1.本发明涉及注气油田分层开采技术领域,提供一种基于迁移学习的油田产油量预测方法。
背景技术:
2.随着大部分油田进入到开发的中后期阶段,二次采油已成为各油田提高产量,维持产量的必然选择,主要有注气、注水等方法,对注气注水后的产油量及产液量进行预测,是油井配产及开发方案调整的重要内容,为深层油藏高效开发提供理论支撑。目前产量预测的方法有很多,如,ls-svm算法和长短期记忆网络等,应用在实际油田的预测中,但这些方法一般都需要大量的训练样本。而实际中,新井组样本量较少,会对预测效果产生影响,以预测某油田新井组产油量为例,可能只有几年的数据,在小样本的情况下,模型精度不高。所以,对新井组产油量进行预测时,应该充分考虑样本量对预测结果的影响。由于油田产油量和注气量、注水量之间的关系不是线性的,而是一种非线性关系,需要大量数据训练模型才能拟合这种非线性关系。传统的产量预测方法,它们只适用于历史数据较多的情况,而油藏数值模拟方法,存在工作量大、投入多、适用性受到限制等局限性。
3.因此,我们发明了一种新的基于迁移学习的油田产油量预测方法,解决油田实际项目中遇到的技术问题。
技术实现要素:
4.本发明提供一种基于迁移学习的油田产油量预测方法,采用堆叠lstm神经网络对小样本进行预测。
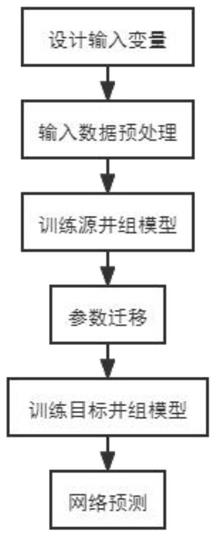
5.本发明的目的可通过下述技术措施来实现:基于迁移学习的油田产油量预测方法,该基于迁移学习的油田产油量预测方法包括:步骤1,对不同井组的油田数据进行维度对齐处理,使模型可以迁移;步骤2,采用4层堆叠lstm网络,使用源井组的数据训练网络;步骤3,根据损失指标来保存训练中最佳的模型权重参数;步骤4,加载已训练好的格式模型,训练目标井组的数据,比较预测值和实际值,优化预测模型。
6.本发明可以通过如下技术措施来实现:
7.步骤1,不同井组数据的维度不同。要想迁移模型,最终进入模型的数据维度就必须一致,因此维度对齐使得源井组和目标井组数据维度是一致的。
8.步骤2,采用4层堆叠lstm网络,每层有50个神经元,网络最后一层dense层神经元个数为1,使用keras搭建网络,使用mse损失函数,选择adam优化器,用dropout防止过拟合,dropout比率选择0.2。在每次训练的时候保存损失最小的模型,重复进行多次实验,结果求平均值;根据堆叠lstm网络模型输出的预测值与真实值的准确率来衡量模型的性能,得到这组数据的准确率均值。
9.步骤3,模型迁移就是将源井组已经训练好的模型拿过来,作为新井组初始化参数,然后继续训练就可以。因此,在多次迭代时,保存最小损失函数对应的最优网络,使用此
模型进行迁移学习。
10.步骤4,迁移训练好的堆叠lstm模型预测新井组的产油量,训练新井组的数据,比较预测值和实际值,优化预测模型进一步提高预测效率和预测精度。
附图说明
11.图1为本发明的基于迁移学习的油田产油量预测方法的流程图;
12.图2为本发明中维度对齐过程以及具体使用方式的示意图。
具体实施方式
13.为使本发明的上述目的、特征和优点能更明显易懂,下文特举出较佳实施例,并配合附图所示,作详细说明如下。
14.如图1所示,图1为本发明的基于迁移学习的油田产油量预测方法的流程图。
15.在本发明的具体实施例中,根据拉丁超立方生成15种井组的月度产油量数据作为样本,首先从中取出几类作为训练模型的源井组数据集,然后再从剩余的井组中挑选一类作为小样本目标井组数据集,并将数据集按照一定比例分为训练集和测试集。利用模型预测油田月产油量,其输入变量为各井在每个时间上的工作制度,如注气井的注气量、注水井的注水量、生产井的井底流压等。
16.当实际操作时,用keras构建神经网络,在linux系统、英伟达rtx3090gpu、英特尔i9cpu设备上训练模型。源井组数据样本尽可能大且多样化,尽可能多涵盖几种情况,获得的迁移模型具有较好的预测效果,小样本情况下,准确率也较高。本发明实施例选用4种井组400种制度作为源井组数据,1种井组(不含于上述4种井组)10种制度作为目标井组数据,准确率是90.4%,20种制度时准确率可达91.6%。
17.根据堆叠lstm网络模型输出的预测值与真实值的准确率来衡量模型的性能,小样本准确率的均值,可以达到90%。
技术特征:
1.基于迁移学习的油田产油量预测方法,其特征在于,该基于迁移学习的油田产油量预测方法包括:步骤1,对不同井组的油田数据进行维度对齐处理,使模型可以迁移;步骤2,采用4层堆叠lstm网络,使用源井组的数据训练网络;步骤3,根据损失指标来保存训练中最佳的模型权重参数;步骤4,加载已训练好的格式模型,训练目标井组的数据,比较预测值和实际值,优化预测模型。2.根据权利要求1所述的基于迁移学习的油田产油量预测方法,其特征在于,在步骤1中,不同的井组之间会存在数据维度差异,利用维度对齐进行数据预处理,将两个井组不同维度的数据整合到同一维度,使模型可以迁移。3.根据权利要求1所述的基于迁移学习的油田产油量预测方法,其特征在于,在步骤2中,设计网络结构与参数,把源井组数据归一化后,导入神经网络模型中进行训练而得到预训练模型,为迁移做准备。4.根据权利要求1所述的基于迁移学习的油田产油量预测方法,其特征在于,在步骤3中,保存训练过程中的最佳模型权重,即保存精度较高的模型,预训练模型很准确的时候,把参数保存,迁移后也能获得较好的结果。5.根据权利要求1所述的基于迁移学习的油田产油量预测方法,其特征在于,在步骤4中,对样本数据较少的新井组,可以加载预训练模型,在预训练模型的基础上训练,训练出最终模型用于预测油田产油量。
技术总结
本发明提供了一种基于迁移学习的油田产油量预测方法,本方法实现的功能是,通过迁移学习实现小样本井组的产油量预测。本发明首先对不同井组不同维度的数据进行处理,采用维度对齐统一数据维度,然后构建一个堆叠LSTM神经网络,采用样本量充足的源井组数据,保存网络参数,训练出预训练模型。在预测小样本的时候,调用迁移参数,在预训练模型的基础上,使用目标井组的小样本数据集进行训练,得到适用于小样本预测的模型。该基于迁移学习的油田产油量预测方法能帮油田节省预测时间,对井组部署和油井工作制度的确定有重要意义。油井工作制度的确定有重要意义。
技术研发人员:董玉坤 张宇 刘富彬
受保护的技术使用者:中国石油大学(华东)
技术研发日:2021.12.21
技术公布日:2022/3/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。