1.本技术涉及用于与声场相关的音频表示和渲染的装置和方法,但非排他地涉及用于音频解码器的音频表示的装置和方法。
背景技术:
2.用多个观看方向呈现媒体的空间音频回放是已知的。这种回放的示例包括这种媒体的观看视觉内容,包括用以下方式回放:在具有(至少)头部定向跟踪的头戴式显示器(或头戴式电话)上;或者在非头戴式的电话屏幕上,其中,可以通过改变电话的位置/定向或通过任何用户接口手势来跟踪观看方向;或者在周围的屏幕上。
3.与“具有多个观看方向的媒体”相关联的视频例如可以是360度视频、180度视频、或视角比传统视频宽得多的其他视频。传统视频是指通常在屏幕上整体显示的视频内容,而没有改变观看方向的选项(或任何特定需要)。
4.与具有多个观看方向的视频相关联的音频可以在耳机上呈现,其中,观看方向被跟踪并影响空间音频回放;或者可以用环绕扬声器设置来呈现。
5.与具有多个观看方向的视频相关联的空间音频可以源自从麦克风阵列(例如,被安装在类似ozo的vr相机或手持式移动设备上的阵列)捕获的空间音频,或者源自诸如录音室混音之类的其他源。音频内容也可以是诸如麦克风捕获的声音和所添加的解说员轨道之类的若干内容类型的混合。
6.与具有多个观看方向的视频相关联的空间音频可以采用各种形式,例如:由球面谐波音频信号分量组成的全景环绕声(ambisonic)信号(任意阶)。球面谐波可以被认为是一组空间选择性波束信号。当前例如在youtube 360vr视频服务中使用ambisonics。ambisonics的优势在于它是一种简单且定义明确的信号表示;环绕扬声器信号,例如5.1。目前,典型电影的空间音频是以这种形式传送的。环绕扬声器信号的优势是简单性和传统兼容性。类似于环绕扬声器信号格式的一些音频格式包括音频对象,其可以被视为具有时变位置的音频通道。位置可以通知音频对象的方向和距离两者,或者方向;参数化空间音频,诸如两个音频通道音频信号和感知相关频带中的相关联的空间元数据。一些最先进的音频编码方法和空间音频捕获方法应用了这种信号表示。空间元数据在本质上确定了应如何在接收器端空间再现音频信号(例如,到在不同频率的那些方向)。参数化空间音频的优势在于其多功能性、质量、以及使用低比特率编码的能力。
技术实现要素:
7.根据第一方面,提供了一种装置,其包括被配置为执行以下操作的部件:获得散焦方向(defocus direction);处理表示音频场景的空间音频信号以生成表示基于散焦方向的经修改的音频场景的经处理的空间音频信号,以便在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重;以及输出经处理的空间音频信号,其中,基于散焦方向的经修改的音频场景在散焦方向上至少部分地使
能空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的去加重。
8.该部件可以进一步被配置为获得散焦量(defocus amount),并且其中,被配置为处理空间音频信号的部件可以被配置为:根据散焦量,在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重。
9.被配置为处理空间音频信号的部件可以被配置为执行以下中的至少一个:在散焦方向上至少部分地相对于空间音频信号的其他部分至少部分地减少空间音频信号的一部分的加重;以及在散焦方向上相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的加重。
10.被配置为处理空间音频信号的部件可以被配置为执行以下中的至少一个:根据散焦量,在散焦方向上至少部分地相对于空间音频信号的其他部分至少部分地降低空间音频信号的一部分的声级;以及根据散焦量,在散焦方向上相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的声级。
11.该部件可以进一步被配置为获得散焦形状(defocus shape),并且其中,被配置为处理空间音频信号的部件可以被配置为:在散焦方向上并在散焦形状内至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重。
12.被配置为处理空间音频信号的部件可以被配置为执行以下中的至少一个:在散焦方向上并在散焦形状内至少部分地相对于空间音频信号的其他部分至少部分地减少空间音频信号的一部分的加重;以及在散焦方向上并在散焦形状内相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的加重。
13.被配置为处理空间音频信号的部件可以被配置为执行以下中的至少一个:根据散焦量,在散焦方向上并在散焦形状内至少部分地相对于空间音频信号的其他部分至少部分地降低空间音频信号的一部分的声级;以及根据散焦量,在散焦方向上并在散焦形状内相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的声级。
14.该部件可以被配置为获得再现控制信息,以控制输出经处理的空间音频信号的至少一个方面,并且其中,被配置为输出经处理的空间音频信号的部件可以被配置为执行以下中的一个:根据再现控制信息,处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号;在被配置为基于散焦方向来处理表示音频场景的空间音频信号以生成表示经修改的音频场景的经处理的空间音频信号并输出经处理的空间音频信号作为输出空间音频信号的部件之前根据再现控制信息处理空间音频信号。
15.空间音频信号和经处理的空间音频信号可以包括相应的ambisonic信号,并且其中,被配置为将空间音频信号处理成经处理的空间音频信号的部件可以被配置为针对一个或多个频率子带,执行以下操作:从空间音频信号中提取表示从聚焦方向(focus direction)到达的声音分量的单通道目标音频信号;生成聚焦的空间音频信号,其中,该聚焦的音频信号被布置在由散焦方向定义的空间位置;以及将经处理的空间音频信号创建为从空间音频信号中减去聚焦的空间音频信号的线性组合,其中,聚焦的空间音频信号和空间音频信号中的至少一个通过基于散焦量而导出的相应的缩放因子来缩放,以降低声音在散焦方向上的相对级别。
16.被配置为提取单通道目标音频信号的部件可以被配置为:应用波束成形器以从空间音频信号中得到表示从散焦方向到达的声音分量的波束成形信号;以及应用后置滤波器
以基于波束成形信号得到经处理的音频信号,从而调整波束成形信号的频谱以近似从散焦方向到达的声音的频谱。
17.空间音频信号和经处理的空间音频信号可以包括相应的一阶ambisonic信号。
18.空间音频信号和经处理的空间音频信号可以包括相应的参数化空间音频信号,其中,参数化空间音频信号可以包括一个或多个音频通道以及空间元数据,其中,空间元数据可以包括针对多个频率子带的相应方向指示和能量比率参数,其中,被配置为处理空间音频信号以生成经处理的空间音频信号的部件可以被配置为:针对一个或多个频率子带,计算散焦方向与针对空间音频信号的相应频率子带而指示的方向之间的相应的角度差;针对一个或多个频率子带,基于针对相应频率子带而计算的角度差,通过使用预定义的角度差函数和基于散焦量而导出的缩放因子,导出相应的增益值;针对经处理的空间音频信号的一个或多个频率子带,基于空间音频信号的相应频率子带的能量比率参数以及增益值,计算相应的更新定向能量(updated directional energy)值;针对经处理的空间音频信号的一个或多个频带,基于空间音频信号的相应频率子带的能量比率参数以及缩放因子,计算相应的更新环境能量(updated ambient energy)值;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量除以更新定向能量与更新环境能量之和,计算相应的经修改的能量比率参数;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量与更新环境能量之和,计算相应的频谱调整因子;以及组成经处理的空间音频信号,该经处理的空间音频信号包括空间音频信号的一个或多个音频通道、空间音频信号的方向指示、经修改的能量比率参数、以及频谱调整因子。
19.空间音频信号和经处理的空间音频信号可以包括相应的参数化空间音频信号,其中,参数化空间音频信号可以包括一个或多个音频通道以及空间元数据,其中,空间元数据可以包括针对多个频率子带的相应方向指示和能量比率参数,其中,被配置为处理空间音频信号以生成经处理的空间音频信号的部件可以被配置为:针对一个或多个频率子带,计算散焦方向与针对空间音频信号的相应频率子带而指示的方向之间的相应的角度差;针对一个或多个频率子带,基于针对相应频率子带而计算的角度差,通过使用预定义的角度差函数和基于散焦量而导出的缩放因子,导出相应的增益值;针对经处理的空间音频信号的一个或多个频率子带,基于空间音频信号的相应频率子带的能量比率参数以及增益值,计算相应的更新定向能量值;针对经处理的空间音频信号的一个或多个频带,基于空间音频信号的相应频率子带的能量比率参数以及缩放因子,计算相应的更新环境能量值;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量除以更新定向能量与更新环境能量之和,计算相应的经修改的能量比率参数;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量与更新环境能量之和,计算相应的频谱调整因子;在一个或多个频率子带中,通过将空间音频信号的一个或多个音频通道中的相应音频通道的相应频带乘以针对相应频率子带而导出的频谱调整因子,得到一个或多个增强音频通道;组成经处理的空间音频信号,该经处理的空间音频信号包括一个或多个增强音频通道、空间音频信号的方向指示、以及经修改的能量比率参数。
20.空间音频信号和经处理的空间音频信号可以包括相应的根据第一预定义扬声器配置的多通道扬声器信号,并且其中,被配置为处理空间音频信号以生成经处理的空间音频信号的部件可以被配置为:计算散焦方向与针对空间音频信号的相应通道而指示的扬声
器方向之间的相应的角度差;针对空间音频信号的每个通道,基于针对相应通道而计算的角度差,通过使用预定义的角度差函数和基于散焦量而导出的缩放因子,导出相应的增益值;通过将空间音频信号的相应通道乘以针对相应通道而导出的增益值,得到一个或多个经修改的音频通道;以及提供经修改的音频通道作为经处理的空间音频信号。
21.预定义的角度差函数可以产生增益值,该增益值随着角度差的值的减小而减小,并随着角度差的值的增大而增大。
22.经处理的空间音频信号可以包括ambisonic信号,并且输出空间音频信号可以包括双通道双耳信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且其中,被配置为根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的部件可以被配置为:基于所指示的再现定向,生成旋转矩阵;将经处理的空间音频信号的通道与旋转矩阵相乘以得到旋转后的空间音频信号;使用预定义的一组有限脉冲响应(fir)滤波器对来对旋转后的空间音频信号的通道进行滤波,其中,该组fir滤波器对是基于头部相关脉冲响应函数(hrtf)或头部相关脉冲响应(hrir)的数据集而生成的;以及将双耳信号的左通道和右通道生成为针对左通道和右通道中的相应一个通道而得到的旋转后的空间音频信号的滤波后通道之和。
23.输出空间音频信号可以包括双通道双耳音频信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且被配置为根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的部件可以被配置为:在所述一个或多个频率子带中,通过将经处理的空间音频信号的一个或多个音频通道中的相应音频通道的相应频带乘以针对相应频率子带而接收的频谱调整因子,得到一个或多个增强音频通道;以及根据所指示的再现方向,将一个或多个增强音频通道转换成双通道双耳音频信号。
