1.本发明涉及交通流预测领域,尤其涉及一种基于时空缓冲区的轨迹数据补全及交通流预测方法。
背景技术:
2.交通流(即汽车、自行车、人群等)反映了城市交通的实时交通热点和空间上的车辆数量分布,其预测对交通管理和城市建设具有重要意义。然而,准确预测交通流是一个极具挑战性的问题,它本质上是一个受复杂因素影响的时空现象。交通流预测的基础是获取待预测区域内的交通流轨迹数据,再通过对这些数据进行分析来反演交通流的时空变化趋势。然而,由于gps轨迹采集过程中不可避免地存在数据质量问题(如内容缺失、数据冗余、逻辑错误等),因此需要对轨迹进行补全。现有的轨迹数据补全方法主要是通过自身数据插值或者相似轨迹匹配的方法来实现的。
3.例如,申请号为cn201611019110.8的发明专利中提供了一种基于三阶贝塞尔曲线及插值的gps轨迹数据补全方法,该补全方法包括:采集gps轨迹数据,并进行预处理,剔除不符合要求的轨迹点,然后遍历轨迹点,计算相邻轨迹点的间隔时间,筛选出需要进行补全的轨迹点对,对每个待补全的轨迹点对,分别获取起始点和终止点的控制点,为该轨迹点对和两个控制点形成的四边形构建三阶贝塞尔曲线方程并求解,计算出该轨迹点对需要补全的轨迹点集。该方案中,其对于轨迹数据的补全主要通过自身轨迹信息来实现,但是这种补全过程的原理是对曲线进行平滑,但在现实中车辆轨迹往往是无法通过曲线平滑来反演的。例如两个非直线的路口之间的轨迹,其需要进行转弯或者掉头,此类轨迹不可能通过自身轨迹信息进行反演。
4.再例如,在申请号为cn202010347241.9的发明专利中提供了一种移动轨迹的处理方法和装置,该方法将待处理移动轨迹中存在缺失轨迹的坐标点组合确定第一坐标点组合,对每个第一坐标点组合,按匹配规则从历史轨迹库的多个参考轨迹中筛选出匹配的参考轨迹,作为该第一坐标点组合的补全轨迹;参考轨迹为包括第一坐标点组合的两个坐标点的完整轨迹;用第一坐标点组合的补全轨迹中位于第一坐标点组合的两个坐标点之间的坐标点补全缺失轨迹,得到补全后的移动轨迹。该方案中,其对于轨迹数据的补全主要通过匹配到的其他轨迹来实现,但是这种做法忽略了轨迹数据的时空异质性。因为城市内的交通存在众多人为影响因素,例如潮汐车道、临时交通管制、路面施工维修、交通事故绕道等等,直接在所有轨迹数据集中匹配相似轨迹可能存在与实际不符的情况。
5.由此可见,现有技术中的轨迹补全方法无法较好地对轨迹数据的时空异质性进行区分,导致匹配的轨迹数据无法很好地用于交通流预测。
技术实现要素:
6.为了克服上述现有技术的不足,本发明提供一种基于时空缓冲区的轨迹数据补全方法及交通流预测方法,可有效解决上述问题。
7.本发明具体采用的技术方案如下:
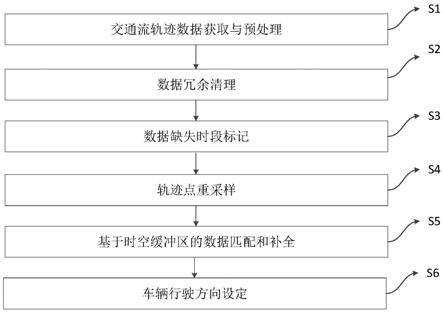
8.第一方面,本发明提供了一种基于时空缓冲区的轨迹数据补全方法,其包括以下步骤:
9.s1、获取待补全的交通流轨迹数据,并对其进行数据预处理,得到每一车辆的第一轨迹,所述第一轨迹由轨迹点组成,每一个轨迹点的信息包含车辆唯一编码、信息记录时间、经纬度坐标;
10.s2、对每一条所述第一轨迹进行冗余清理,若第一轨迹中存在一个时间段内的连续轨迹点经纬度坐标均相同时,将该时间段标记为非行驶时间,保留该时间段内首尾两个轨迹点并删除其余中间轨迹点,每一条第一轨迹经过冗余清理得到第二轨迹;
11.s3、针对每一条所述第二轨迹,查询其中每一个轨迹点的经纬度坐标是否存在缺失,若存在缺失则将对应轨迹点标记为缺失轨迹点,若不存在缺失则将对应轨迹点标记为完整轨迹点,将中间存在缺失轨迹点的两个完整轨迹点之间的时段作为数据缺失时段;
