1.本发明属计算机视觉、自然语言处理技术领域,具体涉及一种基于注意力机制的自然语言视觉推理方法。
背景技术:
2.指称表达式理解是指在图像中定位自然语言描述的对象区域。即:输入一张图片(包含人或其他对象),输入一句可识别图中某个特定对象的自然语言描述(指称表达式),描述是英文的单词、短语或一句话,可包含对象的类别、位置、颜色、大小以及与周围对象的关系等属性。要求在图片中定位所描述对象的区域(用边界框框出对象并分割)。指称表达式理解是一项有意义的任务,它可以运用到图像检索中,比如在图片库中查找具有特定属性的对象。另外,指称表达式理解也是机器了解现实世界并像人类一样与人交流的一项重要技术,可以运用到现代化智能设备视觉理解和对话系统中。
3.j.mao等人在文献“j.mao,j.huang,a.toshev,o.camburu,l.yuille,and k.murphy,“generation and comprehension of unambiguous object descriptions,”proc.ieee conference on computer vision and pattern recognition(cvpr),pp.11-20,2016.”中使用长短时记忆网络lstm结构来建立概率模型p(r|o),并寻找概率最大化的对象o。首先生成一组候选区域,然后根据概率对这些候选区域进行排名。rohrbach等人在文献“rohrbach,m.rohrbach,r.hu,t.darrell,and b.schiele,“grounding of textual phrases in images by reconstruction,”proc.european conference on computer vision(eccv),pp.817-834,2016.”中采用联合嵌入模型来直接计算p(r|o),使用双视图神经网络学习图像-文本嵌入,图像-文本表示的后面接着两个非线性层,这些表示可通过两个预训练的网络和现成的特征提取网络来获取。结合以上两种方法,l.yu等人在文献“l.yu,h.tan,m.bansal,and l.berg,“a joint speaker-listener-reinforcer model for referring expressions,”proc.ieee conference on computer vision and pattern recognition(cvpr),pp.7282-7290,2017.”提出了一种将cnn-lstm和嵌入模型相结合的模型以获得更好的表现。该模型可以联合学习cnn-lstm的“说话者”模型和基于嵌入的“听者”模型,用于指称表达式的生成和理解任务。此外还添加了一个基于奖励的鉴别增强器以指导更具有区分性的指称表达式的采样,进一步改进了系统。该模型不是独立工作的,而是让“说话者”、“听者”和“强化者”相互作用,从而提高生成和理解任务的性能。但该方法对指称表达式上下文信息理解不足,导致最终的定位结果不准确。
技术实现要素:
4.为了克服现有技术对指称表达式上下文信息理解不足或不准确的问题,本发明提供一种基于注意力机制的自然语言视觉推理方法。主要包括一个语言注意力网络模块和三个视觉处理模块,首先,输入语言表达式,利用one-hot编码、bilstm编码等对其进行处理,并据此计算得到三个视觉处理模块用的短语嵌入表示和权重;然后,利用mask r-cnn检测
器对输入图像进行目标检测,以检测得到的目标作为图像的候选对象,并将其分别输入到主语模块、位置模块和关系模块,每个模块分别计算得到相应的匹配得分;最后,计算三个模块匹配得分的加权和作为总体匹配得分,以总体匹配得分最高的候选对象作为语言表达式描述的对象,输出其位置框,完成图像的视觉推理。本发明采用端到端的模块化网络,每个模块都能通过学习关注到应该关注的单词,具有更好的上下文信息理解力,且可以自适应输入的指称表达式,能够处理多种结构的表达式。
5.一种基于注意力机制的自然语言视觉推理方法,其特征在于步骤如下:
6.步骤1:采用one-hot编码将输入语言表达式中的每个单词编码到嵌入表示向量e
t
中,再使用bilstm编码每个单词的上下文,将得到的前后两个方向上的隐藏向量相连接,得到每个单词的隐藏表示向量h
t
,t表示表达式中的单词序号,t=1,2,...,t,t表示表达式包含的单词个数;
7.步骤2:按照下式计算得到不同模块对每个单词的关注度:
[0008][0009]
其中,m∈{sub,loc,rel},m=sub表示主语模块,m=loc表示位置模块,m=rel表示关系模块,a
m,t
表示模块m对第t个单词的关注度,fm表示模块m可训练的向量;
[0010]
按下式计算单词嵌入表示向量的加权和,作为每个模块的短语嵌入表示向量:
[0011][0012]
其中,qm表示模块m的短语嵌入;
[0013]
步骤3:连接第一个单词和最后一个单词的隐藏表示向量,使用一个全连接层将其转换成三个模块的权重,具体如下:
[0014][0015]
其中,w
sub
表示主语模块的权重,w
loc
表示位置模块的权重,w
rel
表示关系模块的权重,softmax(
·
)表示归一化指数函数,用于计算每个模块的权重,wm表示每个模块对单词的关注度;h1表示语言表达式中第一个单词的隐藏表示向量,h
t
表示最后一个单词的隐藏表示向量,bm表示偏置;
[0016]
步骤4:利用mask r-cnn检测器对输入图像进行目标检测,以检测得到的目标作为图像的候选对象;其中,采用残差网络作为mask r-cnn检测器的特征提取网络;
[0017]
步骤5:将残差网络conv3_x模块输出的特征c3和conv4_x模块输出的特征c4通过1
×
1的卷积合并得到主语特征,将主语特征输入到主语模块中的属性预测分支,得到预测的属性;
[0018]
将主语特征划分成14
×
14的空间网格,再计算主语模块的短语嵌入表示向量与每个网格的相似度,此过程的计算表达式如下:
[0019]
ha=tanh(wvv wqq
sub
)
ꢀꢀꢀꢀ
(4)
[0020][0021]
其中,ha表示空间网格上主语模块的短语嵌入,tanh(
·
)表示tanh激活函数,wv表示空间网格的权重;wq表示主语模块对每个单词的关注度;v表示空间网格的特征;w
h,a
表示网格上每个单词的权重;av表示网格的注意力值;
[0022]
按下式计算空间网格特征v的各个分量vi的加权和,得到候选对象的视觉表示向量:
[0023][0024]
其中,表示候选对象i的主语视觉表示,表示第i个网格上的注意力值,vi表示第i个网格的特征,g表示网络数量;
[0025]
计算视觉表示向量和短语嵌入表示向量q
sub
之间的相似度,以相似度值作为主语模块的匹配得分,其计算表达式为:
[0026][0027]
其中,oi表示第i个候选对象,s(oi|q
sub
)表示第i个候选对象的主语的视觉表示和主语短语嵌入的匹配分数,f(
·
)表示匹配函数,由两个多层感知机和l2正则化构成;
[0028]
步骤6:将候选对象位置的视觉表示和位置短语嵌入输入到位置模块,首先采用5维向量编码候选对象的左上角位置、右下角位置以及与图像的相对面积:
[0029][0030]
其中,li表示第i个候选对象的绝对位置的视觉表示,i=1,2,...,n,n是mask r-cnn检测器检测识别出的候选对象个数,表示第i个候选对象边界框左上角的横坐标值,表示第i个候选对象边界框左上角的纵坐标值,表示第i个候选对象边界框右下角的横坐标值,表示第i个候选对象边界框右下角的纵坐标值,wi表示第i个候选对象的边界框的宽,hi表示第i个候选对象的边界框的高,w表示输入图像的宽,h表示输入图像的高;
[0031]
然后,通过计算偏移量和面积比来编码候选对象的相对位置表示:
[0032][0033]
其中,δl
ij
表示第i个候选对象和第i个候选对象的相对位置表示,i,j=1,2,...,n,[δx
tl
]
ij
表示第i个候选对象和第j个候选对象的边界框左上角的横坐标值之差的绝对值,[δy
