多个透明对象3d检测
技术领域
1.本公开一般涉及用于获得对象的3d姿态的系统和方法,并且更具体地,涉及一种机器人系统,其获得其是一组对象的一部分的对象的3d姿态,其中,该系统获得多个对象的rgb图像,使用图像分割来分割图像,剪切所述多个对象的分割图像,并且使用基于学习的神经网络来获得分割图像中的每个对象的3d姿态。
背景技术:
2.机器人执行包括拾取和放置操作的多个任务,其中机器人拾取对象并将对象从一个位置(例如收集料箱)移动到另一个位置(例如传送带),其中对象在料箱中的被称为对象的3d姿态的位置和取向略微不同。因此,为了使机器人有效地拾取对象,机器人通常需要知道对象的3d姿态。为了识别从料箱拾取的对象的3d姿态,一些机器人系统采用生成料箱的2d红-绿-蓝(rgb)彩色图像和料箱的2d灰度深度图图像的3d照相机,其中深度图图像中的每个像素具有定义从照相机到特定对象的距离的值,即,像素越靠近对象,其值越低。深度图图像识别到照相机的视场中的点云中的点的距离测量,其中点云是由特定坐标系定义的数据点的集合,并且每个点具有x、y和z值。然而,如果机器人拾取的对象是透明的,则光不能从对象的表面精确地反射,并且由照相机产生的点云无效,并且深度图像不可靠,因此不能可靠地识别对象以进行拾取。
3.转让给本技术的受让人并且通过引用结合于此的、标题为由2d照相机进行的3d姿态估计、于2020年4月3日提交的美国专利申请第16/839,274号公开了一种机器人系统,该机器人系统用于使用来自2d照相机的2d图像和基于学习的神经网络来获得对象的3d姿态,该神经网络能够识别正被拾取的透明对象的3d姿态。神经网络从2d图像提取对象上的多个特征,并且针对所提取的特征中的每个生成热图,该热图通过颜色表示来识别对象上的特征点的位置的概率。该方法提供包括来自2d图像上的热图的多个特征点的特征点图像,并且通过比较特征点图像和对象的3d虚拟cad模型来估计对象的3d姿态。换句话说,采用优化算法来最优地旋转和平移cad模型,使得投影的特征点在模型中与图像中的预测特征点匹配。
4.如上所述,'274机器人系统预测由机器人拾取的对象的图像上的多个特征点。然而,如果机器人从诸如料箱中的多个对象之类的一组对象中选择性地拾取对象,则在图像中将存在多个对象,并且每个对象将具有多个预测特征。因此,当cad模型旋转时,其投影特征点可以匹配不同对象上的预测特征点,从而阻止该过程可靠地识别单个对象的姿态。
技术实现要素:
5.以下讨论公开并描述了用于获得多个对象的3d姿态以允许机器人拾取所述多个对象的系统和方法。该方法包括使用照相机获得所述多个对象的2d红-绿-蓝(rgb)彩色图像,以及通过使用深度学习卷积神经网络执行图像分割过程来生成rgb图像的分割图像,该图像分割过程从rgb图像提取多个特征并且向分割图像中的各个像素分配标签,使得分割
图像中的各个对象具有相同标签。该方法还包括将分割图像分离成多个剪切图像,其中每个剪切图像包括所述多个对象中的一个,估计每个剪切图像中的每个对象的3d姿态,以及将所述3d姿态组合成单个姿态图像。每当由机器人从一组对象中拾取一个对象时,执行获得彩色图像、生成分割图像、分离分割图像、估计每个对象的3d姿态以及组合3d姿态的步骤。
附图说明
6.结合附图,从以下描述和所附权利要求,本公开的附加特征将变得显而易见。
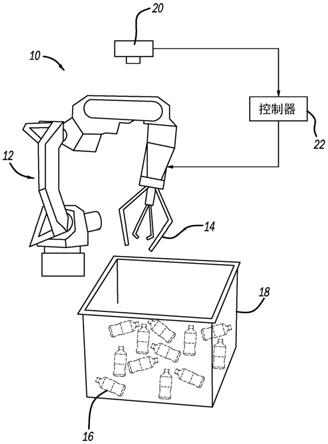
7.图1是包括从料箱拾取出多个对象的机器人系统的示意图;
8.图2是用于从图1所示的机器人系统中的料箱拾取所述多个对象的料箱拾取系统的示意性框图;
9.图3是与图2所示的系统分离的分割模块的示意性框图;
10.图4是示出了用于使用已训练的神经网络的基于学习的神经网络过程的流程图,所述基于学习的神经网络过程使用对象的2d分割图像和神经网络估计对象的3d姿态;
11.图5是描绘用于在图4所示的过程中确定对象的3d姿态估计的透视n点(pnp)过程的示意图;以及
12.图6是包括多个类别的分割图像的示意图,其中每个类别具有多个对象。
具体实施方式
13.以下对本公开实施例的讨论涉及一种机器人系统,该机器人系统获得在一组透明对象中的多个对象的3d姿态,其中该系统获得该多个对象的rgb图像,使用图像分割来分割该图像,剪切该多个对象的分割图像,并使用基于学习的神经网络来获得各分割对象的3d姿态,这样的讨论在本质上仅是示例性的,而绝非旨在限制本发明或其应用或使用。例如,该系统和方法具有用于确定一组透明对象中的透明对象的位置和取向的应用。然而,该系统和方法可以具有其他应用。