24.输出空间音频信号可以包括双通道双耳音频信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且其中,被配置为根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的部件可以被配置为:根据所指示的再现方向,将一个或多个增强音频通道转换成双通道双耳音频信号。
25.输出空间音频信号可以包括双通道双耳信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且其中,被配置为根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的部件可以被配置为:根据所指示的再现方向,选择一组头部相关传递函数(hrtf);以及将经处理的空间音频信号的通道转换成双通道双耳信号,该双通道双耳信号使用所选择的一组hrtf来传送旋转后的音频场景。
26.再现控制信息可以包括第二预定义扬声器配置的指示,并且输出空间音频信号可以包括根据第二预定义扬声器配置的多通道扬声器信号,并且其中,被配置为根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的部件可以被配置为:通过被配置为执行以下操作来基于经处理的空间音频信号的通道并使用幅度平移来得到输出空间音频信号的通道:导出包括幅度平移增益的转换矩阵,并使用转换矩阵来乘以经处理的空间音频信号的通道以得到输出空间音频信号
的通道,其中,该幅度平移增益提供从第一预定义扬声器配置到第二预定义扬声器配置的映射。
27.该部件可以进一步被配置为:从包括至少一个方向传感器的传感器装置和至少一个用户输入获得散焦输入,其中,该散焦输入包括基于至少一个方向传感器的方向的散焦方向的指示。
28.散焦输入还可以包括散焦量的指示符。
29.散焦输入还可以包括散焦形状的指示符。
30.散焦形状可以包括以下中的至少一个:散焦形状宽度;散焦形状高度;散焦形状半径;散焦形状距离;散焦形状深度;散焦形状范围;散焦形状直径;以及散焦形状表征器。
31.散焦方向可以是由散焦方向的范围定义的弧。
32.根据第二方面,提供了一种方法,其包括:获得散焦方向;处理表示音频场景的空间音频信号以生成表示基于散焦方向的经修改的音频场景的经处理的空间音频信号,以便在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重;以及输出经处理的空间音频信号,其中,基于散焦方向的经修改的音频场景在散焦方向上至少部分地使能空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的去加重。
33.该方法还可以包括获得散焦量,并且其中,处理空间音频信号可以包括:根据散焦量,在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重。
34.处理空间音频信号可以包括以下中的至少一个:在散焦方向上至少部分地相对于空间音频信号的其他部分至少部分地减少空间音频信号的一部分的加重;以及在散焦方向上相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的加重。
35.处理空间音频信号可以包括以下中的至少一个:根据散焦量,在散焦方向上至少部分地相对于空间音频信号的其他部分至少部分地降低空间音频信号的一部分的声级;以及根据散焦量,在散焦方向上相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的声级。
36.该方法还可以包括获得散焦形状,并且其中,处理空间音频信号可以包括:在散焦方向上并在散焦形状内至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重。
37.处理空间音频信号可以包括以下中的至少一个:在散焦方向上并在散焦形状内至少部分地相对于空间音频信号的其他部分至少部分地减少空间音频信号的一部分的加重;以及在散焦方向上并在散焦形状内相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的加重。
38.处理空间音频信号可以包括以下中的至少一个:根据散焦量,在散焦方向上并在散焦形状内至少部分地相对于空间音频信号的其他部分至少部分地降低空间音频信号的一部分的声级;以及根据散焦量,在散焦方向上并在散焦形状内相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的声级。
39.该方法可以包括获得再现控制信息,以控制输出经处理的空间音频信号的至少一个方面,并且其中,输出经处理的空间音频信号可以包括以下中的一个:根据再现控制信
息,处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号;在被配置为基于散焦方向来处理表示音频场景的空间音频信号以生成表示经修改的音频场景的经处理的空间音频信号并输出经处理的空间音频信号作为输出空间音频信号的部件之前根据再现控制信息处理空间音频信号。
40.空间音频信号和经处理的空间音频信号可以包括相应的ambisonic信号,并且其中,将空间音频信号处理成经处理的空间音频信号可以包括针对一个或多个频率子带:从空间音频信号中提取表示从聚焦方向到达的声音分量的单通道目标音频信号;生成聚焦的空间音频信号,其中,该聚焦的音频信号被布置在由散焦方向定义的空间位置;以及将经处理的空间音频信号创建为从空间音频信号中减去聚焦的空间音频信号的线性组合,其中,聚焦的空间音频信号和空间音频信号中的至少一个通过基于散焦量而导出的相应的缩放因子来缩放,以降低声音在散焦方向上的相对级别。
41.提取单通道目标音频信号可以包括:应用波束成形器以从空间音频信号中得到表示从散焦方向到达的声音分量的波束成形信号;以及应用后置滤波器以基于波束成形信号得到经处理的音频信号,从而调整波束成形信号的频谱以近似从散焦方向到达的声音的频谱。
42.空间音频信号和经处理的空间音频信号可以包括相应的一阶ambisonic信号。
43.空间音频信号和经处理的空间音频信号可以包括相应的参数化空间音频信号,其中,参数化空间音频信号可以包括一个或多个音频通道以及空间元数据,其中,空间元数据可以包括针对多个频率子带的相应方向指示和能量比率参数,其中,处理空间音频信号以生成经处理的空间音频信号可以包括:针对一个或多个频率子带,计算散焦方向与针对空间音频信号的相应频率子带而指示的方向之间的相应的角度差;针对一个或多个频率子带,基于针对相应频率子带而计算的角度差,通过使用预定义的角度差函数和基于散焦量而导出的缩放因子,导出相应的增益值;针对经处理的空间音频信号的一个或多个频率子带,基于空间音频信号的相应频率子带的能量比率参数以及增益值,计算相应的更新定向能量值;针对经处理的空间音频信号的一个或多个频带,基于空间音频信号的相应频率子带的能量比率参数以及缩放因子,计算相应的更新环境能量值;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量除以更新定向能量与更新环境能量之和,计算相应的经修改的能量比率参数;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量与更新环境能量之和,计算相应的频谱调整因子;以及组成经处理的空间音频信号,该经处理的空间音频信号包括空间音频信号的一个或多个音频通道、空间音频信号的方向指示、经修改的能量比率参数、以及频谱调整因子。
44.空间音频信号和经处理的空间音频信号可以包括相应的参数化空间音频信号,其中,参数化空间音频信号可以包括一个或多个音频通道以及空间元数据,其中,空间元数据可以包括针对多个频率子带的相应方向指示和能量比率参数,其中,处理空间音频信号以生成经处理的空间音频信号可以包括:针对一个或多个频率子带,计算散焦方向与针对空间音频信号的相应频率子带而指示的方向之间的相应的角度差;针对一个或多个频率子带,基于针对相应频率子带而计算的角度差,通过使用预定义的角度差函数和基于散焦量而导出的缩放因子,导出相应的增益值;针对经处理的空间音频信号的一个或多个频率子带,基于空间音频信号的相应频率子带的能量比率参数以及增益值,计算相应的更新定向
能量值;针对经处理的空间音频信号的一个或多个频带,基于空间音频信号的相应频率子带的能量比率参数以及缩放因子,计算相应的更新环境能量值;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量除以更新定向能量与更新环境能量之和,计算相应的经修改的能量比率参数;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量与更新环境能量之和,计算相应的频谱调整因子;在一个或多个频率子带中,通过将空间音频信号的一个或多个音频通道中的相应音频通道的相应频带乘以针对相应频率子带而导出的频谱调整因子,得到一个或多个增强音频通道;组成经处理的空间音频信号,该经处理的空间音频信号包括一个或多个增强音频通道、空间音频信号的方向指示、以及经修改的能量比率参数。
45.空间音频信号和经处理的空间音频信号可以包括相应的根据第一预定义扬声器配置的多通道扬声器信号,并且其中,处理空间音频信号以生成经处理的空间音频信号可以包括:计算散焦方向与针对空间音频信号的相应通道而指示的扬声器方向之间的相应的角度差;针对空间音频信号的每个通道,基于针对相应通道而计算的角度差,通过使用预定义的角度差函数和基于散焦量而导出的缩放因子,导出相应的增益值;通过将空间音频信号的相应通道乘以针对相应通道而导出的增益值,得到一个或多个经修改的音频通道;以及提供经修改的音频通道作为经处理的空间音频信号。
46.预定义的角度差函数可以产生增益值,该增益值随着角度差的值的减小而减小,并随着角度差的值的增大而增大。
47.经处理的空间音频信号可以包括ambisonic信号,并且输出空间音频信号可以包括双通道双耳信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且其中,根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号可以包括:基于所指示的再现定向,生成旋转矩阵;将经处理的空间音频信号的通道与旋转矩阵相乘以得到旋转后的空间音频信号;使用预定义的一组有限脉冲响应(fir)滤波器对来对旋转后的空间音频信号的通道进行滤波,其中,该组fir滤波器对是基于头部相关脉冲响应函数(hrtf)或头部相关脉冲响应(hrir)的数据集而生成的;以及将双耳信号的左通道和右通道生成为针对左通道和右通道中的相应一个通道而得到的旋转后的空间音频信号的滤波后通道之和。
48.输出空间音频信号可以包括双通道双耳音频信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号可以包括:在所述一个或多个频率子带中,通过将经处理的空间音频信号的一个或多个音频通道中的相应音频通道的相应频带乘以针对相应频率子带而接收的频谱调整因子,得到一个或多个增强音频通道;以及根据所指示的再现方向,将一个或多个增强音频通道转换成双通道双耳音频信号。
49.输出空间音频信号可以包括双通道双耳音频信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且其中,根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号可以包括:根据所指示的再现方向,将一个或多个增强音频通道转换成双通道双耳音频信号。
50.输出空间音频信号可以包括双通道双耳信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且其中,根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号可以包括:根据所指示的再现方向,选择一组头部相关传递函数(hrtf);以及将经处理的空间音频信号的通道转换成双通道双耳信号,该双通道双耳信号使用所选择的一组hrtf来传送旋转后的音频场景。
