技术特征:
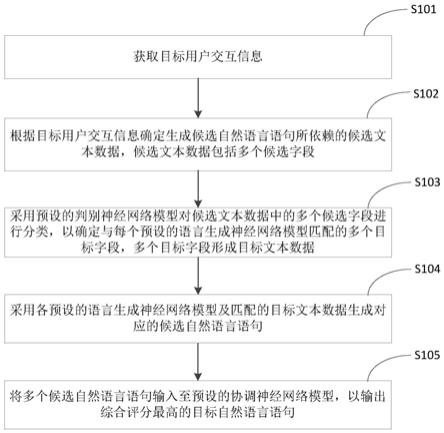
1.一种自然语言生成方法,其特征在于,包括:获取目标用户交互信息;根据目标用户交互信息确定生成候选自然语言语句所依赖的候选文本数据,所述候选文本数据包括多个候选字段;采用预设的判别神经网络模型对所述候选文本数据中的多个候选字段进行分类,以确定与每个预设的语言生成神经网络模型匹配的多个目标字段,所述多个目标字段形成目标文本数据;采用各预设的语言生成神经网络模型及匹配的目标文本数据生成对应的候选自然语言语句;将多个候选自然语言语句输入至预设的协调神经网络模型,以输出综合评分最高的目标自然语言语句。2.根据权利要求1所述的方法,其特征在于,所述语言生成神经网络模型包括:基于知识的语言生成模型、基于对话动作的语言生成模型及基于搜索条件的语言生成模型;所述采用各预设的语言生成神经网络模型及匹配的目标文本数据生成对应的候选自然语言语句,包括:将各类型的目标文本数据输入到匹配的语言生成神经网络模型中;通过各匹配的语言生成神经网络模型对目标文本数据进行自然语言生成处理,并输出对应的候选自然语言语句。3.根据权利要求2所述的方法,其特征在于,所述基于知识的语言生成模型包括编码器、知识选择器、解码器和词语生成器;与基于知识的语言生成模型匹配的目标文本数据为基于知识的目标文本数据;所述基于知识的目标文本数据包括以下多种目标字段:用户意图搜索结果、与用户意图关联的知识库中的实体、用户画像信息、对话动作和槽位信息;采用基于知识的语言生成模型及基于知识的目标文本数据生成对应的候选自然语言语句,包括:采用所述编码器对各基于知识的目标字段进行编码处理,以生成对应的隐状态表示数据;采用所述知识选择器根据各所述隐状态表示数据确定所述与用户意图关联的知识库中的实体中直接关联实体;采用解码器对除与用户意图关联的知识库中的实体以外的基于知识的目标文本数据及所述直接关联实体进行解码,形成解码后的文本数据;根据解码后的文本数据和所述词语生成器生成匹配的候选自然语言语句。4.根据权利要求3所述的方法,其特征在于,所述基于知识的语言生成模型还包括协调器;所述词语生成器包括词表生成器和拷贝生成器;所述根据解码后的文本数据和所述词语生成器生成匹配的候选自然语言语句,包括:采用协调器按照解码顺序确定与解码后的文本数据中当前文本数据相匹配的是词表生成器或拷贝生成器;所述解码顺序为所述解码器生成解码后的文本数据的顺序;若确定匹配的是词表生成器,则采用词表生成器根据用户意图搜索结果、用户画像信息、对话动作和槽位信息生成对应的词语;若确定匹配的是拷贝生成器,则采用拷贝生成器根据用户意图搜索结果、所述直接关
联实体、对话动作和槽位信息生成对应的词语;对生成的所有词语进行语义识别处理,以将所有词语拼接组成候选自然语言语句。5.根据权利要求4所述的方法,其特征在于,所述将多个候选自然语言语句输入至预设的协调神经网络模型,以输出综合评分最高的目标自然语言语句,包括:将多个候选自然语言语句输入预设的协调神经网络模型;采用所述协调神经网络模型按照预设的评测策略对多个候选自然语言语句进行综合评分,并输出综合评分最高的目标自然语言语句。6.根据权利要求5所述的方法,其特征在于,所述采用所述协调神经网络模型按照预设的评测策略对多个候选自然语言语句进行综合评分,包括:采用所述协调神经网络模型计算各候选自然语言语句对应的困惑度,并对各候选自然语言语句进行语义分析,以获得语义分析结果;根据各候选自然语言语句对应的困惑度及语义分析结果确定各候选自然语言语句的综合评分。7.