1.本发明涉及语音信号处理领域,特别是涉及一种基于联合训练的端到端鲁棒语音识 别系统。
背景技术:
2.语音作为人类交流信息的主要手段之一,语音增强一直在语音信号处理中占据着重 要的地位。语音增强是指当语音信号被各种各样的噪声干扰、甚至淹没后,从噪声背景 中提取有用的语音信号,抑制、降低噪声干扰的技术。
3.实际语音遇到的干扰可以分以下几类:
①
周期性噪声,例如电气干扰,发动机旋转 部分引起的干扰等,这类干扰表现为一些离散的窄频峰;
②
冲激噪声,例如-些电火花、 放电产生的噪声干扰;
③
宽带噪声,这是指高斯噪声或白噪声一类的噪声,它们的特点 是频带宽,几乎覆盖整个语音频带;
④
语音干扰,例如话筒中拾入其它人的说话,或者 传输时遇到串音引起的语音。对付上述各种不同类型的噪声,增强技术亦是不一样的。
4.语音增强技术的目标是从嘈杂的环境中,将目标干净语音分离出来,去除背景干扰 噪声。当一段语音中含有背景噪音,会严重影响语音识别、说话人识别和助听器等系统 的性能,因此语音增强技术就显得尤其重要。
5.在语音增强技术的发展过程中,早期的研究主要是采用基于谱减法、维纳滤波和基 于统计的方法等。但是,这些方法对于非平稳噪声效果十分有限,因此也制约着这些方 法的应用。近年来,随着计算机技术的发展,基于深度学习的语音增强方法得到了很大 的发展,受到了越来越多人的关注。
6.基于深度学习的语音增强方法利用大量成对的带噪-干净语音数据训练语音增强模 型,建立带噪语音特征参数和目标干净语音信号特征参数之间的映射关系。这样对于任 意输入的带噪语音信号都可以通过建立的增强模型来输出降噪后的语音信号,从而达到 语音增强的目的。采用基于深度学习建模的语音增强方法与传统的方法具有很多优点, 比如利用深度学习强大的建模能力,可以很好的学习到带噪语音和目标语音信号之间的 映射关系。但是,对于语音增强来说,其最大的问题是增强后的语音存在失真问题。语 音失真会丢失很多十分重要的语音信息,制约着语音增强的性能,严重影响语音识别的 性能。
技术实现要素:
7.本发明所要解决的技术问题是提供一种基于联合训练的端到端鲁棒语音识别系统, 以在嘈杂的背景环境中保持语音识别的性能。
8.为解决上述技术问题,本发明采用如下的技术方案。
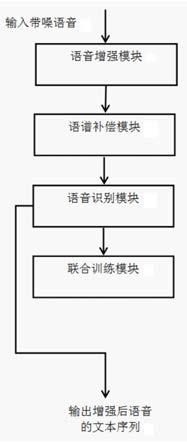
9.一种基于联合训练的端到端鲁棒语音识别系统,其特点是,包括语音增强模块、语 谱补偿模块、语音识别模块和联合训练模块;
10.所述语音增强模块,用于去除语音中的部分干扰信号;
11.所述语谱补偿模块,与所述语音增强模块相连接,用于获取语谱补偿的权重矩阵
λ, 利用该权重矩阵λ实现语谱补偿;
12.所述语音识别模块,与所述语谱补偿模块连接,主要用于预测整个语音对应的文本 序列;
13.所述联合训练模块,用于联合优化语音增强模块、语谱补偿模块及语音识别模块。
14.优选地,所述语音增强模块包括基于映射的第一语音增强模块和基于掩蔽的第二语 音增强模块。
15.优选地,所述基于映射的第一语音增强模块中,获取基于映射方法的增强幅值谱 16.优选地,所述基于掩蔽的第二语音增强模块中获取语音增强的掩蔽值
17.优选地,通过掩蔽值与原始输入语音的幅值谱y点乘得到增强后语音的幅值谱 18.优选地,所述语谱补偿模块中,获得语谱补偿的权重矩阵λ。
19.优选地,根据所述权重矩阵λ计算获得最终语谱补偿后的语谱
20.优选地,所述语谱补偿模块中,训练目标函数为计算语谱补偿语音与目 标干净语音幅值谱之间的均方误差。
21.优选地,所述语音识别模块中,将fbank作为输入特征。
22.优选地,所述语音识别模块中,利用端到端语音识别模型得到语音对应的文本序列 预测
23.本发明的有益效果是:
24.本发明的一种基于联合训练的端到端鲁棒语音识别系统,包括语音增强模块、语谱 补偿模块、语音识别模块和联合训练模块。语音增强模块,首先训练两个基于深度学习 的语音增强系统,分别为基于掩蔽的增强系统和基于映射的增强系统,它们是用于去除 大部分的干扰信号作为增强模块。语谱补偿模块,与语音增强模块相连,用于获取语谱 补偿的权重矩阵,利用该权重矩阵对基于掩蔽增强的语谱和基于映射增强的语谱进行融 合,进而实现语谱补偿并对增强的语音进一步增强的作用。语音识别模块,与语谱补偿 模块相连,将语音信号转换为预测的文本序列。联合训练模块,用于联合训练和优化语 音增强模块,语谱补偿模块和语音识别模块。
25.本发明基于联合训练的端到端鲁棒语音识别系统具有以下有益效果:
26.(1)本发明中,其语音增强模块利用深度神经网络使用基于掩蔽方法以及基于映 射方法分别对于包含噪声的语音进行增强,以去除大部分的背景噪声,从而实现对输入 语音信号增强的目的。
27.(2)本发明中,由于语音增强模块会产生语音失真进而丢失重要的语音信息,为 了找回丢失的信息解决语音失真的问题,在语谱补偿模块中,首先估计出语谱补偿的权 重矩阵,利用该矩阵对基于掩蔽方法的增强语谱和基于映射方法增强的语谱进行融合, 进而
实现语谱补偿并对增强的语音起到进一步增强的作用。;
28.(3)本发明中,在语音识别模块中,将原始输入的语谱、基于掩蔽方法增强的语 谱、基于映射方法增强的语谱以及语谱补偿模块得到的语谱分别通过fbank得到fbank 特征,并将它们连接起来,从而得到语音识别模块的输入特征。然后利用语音转换器得 到最终整个文本序列的预测,进而得到更好的语音识别性能。
29.(4)本发明中,在联合训练模块中采用联合优化语音增强模块、语谱补偿模块与 语音识别模块可以在提升语谱补偿后语音质量的同时提高语音识别的鲁棒性。
30.本发明利用增强和语谱补偿对输入的带噪语音进行建模,使得增强后的语音更加保 真,提高了端到端语音识别系统的性能,进而提升了语音识别的鲁棒性。
附图说明
31.图1是本发明的基于联合训练的端到端鲁棒语音识别系统的结构示意图。
32.图2是本发明的基于联合训练的端到端鲁棒语音识别系统的语音增强模块的结构 示意图。
33.图3是本发明的基于联合训练的端到端鲁棒语音识别系统的语谱补偿模块的结构 示意图。
34.图4是本发明的基于联合训练的端到端鲁棒语音识别系统的语音识别模块的结构 示意图。
35.图5是本发明的基于联合训练的端到端鲁棒语音识别系统的联合训练模块的结构 示意图。
具体实施方式
36.下面结合附图对本发明的较佳实施例进行详细阐述,,使本发明的目的、技术方案 和优点更加清楚明白,使本发明的优点和特征能更易于被本领域技术人员理解,从而对 本发明的保护范围做出更为清楚明确的界定。以下结合具体实施例,并参照附图,对本 发明进一步详细说明。
37.需要说明的是,在附图或说明书描述中,相似或相同的部分都使用相同的图号。且 在附图中,以简化或是方便标示。再者,附图中未绘示或描述的实现方式,为所属技术 领域中普通技术人员所知的形式。另外,虽然本文可提供包含特定值的参数的示范,但 应了解,参数无需确切等于相应的值,而是可在可接受的误差容限或设计约束内近似于 相应的值。
38.如图1-5,本发明的一种基于联合训练的端到端鲁棒语音识别系统包括语音增强模 块、语谱补偿模块、语音识别模块和联合训练模块;
39.所述语音增强模块,用于去除语音中的部分干扰信号;
40.所述语谱补偿模块,与所述语音增强模块相连接,用于获取语谱补偿的权重矩阵λ, 利用该权重矩阵λ实现语谱补偿;
41.所述语音识别模块,与所述语谱补偿模块连接,主要用于预测整个语音对应的文本 序列;
42.所述联合训练模块,用于联合优化语音增强模块、语谱补偿模块及语音识别模块。
43.进一步地,所述语音增强模块包括基于映射的第一语音增强模块和基于掩蔽的第
增强掩蔽值
[0062][0063]
上式(5)中,线性整流函数relu表示激活函数。得到增强的掩蔽值可以通 过掩蔽值与原始输入语音的幅值谱点乘得到增强后语音的幅值谱
[0064][0065]
上式(6)中,
⊙
表示点乘符号。
[0066]
进一步地,所述语谱补偿模块中,获得语谱补偿的权重矩阵λ。