51.再现控制信息可以包括第二预定义扬声器配置的指示,并且输出空间音频信号可以包括根据第二预定义扬声器配置的多通道扬声器信号,并且其中,根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号可以包括:通过被配置为执行以下操作来基于经处理的空间音频信号的通道并使用幅度平移来得到输出空间音频信号的通道:导出包括幅度平移增益的转换矩阵,并使用转换矩阵来乘以经处理的空间音频信号的通道以得到输出空间音频信号的通道,其中,该幅度平移增益提供从第一预定义扬声器配置到第二预定义扬声器配置的映射。
52.该方法还可以包括:从包括至少一个方向传感器的传感器装置和至少一个用户输入获得散焦输入,其中,该散焦输入包括基于至少一个方向传感器的方向的散焦方向的指示。
53.散焦输入还可以包括散焦量的指示符。
54.散焦输入还可以包括散焦形状的指示符。
55.散焦形状可以包括以下中的至少一个:散焦形状宽度;散焦形状高度;散焦形状半径;散焦形状距离;散焦形状深度;散焦形状范围;散焦形状直径;以及散焦形状表征器。
56.散焦方向可以是由散焦方向的范围定义的弧。
57.根据第三方面,提供了一种装置,其包括至少一个处理器和包括计算机程序代码的至少一个存储器,该至少一个存储器和计算机程序代码被配置为与至少一个处理器一起使该装置至少:获得散焦方向;处理表示音频场景的空间音频信号以生成表示基于散焦方向的经修改的音频场景的经处理的空间音频信号,以便在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重;以及输出经处理的空间音频信号,其中,基于散焦方向的经修改的音频场景在散焦方向上至少部分地使能空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的去加重。
58.可以进一步使该装置获得散焦量,并且其中,被使得处理空间音频信号的该装置可以被使得:根据散焦量,在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重。
59.被使得处理空间音频信号的该装置可以被使得执行以下中的至少一个:在散焦方向上至少部分地相对于空间音频信号的其他部分至少部分地减少空间音频信号的一部分的加重;以及在散焦方向上相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的加重。
60.被使得处理空间音频信号的该装置可以被使得执行以下中的至少一个:根据散焦量,在散焦方向上至少部分地相对于空间音频信号的其他部分至少部分地降低空间音频信号的一部分的声级;以及根据散焦量,在散焦方向上相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的声级。
61.可以进一步使该装置获得散焦形状,并且其中,被使得处理空间音频信号的该装置可以被使得:在散焦方向上并在散焦形状内至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重。
62.被使得处理空间音频信号的该装置可以被使得执行以下中的至少一个:在散焦方向上并在散焦形状内至少部分地相对于空间音频信号的其他部分至少部分地减少空间音频信号的一部分的加重;以及在散焦方向上并在散焦形状内相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的加重。
63.被使得处理空间音频信号的该装置可以被使得执行以下中的至少一个:根据散焦量,在散焦方向上并在散焦形状内至少部分地相对于空间音频信号的其他部分至少部分地降低空间音频信号的一部分的声级;以及根据散焦量,在散焦方向上并在散焦形状内相对于空间音频信号的一部分至少部分地增大空间音频信号的其他部分的声级。
64.可以使该装置获得再现控制信息以控制输出经处理的空间音频信号的至少一个方面,并且其中,被使得处理空间音频信号的该装置可以被使得执行以下中的一个:根据再现控制信息,处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号;在被配置为基于散焦方向来处理表示音频场景的空间音频信号以生成表示经修改的音频场景的经处理的空间音频信号并输出经处理的空间音频信号作为输出空间音频信号的部件之前根据再现控制信息处理空间音频信号。
65.空间音频信号和经处理的空间音频信号可以包括相应的ambisonic信号,并且其中,被使得将空间音频信号处理成经处理的空间音频信号的该装置可以被使得针对一个或多个频率子带,执行以下操作:从空间音频信号中提取表示从聚焦方向到达的声音分量的单通道目标音频信号;生成聚焦的空间音频信号,其中,该聚焦的音频信号被布置在由散焦方向定义的空间位置;以及将经处理的空间音频信号创建为从空间音频信号中减去聚焦的空间音频信号的线性组合,其中,聚焦的空间音频信号和空间音频信号中的至少一个通过基于散焦量而导出的相应的缩放因子来缩放,以降低声音在散焦方向上的相对级别。
66.被使得提取单通道目标音频信号的该装置可以被使得:应用波束成形器以从空间音频信号中得到表示从散焦方向到达的声音分量的波束成形信号;以及应用后置滤波器以基于波束成形信号得到经处理的音频信号,从而调整波束成形信号的频谱以近似从散焦方向到达的声音的频谱。
67.空间音频信号和经处理的空间音频信号可以包括相应的一阶ambisonic信号。
68.空间音频信号和经处理的空间音频信号可以包括相应的参数化空间音频信号,其中,参数化空间音频信号可以包括一个或多个音频通道以及空间元数据,其中,空间元数据可以包括针对多个频率子带的相应方向指示和能量比率参数,其中,被使得处理空间音频信号以生成经处理的空间音频信号的该装置可以被使得:针对一个或多个频率子带,计算散焦方向与针对空间音频信号的相应频率子带而指示的方向之间的相应的角度差;针对一个或多个频率子带,基于针对相应频率子带而计算的角度差,通过使用预定义的角度差函数和基于散焦量而导出的缩放因子,导出相应的增益值;针对经处理的空间音频信号的一个或多个频率子带,基于空间音频信号的相应频率子带的能量比率参数以及增益值,计算相应的更新定向能量值;针对经处理的空间音频信号的一个或多个频带,基于空间音频信号的相应频率子带的能量比率参数以及缩放因子,计算相应的更新环境能量值;针对经处
理的空间音频信号的一个或多个频率子带,基于更新定向能量除以更新定向能量与更新环境能量之和,计算相应的经修改的能量比率参数;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量与更新环境能量之和,计算相应的频谱调整因子;以及组成经处理的空间音频信号,该经处理的空间音频信号包括空间音频信号的一个或多个音频通道、空间音频信号的方向指示、经修改的能量比率参数、以及频谱调整因子。
69.空间音频信号和经处理的空间音频信号可以包括相应的参数化空间音频信号,其中,参数化空间音频信号可以包括一个或多个音频通道以及空间元数据,其中,空间元数据可以包括针对多个频率子带的相应方向指示和能量比率参数,其中,被使得处理空间音频信号以生成经处理的空间音频信号的该装置可以被使得:针对一个或多个频率子带,计算散焦方向与针对空间音频信号的相应频率子带而指示的方向之间的相应的角度差;针对一个或多个频率子带,基于针对相应频率子带而计算的角度差,通过使用预定义的角度差函数和基于散焦量而导出的缩放因子,导出相应的增益值;针对经处理的空间音频信号的一个或多个频率子带,基于空间音频信号的相应频率子带的能量比率参数以及增益值,计算相应的更新定向能量值;针对经处理的空间音频信号的一个或多个频带,基于空间音频信号的相应频率子带的能量比率参数以及缩放因子,计算相应的更新环境能量值;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量除以更新定向能量与更新环境能量之和,计算相应的经修改的能量比率参数;针对经处理的空间音频信号的一个或多个频率子带,基于更新定向能量与更新环境能量之和,计算相应的频谱调整因子;在一个或多个频率子带中,通过将空间音频信号的一个或多个音频通道中的相应音频通道的相应频带乘以针对相应频率子带而导出的频谱调整因子,得到一个或多个增强音频通道;组成经处理的空间音频信号,该经处理的空间音频信号包括一个或多个增强音频通道、空间音频信号的方向指示、以及经修改的能量比率参数。
70.空间音频信号和经处理的空间音频信号可以包括相应的根据第一预定义扬声器配置的多通道扬声器信号,并且其中,被使得处理空间音频信号以生成经处理的空间音频信号的该装置可以被使得:计算散焦方向与针对空间音频信号的相应通道而指示的扬声器方向之间的相应的角度差;针对空间音频信号的每个通道,基于针对相应通道而计算的角度差,通过使用预定义的角度差函数和基于散焦量而导出的缩放因子,导出相应的增益值;通过将空间音频信号的相应通道乘以针对相应通道而导出的增益值,得到一个或多个经修改的音频通道;以及提供经修改的音频通道作为经处理的空间音频信号。
71.预定义的角度差函数可以产生增益值,该增益值随着角度差的值的减小而减小,并随着角度差的值的增大而增大。
72.经处理的空间音频信号可以包括ambisonic信号,并且输出空间音频信号可以包括双通道双耳信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且其中,被使得根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的该装置可以被使得:基于所指示的再现定向,生成旋转矩阵;将经处理的空间音频信号的通道与旋转矩阵相乘以得到旋转后的空间音频信号;使用预定义的一组有限脉冲响应(fir)滤波器对来对旋转后的空间音频信号的通道进行滤波,其中,该组fir滤波器对是基于头部相关脉冲响应函数(hrtf)或头部相关脉冲响应(hrir)的数据集而生成的;以及将双耳信号的左通道和右通道生成为针对
左通道和右通道中的相应一个通道而得到的旋转后的空间音频信号的滤波后通道之和。
73.输出空间音频信号可以包括双通道双耳音频信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且被使得根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的该装置可以被使得:在所述一个或多个频率子带中,通过将经处理的空间音频信号的一个或多个音频通道中的相应音频通道的相应频带乘以针对相应频率子带而接收的频谱调整因子,得到一个或多个增强音频通道;以及根据所指示的再现方向,将一个或多个增强音频通道转换成双通道双耳音频信号。
74.输出空间音频信号可以包括双通道双耳音频信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且其中,被使得根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的该装置可以被使得:根据所指示的再现方向,将一个或多个增强音频通道转换成双通道双耳音频信号。
75.输出空间音频信号可以包括双通道双耳信号,其中,再现控制信息可以包括定义关于音频场景的收听方向的再现定向的指示,并且其中,被使得根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的该装置可以被使得:根据所指示的再现方向,选择一组头部相关传递函数(hrtf);以及将经处理的空间音频信号的通道转换成双通道双耳信号,该双通道双耳信号使用所选择的一组hrtf来传送旋转后的音频场景。
76.再现控制信息可以包括第二预定义扬声器配置的指示,并且输出空间音频信号可以包括根据第二预定义扬声器配置的多通道扬声器信号,并且其中,被使得根据再现控制信息来处理表示基于散焦方向的经修改的音频场景的经处理的空间音频信号以生成输出空间音频信号的该装置可以被使得:通过被配置为执行以下操作来基于经处理的空间音频信号的通道并使用幅度平移来得到输出空间音频信号的通道:导出包括幅度平移增益的转换矩阵,并使用转换矩阵来乘以经处理的空间音频信号的通道以得到输出空间音频信号的通道,其中,该幅度平移增益提供从第一预定义扬声器配置到第二预定义扬声器配置的映射。