根据权利要求6所述的方法,其特征在于,所述将多个候选自然语言语句输入至预设的协调神经网络模型之前,还包括:将多个候选自然语言语句输入预设的语言模型,以确定各所述候选自然语言语句对应的困惑度;判断各所述困惑度是否小于预设的困惑度阈值;若确定所述困惑度小于预设的困惑度阈值,则保留该困惑度对应的候选自然语言语句;若确定所述困惑度大于或等于预设的困惑度阈值,则删除该困惑度对应的候选自然语言语句。8.根据权利要求6所述的方法,其特征在于,所述将多个候选自然语言语句输入至预设的协调神经网络模型之前,还包括:判断各所述候选自然语言语句中相同词语的数量是否大于或等于预设的数量阈值;若确定相同词语的数量小于预设的数量阈值,则保留对应的候选自然语言语句;若确定相同词语的数量大于或等于预设的检测阈值,则删除对应的候选自然语言语句。9.根据权利要求3所述的方法,其特征在于,所述采用基于知识的语言生成模型及基于知识的目标文本数据生成对应的候选自然语言语句之前,还包括:获取训练样本,所述训练样本中包括:历史用户意图搜索结果、历史与用户意图关联的知识库中的实体、历史对话动作、历史用户画像信息和历史槽位信息;将所述训练样本输入到预设基于知识的语言生成模型中,以对所述预设基于知识的语言生成模型进行训练;采用预设的选择知识损失函数以及预设的生成回复损失函数判断所述预设基于知识的语言生成模型是否满足收敛条件;当预设的选择知识损失函数与预设的生成回复损失函数的和达到最小时,确定所述预设基于知识的语言生成模型满足收敛条件;将满足收敛条件的预设基于知识的语言生成模型确定为训练至收敛的基于知识的语
言生成模型。10.一种自然语言生成装置,其特征在于,包括:获取模块,用于获取目标用户交互信息;确定模块,用于根据目标用户交互信息确定生成候选自然语言语句所依赖的候选文本数据,所述候选文本数据包括多个候选字段;分类模块,用于采用预设的判别神经网络模型对所述候选文本数据中的多个候选字段进行分类,以确定与每个预设的语言生成神经网络模型匹配的多个目标字段,所述多个目标字段形成目标文本数据;生成模块,用于采用各预设的语言生成神经网络模型及匹配的目标文本数据生成对应的候选自然语言语句;输出模块,用于将多个候选自然语言语句输入至预设的协调神经网络模型,以输出综合评分最高的目标自然语言语句。11.一种电子设备,其特征在于,包括:存储器,处理器;存储器;用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为由所述处理器执行如权利要求1至9任一项所述的自然语言生成方法。12.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如权利要求1至9任一项所述的自然语言生成方法。13.一种计算机程序产品,包括计算机程序,其特征在于,该计算机程序被处理器执行时实现权利要求1至9任一项所述的自然语言生成方法。
技术总结
本发明实施例提供一种自然语言生成方法、装置、设备、介质及产品,该方法通过采用预设的判别神经网络模型对候选文本数据中的多个候选字段进行分类,以确定与每个预设的语言生成神经网络模型匹配的多个目标字段。然后采用各预设的语言生成神经网络模型及匹配的目标文本数据生成对应的候选自然语言语句,将多个候选自然语言语句输入至预设的协调神经网络模型,以输出综合评分最高的目标自然语言语句,从而解决了基于神经网络的自然语言生成方式生成的自然语言质量较低的问题。生成的自然语言质量较低的问题。生成的自然语言质量较低的问题。
技术研发人员:徐泽坤 岳文浩
受保护的技术使用者:海信视像科技股份有限公司
技术研发日:2021.11.17
技术公布日:2022/3/25
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。