12.s4、对s3处理后的第二轨迹中除非行驶时间之外的其余行驶时间均按照固定间隔进行重采样,得到第三轨迹;
13.s5、遍历所有的第三轨迹,依次将存在数据缺失时段的每一条第三轨迹作为待补全轨迹;针对每一条待补全轨迹中的每一个数据缺失时段,获取位于该数据缺失时段首端的第一完整轨迹点和尾端的第二完整轨迹点,以第一完整轨迹点和第二完整轨迹点为中心分别建立第一空间缓冲区和第二空间缓冲区,同时以该数据缺失时段为中心在时间维度上向前后进行扩展从而建立时间缓冲区,从所有第三轨迹中提取在所述时间缓冲区范围内同时经过第一空间缓冲区和第二空间缓冲区的轨迹作为待匹配轨迹,计算所述待补全轨迹中的第一组合轨迹段与每一条待匹配轨迹中的第二组合轨迹段的轨迹相似度,基于轨迹相似度最大的待匹配轨迹对待补全轨迹中的数据缺失时段进行插值补全;每一条第三轨迹中的所有数据缺失时段均被补全后,形成第四轨迹;
14.所述第一组合轨迹段由待补全轨迹中位于第一空间缓冲区前端包含第一轨迹点数量的轨迹段与位于第二空间缓冲区后端包含第二轨迹点数量的轨迹段组合而成,所述第二组合轨迹段由待匹配轨迹中位于第一空间缓冲区前端包含第一轨迹点数量的轨迹段与位于第二空间缓冲区后端包含第二轨迹点数量的轨迹段组合而成;
15.s6、将所有第四轨迹中的每一个轨迹点映射至地图上,并对每一个轨迹点按照其轨迹走向设定车辆行驶方向,完成交通流轨迹数据的补全。
16.作为优选,s1中,所述数据预处理包括对交通流轨迹数据进行数据清洗以及无效字段去除。
17.作为优选,s2中,所述时间段的长度最低为10~30分钟。
18.作为优选,s4中,重采样过程中所采用的固定间隔为10~60秒。
19.作为优选,s5中,所述第一空间缓冲区和第二空间缓冲区为半径1~10米的圆形区域;所述时间缓冲区为将数据缺失时段在时间维度上各自向前后扩展0.5~1小时后得到的时段区间。
20.作为优选,s5中,所述轨迹相似度采用dtw算法计算。
21.作为优选,s5中,所述第一轨迹点数量和第二轨迹点数量为5~30个。
22.作为优选,s6中,每一个轨迹点的所述车辆行驶方向为前一个轨迹点与当前轨迹
点的连线延长线方向。
23.作为优选,s6中,将每一条第四轨迹中的所有轨迹点作为途经点,调用路径规划算法或者地图api还原出车辆行驶路径,从而得到连续的车辆行驶轨迹以及轨迹中任意点位的车辆行驶方向。
24.第二方面,本发明提供了一种交通流预测方法,其以第一方面中任一方案所述补全方法得到的交通流轨迹数据作为交通流预测模型的输入数据,并由训练后的交通流预测模型输出目标区域在目标时刻的交通流预测结果。
25.相对于现有技术而言,本发明的有益效果如下:
26.本发明针对交通流轨迹数据的特点,通过数据预处理、冗余处理、数据缺失时段标记和重采样,实现了轨迹数据的标准化,进而基于时空缓冲区对轨迹数据进行匹配和补全。本发明通过设置时空缓冲区,同时在空间维度和时间维度进行了待匹配轨迹的筛选,这种做法即合理解决了轨迹的时空异质性问题,又大大节省了后续轨迹相似度计算的计算量。本发明可以获得带有车辆行驶方向的完整轨迹数据集,为交通流量预测奠定数据基础。
附图说明
27.图1为基于时空缓冲区的轨迹数据补全方法的流程图;
28.图2为本发明中利用空间缓冲区进行轨迹匹配的示意图;
29.图3为第一种车辆行驶方向的获取示意图;
30.图4为第二种车辆行驶方向的获取示意图。
具体实施方式
31.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
