技术特征:
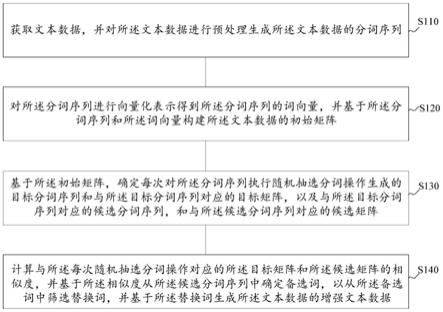
1.一种文本数据增强方法,其特征在于,包括:获取文本数据,并对所述文本数据进行预处理生成所述文本数据的分词序列;对所述分词序列进行向量化表示得到所述分词序列的词向量,并基于所述分词序列和所述词向量构建所述文本数据的初始矩阵;基于所述初始矩阵,确定每次对所述分词序列执行随机抽选分词操作生成的目标分词序列和与所述目标分词序列对应的目标矩阵,以及与所述目标分词序列对应的候选分词序列,和与所述候选分词序列对应的候选矩阵;计算与所述每次随机抽选分词操作对应的所述目标矩阵和所述候选矩阵的相似度,并基于所述相似度从所述候选分词序列中确定备选词,以从所述备选词中筛选替换词,并基于所述替换词生成所述文本数据的增强文本数据。2.根据权利要求1所述的文本数据增强方法,其特征在于,所述对所述文本数据进行预处理生成所述文本数据的分词序列,包括:对所述文本数据进行泛化处理,确定所述文本数据的泛化字符串;基于所述泛化字符串对所述文本数据进行分词处理,生成所述文本数据的分词序列。3.根据权利要求1所述的文本数据增强方法,其特征在于,所述对所述分词序列进行向量化表示得到所述分词序列的词向量,包括:获取预构建的词嵌入模型,并基于所述词嵌入模型对所述分词序列进行文本向量化处理得到所述分词序列的词向量。4.根据权利要求1所述的文本数据增强方法,其特征在于,所述基于所述初始矩阵,确定每次对所述分词序列执行随机抽选分词操作生成的目标分词序列和与所述目标分词序列对应的目标矩阵,包括:读取随机抽选分词操作的目标次数,并对所述分词序列执行所述目标次数的随机抽选分词操作;在每次对所述分词序列执行所述随机抽选分词操作时,确定当次随机抽选的第一分词,并基于所述第一分词在所述分词序列中的位置计算所述第一分词的窗口文本距离;以及将所述分词序列中以所述第一分词为中心,且满足所述窗口文本距离的子分词序列作为目标分词序列,并基于所述初始矩阵生成与所述目标分词序列对应的目标矩阵。5.根据权利要求4所述的文本数据增强方法,其特征在于,所述方法还包括:在检测到所述第一分词与所述泛化字符串相同时,对所述分词序列重新执行所述随机抽选分词操作。6.根据权利要求1所述的文本数据增强方法,其特征在于,所述确定与所述目标分词序列对应的候选分词序列,和与所述候选分词序列对应的候选矩阵,包括:从所述分词序列中随机选取第二分词,并通过所述第二分词替换所述目标分词序列中的第一分词得到候选分词序列;基于所述初始矩阵生成与所述候选分词序列匹配的候选矩阵。7.根据权利要求1或6所述的文本数据增强方法,其特征在于,所述计算与所述每次随机抽选分词操作对应的所述目标矩阵和所述候选矩阵的相似度,并基于所述相似度从所述候选分词序列中确定备选词,包括:
对与所述每次随机抽选分词操作对应的所述目标矩阵和所述候选矩阵分别进行归一化处理,得到归一化目标矩阵和归一化候选矩阵;计算所述归一化目标矩阵和所述归一化候选矩阵中列向量的相似度的平均和,并将所述平均和作为标准相似度;获取预设相似度阈值,并在检测到所述标准相似度大于所述相似度阈值时,将与所述候选矩阵对应的第二分词作为备选词。8.根据权利要求1所述的文本数据增强方法,其特征在于,所述从所述备选词中筛选替换词,并基于所述替换词生成所述文本数据的增强文本数据,包括:对大于所述相似度阈值的所有所述标准相似度,按序排列得到标准相似度序列;读取预设替换词数目,并确定所述标准相似度序列中与所述替换词数目匹配的数值较大的子标准相似度序列;将所述子标准相似度序列各自的备选词作为替换词,并基于所述替换词生成所述文本数据的增强文本数据。9.根据权利要求1或8所述的文本数据增强方法,其特征在于,所述方法还包括:确定所述标准相似度序列的长度,并在检测到所述长度小于所述替换词数目时,将与所述标准相似度序列对应的备选词均作为所述替换词。10.一种文本数据增强装置,其特征在于,包括:分词序列生成模块,用于获取文本数据,并对所述文本数据进行预处理生成所述文本数据的分词序列;初始矩阵构建模块,用于对所述分词序列进行向量化表示得到所述分词序列的词向量,并基于所述分词序列和所述词向量构建所述文本数据的初始矩阵;随机抽选分词操作模块,用于基于所述初始矩阵,确定每次对所述分词序列执随机抽选分词操作生成的目标分词序列和与所述目标分词序列对应的目标矩阵,以及与所述目标分词序列对应的候选分词序列,和与所述候选分词序列对应的候选矩阵;替换词确定模块,用于计算与所述每次随机抽选分词操作对应的所述目标矩阵和所述候选矩阵的相似度,并基于所述相似度从所述候选分词序列中确定备选词,以从所述备选词中筛选替换词,并基于所述替换词生成所述文本数据的增强文本数据。11.一种电子设备,包括:处理器;以及存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时实现如权利要求1至9中任一项所述的文本数据增强方法。12.一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至9中任一项所述的文本数据增强方法。
技术总结
本公开提供了一种文本数据增强方法及装置、电子设备、存储介质,涉及计算机技术领域。该文本数据增强方法包括:生成文本数据泛化后的分词序列和词向量;确定每次从分词序列随机抽选分词生成的目标分词序列、替换目标分词序列的中心词得到的候选分词序列、与每一目标分词序列对应的目标矩阵、与每一候选分词序列对应的候选矩阵;计算每一目标矩阵和候选矩阵中不同词向量之间的相似度平均和,并将与相似度平均和大于相似度阈值对应的候选矩阵的候选分词序列的中心词作为备选词,以从备选词中选取相似度平均和较大的目标备选词作为替换词,并基于替换词生成增强文本数据。本公开实施例的技术方案可以提高文本数据增强的可靠性、有效性、普适性。普适性。普适性。
技术研发人员:王有元 杨旭
受保护的技术使用者:中国电信股份有限公司
技术研发日:2021.12.23
技术公布日:2022/4/8
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。