基于改进的注意力机制fairmot多类别跟踪方法
技术领域
1.本发明涉及计算机视觉中多目标追踪领域,具体属于一种对无人机视频进行多类别多目标追踪的方法。
背景技术:
2.随着智慧城市的建设,日益密集的摄像头分布使得我国的视频监控系统逐渐变得成熟化和产业化,视频数据的急剧增加,使得当前的高性能数据分析技术逐渐应用在视频监控系统中。当前,无论是在学校、商场、道路和小区等公共区域,还是家庭、办公室等私密性场所,摄像头基本全部覆盖,来保障个人财产安全和社会的有序发展。这些摄像机所起到的作用大多仅限于拍摄监控录像,在监控摄像头的背后,视频监控系统对视频场景内容进行处理和分析,对突发事件进行过程监控并及时存储有效数据,使后台决策系统可以高效地进行指挥调度。然而,视频分析技术中最关键的就是目标的提取与跟踪,目标跟踪就是对视频中的人物、车辆或其它移动的物体进行实时定位,以便工作人员或者视频分析系统能够更好的理解视频内容所能表达的语义信息,做出精准的决策。
3.目标跟踪作为计算机视觉研究领域的热点之一,过去几十年以来,目标跟踪的研究取得了长足的发展。从基于mean shift、粒子滤波和kalman filter的经典跟踪方法,到基于检测(trackby detection)或相关滤波(correlation filter)的方法,到最近几年来出现的深度学习相关方法。每年在几个主要跟踪数据集上的竞赛非常激烈,方法也越来越多。尽管近年来受到了广泛研究,目标跟踪问题本身的高难度、高质量数据的稀少,研究热度比目标检测、语义分割等基本视觉任务略低一些。深度学习的发展和gpu计算能力的增强带来了视觉算法性能的突飞猛进,而在目标跟踪领域中基于深度神经网络的方法在近几年逐渐成为众多研究学者研究的主要方向。
4.无人驾驶飞机简称“无人机”,英文缩写为“uav”,是利用无线电遥控设备和自备的程序控制装置操纵的不载人飞机。无人机按照应用领域,可分为军用与民用。军用方面,无人机分为侦察机和靶机。民用方面,无人机 行业应用,是无人机真正的刚需。目前无人机在航拍、农业、植保、微型自拍、快递运输、灾难救援、观察野生动物、监控传染病、测绘、新闻报道、电力巡检、救灾、影视拍摄、制造浪漫等等领域的应用,大大的拓展了无人机本身的用途。
5.近几年来,随着科技有限公司等无人机研发公司在民用无人机上的不断创新与研发,性能优越,价格亲民的无人机开始走进日常生活。现在可以使用无人机进行无接触快递配送、图像视频拍摄、航拍以及灾难救援等等。智能化的无人机在的日常生活中扮演越来越多的角色,给生活带来了极大的便利。更好的将无人机的优势与基于卷积神经网络的目标追踪算法进行结合,将会给生活质量带来巨大的改变和提升。
6.虽然无人机的飞行性能与拍摄性能得到很大的提升,但是基于卷积神经网络的目标追踪算法对无人机拍摄的视频进行追踪时却面临着一些困难和挑战需要去克服。因为无人机拍摄的视频存在着目标尺寸小、密度大,以及无人机在飞行的过程中存在镜头的旋转
以及抖动等情况,导致拍摄出来的视频序列给当前的基于卷积神经网络的目标追踪算法的追踪准确性带来了极大的挑战。
技术实现要素:
7.本发明旨在解决上述问题,在现有多目标追踪算法fairmot的基础上提出了一种基于改进的注意力机制fairmot多类别跟踪方法。本发明可以充分利用无人机拍摄的视频,通过引入通道和空间注意力机制的多目标多类别目标追踪算法,对无人机拍摄的视频序列中存在的目标进行追踪及其运动轨迹可视化显示。
8.为了达到上述目的,本发明采用的技术方案以及实验步骤如下:
9.(1)首先对无人机数据集进行预处理。
10.公开的用于目标追踪的无人机数据集主要有两个,一个是visdrone系列公开数据集,还有一个是uavdt公开数据集。实验是在visdrone2019和uavdt这两个公开的无人机数据集上进行训练和测试的。
11.(1a)首先要对无人机数据集的标签进行转换,因为设计一种不仅仅局限于某一单一类别而是能够对多个类别同时进行追踪的算法,因此首先需要对上述两个无人机数据集进行标签转换以统一各个类别的标签。在原始的数据集中,uavdt数据集一共有3个类别:0号类别代表car类,1号类别代表truck类,2号类别代表bus类;visdrone2019数据集一共有12个类别:0号类别代表ignore regions,1号类别代表pedestrian类,2号类别代表people类,3号类别代表bicycle类,4号类别代表car类,5号类别代表van类,6号类别代表truck类,7号类别代表tricycle类,8号类别代表awning-tricycle类,9号类别代表bus类,10号类别代表motor类,11号类别代表others类。通过标签转换统一数据集的car类标签为3,truck类标签为5,bus类标签为8,其余类别标签在原标签基础上减1,ignore region类和others类被剔除。
