
[0089]
为了根据节点的偏好进一步校正我们在上一节中定义的参数,在lbp迭代期间,我们为每个良性尾部t维护一个修正因子c
bt
(t),为每个sybil头部节点h维护个修正因子c
sh
(h)。
[0090][0091]
[0092]
其中n
out
(t)是t的出边邻居集,n
in
(h)是h的入边邻居集。请注意,这里的计数包括了双向邻居。post(
·
)是从上次迭代计算的后验概率分布。
[0093]
图3展示了预测具有良性尾部或sybil头部的关注和被关注行为。根据其记录,良性尾部t可能会受到另一次sybil攻击的影响。相应地,sybil头部h也可以以很小的代价再吸引一个良性用户。修正因子c
bt
(t)衡量良性用户t抵抗sybil攻击的能力。这个想法来自如图3所示的观察:如果良性用户已经关注了一定数量的sybils,那么有很大的把握说他/她会再次关注。类似地,c
sh
(h)衡量sybilh诱导良性用户妥协的能力。在lbp的每次迭代中,c
bt
(t)和c
sh
(h)将被更新并用于调整边势函数中的参数。在下一节中,我们将对边势函数中的参数实施校正,以根据节点的特征调整信任传播的强度。
[0094]
3.3重新定义势函数
[0095]
最后,我们将3.1和3.2得出的结果整合到我们的边势函数设计中。
[0096]
如3.1中所述,对于双向边,我们使用修正因子修改的强度wo:
[0097][0098]
校正因子设计的动机之一是出于典型的用户行为,即“回关(followback)”[followback]。“出于礼貌或好奇而回关”是大多数妥协边产生的原因。校正因子用于削弱对“糊涂”的良性节点的基于同质性的推理,并增强对“精巧”的sybil节点的基于异质性的推理。
[0099]
对于单向边(t,h),考虑到lbp算法中的消息传递是双向的,我们根据表2中的条件概率估计使我们的潜在函数对方向敏感。具体来说,我们把t对h的推断[bp],即p(h∣t)作为t传递给h的消息。相应地,从h到t的推理消息为p(t∣h)。然后我们引入修正因子来适应节点的特性。
[0100]
具体地,我们有如下单项边(有向边)势函数。
[0101]
当从尾部t向有向边的头部h发送消息时,我们有基于p(h|t)的
[0102][0103]
基于p(t|h)的从头部h到t的消息
[0104][0105]
综上所述,我们有以下方向敏感的边势函数设计:
the 19th international conference on world wide web.591
–
600.]中提取了一个具有269,640个节点和6,818,501条边的twitter关注-被关注图,并从文献2中获得了真实标签。其中178377为良性,91263为sybil。我们从中分出9000个sybil和17000个良性用户(约10%)作为训练集,并在整体社交图上进行测试。
[0117]
对比方法:我们将sybilhp与基于有向图的方法gang(包括矩阵版本和基本版本)(文献1)以及其他两种基于lbp的方法sybilscar(文献2)和sybilbelief(文献5neil zhenqiang gong,mario frank,and prateek mittal.2014.sybilbelief:asemi-supervised learning approach for structure-based sybil detection.ieee transactions on information forensics and security 9,6(2014),976
–
987.)进行比较。对于这些基于无向图的方法,我们通过仅默认保留那些双向边将我们的有向图转换为无向图,注意,这会导致许多节点变得孤立并且无法参与lbp过程。
[0118]
参数设置:对于sybilhp,我们将节点为sybil、良性和未标记的先验概率分别设置为0.9、0.1和0.5,这也是gang、sybilscar和sybilbelief的作者建议的;为twitter数据分配wo=0.99,w
st
=0.75,w
bh
=0.75,并设置lbp迭代次数iter=5。对于gang,设置(即同质强度w=0.51),按照作者关于适配twitter的建议设定参数。值得注意的是,我们还为4.2.2中的twitter数据集采用了具有优化参数(w=0.63)的基本版本的gang。也按照原文推荐的配置设置了sybilscar和sybilbelief的参数。