32.相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
33.在本发明的一个较佳实施例中,提供了一种基于时空缓冲区的轨迹数据补全方法,补全后的交通流轨迹数据用于进行空间上不同位置的交通流量预测,其包括以下步骤:
34.s1、获取待补全的交通流轨迹数据,并对其进行数据预处理,得到每一车辆的第一轨迹,所述第一轨迹由一系列轨迹点组成,每一个轨迹点的信息包含车辆唯一编码、信息记录时间、经纬度坐标。
35.在本发明中,此类交通流轨迹数据可以是车载终端上传的定位数据,其中车辆可以是汽车也可以是其他的电动自行车、共享单车等,对此不做限制,视具体的使用场景而定。由于此类交通流轨迹数据往往包含了大量的字段,因此需要先对其进行预处理,本实施例中所采用的数据预处理包括对交通流轨迹数据进行数据清洗以及无效字段(例如序列号、车牌号、车辆id、车辆颜色、加密等)去除,仅保留车辆唯一编码、信息记录时间、经纬度坐标这三个字段。
36.作为一种具体实现形式,数据清洗方式可以根据原始数据的具体类型选用,本实施例中主要去除原始数据中的重复值和偏离正常范围的异常值,而对于经纬度坐标的缺失值不进行处理。
37.s2、对每一条所述第一轨迹进行冗余清理,若第一轨迹中存在一个时间段内的连续轨迹点经纬度坐标均相同时,将该时间段标记为非行驶时间,保留该时间段内首尾两个轨迹点并删除其余中间轨迹点,每一条第一轨迹经过冗余清理得到第二轨迹。
38.对交通流预测而言,其中的非行驶时间实际代表了车辆处于停车状态,而此类状态一般不能归类为正常的交通流量。例如,车辆停在路边停车场时,也会上报其定位数据而且定位数据存在部分偏差,但其实际处于非行驶时间,此时假如依然将轨迹点数据置于轨迹中,则会导致该位置的交通流量大大增加。因此本步骤中需要对非行驶时间进行标记,后续即可将这些车辆轨迹点排除在轨迹数据集之外。在实际应用时,考虑到定位数据的不稳定性,在判断连续轨迹点经纬度坐标是否相同时,应该设置一定的误差空间,即定位坐标差值在误差范围内的轨迹点都视为经纬度坐标相同。
39.但是在对非行驶时间进行标记时,需要合理区分正常的驻车等待时间和非行驶时间,这需要设置合理的时间段长度来区分。在本实施例中,用于区分非行驶时间的时间段的长度t最低为10~30分钟,即如果在时长大于t的时间内车辆长期处于某一位置不变,则将其视为非行驶时间,如果在时长不大于t的时间内车辆长期处于某一位置不变,则将其视为是行驶过程中的驻车等待时间。
40.s3、针对每一条所述第二轨迹,查询其中每一个轨迹点的经纬度坐标是否存在缺失,若存在缺失则将对应轨迹点标记为缺失轨迹点,若不存在缺失则将对应轨迹点标记为完整轨迹点,将中间存在缺失轨迹点的两个完整轨迹点之间的时段作为数据缺失时段。
41.由此,通过该步骤就可以从轨迹中标记出需要进行数据缺失补全的时段,后续仅需要对这些时段进行补全即可。
42.s4、对s3处理后的第二轨迹中除非行驶时间之外的其余行驶时间均按照固定间隔进行重采样,得到第三轨迹。
43.本步骤中,重采样的目的是为了统一轨迹中相邻轨迹点的间隔,为后续的轨迹相似度匹配统一匹配基础。重采样过程中所采用的固定间隔可根据实际的数据密度而定,优选为10~60秒。
44.例如,原始轨迹中每3秒记录一次轨迹点,这对于进一步计算来说过于频繁,因此可以采用固定时间间隔进行均匀采样,以20秒的新时间间隔定期获取原始轨迹上的轨迹点,形成第三轨迹。另外,对于多种来源的轨迹数据,也可以利用这种重采样方式统一时间间隔尺度。由此,最终形成的所有第三轨迹中,非行驶时间的重复数据已经被去除,同时所有行驶时间的轨迹点间隔也被统一,为后续的轨迹匹配奠定了基础。
