1.本发明属于智能教育领域,应用于知识追踪任务。
背景技术:
2.一、名词解释:1.知识追踪(knowledge tracing,kt):根据学习者的答题记录建模得到学习者的知识掌握状态并预测学习者在下一题目的答对概率。2.知识查询(convolutional neural networks,kqn):2019年研究者提出知识查询网络以解决知识追踪任务,它利用神经网络将学生的当前时间步的历史交互序列和下一个时间步题目包含的kc编码为相同维度的知识状态向量和技能向量,然后用两个向量之间的点积来定义学生知识状态和kc的相互作用。3.长短期记忆网络(long short-term memory,lstm):lstm模型是研究者针对rnn的梯度消失和梯度爆炸问题而提出的改进模型。它在原始rnn模型之上加入“门”来控制信息的传递,可在一定程度上避免梯度消失与爆炸问题,获取序列的长距离依赖信息。4.自注意力机制(self-attention mechanism):源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息;后来有人把这个思想运用到图像处理和自然语言处理当中,并取得了不错的效果,最近有人引入自注意力机制到知识追踪任务中,其目的是为了更好地关注那些对预测更重要的学习历史序列。5.重构错误(reconstruct problem):知识查询网络模型的一大问题就是重构错误,即当学生正确回答包含某技能的题目时,但模型对当前时间步学生能否答对包含该技能的题目的预测概率反而降低,反之亦然。6.知识成分(knowledge component,kc):kc可以被泛化地理解为知识点、知识概念、原理、事实或者技能。
3.二、现有技术:1.(1)贝叶斯知识追踪(bayesian knowledge tracing,bkt)方法: bkt模型将学生知识状态建模为一组潜在的二元变量,同时利用隐马尔可夫模型(hiddenmarkov model,hmm)根据学生回答问题的对错情况等可观测变量来更新学生知识状态这个潜在变量。虽然bkt及其扩展模型在kt领域已经取得了很大成功,但是其本身仍存在不小的问题。第一,学习者的知识状态表示为一组二元变量的设定不符合现实世界中的学习过程;第二,bkt针对每个kc分开建模的方式使它无法捕捉不同kc间的关系,也无法对未定义的kc进行建模。(2)深度知识追踪模型(deep knowledge tracing,dkt):2015 年,dkt模型首次将深度神经网络引入到知识追踪任务中,它利用lstm建模学生序列并取得了不错的效果,但其可解释性一直为人质疑。(3)知识查询网络(knowledge querynetwork,kqn)模型:利用神经网络将学生的当前时间步的历史交互序列和下一个时间步题目包含的kc编码为相同维度的知识状态向量和技能向量,然后用两个向量之间的点积来定义学生知识状态和kc的相互作用,它和dkt一样都存在重构错误。2.自注意力知识追踪(self attention kt,sakt)模型:率先在kt领域使用了
transformer 结构替代原始dkt模型使用的rnn,解决了rnn存在的长期依赖问题并使得模型预测性能大大提升,但是,sakt模型也丧失了rnn对序列建模的能力。
4.三、技术问题:1.虽然知识查询网络在一定程度上提升了在学生和kc交互方面的可解释性,但其预测性能不如自注意力知识追踪,原因是lstm的长期依赖问题限制了模知识查询网络的性能,并且知识查询网络还存在和dkt一样的重构错误。2.自注意力知识追踪使用了更先进的transformer结构,但也丧失了rnn对序列建模的能力,学生的学习是连续的,所以模型的序列建模能力是不可忽视的。
技术实现要素:
7.1.针对知识查询网络和自注意力知识追踪模型的不足,本发明的目的是为了融合知识查询网络和自注意力知识追踪模型各自的优势,在知识查询网络模型中引入自注意力机制,在获取了更加准确的学生历史交互序列内部关键特征的同时保留了长短期记忆网络循环建模的能力,并在损失函数中引入正则化项,增强了模型预测的一致性,解决知识查询网络本身存在的重构错误;