[0119]
作为一种可实施方式,我们在python 3.8中实现了sybilhp。为了进行适当的对比实验,我们还将gang、sybilscar、sybilbelief的原始c 代码(来自作者)移植到python。
[0120]
4.2实验结果
[0121]
4.2.1评估sybilhp
[0122]
我们首先简要评估sybilhp在不同条件下的性能,包括攻击边密度、噪声标签和参数设置。
[0123]
攻击边的影响:我们以2:1的比例添加不同数量的单向攻击边、双向边(妥协边)。图4中显示了随着攻击边数量的增加,检测准确率下降,at表示单向攻击边的数量,bi表示双向攻击边的数量。这里我们省略了召回率和准确率,因为这两个指标与准确率表现几乎完全相同。我们在这里只展示sybilhp和gang的原因与此相同,调参后各种方法之间的性能差异可以忽略不计,在同一图中绘制会造成混叠。
[0124]
标签噪声的影响:在包含错误标记的训练集的情况下,基于lbp的方法对标签噪声具固有的鲁棒性。图5显示了训练集中不同比例的错误标签对召回率的影响,我们发现与sybilscar和gang相比,sybilbelief和sybilhp对标签噪声表现出更强的鲁棒性,这可能是因为它们的非线性带来的优势。
[0125]
模型参数的影响:sybilhp具有三个可调参数wo、w
bh
和w
st
。我们通过对有向twitter数据集进行变量控制来评估这些参数的不同配置。图6显示了当我们改变其中一个参数时检测性能的变化。请注意,精度、召回率和准确率的绝对大小不具对比参考意义,因为其他参数是固定的。
[0126]
我们观察到存一些在精度和召回率之间有很好的权衡的参数选择,它们与我们在3.1中的估计的基本一致(例如,w
bh
≈0.75)。
[0127]
4.2.2真实推特数据集对比实验
[0128]
整体分类和排序性能:由于基于lbp的检测方法估计每个节点的后验概率,我们可以按节点是sybil的后验概率按降序对节点进行排序。表3显示了与其他三种先进的sybil检测方法相比的整体分类性能。我们将接收器操作特征曲线下的面积(auc)作为排名的评估指标,它可以解释为在测试数据集中随机采样的sybil节点排名高于随机采样的良性节点的概率。结果表明sybilhp显著优于所有比较的方法,图7显示了auc与其他三种方法相比的整体排名性能。
[0129]
表3分类效能
[0130]
方法精确率pr召回率rc准确率accsybilbelief0.8730.5010.806sybilscar0.9050.5080.815gang_matrix0.7980.4250.769gang_basic0.7570.8080.847sybilhp0.9080.7970.904
[0131]
排名靠前的节点中的sybil节点:由于节点的排名可以作为优先级列表,由系统或人工进行进一步的检查和验证,因此排名靠前的节点的准确性很重要,因为将只考虑他们可以节约对其他大多数节点额外的人工检测成本。因此,我们进一步比较了前90k正响应节点的不同部分中sybil的比例。具体来说,我们将top-80k节点(因为数据集只包含91k的sybil)分成10个区间,并计算每个区间的sybil数量。图8显示了在每个10k间隔中检测到的sybils的分布。对于gang_matrix、sybilscar和sybilbelief,我们可以观察到在间隔50k-60k处明显下降,而本发明sybilhp在此区间继续发挥其优势。
[0132]
综上,本发明提出的sybilhp,一种基于同质性预测的有向社交网络虚假用户检测方法,该方法针对具有自适应同质预测的有向社交网络进行了优化。所提出的方法具有一种基于mrf的新边势函数,它将迭代边权重估计纳入lbp,并通过方向敏感的势函数设计赋予在边上传递的消息具有方向性。我们使用大型twitter数据集将sybilhp与最先进的基于结构的检测方法进行比较,结果表明sybilhp具有卓越的性能。
[0133]
以上所示仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。