45.s5、遍历所有的第三轨迹,依次将存在数据缺失时段的每一条第三轨迹作为待补全轨迹,针对每一条待补全轨迹中的每一个数据缺失时段,均执行以下的补全操作:
46.s51、获取位于该数据缺失时段首端的第一完整轨迹点和尾端的第二完整轨迹点,即位于数据缺失时段前端的第一个完整轨迹点和位于完整轨迹点后端的第一个完整轨迹点。
47.s52、以第一完整轨迹点和第二完整轨迹点为中心分别建立第一空间缓冲区和第
二空间缓冲区,同时以该数据缺失时段为中心在时间维度上向前后进行扩展从而建立时间缓冲区。
48.本步骤中,空间缓冲区(buffer)是以中心点为圆心形成的一个圆形区域,设置空间缓冲区的目的是为了将在轨迹匹配时着重考虑空间上的相邻轨迹,解决轨迹数据的空间异质性问题。因为,在实际的车辆运行过程中,大量车辆都会经过同一路段,这些经过同一路段的车辆轨迹可以作为缺失数据的轨迹补全时的参考轨迹,而其他路段中的轨迹即使相似其参考价值也相对较低。第一空间缓冲区和第二空间缓冲区的建立,可以消除路段的宽度对定位的影响以及定位数据自身的误差,从而提取与出待补全轨迹经过同一路段的所有轨迹。
49.例如,参见图2所示,若轨迹b为待补全轨迹,而该轨迹中第3和第4个轨迹点存在坐标缺失,两者之间即为数据缺失时段,需要进行补全。通过针对第3和第4个轨迹点各自建立空间缓冲区buffer1和buffer2,可以提取出轨迹c作为待匹配轨迹,而轨迹a没有经过空间缓冲区buffer2,因此表明其形式路径与本发明差异过大,车辆大概率走了另一条路线,故不作为待匹配轨迹。
50.另外,时间缓冲区是一个仿照空间缓冲区建立的时间维度的时段概念,其本质上相当于将数据缺失时段向两侧进行扩展,形成了一个包含数据缺失时段但大于数据缺失时段的时段区间。通过这个时间缓冲区,可以将与待补全轨迹在相近时间经过同一路段的轨迹进行提取。在轨迹提取时考虑时间维度的目的是解决轨迹数据的时间异质性问题,因为在实际的车辆运行过程中,同一个路段中的交通组织方式以及车辆行驶习惯可能是不同的。例如,某一区域中存在潮汐车道或者某一位置出现临时交通管制,那么该位置相邻的车辆其在不同时间的行驶轨迹可能出现差异,如果不考虑时间维度容易引入与实际不符的轨迹作为待补全轨迹。
51.上述空间缓冲区和时间缓冲区中,具体的缓冲区大小均需要根据实际进行调整,不宜过大也不宜过小。本实施例中,第一空间缓冲区和第二空间缓冲区推荐采用半径1~10米的圆形区域;而时间缓冲区推荐采用将数据缺失时段在时间维度上各自向前后扩展0.5~1小时后得到的时段区间。
52.由此可见,本发明中通过包含空间缓冲区和时间缓冲区在内的时空缓冲区,同时在空间维度和时间维度进行了待匹配轨迹的筛选。这种做法即合理解决了轨迹的时空异质性问题,又大大节省了后续轨迹相似度计算的计算量。
53.s53、从所有第三轨迹中提取在所述时间缓冲区范围内同时经过第一空间缓冲区和第二空间缓冲区的轨迹作为待匹配轨迹,计算所述待补全轨迹中的第一组合轨迹段与每一条待匹配轨迹中的第二组合轨迹段的轨迹相似度,基于轨迹相似度最大的待匹配轨迹对待补全轨迹中的数据缺失时段进行插值补全。
54.其中,第一组合轨迹段和第二组合轨迹段都是各自由两段轨迹段组成的组合轨迹,具体而言:第一组合轨迹段由待补全轨迹中位于第一空间缓冲区前端包含第一轨迹点数量n1的轨迹段与位于第二空间缓冲区后端包含第二轨迹点数量n2的轨迹段组合而成,第二组合轨迹段由待匹配轨迹中位于第一空间缓冲区前端包含第一轨迹点数量n1的轨迹段与位于第二空间缓冲区后端包含第二轨迹点数量n2的轨迹段组合而成。