77.可以进一步使该装置:从包括至少一个方向传感器的传感器装置和至少一个用户输入获得散焦输入,其中,该散焦输入包括基于至少一个方向传感器的方向的散焦方向的指示。
78.散焦输入还可以包括散焦量的指示符。
79.散焦输入还可以包括散焦形状的指示符。
80.散焦形状可以包括以下中的至少一个:散焦形状宽度;散焦形状高度;散焦形状半径;散焦形状距离;散焦形状深度;散焦形状范围;散焦形状直径;以及散焦形状表征器。
81.散焦方向可以是由散焦方向的范围定义的弧。
82.根据第四方面,提供了一种装置,其包括:获得电路,被配置为获得散焦方向;空间音频信号处理电路,被配置为处理表示音频场景的空间音频信号以生成表示基于散焦方向的经修改的音频场景的经处理的空间音频信号,以便在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重;以及输出电
路,被配置为输出经处理的空间音频信号,其中,基于散焦方向的经修改的音频场景在散焦方向上至少部分地使能空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的去加重。
83.根据第五方面,提供了一种包括指令的计算机程序[或包括程序指令的计算机可读介质],这些指令用于使装置至少执行以下操作:获得散焦方向;处理表示音频场景的空间音频信号以生成基于散焦方向的表示经修改的音频场景的经处理的空间音频信号,以便在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重;以及输出经处理的空间音频信号,其中,基于散焦方向的经修改的音频场景在散焦方向上至少部分地使能空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的去加重。
[0084]
根据第六方面,提供了一种非暂时性计算机可读介质,其包括用于使装置至少执行以下操作的程序指令:获得散焦方向;处理表示音频场景的空间音频信号以生成表示基于散焦方向的经修改的音频场景的经处理的空间音频信号,以便在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重;以及输出经处理的空间音频信号,其中,基于散焦方向的经修改的音频场景在散焦方向上至少部分地使能空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的去加重。
[0085]
根据第七方面,提供了一种装置,其包括:用于获得散焦方向的部件;处理表示音频场景的空间音频信号以生成表示基于散焦方向的经修改的音频场景的经处理的空间音频信号,以便在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重的部件;以及用于输出经处理的空间音频信号的部件,其中,基于散焦方向的经修改的音频场景在散焦方向上至少部分地使能空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的去加重。
[0086]
根据第八方面,提供了一种计算机可读介质,其包括用于使装置至少执行以下操作的程序指令:获得散焦方向;处理表示音频场景的空间音频信号以生成表示基于散焦方向的经修改的音频场景的经处理的空间音频信号,以便在散焦方向上至少部分地控制空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的相对去加重;以及输出经处理的空间音频信号,其中,基于散焦方向的经修改的音频场景在散焦方向上至少部分地使能空间音频信号的一部分至少部分地相对于空间音频信号的其他部分的去加重。
[0087]
一种装置,包括用于执行如上所述的方法的动作的部件。
[0088]
一种装置,被配置为执行如上所述的方法的动作。
[0089]
一种计算机程序,包括用于使计算机执行如上所述的方法的程序指令。
[0090]
一种被存储在介质上的计算机程序产品可以使装置执行本文所述的方法。
[0091]
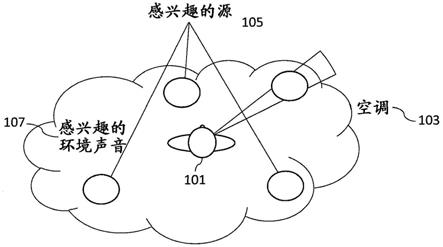
一种电子设备可以包括如本文所述的装置。
[0092]
一种芯片组可以包括如本文所述的装置。
[0093]
本技术的实施例旨在解决与现有技术相关联的问题。
附图说明
[0094]
为了更好地理解本技术,现在将通过示例的方式参考附图,其中:
[0095]
图1a、图1b和图1c示出示出了音频聚焦区或区域的示例声音场景;
[0096]
图2a和图2b示意性地示出根据一些实施例的示例回放装置和用于操作回放装置的方法;
[0097]
图3a和图3b示意性地示出根据一些实施例的具有高阶ambisonic音频信号输入的如图2a中所示的示例聚焦处理器和操作该示例聚焦处理器的方法;
[0098]
图4a和图4b示意性地示出根据一些实施例的具有参数化空间音频信号输入的如图2a中所示的示例聚焦处理器和操作该示例聚焦处理器的方法;
[0099]
图5a和图5b示意性地示出根据一些实施例的具有多通道和/或音频对象音频信号输入的如图2a中所示的示例聚焦处理器和操作该示例聚焦处理器的方法;
[0100]
图6a和图6b示意性地示出根据一些实施例的具有高阶ambisonic音频信号输入的如图2a中所示的示例再现处理器和操作该示例再现处理器的方法;
[0101]
图7a和图7b示意性地示出根据一些实施例的具有参数化空间音频信号输入的如图2a中所示的示例再现处理器和操作该示例再现处理器的方法;
[0102]
图8示出一些实施例的示例实现;
[0103]
图9示出根据一些实施例的用于控制聚焦方向、聚焦量和聚焦宽度的示例控制器;
[0104]
图10示出根据一些实施例的基于处理高阶ambisonic音频信号的示例处理输出;
[0105]
图11示出适于实现所示装置的示例设备。
具体实施方式
[0106]
下面进一步详细地描述了用于提供空间音频信号的有效渲染和回放的合适装置和可能的机制。
[0107]
先前的空间音频信号回放示例允许用户控制聚焦方向和聚焦量(focus amount)。然而,在某些情况下,这种聚焦方向/量的控制可能是不够的。如下文所讨论的概念是其特征在于可以指示在某些方向上消除或去加重声音的进一步的聚焦控制的装置和方法。例如,在声场中可存在许多不同的特征,诸如在某些方向上的多个主导声源以及环境声音。一些用户可能更喜欢去除该声场的某些特征,而其他一些用户可能更喜欢听到完整的音频场景,或者去除该声场的替代特征。特别地,用户可能希望以如下这种方式移除不期望的声音:按最初预期的那样再现空间声音场景的剩余部分。
[0108]
下面描述的图1a至图1c示出了用户预期在收听再现空间音频信号时感知的事物。
[0109]
作为示例,图1a示出了以定义的定向定位的用户101。在音频场景内存在感兴趣的源105,例如,讲话者。此外,可存在在用户周围的其他环境音频内容107。
[0110]
此外,用户可以识别诸如空调103之类的干扰音频源。常规地,用户可以控制回放以聚焦在感兴趣的源105上,以相对于干扰源103加重感兴趣的源。然而,如在实施例中所讨论的概念尝试代替地通过执行所识别的一个或多个源(如在图1a中由散焦或负焦识别源103所指示的)的“移除”(或散焦或负焦(negative-focus))来改进声音质量。
[0111]
作为另一个示例,如图1b中所示,用户可能希望对声音场景内的形状或区内的任何源进行散焦或负焦。因此,例如,图1b示出了在具有感兴趣的源105(例如,讲话者)的音频或声音场景内以定义定向定位的用户101、诸如环境音频内容之类的其他环境音频内容107、以及定义区153内的干扰源155。在这个示例中,散焦或负焦区由散焦弧(defocus arc)
151表示,散焦弧151具有定义的宽度和相对于用户101的方向。具有定义的宽度和相对于用户101的方向的散焦弧151覆盖干扰源区153内的干扰源155。
[0112]
在图1c中示出了可以表示散焦或负焦区的另一方式,其中,散焦区或体积(对于3d区)161覆盖干扰源区153内的干扰源155。在这个示例中,散焦区可以由距离以及方向和“宽度”来定义。
[0113]
因此,如本文所讨论的实施例尝试(除了散焦方向和量之外还)提供散焦形状的控制。如关于本文所描述的实施例而讨论的概念涉及空间音频再现并使能利用控制部件的音频回放,以用于将源自可选空间方向(或区域或体积)的音频元素相对于在这些所确定的散焦形状之外的元素减少/消除/去除所期望的量(例如,0%-100%),以便去加重在所选择的空间方向(或区域或体积)上的音频元素的可听度,同时保持在未选择的空间方向(或区域或体积)上的期望音频元素的可听度,同时还使空间音频信号格式相同。
[0114]
实施例提供与可选择的方向和量对应的至少一个散焦(或负焦)参数。此外,在一些实施例中,该散焦(或负焦)参数可以定义散焦(或负焦)形状,并且可以由与方向、宽度、高度、半径、距离、以及深度对应的以下参数中的任意一个(或两个或更多个的组合)来定义。在一些实施例中,该参数集包括定义任何任意散焦形状的参数。
[0115]
在一些实施例中,至少一个散焦参数与至少一个聚焦参数一起被提供,以便加重进一步选择的空间方向(或者形状、区域或体积)的可听度。
[0116]
在一些实施例中,空间音频信号处理可以通过以下操作来执行:获得与具有多个观看方向的媒体相关联的空间音频信号;获得聚焦/散焦方向和量参数(其可以可选地包括获得至少一个聚焦/散焦形状信息);修改空间音频信号以具有所期望的(聚焦和)散焦特性;以及(用耳机或扬声器)再现经修改的空间音频信号。
[0117]
所获得的空间音频信号例如可以是:ambisonic信号;扬声器信号;参数化空间音频格式,诸如一组音频通道以及相关联的空间元数据。
[0118]
聚焦/散焦信息可以被定义如下:聚焦(focus)是指增大源自可选方向(或形状或区域)的音频的相对突出度,而散焦(de-focus)是指减少源自该方向(或形状或区域)的音频的相对突出度。
[0119]
聚焦/散焦量确定聚焦或散焦的程度。例如,它可以是从0%到100%,其中,0%意味着保持原始声音场景不改变,而100%意味着最大程度地聚焦/散焦到期望方向上或定义区内。
[0120]
在一些实施例中,聚焦/散焦控制可以是确定聚焦还是散焦的切换控制,或者它可以是以其他方式来进行控制,例如,通过将聚焦量在范围从-100%到100%扩展,其中,负值指示散焦(或负焦)效应,正值指示聚焦效应。
[0121]
应当注意,不同的用户可能希望具有不同的聚焦/散焦特性。基于他们的个人偏好,可以针对每个用户单独地修改和再现原始空间音频信号。
[0122]
图2a示出了根据示例的空间音频处理装置250的一些组件和/或实体的框图。将理解,在该附图中示出并且随后进一步详述的两个单独的步骤(聚焦/散焦处理器 再现处理器)可以被实现为集成过程,或者在一些示例中以如本文所描述的相反顺序(其中,再现处理器操作之后是聚焦处理器操作)来实现。空间音频处理装置250包括音频聚焦处理器201,其被配置为接收输入音频信号,此外还接收聚焦/散焦参数202;以及基于输入音频信号200
并根据聚焦/散焦参数202(其可以包括关于聚焦/散焦元素的聚焦/散焦方向;聚焦/散焦量;聚焦/散焦高度;聚焦/散焦半径;聚焦/散焦距离;以及聚焦/散焦深度),得到具有聚焦/散焦声音分量的音频信号204。此外,空间音频处理装置250还可以包括音频再现处理器207,其被配置为接收具有聚焦/散焦声音分量的音频信号204以及再现控制信息206,并且被配置为基于具有聚焦/散焦声音分量的音频信号204并进一步根据再现控制信息206,以预定义的音频格式得到输出音频信号208,其中,再现控制信息206用于控制与在音频再现处理器207中处理具有聚焦/散焦分量的空间音频信号有关的至少一个方面。再现控制信息206可以包括再现定向(或再现方向)的指示和/或适用的扬声器配置的指示。考虑到用于处理上述空间音频信号的方法,音频聚焦处理器201可以被设置为通过修改音频场景来实现处理空间音频信号的方面,以便根据所接收的聚焦/散焦量,在所接收的聚焦区或方向中控制至少空间音频信号的一部分的加重或去加重。音频再现处理器207可以基于所观察的方向和/或位置,输出经处理的空间音频信号作为经修改的音频场景,其中,经修改的音频场景在聚焦区中并根据所接收的聚焦量至少针对空间音频信号的所述部分表现出加重。