8.2.本发明的技术创新点是:(1)提出了一种引入自注意力机制的知识查询网络的深度知识追踪模型,利用长短期记忆网络提供的位置信息来建模学生历史交互序列的前后关系保留了模型序列建模的能力,同时通过自注意力机制关联单个序列的不同位置以计算序列的表示来获得更加准确的学生历史做题记录内部关键特征,融合两者优势提升预测性能; (2)模型的损失函数中引入对应重构问题的正则化项以增强预测的一致性进而解决kqn 本身存在的重构错误;
附图说明
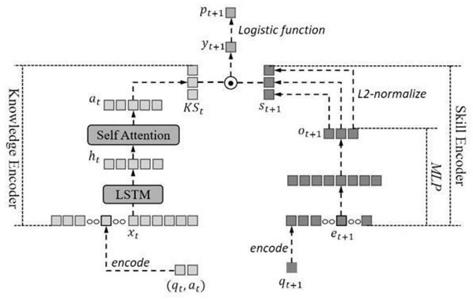
9.附图1是引入自注意力机制的知识查询网络结构图。
具体实施方式
10.上说明书附图为本发明在t时刻的模型结构图,模型由三个部分组成:知识状态编码器(knowledge state encoder)、技能编码器(skill encoder)和知识状态查询(knowledge state query)。在t时刻,知识状态编码器将来自学生的历史交互元组x
t
首先输入lstm层中得到隐藏状态h
t
,再把h
t
输入到注意力层得到a
t
,最后将a
t
转换为d维的知识状态向量ks
t
;而技能编码器将下一个时间步t 1所包含的技能q
t 1
通过多层感知器(multilayer perceptron, mlp)嵌入到同样为d维的技能向量s
t 1
中。然后将这两个向量传递给知识状态查询组件,知识查询组件利用两个向量点积的方式描述学生知识状态和题目包含kc之间的交互,最后将点积结果经过sigmoid函数获取当前时间步学生能否正确作答下一时间步的题目的概率预测。
技术特征:
1.一种引入自注意力机制的知识查询网络的深度知识追踪模型其特征在于:首先利用知识状态编码器中的长短期记忆网络提供的位置信息来建模学生交互序列的前后关系,再通过自注意力机制关联单个序列的不同位置以计算序列的表示来获得更加准确的学生历史做题记录内部关键特征,然后将自注意力层得到的结果编码成知识状态向量。最后,模型利用技能编码器的多层感知机得到的技能向量与知识编码器得到的知识状态向量进行向量点积来模拟知识状态与知识点的相互作用并输入到sigmoid函数中得到学生下一问题的正确作答概率。损失函数中引入了加入了对应重构问题的正则化项以增强模型预测的一致性进而解决其存在的重构错误。2.根据权利要求1所述的一种引入自注意力机制的知识查询网络模型其特征在于:所述知识状态编码器在保留了长短期记忆网络建模序列的能力的同时,利用自注意力机制自动关注学生历史交互序列中对预测结果影响更大的做题记录,提取更为准确的学生知识状态相关特征。3.根据权利要求1所述的一种引入自注意力机制的知识查询网络模型其特征在于:所述加入对应重构问题的正则化项是通过考虑到预测和当前学生知识状态与技能之间相互作用的损失来规范原模型。4.根据权利要求1所述的一种引入自注意力机制的知识查询网络模型其特征在于:所述学生知识状态编码器的输入学生交互序列和技能编码器的输入技能均被编码成独热编码向量。5.根据权利要求1所述的一种引入自注意力机制的知识查询网络模型其特征在于:所述学生知识状态编码器的输出学生知识状态向量和技能编码器的输出技能向量的点积作用是符合现实世界中学生作答问题时是基于自身知识状态结合题目进行答题的情况。
技术总结
针对知识查询网络和自注意力知识追踪模型的不足,设计了引入自注意力机制的知识查询网络模型。本发明的目的是为了知识查询网络、自注意力机制各自的优势,在知识查询网络中引入自注意力机制在保留模型建模序列的能力的同时还能增强关联单个序列的不同位置以计算序列的表示来获得更加准确的学生历史做题记录内部关键特征。并且在模型损失函数中加入了对应重构错误的正则化项以增强模型预测的一致性进而解决其存在的重构错误。致性进而解决其存在的重构错误。致性进而解决其存在的重构错误。
技术研发人员:程艳 吴刚 陈豪迈 项国雄
受保护的技术使用者:江西师范大学
技术研发日:2021.12.20
技术公布日:2022/4/1
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。