[0067]
进一步地,根据所述权重矩阵λ计算获得最终语谱补偿后的语谱
[0068]
进一步地,所述语谱补偿模块中,训练目标函数为计算语谱补偿语音与 目标干净语音幅值谱之间的均方误差。
[0069]
如图3是语谱补偿模块的结构示意图,其与所述语音增强模块相连接,用于弥补因 语音失真带来的信息丢失问题。利用深度神经网络为每一个时频单元估计语谱补偿的权 重矩阵。获取语谱补偿的权重矩阵后,利用该权重矩阵对基于掩蔽方法的增强语谱和基 于映射方法的增强语谱进行融合。根据该权重矩阵λ,对基于掩蔽方法的增强语音特征 和基于映射方法的增强语音特征进行线性加权进而实现语谱补偿找回因语音失真丢失 的语音信息,进一步增强语音,提升语音增强的性能。利用语谱补偿后的幅值谱作为最 终增强后的特征。在语谱补偿后的幅值谱和真实的幅值谱之间计算均方误差作为语音增 强模块的训练目标函数。
[0070]
语谱补偿模块首先将输入的h
fusion
通过深度神经网络获取深层表示h
mend
,如下式 (7)。
[0071]hmend
=f
dnn
(h
fusion
)
ꢀꢀꢀꢀꢀ
(7)
[0072]
式(8)中的h
mend
进行sigmoid操作,以获取得到语谱补偿的权重矩阵λ。
[0073][0074]
式(8)的σ表示sigmoid激活函数。
[0075]
将λ作为基于掩蔽方法的语音增强谱权重矩阵,1-λ作为基于映射方法的增强语 谱权重矩阵,那么可以通过下面的公式(9)得到最终语谱补偿后的语谱
[0076][0077]
对于语谱补偿模块,其训练目标函数为计算语谱补偿语音与目标干净
语 音幅值谱之间的均方误差,见下式(10)。
[0078][0079]
式(10)中,tf表示时频单元的数目,表示平方frobenius范数,|x|表示目标 干净语音幅值谱。
[0080]
进一步地,所述语音识别模块中,将fbank作为输入特征。
[0081]
进一步地,所述语音识别模块中,利用端到端语音识别模型得到语音对应的文本序 列预测
[0082]
如图4,语音识别模块的结构示意图,其与所述语谱补偿模块相连接,语音识别通常 使用fbank作为输入特征,主要用于预测整个语音对应的文本序列。将原始的输入语谱、 基于掩蔽方法的增强语谱、基于映射方法的增强语谱、语谱补偿模块得到的语谱经过转 换得到fbank特征,并将它们拼接起来,得到语音识别模块的最终输入特征。利用端到 端语音识别模型得到语音对应的文本序列预测。采用交叉熵作为语音识别模块的训练目 标函数。
[0083]
语音识别中常用的音频特征包括fbank与mfcc。获得语音信号的fbank特征的 一般步骤是:预加重、分帧、加窗、短时傅里叶变换(stft)、mel滤波、去均值等。 对fbank做离散余弦变换(dct)即可获得mfcc特征。
[0084]fi
=fbank(θ)
ꢀꢀꢀ
(11)
[0085]
式(11)中,fi表示fbank特征,fbank(l)表示提取fbank特征的函数, [0086]
通过fbank(l)函数分别提取原始输入语音的fbank特征、基于映射增强方法的 fbank特征、基于掩蔽增强方法的fbank特征、语谱补偿模块的fbank特征。将这些 fbank特征连接起来作为语音识别模块的输入特征。
[0087]
f=concat(f
original
;f
mapping
;f
masking
;f
mmfnet
)
ꢀꢀꢀꢀ
(12)
[0088]
式(12)中,f表示语音识别的输入特征。f
original
表示原始语音信号的fbank特征; f
mapping
表示基于映射增强方法的fbank特征;f
masking
表示基于掩蔽增强方法的fbank特 征;f
mmfnet
表示语谱补偿模块的fbank特征。concat(
·
)表示将这些fbank特征连接起 来的连接函数。
[0089]
将f输入到语音转换器得到最终整个语音文本序列的预测见下式(13):
[0090][0091]