55.需注意的是,上述第一组合轨迹段和第二组合轨迹段中,前后两段轨迹中的轨迹
点数量n1、n2是一一对应匹配的,这是为了保证轨迹相似度计算时的可对比性。一般而言,第一轨迹点数量n1和第二轨迹点数量n2均可采用5~30个。
56.另外,本步骤中采用的轨迹相似度算法可以是任意的可行算法,由于第一组合轨迹段和第二组合轨迹段都是序列数据,因此本发明中推荐采用dtw算法计算轨迹相似度。dtw算法属于现有技术,对此不再赘述其原理和具体实现。
57.当获得轨迹相似度最大的待匹配轨迹后,待补全轨迹中的数据缺失时段的轨迹点可以直接从这条轨迹相似度最大的待匹配轨迹中进行匹配获取,即将这条轨迹相似度最大的待匹配轨迹中位于两个空间缓冲区之间的轨迹点赋予待补全轨迹中的数据缺失时段。
58.s54、每一条第三轨迹中的所有数据缺失时段均按照s51~s53进行补全后,形成第四轨迹。
59.s6、将所有第四轨迹中的每一个轨迹点映射至地图上,并对每一个轨迹点按照其轨迹走向设定车辆行驶方向,完成交通流轨迹数据的补全。
60.本步骤的目的是为轨迹点赋予交通流预测所需的车辆行驶方向,本发明中车辆行驶方向的计算可以采用两种不同的方式:
61.第一种方式为:针对每一个轨迹点,将该轨迹点的前一个轨迹点与当前轨迹点的连线延长线方向作为车辆行驶方向。
62.举例而言,如图3所示,在这种方式中,对于轨迹点b2,其前一个轨迹点为b1,那么以b1为原点,将b1与b2相连,其射线方向记为轨迹点b2的车辆行驶方向。
63.这种方式可以对轨迹点的车辆行驶方向进行大致赋值,但是当轨迹有较多弯折时,其行驶方向与实际方向可能存在一定的偏差,因此本发明推荐采用第二种方式。
64.第二种方式为:将每一条第四轨迹中的所有轨迹点作为途经点,调用路径规划算法或者地图api还原出车辆行驶路径,从而得到连续的车辆行驶轨迹以及轨迹中任意点位的车辆行驶方向。
65.在这种方式中,相当于对原本离散的轨迹点进行了连续插值,形成了连续轨迹线。由于所有轨迹点并不直接进行相连然后计算其车辆行驶方向,而是先基于这些轨迹点还原车辆的实际行驶路径,其可以更好地反应车辆的行驶方向。一般而言,可以采用每个轨迹点处连续路径轨迹线的切线方向作为其车辆行驶方向。
66.举例而言,如图4所示,在这种方式中,对于轨迹点b2,弧线为还原出车辆行驶路径,因此该弧线上b2位置的切线即可记为轨迹点b2的车辆行驶方向。
67.需要说的是,本发明中的路径规划算法可以直接采用现有技术,例如dijkstra算法,地图api可以是百度、高德、google等商业地图软件所提供的的api接口,对此不做限制。
68.综上,本发明通过上述s1~s6的补全方法,即可得到完整的带有车辆行驶方向的轨迹数据集。
69.在本发明的另一实施例中,基于上述轨迹数据集,可以进一步得到一种交通流预测方法,其以前述补全方法得到的交通流轨迹数据作为交通流预测模型的输入数据,并由训练后的交通流预测模型输出目标区域在目标时刻的交通流预测结果。
70.需要说的是,本发明中的交通流预测模型不限,可以采用任意现有技术中可实现交通流预测的模型来实现,例如时空图神经网络、lstm等等。
71.以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有
关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。