tl
]
ij
表示第i个候选对象和第j个候选对象的边界框左上角的纵坐标值之差的绝对值,[δx
br
]
ij
表示第i个候选对象和第j个候选对象的边界框右下角的横坐标值之差的绝对值,[δy
br
]
ij
表示第i个候选对象和第j个候选对象的边界框右下角的纵坐标值之差的绝对值,wj表示第j个候选对象的边界框的宽,hj表示第j个候选对象的边界框的高;
[0034]
候选对象的位置表示向量为:
[0035][0036]
最后,计算候选对象的位置表示向量和短语嵌入表示向量q
loc
之间的相似度,以相似度值作为位置模块的匹配得分,其计算表达式为:
[0037][0038]
其中,s(oi|q
loc
)表示第i个候选对象的位置的视觉表示和位置短语嵌入的匹配分数;
[0039]
步骤7:将候选对象关系的视觉表示和关系短语嵌入输入到关系模块,首先编码周围对象到候选对象的相对位置表示:
[0040][0041]
其中,δm
ij
表示第i个候选对象和其第j个周围对象的相对位置表示,每个候选对象有8个周围对象,周围对象是指与候选对象欧氏距离最小的候选对象,i=1,2,...,n,j=1,2,...,8,[δx
tl
]
ij
表示第i个候选对象和其第j个周围对象的边界框左上角的横坐标值之差的绝对值,[δy
tl
]
ij
表示第i个候选对象和其第j个周围对象的边界框左上角的纵坐标值之差的绝对值,[δx
br
]
ij
表示第i个候选对象和其第j个周围对象的边界框右下角的横坐标值之差的绝对值,[δy
br
]
ij
表示第i个候选对象和其第j个周围对象的边界框右下角的纵坐标值之差的绝对值,wj表示第j个周围对象的边界框的宽,hj表示第j个周围对象的边界框的高;
[0042]
然后,按下式计算每个候选对象和其周围对象的关系视觉表示:
[0043][0044]
其中,表示第i个候选对象和其第j个周围对象的关系的视觉表示,wr(
·
)表示关系模块的权重;v
ij
表示第i个候选对象的第j个周围对象的特征c4,br表示关系模块的偏置;
[0045]
最后,计算每个候选对象和其周围对象的关系视觉表示与短语嵌入表示向量q
rel
之间的相似度,以最大相似度值作为关系模块的匹配得分,即:
[0046][0047]
其中,s(oi|q
rel
)表示第i个候选对象和其周围对象的关系视觉表示和关系短语嵌入的匹配分数;
[0048]
步骤8:按照下式计算得到每个候选对象的总体匹配得分si:
[0049]
si=w
sub
×
s(oi|q
sub
) w
loc
×
s(oi|q
loc
) w
rel
×
s(oi|q
rel
) (15)
[0050]
其中,i=1,2,...,n;
[0051]
以总体匹配得分最高的候选对象作为语言表达式描述的对象,输出其位置框,完成图像的视觉推理。
[0052]
本发明的有益效果是:(1)上下文信息理解更准确。本发明采用端到端的模块化网络,具备更细粒度的单词权重分配能力,每个模块都能通过学习关注到应该关注的单词,使模型具有更好的理解力。(2)不过于依赖于外部语言解析器。本发明设计的语言解析网络可以自适应输入的指称表达式,所受的局限性较小,可处理多种结构的表达式。
附图说明
[0053]
图1是本发明基于注意力机制的自然语言视觉推理方法流程图;
[0054]
图2是采用本发明方法得到的推理结果图像;
[0055]
其中,(a)-输入的指称表达式,(b)-输入的原始图像,(c)-本发明得到的推理结果图像。
具体实施方式
[0056]
下面结合附图和实施例对本发明进一步说明,本发明包括但不仅限于下述实施例。
[0057]
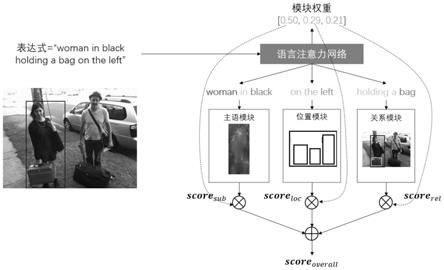
如图1所示,本发明提供了一种基于注意力机制的自然语言视觉推理方法,主要包括一个语言注意力网络模块和三个视觉处理模块,其具体实现过程如下:
[0058]
1、语言注意力网络模块
[0059]
(1)采用one-hot编码将输入语言表达式中的每个单词编码到嵌入表示向量et中,再使用bilstm编码每个单词的上下文,将得到的前后两个方向上的隐藏向量相连接,得到每个单词的隐藏表示向量h