12.(1b)由于uavdt数据集缺少专门的测试数据集,在整个数据集中随机选取了七个序列(约占整个数据集的30%)作为的测试数据集,这些序列为:m0204、m0208、m0402、m0702、m1005、m1008以及m1302。
13.(1c)为了降低图像中的模糊区域或存在严重遮挡的目标对实验训练效果的影响,根据数据集的原始标签中每个目标的遮挡程度对数据集中遮挡严重的目标或区域进行了遮罩预处理(类似于数据增强中的cutout),这样做不仅可以提升模型的鲁棒性而且还有助于加快模型训练的收敛速度。
14.(2)构建模型
15.在对数据进行预处理之后,接下来就是构建网络模型。网络模型主要由三部分构成,依次是:加入了卷积注意力机制模块(convolutional block attention module,cbam)的encoder-decoder骨干网络、目标检测分支(object detection branch)以及重识别分支(re-id branch)。
16.(2a)encoder-decoder骨干网络由添加cbam的dla34-base卷积神经网络、dlaup特征融合模块和idaup特征融合模块组成,其主要作用就是对输入的图像数据进行特征提取,获得输入图像的空间信息和语义信息,且在准确率和速度之间保持一个较好的平衡。
17.(2b)添加cbam的dla34-base卷积神经网络通过在卷积神经网络中引入空间注意
力机制和通道注意力机制,使卷积神经网络的特征提取性能得到较大的提升,为后边的目标检测和重识别分支提供更加可靠的特征图。
18.(2c)dlaup特征融合模块的主要作用是将骨干网络中不同模块间的特征进行融合,作用类似于resnet的残差连接,这种操作可以提升网络的表达能力,降低随着网络深度的增加出现的网络“退化”问题。
19.(2d)idaup特征融合模块的主要作用是将骨干网络中不同层级间的特征进行融合,类似于densenet的connection连接。
20.(2e)目标检测分支是建立在centernet之上的,主要负责对骨干网络输出的特征图进行目标检测,该分支由三个平行的检测头组成,这三个检测头分别为heatmap检测头,box size检测头以及center offset检测头。在的模型中,heatmap检测头、box size检测头以及center offset检测头使用的是ttfnet算法中的heatmap检测头与wh检测头,分别用来预测骨干网络输出的特征图中目标的中心点以及目标的边界框,center offset检测头则为本模型新添加的检测头,其结构同上述两个检测头一样,主要用来预测目标中心点的偏移量。
21.(2f)重识别分支的主要作用是根据目标检测分支检测到的目标中心点位置,到骨干网络中提取该目标的re-id表征特征,再通过匈牙利算法和卡尔曼滤波算法,将相邻帧之间的同一目标进行匹配,为它们分配相同的id值,进而形成其在连续图像序列中连贯的追踪轨迹。
22.(3)训练网络
23.数据和模型分别处理好之后开始进行训练。训练过程主要分为四步,即数据加载与增强、骨干网络的训练、目标检测分支的训练、重识别分支的训练。
24.(3a)首先加载数据并对数据进行增强。因为数据集是连续的视频序列抽取的帧,相邻的两帧之间存在着极高的相似度,如果按照正常的数据加载顺序加载数据并进行训练,那么提取到的特征的随机性很小,这样很有可能导致模型的收敛速度减慢或者陷入局部最优解的困扰。因此在本实验中,参照mcmot算法的数据增强方法,预先为数据集设定了多组不同宽高的尺寸作为输入图像的缩放尺度,在加载数据的过程中随机选择预设尺度中的一组,将图像缩放到该指定尺寸之后再输入骨干网络,这样做的好处是使输入的图像具有不同的尺度,这样不仅可以提升模型对于物体尺度变化的鲁棒性,而且能够提升整个模型的特征提取能力。