[0123]
在图2a的图示中,输入音频信号、具有聚焦/散焦声音分量的音频信号以及输出音频信号中的每一个被提供为采用预定义的空间音频格式的相应的空间音频信号。因此,这些信号可以分别被称为输入空间音频信号、具有聚焦/散焦声音分量的空间音频信号、以及输出空间音频信号。沿着前文中所描述的思路,通常,空间音频信号传送涉及在音频场景的各具体位置处的一个或多个定向声源以及音频场景的环境两者的音频场景。然而,在一些情况下,空间音频场景可以涉及没有环境的一个或多个定向声源或者没有任何定向声源的环境。就此而言,空间音频信号包括传送一个或多个定向声音分量和/或环境声音分量的信息,其中,该一个或多个定向声音分量表示在音频场景内具有某一位置的不同声源(例如,相对于收听点的某一到达方向和某一相对强度),该环境声音分量表示在音频场景内的环境声音。应当注意,将音频场景划分成定向声音分量和环境分量通常只是一种表示或近似,而实际的声音场景可涉及诸如宽源和相干声反射之类的更复杂的特征。尽管如此,即使具有如此复杂的声学特征,至少在感知意义上将音频场景概念化为定向分量和环境分量(direct and ambient components)的组合通常是一种合理的表示或近似。
[0124]
通常,输入音频信号和具有聚焦/散焦声音分量的音频信号以相同的预定义空间格式来提供,而输出音频信号可以以与被应用于输入音频信号(和具有聚焦/散焦声音分量的音频信号)相同的空间格式来提供,或者可以对输出音频信号使用不同的预定义空间格式。输出音频信号的空间音频格式是鉴于被应用于回放输出音频信号的声音再现硬件的特性而选择的。通常,可以以第一预定空间音频格式提供输入音频信号,并且可以以第二预定空间音频格式提供输出音频信号。适合用作第一和/或第二空间音频格式的空间音频格式的非限制性示例包括ambisonics、根据预定义扬声器配置的环绕扬声器信号、预定义的参数化空间音频格式。在空间音频处理装置250的框架中使用这些空间音频格式作为第一和/或第二空间音频格式的更详细的非限制性示例随后在本公开中提供。
[0125]
空间音频处理装置250通常被应用于将输入空间音频信号200作为输入帧序列处理成相应的输出帧序列,每个输入(输出)帧包括用于输入(输出)空间音频信号的每个通道的相应的数字音频信号段,以预定义的采样频率被提供为相应的在时间上的一系列输入(输出)样本。在一些实施例中,空间音频处理装置250的输入信号可以具有编码形式,例如,
aac或aac 嵌入式元数据。在这种实施例中,编码的音频输入最初可以具有解码器。类似地,在一些实施例中,可以以任何合适的方式对来自空间音频处理装置250的输出进行编码。
[0126]
在典型的示例中,空间音频处理装置250使用固定的预定义帧长度以使得每个帧包括用于输入空间音频信号的每个通道的相应的l个样本,该固定的预定义帧长度在预定义的采样频率映射到对应的时长。作为这方面的示例,固定帧长度可以是20毫秒(ms),其在8、16、32或48khz的采样频率下分别导致每通道l=160、l=320、l=640和l=960个样本的帧。这些帧可以是非重叠的,或者它们可以部分重叠,取决于处理器是否应用滤波器组以及如何配置这些滤波器组。然而,这些值用作非限制性示例并且可以代替地使用与这些示例不同的帧长度和/或采样频率,取决于例如期望音频带宽、期望成帧延迟和/或可用处理能力。
[0127]
在空间音频处理装置250中,聚焦/散焦是指用户可选择的方向/量参数(或感兴趣的空间区)。聚焦/散焦通常例如可以是音频场景的某一方向、距离、半径、弧。在另一个示例中,聚焦/散焦区是在其中当前定位感兴趣的(定向)声源的区。在前一种情况下,用户可选择的聚焦/散焦可以标示保持不变或不经常改变的区,因为聚焦主要是在特定方向上(或空间区中),而在后一种情况下,用户选择的聚焦/散焦可以更频繁地改变,因为聚焦/散焦被设置到某一声源,该声源可以(或可以不)随时间改变其在音频场景中的位置(或形状/大小)。在示例中,聚焦/散焦例如可以被定义为定义方向的方位角。
[0128]
可以例如根据由在图2b中描绘的流程图所示的方法260来提供在前文中参考空间音频处理装置250的组件描述的功能。方法260例如可以由被设置为实现在本公开中经由多个示例描述的空间音频处理系统250的装置来提供。方法260用作一种用于将表示音频场景的输入空间音频信号处理成表示经修改的音频场景的输出空间音频信号的方法。方法260包括接收聚焦/散焦方向的指示和聚焦/散焦强度或量的指示,如框261中所示。方法260还包括将输入空间音频信号处理成表示经修改的音频场景的中间空间音频信号,其中,根据所述聚焦/散焦强度来修改从所述聚焦/散焦方向到达的声音的相对级别,如框263中所示。方法260还包括接收再现控制信息,该再现控制信息控制将中间空间信号处理成输出空间音频信号,如框265中所示。再现控制信息例如可以定义用于输出空间音频信号的再现定向(例如,收听方向或观看方向)或扬声器配置中的至少一个。方法260还包括根据所述再现控制信息,将中间空间音频信号处理成输出空间音频信号,如框267中所示。
[0129]
方法260可以以多种方式改变,例如,根据与在上文和下文中提供的空间音频处理装置250的组件的相应功能有关的示例。
[0130]
在以下示例中更详细地描述了一种散焦操作,然而,应当理解,相同的操作可以被应用于其他聚焦操作以及其他散焦操作。
[0131]
在一些实施例中,空间音频处理装置250的输入是ambisonic信号。该装置可以被配置为接收(并且该方法可以被应用于)任何阶的ambisonic信号。ambisonic音频信号可以是由全向信号和沿y、z、x坐标轴的三个正交一阶模式组成的一阶ambisonic(foa)信号。在本文选择y、z、x坐标顺序是因为它与ambisonic信号的典型acn(ambisonics通道编号)通道排序的一阶系数的顺序相同。
[0132]
注意,ambisonics音频格式可以按照空间波束模式来表达空间音频信号,并且本领域技术人员会直接获得下文中的示例并设计替代的多组空间波束模式来表达空间音频。
此外,ambisonics音频格式是一种特别相关的音频格式,因为它是在360度视频的上下文中表达空间音频的典型方式。ambisonic音频信号的典型源包括麦克风阵列和vr视频流服务(诸如youtube 360)中的内容。
[0133]
关于图3a,示出了在ambisonic输入和输出的上下文中的聚焦处理器350。该附图假定一阶ambisonics(foa)信号(4个通道),然而,可以应用更高阶的ambisonics(hoa)来代替foa。在实现hoa输入格式的实施例中,代替4个通道的通道数量例如可以是9个通道(二阶ambisonics)或16个通道(三阶ambisonics)。
[0134]
示例的ambisonic信号x
foa
(t)300以及(散)聚焦方向304、(散)聚焦量和(散)聚焦控制310是聚焦处理器350的输入。
[0135]
在一些实施例中,聚焦处理器350包括滤波器组301。在一些实施例中,滤波器组301被配置为转换ambisonic(foa)信号300(对应于ambisonic或球面谐波模式)以生成时域输入音频信号的时频域版本。在一些实施例中,滤波器组301可以是短时傅立叶变换(stft)或用于空间声音处理的任何其他合适的滤波器组,诸如复调制正交镜像滤波器(qmf)组。滤波器组301的输出是频带中的时频域ambisonic音频信号302。频带可以是所应用的滤波器组301的一个或多个频率区间(frequency bin)(单独的频率分量)。频带可以近似计算感知相关的分辨率,诸如bark频带,其在低频比在高频时在频谱上更具选择性。可替代地,在一些实现中,频带可以与频率区间相对应。
[0136]
(非聚焦的)时频域ambisonic音频信号302被输出到单声道聚焦器303和混合器311。
[0137]
聚焦处理器301还可以包括单声道聚焦器303。单声道聚焦器303被配置为从滤波器组301接收变换后的(非聚焦的)时频域ambisonic信号302,此外还接收(散)聚焦方向参数304.
[0138]
单声道(散)聚焦器303可以实现任何已知的方法以基于foa输入来生成单声道聚焦音频输出。在这个示例中,单声道聚焦器303实现最小方差无失真响应(mvdr)单声道聚焦音频输出。mvdr波束成形操作尝试从期望聚焦方向获得目标信号而没有失真,同时在此约束下找到尝试最小化输出能量(换句话说,抑制干扰能量)的自适应波束成形权重。
[0139]
在一些实施例中,单声道聚焦器303被配置为通过下式来将频带信号(例如,在foa情况下的四个通道)组合成一个波束成形信号:
[0140]
y(b,n)=wh(k,n)x(b,n)
[0141]
其中,k是频带索引,b是频率区间索引(其中,b被包括在频带k中),n是时间索引,y(b,n)是区间b的一通道波束形成信号,w(k,n)是4x1波束成形权重向量,x(b,n)是具有四个频率区间b信号通道的4x1 foa信号向量。在这个表达式中,相同的波束成形权重w(k,n)被应用于区间b被包括在频带k中的信号x(b,n)。
[0142]
实现mvdr波束形成器的单声道聚焦器303可以针对每个频带k,使用:
[0143]-在频带k在区间内的信号x(b,n)的协方差矩阵的估计(并且可能地具有在若干时间索引n上的时间平均)以及
[0144]-根据聚焦方向的转向向量(steering vector)。在foa信号的示例中,可以基于指向聚焦方向的单位向量来生成转向向量。例如,用于foa的转向向量可以是其中,v
(n)是指向聚焦方向的单位向量(在坐标排序y、z、x中)。
[0145]
基于协方差矩阵估计和转向向量,可以使用已知的mvdr公式来生成权重w(k,n)。
[0146]
因此,在一些实施例中,单声道聚焦器303可以提供单个通道聚焦输出信号306,其被提供给ambisonics平移器305。
[0147]
在一些实施例中,ambisonics平移器305被配置为接收通道(散)聚焦输出信号306和(散)聚焦方向304,并生成ambisonic信号,其中,单声道聚焦信号被定位在聚焦方向上。由ambisonics平移器305生成的聚焦时频ambisonic信号308输出可以是基于下式而生成的:
[0148][0149]
在一些实施例中,(散)聚焦时频ambisonic信号y
foa
(b,n)308进而可以被输出到混合器311。
[0150]
在一些实施例中,诸如mvdr之类的波束形成器的输出可以与后置滤波器级联。后置滤波通常是在频带中自适应地修改波束形成器输出的增益或能量的过程。例如,已知虽然mvdr在抑制单独的强干扰声源方面是有效的,但它在诸如具有交通噪音的户外录音之类的环境声学场景方面表现不佳。这是因为mvdr有效地旨在将波束模式最小值导向干扰所在的那些方向。当干扰声音如交通噪声那样在空间上扩散时,mvdr并不能那么有效地抑制这些干扰。
[0151]
因此,在一些实施例中,可以实现后置滤波器以估计在聚焦方向上在频带中的声能。进而,在相同频带处测量波束形成器输出能量,并且在频带中应用增益以校正声谱来改进所估计的目标频谱。在这种实施例中,后置滤波器可以进一步抑制干扰声音。
[0152]
在delikaris-manias、symeon和ville,pulkki的“使用麦克风阵列的空间滤波应用的交叉模式相干算法(cross pattern coherence algorithm for spatial filtering applications utilizing microphone arrays)”(ieee期刊,关于音频、语音和语言处理,第21卷,第11期(2013年):第2356-2367页)中描述了后置过滤器的示例,其中,使用一阶球面谐波信号与二阶球面谐波信号之间的交叉谱能量估计来估计在观看方向上的目标能量。还可以针对诸如在零(全向)阶球面谐波信号与一(偶极子)阶球面谐波信号之间的其他模式获得交叉谱估计。交叉谱估计提供了针对目标方向的能量估计。
[0153]
当实现后置滤波时,波束成形等式可以附加有增益g(k,n):
[0154]y′
(b,n)=g(k,n)wh(k,n)x(b,n)
[0155]