14.图1是机器人系统10的示意图,该系统包括具有末端执行器14的机器人12,该末端执行器被示出为从料箱18分别拾取多个对象16,例如透明瓶子。系统10旨在表示能够受益于这里的讨论的任何类型的机器人系统,其中机器人12可以是适合于该目的任何机器人。照相机20被定位成获取料箱18的多个自顶向下的图像并且将它们提供给控制机器人12的运动的机器人控制器22。因为该多个对象16可以是透明的,所以控制器22不能依赖于深度图图像来识别在料箱18中的该多个对象16的位置。因此,仅使用来自照相机20的rgb图像,并且这样的照相机20可以是2d或3d照相机。
15.为了使机器人12有效地抓住和拾取该多个对象16,需要能够在其抓住对象16之前将末端执行器14定位在适当的位置和取向。如下面将详细讨论的,机器人控制器22采用允许机器人12拾取该多个对象16而不必依赖于准确的深度图图像的算法。更具体地说,该算法使用来自照相机20的rgb图像中的各个像素的不同颜色来执行图像分割过程。图像分割是将标签分配给图像中的每个像素以使得具有相同标签的像素共享某些特性的过程。因此,分割过程预测哪个像素属于该多个对象16中的哪一个。
16.现代图像分割技术可以采用深度学习技术。深度学习是一种特定类型的机器学
习,其通过将某个真实世界环境表示为越来越复杂的概念的层次结构来提供更好的学习性能。深度学习通常采用包括执行非线性处理的若干层神经网络的软件结构,其中每个相继的层接收来自前一层的输出。通常,这些层包括接收来自传感器的原始数据的输入层、从数据中提取抽象特征的多个隐藏层、以及基于来自该多个隐藏层的特征提取来识别某个事物的输出层。神经网络包括神经元或节点,每个神经元或节点具有“权重”,该权重乘以节点的输入以获得某个事物是否正确的概率。更具体地说,每个节点具有一个权重,该权重是一个浮点数,该浮点数与该节点的输入相乘,以生成该节点的输出,该输出是该输入的某一比例。通过在有监督的处理下使神经网络分析一组已知数据,并通过最小化成本函数以允许网络获得正确输出的最高概率,来初始“训练”或设置权重。
17.图2是料箱拾取系统30的示意性框图,该料箱拾取系统是机器人系统10中的控制器22的一部分,其操作以从料箱18拾取该多个对象16。系统30从照相机20接收料箱18的顶视图的2d rgb图像32,其中该多个对象16被示出在图像32中。图像32被提供给执行图像分割过程的分割模块36,其中每个像素被分配某个标签,并且其中与相同对象16相关联的各个像素具有相同的标签。
18.图3是与系统30分离的模块36的示意框图。rgb图像32被提供给特征提取模块40,该模块执行从图像32中提取重要特征的滤波过程,该过程去除背景和噪声。例如,模块40可包括基于学习的神经网络,其从图像32中提取梯度、边缘、轮廓、基本形状等,其中模块40以已知方式提供rgb图像32的提取的特征图像44。特征图像44被提供给区域建议模块50,其使用神经网络来分析图像44中所识别的特征以确定该多个对象16在图像44中的位置。特别地,模块50包括已训练的神经网络,其提供多个不同大小的边界框,诸如50到100个框,即,具有各种长度和宽度的框,其被用于识别对象16存在于图像44中的某一位置处的概率。在该实施例中,边界框都是竖直框,这有助于降低模块50的复杂度。区域建议模块50采用本领域技术人员公知的滑动搜索窗口模板,其中包括所有边界框的搜索窗口例如从图像44的左上到图像44的右下在特征图像44上移动,以寻找识别该多个对象16中的一个的可能存在的特征。
19.滑动窗口搜索产生包括多个边界框52的边界框图像54,每个边界框包围图像44中的预测对象,其中每当机器人12从料箱18中移除该多个对象16中的一个时,图像54中的边界框52的数量将减少。模块50参数化每个框52的中心位置(x,y)、宽度(w)和高度(h),并且提供在框52中存在对象16的0%和100%之间的预测置信度值。图像54被提供给二进制分割模块56,其使用神经网络来估计像素是否属于每个边界框52中的对象16,以去除框52中的不是对象16的一部分的背景像素。图像54中的每个框52中的剩余像素被分配用于特定对象16的值,使得生成通过不同的标记(诸如颜色)来识别该多个对象16的2d分割图像58。因此,所描述的图像分割过程是深度学习掩模r-cnn(卷积神经网络)的改进形式。然后,对图像58中的各个分割对象进行剪切,以将图像58中的每个识别的对象16分离为仅具有该多个对象16中的一个的剪切图像60。