t
,t表示表达式中的单词序号,t=1,2,...,t,t表示表达式包含的单词个数;
[0060]
(2)按照下式计算得到不同模块对每个单词的关注度:
[0061][0062]
其中,m∈{sub,loc,rel},m=sub表示主语模块,m=loc表示位置模块,m=rel表示关系模块,a
m,t
表示模块m对第t个单词的关注度,fm表示模块m可训练的向量;
[0063]
按下式计算单词嵌入表示向量的加权和,作为每个模块的短语嵌入表示向量:
[0064][0065]
其中,qm表示模块m的短语嵌入;
[0066]
(3)连接第一个单词和最后一个单词的隐藏表示向量,使用一个全连接层将其转换成三个模块的权重,具体如下:
[0067][0068]
其中,w
sub
表示主语模块的权重,w
loc
表示位置模块的权重,w
rel
表示关系模块的权重,softmax(
·
)表示归一化指数函数,用于计算每个模块的权重,wm表示每个模块对单词的关注度;h1表示语言表达式中第一个单词的隐藏表示向量,h
t
表示最后一个单词的隐藏表示向量,bm表示偏置;
[0069]
2、输入图像目标检测
[0070]
利用mask r-cnn检测器对输入图像进行目标检测,以检测得到的目标作为图像的候选对象;其中,采用残差网络作为mask r-cnn检测器的特征提取网络。
[0071]
3、主语模块
[0072]
将残差网络conv3_x模块输出的特征c3和conv4_x模块输出的特征c4通过1
×
1的卷积合并得到主语特征,将主语特征输入到主语模块中的属性预测分支,得到预测的属性;
[0073]
将主语特征划分成14
×
14的空间网格,再计算主语模块的短语嵌入表示向量与每个网格的相似度,此过程的计算表达式如下:
[0074]
ha=tanh(wvv wqq
sub
)
ꢀꢀꢀ
(19)
[0075][0076]
其中,ha表示空间网格上主语模块的短语嵌入,tanh(
·
)表示tanh激活函数,wv表示空间网格的权重;wq表示主语模块对每个单词的关注度;v表示空间网格的特征;w
h,a
表示网格上每个单词的权重;av表示网格的注意力值;
[0077]
按下式计算空间网格特征v的各个分量vi的加权和,得到候选对象的视觉表示向量:
[0078][0079]
其中,表示候选对象i的主语视觉表示,表示第i个网格上的注意力值,vi表示第i个网格的特征,g表示网络数量;
[0080]
计算视觉表示向量和短语嵌入表示向量q
sub
之间的相似度,以相似度值作为主语模块的匹配得分,其计算表达式为:
[0081][0082]
其中,oi表示第i个候选对象,s(oi|q
sub
)表示第i个候选对象的主语的视觉表示和主语短语嵌入的匹配分数,f(
·
)表示匹配函数,由两个多层感知机和l2正则化构成;
[0083]
4、位置模块
[0084]
将候选对象位置的视觉表示和位置短语嵌入输入到位置模块,首先采用5维向量编码候选对象的左上角位置、右下角位置以及与图像的相对面积:
[0085][0086]
其中,li表示第i个候选对象的绝对位置的视觉表示,i=1,2,...,n,n是mask r-cnn检测器检测识别出的候选对象个数,表示第i个候选对象边界框左上角的横坐标值,表示第i个候选对象边界框左上角的纵坐标值,表示第i个候选对象边界框右下角的横坐标值,表示第i个候选对象边界框右下角的纵坐标值,wi表示第i个候选对象的边界框的宽,hi表示第i个候选对象的边界框的高,w表示输入图像的宽,h表示输入图像的高;
[0087]
然后,通过计算偏移量和面积比来编码候选对象的相对位置表示:
[0088][0089]
其中,δ
lij
表示第i个候选对象和第i个候选对象的相对位置表示,i,j=1,2,...,n,[δx
tl
]
ij
表示第i个候选对象和第j个候选对象的边界框左上角的横坐标值之差的绝对值,[δy
tl
]
ij
表示第i个候选对象和第j个候选对象的边界框左上角的纵坐标值之差的绝对值,[δx