25.(3b)对骨干网络的训练。骨干网络主要由加入了cbam的dla34-base网络、dlaup特征融合模块和idaup特征融合模块构成。dlaup特征融合模块与idaup特征融合模块与fairmot模型中相同,而dla-34网络中在原网络的level0层之前与level5层之后分别添加了一个cbam注意力模块,这种注意力模块可以在通道和空间维度上进行attention,在level0层之前和level5层之后添加注意力模块既可以保证的模型能够使用预训练的权重又能将注意力机制引入的模型。通过将注意力机制引入的模型,图像数据能够在骨干网络中保持丰富的空间信息和语义信息,以供后边的目标检测分支和行人重识别分支使用。在骨干网络的训练中,加载使用fairmot算法的预训练权重,将数据增强后的图像输入网络中,通过网络提取图像中丰富的特征信息,作为后续分支的输入数据。
26.(3c)对目标检测分支的训练。
27.目标检测分支的训练主要是将骨干网络输出的特征图作为本分支的输入,通过不同的检测头完成目标中心点、目标边界框以及目标中心点偏移量的预测。该分支主要由heatmap检测头、center offset检测头和box size检测头三个平行检测头构成。
28.heatmap检测头分支主要负责估计对象中心的位置,这里采用的是基于热图的表示法,热图的尺寸为1
×h×
w,随着热图中位置和对象中心之间的距离,响应呈指数衰减。需要注意的是不同通道的heatmap能够预测不同的类别,即在car类对应通道的heatmap中,只负责估计car这一类对象的中心点的位置,而在的实验中,共有10类数据,因此在实验中设置heatmap检测头的输出通道数为10,即heatmap检测头输出的数据的尺度为10
×h×
w。center offset检测头分支主要负责更精准地定位对象,re-id功能与对象中心的对齐精准度对于性能至关重要。box size检测头分支主要负责估计每个锚点位置的目标边界框的高度和宽度,与re-id功能没有直接关系,但是其精度将影响对象检测性能的评估。
29.目标检测分支的主要训练流程是将骨干网络提取到的特征图传给目标检测分支的三个检测头,在heatmap检测头中每个通道的heatmap对特征图中可能存在的本类目标的中心点位置进行预测,以此预测当前特征图中该类别目标的个数及其中心点位置,然后将预测结果与真实标签的heatmap值进行比较,使用变形的focal loss损失函数求得heatmap检测头的损失值;center offset检测头负责更精确地定位对象,该检测头根据输入的特征图预测目标的中心点的偏移量,并将预测的结果与真实标签中目标的中心点位置进行比较,通过l1 loss损失函数计算中心点偏移量的损失值,作为center offset检测头的损失值;box size检测头负责根据特征图估计每个锚点处目标边界框的高度和宽度,通过将预测的高度和宽度与真实标签中的高度和宽度进行比较,通过l1 loss损失函数计算目标边框尺寸的损失值,作为box size检测头的损失值。在得到上述三个检测头的损失值后,通过求和计算出目标检测分支总损失值l
detection
,以便后续使用。
30.(3d)对重识别分支的训练。
31.重识别分支旨在生成能够区分不同目标的特性。理想情况下,不同目标之间的亲和力应该小于相同目标之间的亲和力。为了实现这一目标,应用了128个内核的卷积层在骨干特征之上提取每个目标的re-id特征。表示得到的特征映射为e∈r
128
×w×h,从特征映射中可以提取以(x,y)为中心的目标的re-id特征e
x,y
∈r
128
。将得到的特征映射与标签中真实目标的特征映射进行比较,通过交叉熵损失函数计算得到行人重识别分支的损失值,以便后续使用。
32.(3e)反向传播进行网络权重更新
33.根据目标检测分支与行人重识别分支得到的损失值,按照预设的不同的权重值将两个模块得到的损失值加权求和并加上权重作为整个模型的损失值进行反向传播,以此来调整优化网络中的参数值。
34.(4)多类别多目标追踪算法的性能评估
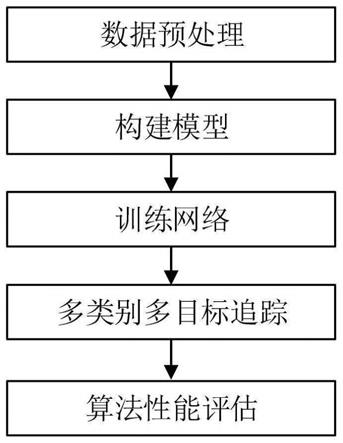
35.模型训练完成之后进行测试。在测试过程中,将每一帧追踪到的目标的详细信息保存在一个txt文件中,然后根据这个txt文件中的信息,将追踪到的目标可视化,包含其所属类别、边界框、目标的id值以及显示其在连续图像序列中运动过的轨迹。此外通过将该txt追踪结果与真实标签进行比对,计算出追踪算法的相关评价指标的结果。
附图说明
36.图1是本发明的流程图。
37.图2是本发明的整体网络结构图。
38.图3是添加了cbam的dla-34骨干网络结构图。
39.图4是dla34-base骨干网络结构图。
40.图5是dla的设计思路图
41.图6是卷积模块的注意力机制模块(cbam)的网络结构图
42.图7是cbam中的通道注意力模块的网络结构图。
43.图8是cbam中的空间注意力模块的网络结构图。