增益g(k,n)可以如下地使用交叉谱能量估计方法来导出。首先,公式化在全向foa信号分量与具有朝向聚焦方向的正瓣的8字形信号(figure-of-eight signal)之间的互相关:
[0156][0157]
其中,具有子索引(w、y、z、x)的信号x标示四个foa信号x(b,n)的信号分量,星号(*)标示复共轭,e标示可以被实现为在期望时间区域上的平均算子的期望算子。频带k的实值的、非负互相关度量进而由下式公式化:
[0158][0159]
实际上,值c(k,n)是在频带k从聚焦方向到达的声音的能量估计。进而,估计波束形成输出y(b,n)=wh(k,n)x(b,n)的频带k内的区间的能量d(k,n):
[0160][0161]
进而,可以获得空间滤波器增益为:
[0162][0163]
换句话说,当能量估计值c(k,n)小于波束输出能量d(k,n)时,空间滤波器进而会减少在频带k的波束输出能量。因此,空间滤波器的功能是进一步调整波束形成器输出的频谱,使其更接近从聚焦方向到达的声音的频谱。
[0164]
在一些实施例中,(散)聚焦处理器可以使用这种后置滤波。单声道聚焦器303的波束成形输出y(b,n)可以在频带中用后置滤波增益进行处理,以生成后置滤波的波束成形输出y
′
(b,n),其中,y
′
(b,n)代替y(b,n)而被应用。可理解除了如上述示例所描述的那些之外,还存在可以应用的各种合适的波束形成器和后置滤波器。
[0165]
在一些实施例中,聚焦处理器350包括混合器311。该混合器被配置为接收(散)聚焦时频ambisonics信号y
foa
(b,n)308和非聚焦的时频ambisonics信号x(b,n)302(具有潜在的延迟调整,其中,mvdr估计和处理涉及前断处理)。此外,混合器311还接收(散)聚焦量和焦/散焦控制参数310。
[0166]
在这个示例中,(散)聚焦控制参数是“聚焦”或“散焦”的二进制开关。(散)聚焦量参数a(n)被表达为在0..1之间的因子,其中,1是最大聚焦,被用于描述聚焦量或散焦量,具体取决于所使用的模式。
[0167]
在一些实施例中,当散焦参数处于“聚焦”模式中时,混合器311的输出是:
[0168]ymix
(b,n)=a(n)y
foa
(b,n) (1-a(n))x(b,n)
[0169]
在一些实施例中,上述公式中的值y
foa
(k,n)在混合之前通过因子(例如,常数4)进行修改以进一步加重(散)聚焦效应。
[0170]
在一些实施例中,当散焦参数处于“散焦”模式中时,混合器可以被配置为执行:
[0171]ymix
(b,n)=x(b,n)-a(n)y
foa
(b,n)
[0172]
换句话说,当a(n)是0时,散焦处理也处于零,然而,当a(n)更大或达到1时,混合过程从空间foa信号x(b,n)中减去信号y
foa
(b,n),y
foa
(b,n)是空间化聚焦信号。由于相减,来自聚焦方向的信号分量的幅度被减少。换句话说,发生散焦处理,并且所得到的ambisonics空间音频信号对于来自聚焦方向的声音具有减少的幅度。在一些配置中,y
mix
(b,n)312可以基于作为a(n)的函数的规则而被放大,以解释由于散焦处理而导致的响度的平均损失。
[0173]
混合器311的输出即混合的时频ambisonics音频信号312被传递给逆滤波器组313。
[0174]
在一些实施例中,聚焦处理器350包括逆滤波器组313,其被配置为接收混合的时频ambisonics音频信号312,并将该音频信号变换到时域。逆滤波器组313利用所添加的聚
焦/散焦生成合适的脉冲编码调制(pcm)ambisonics音频信号。
[0175]
关于图3b,示出了如图3a中所示的foa聚焦处理器的操作360的流程图。
[0176]
如图3b中步骤361所示,初始操作是接收ambisonics(foa)音频信号(以及聚焦/散焦参数,诸如方向、宽度、量或其他控制信息)。
[0177]
如图3b中步骤363所示,下一操作是将变换后的ambisonics音频信号生成到时频域中。
[0178]
如图3b中步骤365所示,在已生成时频域ambisonics音频信号之后,下一操作是基于聚焦方向(例如,使用波束成形),从时频域ambisonics音频信号中生成单声道聚焦ambisonics音频信号。
[0179]
进而,如图3b中步骤367所示,基于聚焦方向,对单声道(散)聚焦ambisonics音频信号执行ambisonics平移。
[0180]
进而,如图3b中步骤369所示,基于(散)聚焦量和(散)聚焦控制参数,将平移后的ambisonic音频信号((散)聚焦时频ambisonic信号)与非聚焦的时频ambisonic信号相混合。
[0181]
如图3b中步骤371所示,可以对混合的ambisonic音频信号进行逆变换。
[0182]
进而,如图3b中步骤373所示,输出时域ambisonic音频信号。
[0183]
关于图4a,示出了聚焦处理器,其被配置为接收参数化空间音频信号作为输入。参数化空间音频信号包括音频信号和空间元数据,诸如频带中的方向和定向与总能量比(direct-to-total energy ratio)。参数化空间音频信号的结构和生成是已知的,并且已经从麦克风阵列(例如,移动电话、vr相机)描述了其生成。此外,也可以从扬声器信号和ambisonic信号生成参数化空间音频信号。在一些实施例中,参数化空间音频信号可以从ivas(沉浸式语音和音频服务)音频流生成,其可以被解码和解复用为空间元数据和音频通道的形式。这种参数化空间音频流中的音频通道的典型数量是两个音频通道音频信号,然而,在一些实施例中,音频通道的数量可以是任意数量的音频通道。
[0184]
在一些示例中,参数化信息包括深度/距离信息,其可以在6自由度(6dof)再现中被实现。在6dof中,距离元数据(连同其他元数据)被用于确定声音的能量和方向应如何根据用户移动发生变化。
[0185]
在这个示例中,每个空间元数据方向参数与定向与总能量比和距离参数两者相关联。在参数化空间音频捕获的上下文中的距离参数的估计已在诸如gb专利申请gb1710093.4和gb1710085.0之类的较早申请中详述,但出于明确的原因未进一步探讨。
[0186]
被配置为接收参数化空间音频400的聚焦处理器450被配置为使用(散)聚焦参数以确定参数化空间音频信号的定向分量和环境分量应被衰减或加重多少以使能(散)聚焦效应。在下面以两种配置来描述聚焦处理器450。第一种使用(散)聚焦参数:方向和量,进一步包括导致聚焦/散焦弧的宽度。在这个配置中,6dof距离参数是可选的。第二种使用参数(散)聚焦方向和量和距离和半径,其导致在某一位置处的聚焦/散焦球体。在这个配置中,需要6dof距离参数。这些配置的差异在以下描述中仅在必需时才进行表述。
[0187]
在以下示例中,方法(和公式)在没有随时间发生变化的情况下被表述,但应当理解,所有参数可以随时间发生变化。
[0188]
在一些实施例中,聚焦处理器包括比率修改器和频谱调整因子确定器401,其被配
置为接收聚焦参数408,另外还接收由频带中的方向402(以及在一些实施例中,距离422)和定向与总能量比404组成的空间元数据。
[0189]
比率修改器和频谱调整因子确定器401被配置为接收聚焦参数,另外还接收由频带中的方向402、定向与总能量比404(以及在一些实施例中,距离422)组成的空间元数据。
[0190]
除非另有说明,否则以下描述考虑了聚焦参数包括方向、宽度和量的情况。在一些实施例中,比率修改器和频谱调整因子确定器401被配置为确定聚焦方向(对于所有频带k是一个)与空间元数据方向(在不同的频带k可能不同)之间的角度差β(k)。在一些实施例中,vm(k)被确定为指向在频带k的空间元数据的方向参数的列单位向量,并且vf被确定为指向聚焦方向的列单位向量。角度距离β(k)可以被确定为:
[0191][0192]
其中,是vm(k)的转置。
[0193]
进而,比率修改器和频谱调整因子确定器401被配置为确定定向增益(direct-gain)参数f(k)。聚焦量参数a可以被表达为在0..1(其中,0意味着零聚焦/散焦,1意味着最大聚焦/散焦)之间的归一化值、以及聚焦宽度(focus-width)β0,其例如可以是在某一时间实例20度。
[0194]
当比率修改器和频谱调整因子确定器401被配置为执行聚焦(与散焦相反)时,示例增益公式是:
[0195][0196]
其中,c是用于聚焦的增益常数,例如,4。当比率修改器和频谱调整因子确定器401被配置为执行散焦时,示例公式是:
[0197][0198]
在一些实施例中,常数c在散焦的情况下可以具有与在聚焦的情况下不同的值。此外,在实践中,可能需要平滑上述函数,以使得聚焦增益函数从在聚焦区域的高值平滑地过渡到在非聚焦区域的低值。
[0199]
除非另有说明,否则以下描述考虑了聚焦参数包括方向、距离、半径和量的情况。在一些实施例中,比率修改器和频谱调整因子确定器401被配置为确定聚焦位置pf和元数据位置pm(k),被公式化如下。在一些实施例中,vm(k)被确定为指向在频带k的空间元数据的方向参数的列单位向量,vf被确定为指向聚焦方向的列单位向量。聚焦位置被公式化为pf=vfdf,其中,df是聚焦距离。空间元数据位置被公式化为pm(k)=vm(k)dm(k),其中,dm(k)是在频带k的空间元数据的距离参数。在一些实施例中,比率修改器和频谱调整因子确定器401被配置为确定聚焦位置pf(对于所有频带k是一个)与空间元数据位置pm(k)(在不同的频带k可能不同)之间的位置差γ(k)。位置差γ(k)可以被确定为:
[0200]
γ(k)=|p
f-pm(k),|
[0201]
其中,|.|算子是用于确定向量的距离。
[0202]
进而,比率修改器和频谱调整因子确定器401被配置为确定定向增益参数f(k)。聚焦量参数a可以被表达为在0..1之间的归一化值(其中,0意味着零聚焦/散焦,1意味着最大
聚焦/散焦),并且聚焦半径被标示为γ0,其例如可以是在某一时间实例1米。
[0203]
当比率修改器和频谱调整因子确定器401被配置为执行聚焦(与散焦相反)时,示例增益公式是:
[0204][0205]
其中,c是用于聚焦的增益常数,例如,4。当比率修改器和频谱调整因子确定器401被配置为执行散焦时,示例公式是:
[0206][0207]
在一些实施例中,常数c在散焦的情况下可以具有与在聚焦的情况下不同的值。此外,在实践中,可能需要平滑上述函数,以使得聚焦增益函数从在聚焦区域的高值平滑地过渡到在非聚焦区域的低值。
[0208]
其余描述适用于以上所描述的这两种聚焦参数配置。在一些实施例中,比率修改器和频谱调整因子确定器401进一步被配置为将参数化空间音频信号的新的定向部分(direct portion)值d(k)确定为:
[0209]
d(k)=r(k)*f(k)
[0210]
其中,r(k)是在频带k的定向与总能量比值。
[0211]
在一些实施例中,比率修改器和频谱调整因子确定器401被配置为将新的环境部分(ambient portion)值a(k)(在聚焦处理中)确定为:
[0212]
a(k)=(1-r(k))*(1-a)
[0213]
在一些实施例中,比率修改器和频谱调整因子确定器401被配置为在散焦处理中使用a(k)=(1-r(k))来确定新的环境分量,这意味着散焦处理没有影响空间周围环境能量。
[0214]
进而,比率修改器和频谱调整因子确定器401被配置为确定被输出到频谱调整处理器403的频谱校正因子s(k),频谱校正因子s(k)进而基于声能的整体修改而被公式化。例如:
[0215][0216]
在一些实施例中,比率修改器和频谱调整因子确定器401被配置为基于下式来确定新的经修改的定向与总能量比参数r
′
(k)以代替r(k):
[0217][0218]
在数值不确定的情况下,d(k)=a(k)=0,进而r
′
(k)也可以被设置为零。
[0219]
在一些实施例中,空间元数据中的方向值402(和距离值422)可以未经修改地被传递和输出。
[0220]
在一些实施例中,聚焦处理器包括频谱调整处理器403。频谱调整处理器403被配置为接收音频信号(其在一些实施例中是采用时频表示,或者可替代地它们首先被变换到时频域)406和频谱调整因子412。在一些实施例中,输出音频信号414也可以是在时频域中,或者在被输出之前被逆变换到时域。输入和输出的域可以取决于实现。