20.然后,将每个剪切图像60发送到单独的3d姿态估计模块70,其以与例如'274申请中相同的方式执行该图像60中的对象16的3d姿态估计,以获得估计的3d姿态72。图4是流程图80,其示出了在模块70中运行的算法,该算法采用使用已训练的神经网络的基于学习的神经网络78来估计特定的剪切图像60中的对象16的3d姿态。图像60被提供给输入层84和多
个连续的残余块层86和88,这些残余块层包括在控制器22中的ai软件中运行的神经网络78中的前馈回路,该前馈回路使用滤波过程来提供图像60中的对象16上的可能的例如梯度、边缘、轮廓等的特征点的特征提取。包括所提取特征的图像被提供给神经网络78中的多个连续卷积层90,其将从所提取特征获得的可能特征点定义为一系列热图92,每个特征点一个热图,热图基于热图92中的颜色示出特征点存在于对象16上的可能性。使用对象16的包括来自所有热图92的所有特征点的多个特征点96的图像60生成图像94,其中每个特征点96基于该特征点的热图92的颜色被分配置信度值,并且其中不使用置信度值不高于某一阈值的那些特征点96。
21.然后,在姿态估计处理器98中,将图像94与具有相同特征点的对象16的标称或虚拟3d cad模型进行比较,以提供对象14的估计3d姿态72。在本领域中,用于将图像94与cad模型进行比较的一种合适的算法被称为透视n点(pnp)。一般来说,pnp过程在给定世界坐标系中的对象的一组n个3d点以及它们在来自照相机20的图像中的对应2d投影的情况下估计对象相对于校准的照相机的姿态。该姿态包括由对象相对于照相机坐标系的旋转(滚动、俯仰和偏航)和3d平移组成的六个自由度(dof)。
22.图5是在该示例中如何实现pnp过程以获得对象16的3d姿态的示意图100。该示意图100示出了在真正或真实位置处的表示对象16的3d对象106。对象106由表示照相机20的照相机112观察,并且在2d图像平面110上投影为2d对象图像108,其中对象图像108表示图像94,并且其中图像108上的点102是由神经网络78预测的表示点96的特征点。示意图100还示出了对象16的在与特征点96相同位置处具有特征点104的虚拟3d cad模型114,其被随机放置在照相机112前面并且在图像平面110上被投影为还包括所投影的特征点118的2d模型图像116。cad模型114在照相机112前面旋转和平移,该照相机旋转和平移模型图像116,以试图最小化模型图像116上的每个特征点118和对象图像108上的相应特征点102之间的距离,即,对准图像116和108。一旦模型图像116与对象图像108尽可能最佳地对准,cad模型114相对于照相机112的姿态就是对象16的估计的3d姿态72。
23.对于图像108和116之间的各个对应特征点中的一个,该分析由等式(1)描述,其中等式(1)用于图像108和116的所有特征点。其中,vi是cad模型114上的各个特征点132中的一个,νi是模型图像116中的相应投影特征点102,αi是对象图像108上的各个特征点102中的一个,r是cad模型114相对于相机112的旋转,t是cad模型114相对于相机112的平移,符号'是矢量转置,并且是指具有索引i的任何特征点。通过用优化解算器求解方程(1),可以计算最优的旋转和平移,从而提供对象16的3d姿态72的估计。
24.所有3d姿态72被组合成单个图像74,并且机器人12选择该多个对象16中的一个来拾取。一旦机器人12拾取并移动了对象16,照相机20将拍摄料箱18的新图像以拾取下一个对象16。该过程继续直到已经拾取了所有对象16。
25.以上讨论了在具有相同类型或类别的一组对象,即透明瓶子中识别多个对象的3d姿态。然而,上述过程具有识别具有不同类型或类别的多个对象的一组对象中的多个对象
的3d姿态的应用。这由图6中所示的分割图像124示出,其包括一个类别的分割对象126(即瓶子)和另一类别的分割对象128(即杯子)。
26.如本领域技术人员将充分理解的,这里讨论的描述本发明的若干和各种步骤和过程可以指由计算机、处理器或其他电子计算设备执行的操作,其使用电现象来操纵和/或变换数据。那些计算机和电子设备可以采用各种易失性和/或非易失性存储器,包括其上存储有可执行程序的非瞬态计算机可读介质,所述可执行程序包括能够由计算机或处理器执行的各种代码或可执行指令,其中存储器和/或计算机可读介质可以包括所有形式和类型的存储器和其他计算机可读介质。
27.前述讨论仅公开和描述了本公开的示例性实施例。本领域技术人员将容易地从这样的讨论和从附图和权利要求认识到,在不偏离如在所附权利要求中限定的本公开的精神和范围的情况下,可以在其中进行各种改变、修改和变化。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