式(13)中,其中是最终整个语音对应的文本序列的预测,speech_transformer (
·
)表示端到端语音识别模型的函数。
[0092]
图4中,对于语音识别模块,使用交叉熵准则作为其训练目标函数
[0093][0094]
式(14)中,s*是整个输出标签序列的真实值;ln为自然对数,p(s*|f)表示当 输入为f特征时达到真实值s*的条件概率。
[0095]
图5是联合训练模块的结构示意图,其与语谱补偿模块和语音识别模块相连接,用 于联合优化各个模块。
[0096]
联合训练模块用于联合训练和优化各个模块:语音增强模块、语谱补偿模块以及语 音识别模块。语谱补偿模块的目标函数和语音识别模块的目标函数以一定的权重进行线 性组合作为最终的目标函数。
[0097][0098]
式(15)中,为总的损失函数,超参数α表示语谱补偿模块和语音识别模 块的权重。最终,通过联合训练的方式优化语音增强系统,进而提升语音识别的鲁棒性。
[0099]
本发明基于联合训练的端到端鲁棒语音识别系统中,语音增强模块,用于对输入的 带噪语音进行增强,去除大部分的噪声信号;语谱补偿模块,与语音增强模块相连,用 于对增强的语音进行语谱补偿,进而找回因语音失真问题丢失的语音信息;语音识别模 块,与语谱补偿模块相连,用于将语音转换成对应的文本序列。联合训练模块,用于联 合训练和优化语音增强模块、语谱补偿模块、语音识别模块。
[0100]
本发明的语音增强模块中使用基于掩蔽方法以及基于映射方法分别对输入的带噪 语音进行增强从而去除大部分的噪声信号。为了解决语音失真问题,我们利用语谱补偿 模块对基于掩蔽方法的增强语音和基于映射方法的增强语音进行融合,进而找回因失真 丢失的语音信息。将语谱补偿模块得到的最终增强特征送入语音识别模块,产生最终预 测的文本序列。最后利用联合优化方法进一步提升语音增强模块和语谱补偿模块的性能 以及提高语音识别的鲁棒性。
[0101]
本发明中,首先利用语音增强模块中的掩蔽增强系统、映射增强系统分别对带噪语 音进行增强以去除大部分的背景噪声,由于语音失真会丢失很多语音信息,利用语谱补 偿模块对基于掩蔽方法的增强语音和基于映射方法的增强语音进行语谱补偿,将补偿后 的语音输送到语音识别模块输出预测文本序列,最后利用联合优化方法进一步提高语音 增强的音质和可懂度,进而提升语音识别的鲁棒性。
[0102]
本发明利用语音增强模块和语谱补偿模块对输入的带噪语音进行建模,使得增强后 的语音更加保真,感知质量和可懂度更高,提高了语音增强系统的性能,进而提升了语 音识别的鲁棒性。
[0103]
需要说明的是,上述对各元件的定义并不仅限于实施方式中提到的各种具体结构或 形状,本领域的普通技术人员可对其进行简单地熟知地替。
[0104]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不 背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无 论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由 所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围 内
的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权 利要求。
[0105]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包 含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应 当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术 人员可以理解的其他实施方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。