br
]
ij
表示第i个候选对象和第j个候选对象的边界框右下角的横坐标值之差的绝对值,[δy
br
]
ij
表示第i个候选对象和第j个候选对象的边界框右下角的纵坐标值之差的绝对值,wj表示第j个候选对象的边界框的宽,hj表示第j个候选对象的边界框的高;
[0090]
候选对象的位置表示向量为:
[0091][0092]
最后,计算候选对象的位置表示向量和短语嵌入表示向量q
loc
之间的相似度,以相似度值作为位置模块的匹配得分,其计算表达式为:
[0093][0094]
其中,s(oi|q
loc
)表示第i个候选对象的位置的视觉表示和位置短语嵌入的匹配分数;
[0095]
5、关系模块
[0096]
将候选对象关系的视觉表示和关系短语嵌入输入到关系模块,首先编码周围对象到候选对象的相对位置表示:
[0097][0098]
其中,δm
ij
表示第i个候选对象和其第j个周围对象的相对位置表示,每个候选对象有8个周围对象,周围对象是指与候选对象欧氏距离最小的候选对象,i=1,2,...,n,j=1,2,...,8,[δx
tl
]
ij
表示第i个候选对象和其第j个周围对象的边界框左上角的横坐标值之差的绝对值,[δy
tl
]
ij
表示第i个候选对象和其第j个周围对象的边界框左上角的纵坐标值之差的绝对值,[δx
br
]
ij
表示第i个候选对象和其第j个周围对象的边界框右下角的横坐标值之差的绝对值,[δy
br
]
ij
表示第i个候选对象和其第j个周围对象的边界框右下角的纵坐标值之差的绝对值,wj表示第j个周围对象的边界框的宽,hj表示第j个周围对象的边界框的高;
[0099]
然后,按下式计算每个候选对象和其周围对象的关系视觉表示:
[0100][0101]
其中,表示第i个候选对象和其第j个周围对象的关系的视觉表示,wr(
·
)表示关系模块的权重;v
ij
表示第i个候选对象的第j个周围对象的特征c4,br表示关系模块的偏置;
[0102]
最后,计算每个候选对象和其周围对象的关系视觉表示与短语嵌入表示向量q
rel
之间的相似度,以最大相似度值作为关系模块的匹配得分,即:
[0103][0104]
其中,s(oi|q
rel
)表示第i个候选对象和其周围对象的关系视觉表示和关系短语嵌入的匹配分数;
[0105]
6、计算视觉推理结果
[0106]
按照下式计算得到每个候选对象的总体匹配得分si:
[0107]
si=w
sub
×
s(oi|q
sub
) w
loc
×
s(oi|q
loc
) w
rel
×
s(oi|q
rel
)
ꢀꢀꢀꢀ
(30)
[0108]
其中,i=1,2,...,n;
[0109]
以总体匹配得分最高的候选对象作为语言表达式描述的对象,输出其位置框,完成图像的视觉推理。
[0110]
为验证本发明方法的有效性,在显存11g的1080ti显卡、pytorch框架、ubuntu18操作系统系统上进行仿真实验。实验中使用的数据集是从coco数据集中收集而来的三个公开的指称表达式理解数据集,分别是:refcoco、refcoco 、refcocog。首先,使用coco数据集的子集以及resnet152特征提取网络的预训练模型权重来训练mask r-cnn。设置迭代次数为1250000,学习率为0.001。然后,使用训练得到的mask r-cnn分别提取refcoco、refcoco 、refcocog三个数据集中图片的特征并存入文件。最后,利用本发明方法对提取到的特征进行处理。图1中给出了计算出的三个视觉模块的权重分别为0.5,0.29,0.21,图中,score
sub
表示主语模块的匹配得分,score
loc
表示位置模块的匹配得分,score
rel
表示关系模块的匹配得分,score
overall
表示总体匹配得分。图2给出了其中一幅图像的推理结果,可以证明,在
指称表达式理解任务中本发明对上下文语义信息理解的准确性和有效性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