[0221]
频谱调整处理器403被配置为针对每个频带k,将在频带k内的所有通道的(时频变换的)频率区间乘以频谱调整因子s(k)。换句话说,频谱调整处理器403被配置为执行频谱
调整。相乘/频谱校正可以随时间进行平滑以避免处理伪影。
[0222]
换句话说,聚焦处理器450被配置为修改音频信号的频谱以及空间元数据,以使得该过程产生已根据(散)聚焦参数而被修改的参数化空间音频信号。
[0223]
关于图4b,示出了如图4a中所示的参数化空间音频输入处理器的操作的流程图460。
[0224]
如图4b中步骤461所示,初始操作是接收参数化空间音频信号(以及聚焦/散焦参数或其他控制信息)。
[0225]
如图4b中步骤463所示,下一操作是修改参数化元数据,并生成频谱调整因子。
[0226]
如图4b中步骤465所示,下一操作是对音频信号进行频谱调整。
[0227]
进而,如图4b中步骤467所示,可以输出频谱调整后的音频信号和经修改的(以及未经修改的)元数据。
[0228]
关于图5a,示出了被配置为接收多通道或对象音频信号作为输入500的聚焦处理器550。在这种示例中,该聚焦处理器可以包括聚焦增益确定器501。聚焦增益确定器501被配置为接收聚焦/散焦参数508和通道/对象位置/定向信息,其可以是静态的或时变的。聚焦增益确定器501被配置为基于(散)聚焦参数508(诸如(散)聚焦方向、(散)聚焦量、(散)聚焦控制以及可选的(散)聚焦距离和半径或(散)聚焦宽度)和来自输入信号500的空间元数据信息502,生成定向增益f(k)参数512。在一些实施例中,通道信号方向被信令传送,并且在一些实施例中,它们被假定。例如,当存在6个通道时,方向可以被假定为5.1音频通道方向。在一些实施例中,可以存在查找表,其被用于根据通道数量来确定通道方向。
[0229]
在一些实施例中没有滤波器组,换句话说,只存在一个频带k。用于每个音频通道的定向增益f(k)作为聚焦增益被输出到聚焦增益处理器503。
[0230]
在一些实施例中,聚焦增益处理器503被配置为接收音频信号和聚焦增益值512,并基于聚焦增益值512(每通道)来处理音频信号506,潜在地具有一些在时间上的平滑。在一些实施例中,基于聚焦增益值512的处理可以是将通道/对象信号与聚焦增益值相乘。
[0231]
聚焦增益处理器503的输出是经聚焦处理的音频通道。通道定向/位置信息没有被改变,并且也作为输出510被提供。
[0232]
在一些实施例中,散焦处理可以被配置为比针对一个方向更宽广。例如,可以包括聚焦宽度β0作为输入参数。在这些实施例中,用户还可以生成散焦弧。在另一个示例中,可以包括聚焦距离df和聚焦半径γ0作为输入参数。在这些实施例中,用户可以在所确定的位置处生成散焦球体。针对其他输入空间音频信号类型也可以采用类似的过程。
[0233]
在一些实施例中,音频对象(空间元数据)可以包括也可以被纳入考虑的距离参数。例如,聚焦/散焦参数可以确定聚焦位置(方向和距离)、以及控制在该位置周围的聚焦/散焦区域的半径参数。在这种实施例中,用户可以生成诸如图1c中所示且在先前描述的散焦模式。类似地,可以定义其他空间相关参数以允许用户控制散焦区域的不同形状。在一些实施例中,在散焦区域内的音频对象的衰减可以是固定分贝数(例如,10db)乘以在0与1之间的期望散焦量的衰减,并且留下在散焦方向之外的音频对象而没有进行增益修改(或者不对在散焦方向之外的音频对象应用与聚焦操作相关的增益或衰减)。在定向增益f(k)(将作为聚焦增益被输出)的公式化中,聚焦增益确定器501可以使用与在图4a中的比率修改器和频谱调整因子确定器401的上下文中描述的相同的公式来确定定向增益f(k)。例外情况
是在音频对象/通道的情况下通常只存在一个频带,并且空间元数据通常仅指示对象方向/距离,而不是比率。当距离不可用时,则可以假定固定距离,例如,2米。
[0234]
关于图5b,示出了如图5a中所示的多通道/对象音频输入处理器的操作的流程图560。
[0235]
如图5b中步骤561所示,初始操作是接收多通道/对象音频信号,并且在一些实施例中还接收通道信息,诸如通道数量和/或通道的分布(以及聚焦/散焦参数或其他控制信息)。
[0236]
如图5b中步骤563所示,下一操作是生成聚焦增益因子。
[0237]
如图5b中步骤565所示,下一操作是针对每个通道音频信号应用聚焦增益。
[0238]
进而,如图5b中步骤567所示,可以输出处理音频信号和未经修改的通道方向(和距离)。
[0239]
关于图6a,示出了基于ambisonic音频输入的再现处理器650的示例(例如,其可以被配置为接收来自如图3a中所示的示例聚焦处理器的输出)。
[0240]
在这些示例中,该再现处理器可以包括ambisonic旋转矩阵处理器601。ambisonic旋转矩阵处理器601被配置为接收经聚焦/散焦处理的ambisonic信号600以及观看方向602。ambisonic旋转矩阵处理器601被配置为基于观看方向参数602,生成旋转矩阵。在一些实施例中,这可以使用任何合适的方法,诸如被应用于头部跟踪的ambisonic双耳化的那些方法(或者更一般地,这种球面谐波函数的旋转在包括除了音频之外的其他领域的许多领域中被使用)。进而,该旋转矩阵被应用于ambisonic音频信号。其结果是得到具有所添加的聚焦/散焦604的旋转ambisonic信号,这些旋转ambisonic信号被输出到ambisonic到双耳滤波器603。
[0241]
ambisonic到双耳滤波器603被配置为接收具有所添加的聚焦/散焦604的旋转ambisonic信号。ambisonic到双耳滤波器603可以包括预先制定的2xk有限脉冲响应(fir)滤波器矩阵,这些fir滤波器被应用于k个ambisonic信号以生成2个双耳信号606。在这个其中示出4个通道foa音频信号的示例中,k=4。可以通过关于一组头部相关脉冲响应(hrir)的最小二乘优化方法来生成fir滤波器。这种设计过程的示例是将hrir数据集变换为频率区间(例如,通过fft)以获得hrtf数据集,并针对每个频率区间确定一个复值处理矩阵,该复值处理矩阵在最小二乘意义上在hrtf数据集的数据点处近似可用hrtf数据集。当以这种方式针对所有频率区间确定复值矩阵时,其结果可以被逆变换(例如,通过逆fft)为时域fir滤波器。fir滤波器还可以例如通过使用hann窗口而被窗口化。
[0242]
在一些实施例中,渲染不是针对耳机而是针对扬声器。存在许多已知的方法可以被用于将ambisonic信号渲染为扬声器输出。一个示例可以是将ambisonic信号线性解码到目标扬声器配置。当ambisonic信号的阶数足够高(例如,至少3阶,但优选地4阶)时,这可以以良好的预期空间保真度而被应用。在这种线性解码的特定示例中,ambisonic解码矩阵可以被设计为当被应用于ambisonic信号(对应于ambisonic波束模式)时,生成与在最小二乘意义上近似适合于目标扬声器配置的向量基幅度平移(vbap)波束模式的波束模式对应的扬声器信号。用这种所设计的ambisonic解码矩阵处理ambisonic信号可以被配置为生成扬声器声音输出。在这种实施例中,再现处理器被配置为接收关于扬声器配置的信息,并且不需要旋转处理。
[0243]
关于图6b,示出了如图6a中所示的ambisonic输入再现处理器的操作的流程图660。
[0244]
如图6b中步骤661所示,初始操作是接收经聚焦/散焦处理的ambisonic音频信号(以及观看方向)。
[0245]
如图6b中步骤663所示,下一操作是基于观看方向,生成旋转矩阵。
[0246]
如图6b中步骤665所示,下一操作是将旋转矩阵应用于ambisonic音频信号,以生成旋转的聚焦/散焦处理的ambisonic音频信号。
[0247]
进而,如图6b中步骤667所示,下一操作是将ambisonic音频信号转换成合适的音频输出格式,例如,双耳格式(或者多通道音频格式或扬声器格式)。
[0248]
进而,如图6b中步骤669所示,输出音频格式被输出。
[0249]
关于图7a,示出了基于参数化空间音频输入的再现处理器750的示例(例如,其可以被配置为接收来自如图4a中所示的示例聚焦处理器输出)。
[0250]
在一些实施例中,该再现处理器包括滤波器组701,其被配置为接收音频通道700音频信号,并将这些音频通道变换到频带(除非输入已经在合适的时频域中)。合适的滤波器组的示例包括短时傅立叶变换(stft)和复正交镜像滤波器(qmf)组。时频音频信号702可以被输出到参数化双耳合成器703。
[0251]
在一些实施例中,该再现处理器包括参数化双耳合成器703,其被配置为接收时频音频信号702和经修改的(以及未经修改的)元数据704,此外还接收观看方向706(或者合适的再现相关控制或跟踪信息)。在6dof再现的上下文中,用户位置可以与观看方向参数一起被提供。
[0252]
参数化双耳合成器703可以被配置为实现任何合适的已知的参数化空间合成方法,该方法被配置为生成双耳音频信号(频带中)708,因为在参数化双耳化块之前已经对信号和元数据进行了聚焦修改。一种已知的用于参数化双耳合成的方法是基于频带中的定向与总能量比参数,将时频音频信号702划分成频带中的定向和环境部分信号,用与频带中的方向参数对应的hrtf处理频带中的定向部分,用解相关器处理环境部分以获得双耳扩散场相干,以及组合经处理的定向和环境部分。双耳音频信号(频带中)708进而具有两个通道,而不管时频音频信号702具有多少个通道。进而,双耳化时频音频信号708可以被传递给逆滤波器组705。实施例的特征进一步在于包括逆滤波器组705的该再现处理器被配置为接收双耳化时频音频信号708,并针对所应用的前向滤波器组应用逆滤波,因此生成具有适合于由耳机(在图7a中未示出)再现的聚焦特性的时域双耳化音频信号710。
[0253]
在一些实施例中,使用合适的扬声器合成方法来用来自参数化空间音频信号的扬声器通道音频信号输出格式来代替双耳音频信号输出。可以使用任何合适的方法,例如,基于合适的已知方法,用扬声器的位置的信息来代替观看方向参数,并且用参数化扬声器合成器来代替参数化双耳合成器703。一种已知的用于参数化扬声器合成的方法是基于频带中的定向与总能量比参数,将时频音频信号702划分成频带中的定向和环境部分信号,用与频带中的扬声器配置和方向参数对应的向量基幅度平移(vbap)增益处理频带中的直接部分,用解相关器处理环境部分以获得非相干扬声器信号,以及组合经处理的定向和环境部分。扬声器音频信号(频带中)进而具有由扬声器配置确定的通道数量,而不管时频音频信号702具有多少个通道。
[0254]
关于图7b,示出了如图7a中所示的参数化空间音频输入再现处理器的操作的流程图760。
[0255]
如图7b中步骤761所示,初始操作是接收经聚焦/散焦处理的参数化空间音频信号(以及观看方向或其他再现相关控制或跟踪信息)。
[0256]
如图7b中步骤763所示,下一操作是对音频信号进行时频转换。
[0257]
如图7b中步骤765所示,下一操作是基于时频转换后的音频信号、元数据以及观看方向(或其他信息),应用参数化双耳(或扬声器通道格式)处理器。
[0258]
进而,如图7b中步骤767所示,下一操作是对所生成的双耳或扬声器通道音频信号进行逆变换。
[0259]
进而,如图7b中步骤769所示,输出音频格式被输出。
[0260]
考虑到当音频信号采用多通道音频的形式并应用图5a中的聚焦处理器550时用于再现处理器的扬声器输出,那么在一些实施例中再现处理器可以包括直通(pass-through),其中,输出扬声器配置与输入信号的格式相同。在输出扬声器配置与输入扬声器配置不同的一些实施例中,再现处理器可以包括向量基幅度平移(vbap)处理器。进而,可以使用vbap(一种已知的幅度平移技术)来处理每一个经聚焦处理的音频通道,以使用目标扬声器配置在空间上再现它们。因此,输出音频信号与输出扬声器设置相匹配。
[0261]
在一些实施例中,可以使用任何合适的幅度平移技术来实现从第一扬声器配置到第二扬声器配置的转换。例如,幅度平移技术可以包括导出幅度平移增益的n
×
m矩阵,其定义了从第一扬声器配置的m个通道到第二扬声器配置的n个通道的转换,进而使用该矩阵,以使其与根据第一扬声器配置而被提供为多通道扬声器信号的中间空间音频信号的通道相乘。中间空间音频信号可以被理解为与具有如图2a中所示的聚焦/散焦声音分量204类似的音频信号。作为非限制性示例,vbap幅度平移增益的导出在pulkki,ville的“使用向量基幅度平移的虚拟声源定位(virtual sound source positioning using vector base amplitude panning)”(《音频工程学会学报》第45卷第6期(1997年):第456-466页)中提供。
[0262]
对于双耳输出,可以实现多通道扬声器信号格式(和/或对象)的任何合适的双耳化。例如,典型的双耳化可以包括用头部相关传递函数(hrtf)处理音频通道,并添加合成室内混响以生成收听室的听觉印象。通过采用例如在gb专利申请gb1710085.0中概述的原理,音频对象声音的距离 方向(即,位置)信息可以被用于随用户移动的6dof再现。
[0263]
在图8中示出了适于以运行合适的软件903的移动电话或移动设备901的形式实现的示例装置。视频例如可以通过将移动电话901附接到daydream视图类型设备来再现(然而为了清楚起见,在此并不讨论视频处理)。
[0264]
音频比特流获得器923被配置为获得音频比特流924,例如从存储设备接收/取回。在一些实施例中,该移动设备包括解码器925,其被配置为接收压缩音频,并对其进行解码。在aac解码的情况下,解码器的示例是aac解码器。所得到的解码(例如,ambisonic,其中,示例实现是如图3a和6a中所示的示例)音频信号926可以被转发到聚焦处理器927。
[0265]
移动电话901在控制器数据接收器911处接收来自外部控制器的控制器数据900(例如,经由蓝牙),并将该数据传递给聚焦参数(来自控制器数据)确定器921。聚焦参数(来自控制器数据)确定器921例如基于控制器设备的定向和/或按钮事件来确定聚焦参数。聚焦参数可以包括所提出的聚焦参数(例如,聚焦/散焦方向、聚焦/散焦量、聚焦/散焦高度、
以及聚焦/散焦宽度)的任何种类的组合。聚焦参数922被转发到聚焦处理器927。
[0266]
基于ambisonic音频信号和聚焦参数,聚焦处理器927被配置为创建具有期望聚焦特性的经修改的ambisonic信号928。这些经修改的ambisonic信号928被转发到ambisonic到双耳处理器929。ambisonic到双耳处理器929还被配置为从移动电话901的定向跟踪器913接收头部定向信息904。基于经修改的ambisonic信号928以及头部定向信息904,ambisonic到双耳处理器929被配置为创建头部跟踪双耳信号930,其可以从移动电话输出,并使用例如耳机来回放。
[0267]
图9示出了示例装置(或聚焦/散焦参数控制器)1050,其可以被配置为控制或生成合适的聚焦/散焦参数,诸如聚焦/散焦方向、聚焦/散焦量、以及聚焦/散焦宽度。该装置的用户可以被配置为通过将控制器指向期望方向1009并按下选择聚焦方向按钮1005来选择聚焦方向。该控制器具有定向跟踪器1001,并且定向信息可以被用于确定聚焦/散焦方向(例如,在如图8中所示的聚焦参数(来自控制器数据)确定器921中)。在一些实施例中,聚焦/散焦方向可以在选择聚焦/散焦方向时在视觉显示器中被可视化。
[0268]
在一些实施例中,可以使用聚焦量按钮(在图9中被示为 和-)1007来控制聚焦量。每次按下会将聚焦量增加/减少一定量,例如,10个百分点。在一些实施例中,当聚焦量被设置为0%并且用户按下减号按钮时,聚焦量被设置为10%,并且聚焦/散焦控制被设置为“散焦”模式。对应地,如果聚焦量被设置为0%并且用户按下加号按钮,则聚焦量被设置为10%,并且聚焦/散焦控制被设置为“聚焦”模式。
[0269]
在一些实施例中,可能需要例如通过确定聚焦信号的期望频率范围或频谱特性来进一步指定聚焦或散焦处理。特别地,如下操作可以是有用的:在语音频率范围内加重或去加重音频频谱以提高清晰度或阻挡讲话者,例如,通过衰减低频内容(例如,低于200hz)和高频内容(例如,高于8khz)来进行聚焦,从而留下与语音相关的特别有用的频率范围。
[0270]
类似地,当用户指示要进行散焦的方向时,音频处理系统可以分析在要进行衰减的方向上的干扰源的频谱或类型(例如,语音、噪声)。进而,基于该分析,该系统可以确定非常适合该干扰源的频率范围或每频率的散焦量。例如,干扰源可以是生成高频噪声的设备,并且针对该散焦方向高频将会比例如中频和低频衰减更多。在另一个示例中,在散焦方向有讲话者,并因此,散焦量可以按照频率进行配置,以主要抑制典型的语音频率范围。
[0271]
应当理解,经聚焦处理的信号可以用任何已知的音频处理技术进行进一步的处理,诸如自动增益控制或增强技术(例如,带宽扩展、噪声抑制)。
[0272]
在一些进一步的实施例中,聚焦/散焦参数(包括方向、量和控制)是由内容创建者生成的,并且这些参数与空间音频信号一起被发送。例如,在具有现场解说员的vr视音频自然纪录片中,代替用户需要选择要进行散焦的解说员的方向,而是可以选择动态聚焦参数预设。该预设可以已经由内容创建者微调以跟随解说员的移动。例如,只有在解说员讲话时才使能散焦。换句话说,内容创建者可以生成一些预期或估计的偏好配置文件作为聚焦/散焦参数。该方法是有益的,因为只需要传送一个空间音频信号,但可以添加不同的偏好配置文件。进而,可以将不支持聚焦的传统回放器配置为简单地解码ambisonic或其他信号类型,而无需应用聚焦/散焦处理。
[0273]
在图10中示出了基于针对ambisonic信号而描述的实现的示例处理输出。在这个示例中,在音频场景内有三个声源:在前面的讲话者、在右侧-90度的讲话者、以及在左侧
110度的白噪声干扰源。图10示出了在聚焦/散焦控制被设置为“聚焦”的情况下如何利用聚焦处理来广泛地加重其中噪声源所在的方向,以及在聚焦/散焦控制被设置为“散焦”的情况下如何利用聚焦处理来广泛地去加重其中噪声源所在的方向,同时在空间音频输出保留这两个讲话者信号。因此,在行1111中在具有在前面的讲话者(特别地以信号x示出)、在右侧-90度的讲话者(特别地以信号y示出)、以及在左侧110度的噪声干扰源(以所有信号示出)的由ambisonic信号示出的示例情况中,ambisonic信号在3个列中被示出(全向w 1101,水平偶极子y 1103和x 1105)。下一行1113示出了其中对噪声源进行完全聚焦处理的ambisonic音频信号。最底下一行1115示出了具有对噪声源的完全散焦处理(即,去加重噪声)的ambisonic音频信号,从而使语音源一般处于活动状态。
[0274]
关于图11,示出了可以被用作分析或合成设备的示例电子设备。该设备可以是任何合适的电子设备或装置。例如,在一些实施例中,设备1700是移动设备、用户设备、平板计算机、计算机、音频回放装置等。
[0275]
在一些实施例中,设备1200包括至少一个处理器或中央处理单元1207。处理器1207可以被配置为执行各种程序代码,诸如本文所描述的方法。
[0276]
在一些实施例中,设备1200包括存储器1211。在一些实施例中,至少一个处理器1207被耦合到存储器1211。存储器1211可以是任何合适的存储部件。在一些实施例中,存储器1211包括用于存储可在处理器1207上实现的程序代码的程序代码部分。此外,在一些实施例中,存储器1211还可以包括用于存储数据(例如根据本文所描述的实施例已被处理或将要被处理的数据)的存储数据部分。在需要时,被存储在程序代码部分内的所实现的程序代码和被存储在存储数据部分内的数据可以经由存储器-处理器耦合而被处理器1207取得。
[0277]
在一些实施例中,接口设备1200包括用户接口1205。在一些实施例中,用户接口1205可以被耦合到处理器1207。在一些实施例中,处理器1207可以控制用户接口1205的操作并从用户接口1205接收输入。在一些实施例中,用户接口1205可以使得用户能够例如经由小键盘向设备1200输入命令。在一些实施例中,用户接口1205可以使得用户能够从设备1200获得信息。例如,用户接口1205可以包括被配置为向用户显示来自设备1200的信息的显示器。在一些实施例中,用户接口1205可以包括触摸屏或触摸接口,其既能够使信息被输入到设备1200中,又能够向设备1200的用户显示信息。
[0278]
在一些实施例中,设备1200包括输入/输出端口1209。在一些实施例中,输入/输出端口1209包括收发机。在这种实施例中,收发机可以被耦合到处理器1207,并且被配置为例如经由无线通信网络实现与其他装置或电子设备的通信。在一些实施例中,收发机或任何合适的收发机或发射机和/或接收机部件可以被配置为经由有线或有线耦合来与其他电子设备或装置通信。
[0279]
收发机可以通过任何合适的已知通信协议来与其他装置通信。例如,在一些实施例中,收发机可以使用合适的通用移动电信系统(umts)协议、诸如ieee 802.x之类的无线局域网(wlan)协议、诸如蓝牙之类的合适的短距离射频通信协议、或红外数据通信路径(irda)。
[0280]
收发机输入/输出端口1209可以被配置为接收信号,并且在一些实施例中获得如本文所描述的聚焦参数。
[0281]
在一些实施例中,可以使用设备1200以通过使用处理器1207执行合适的代码来生成合适的音频信号。输入/输出端口1209可以被耦合到任何合适的音频输出,例如被耦合到多通道扬声器系统和/或耳机(其可以是头戴跟踪式或非跟踪式耳机)等。
[0282]
通常,本发明的各种实施例可以采用硬件或专用电路、软件、逻辑或其任何组合来实现。例如,一些方面可以采用硬件来实现,而其他方面可以采用可由控制器、微处理器或其他计算设备执行的固件或软件来实现,但是本发明不限于此。尽管本发明的各个方面可以被图示和描述为框图、流程图或使用一些其他图形表示,但是众所周知地,本文所描述的这些框、装置、系统、技术或方法可以作为非限制示例采用硬件、软件、固件、专用电路或逻辑、通用硬件或控制器或其他计算设备或其某种组合来实现。
[0283]
本发明的实施例可以通过可由移动设备的数据处理器(诸如在处理器实体中)执行的计算机软件来实现,或者由硬件、或者由软件和硬件的组合来执行。此外,就此而言,应当注意,如附图中的逻辑流程的任何块可以表示程序步骤、或者互连的逻辑电路、块和功能、或者程序步骤和逻辑电路、块和功能的组合。该软件可以被存储在诸如存储器芯片或在处理器内实现的存储器块之类的物理介质上,诸如硬盘或软盘之类的磁性介质上、以及诸如dvd及其数据变体cd之类的光学介质上。
[0284]
存储器可以是适合于本地技术环境的任何类型,并且可以使用任何适当的数据存储技术来实现,诸如基于半导体的存储器设备、磁存储器设备和系统、光学存储器设备和系统、固定存储器和可移除存储器。数据处理器可以是适合于本地技术环境的任何类型,并且作为非限制性示例,可以包括通用计算机、专用计算机、微处理器、数字信号处理器(dsp)、专用集成电路(asic)、基于多核处理器架构的门级电路和处理器中的一个或多个。
[0285]
可以在诸如集成电路模块之类的各种组件中实践本发明的实施例。集成电路的设计总体上是高度自动化的过程。复杂而功能强大的软件工具可用于将逻辑级设计转换为准备在半导体衬底上蚀刻和形成的半导体电路设计。
[0286]
程序,诸如由加利福尼亚州山景城的synopsys公司和加利福尼亚州圣何塞的cadence design所提供的程序,可以使用完善的设计规则以及预先存储的设计模块库来自动对导体进行布线并将组件定位在半导体芯片上。一旦完成了半导体电路的设计,就可以将标准化电子格式(例如,opus、gdsii等)的所得设计传送到半导体制造设施或“fab”进行制造。
[0287]
前面的描述已经通过示例性和非限制性示例提供了本发明的示例性实施例的完整和有益的描述。然而,当结合附图和所附权利要求书阅读时,鉴于以上描述,各种修改和改编对于相关领域的技术人员而言将变得显而易见。然而,本发明的教导的所有这些和类似的修改仍将落入所附权利要求书所限定的本发明的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