44.图9是特征融合模块中dlaup特征融合模块结构图
45.图10是特征融合模块中idaup特征融合模块结构图。
46.图11是目标检测模块的结构图。
47.图12是重识别模块的结构图。
48.图13是各模型在uavdt测试数据集上追踪效果的可视化效果图。
49.图14是各模型在visdrone2019测试数据集上追踪效果的可视化效果图。
具体实施方式
50.下面结合附图对本发明做进一步的描述。
51.参照附图1,本发明的实验步骤如下所示:
52.步骤1,数据预处理
53.(1)统一两个数据集的标签
54.visdrone2019无人机数据集一共有11个类别,uavdt无人机数据集一共有3个类别,为了后续实验方便,将uavdt数据集中每个类别的序号转换与visdrone2019中的类别的序号一致。
55.(2)提取uavdt数据集的测试集
56.由于uavdt数据集缺少测试用的测试集,因此在对uavdt数据集进行类别标签转换后随机选取了数据集中的8个序列作为测试数据集,这些序列具体为:m0204、m0208、m0402、m0702、m1005、m1008以及m1302,数据量约占整个数据集的30%。
57.(3)对图像进行遮罩处理
58.因为无人机数据集图像具有目标小的特点,因此在图像序列中有的目标存在着严重遮挡取的情况,且部分模糊区域的目标并未进行正确的标注,因此为了降低遮挡和模糊区域对训练过程造成不必要的影响,根据数据集的真实标签分别对原始图像及标签进行遮罩和过滤处理,将图像中遮挡严重的目标用黑块遮挡起来,对遮挡严重的目标的标签进行剔除。这种操作类似于数据增强中的cutout方法,好处就是减少不确定目标对象对模型训练的干扰,一定程度上可以加快模型的收敛速度。
59.步骤2,构建模型
60.模型主要由三部分组成,分别是:encoder-decoder骨干网络、目标检测分支和行人重识别分支。
61.参照附图2,encoder-decoder骨干网络的主要功能是将输入的原始图像通过卷积
神经网络将该图像中包含的空间信息以及语义信息提取成固定尺寸的特征图,供目标检测分支和行人重识别分支使用。假设输入图像的尺寸是h
image
×wimage
,那么输出的特征图的尺寸是c
×h×
w,这里的h=h
image
/4,w=w
image
/4。的encoder-decoder骨干网络也可以分为三个部分,分别为:加入了cbam的dla34-base网络、dlaup特征融合模块和idaup特征融合模块。
62.参照附图3,的cbam dla34-base网络是在原dla34-base网络的基础上通过添加cbam注意力机制得到的。dla的全称是deep layer aggregation,被centernet,fairmot等框架所采用,其效果很不错,准确率和模型复杂度平衡的也比较好。其网络结构如附图4所示,该结构能够迭代式的将网络结构的特征信息融合起来,让模型有更高的精度和更少的参数。附图5展示了dla的设计思路,dense connection来自densenet,可以聚合语义信息(在通道方向进行的聚合,能够提高模型推断“是什么”的能力(what))。feature pyramids空间特征金字塔可以聚合空间信息(在分辨率和尺度方向的融合,能够提高模型推断“在哪里”的能力(where))。dla则可以将两者更好地结合起来从而可以更好的获取what和where的信息。
63.虽然dla可以很好的将两者更好地结合起来,但是发现dla的骨干网络共有七层,随着网络深度的增加,特征在传递的过程中难免会产生损失,因此在dla34-base网络中引入了cbam注意力机制,如附图3所示,加入了cbam注意力机制的dla34-base网络。
64.cbam是一种用于前馈神经网络的简单而有效的注意力模块。给定一个中间特征图,cbam模块能够沿着通道和空间两个独立的维度依次推断注意力图,然后将注意力图与输入特征图相乘而进行自适应特征优化。如附图6所示是添加了cbam模块后的整体结构。通过观察该结构图,可以看到,卷积层输出的结果会先通过一个通道注意力模块,得到加权结果之后,会再经过一个空间注意力模块,最终进行加权得到结果。
65.通道注意力模块网络结构如附图7所示。在该模块中,将输入的特征图分别经过基于宽(width)和高(height)的全局最大池化层(global max pooling)和全局平均池化层(global average pooling),然后分别经过共享全连接层。将共享全连接层输出的特征进行基于元素级(element-wise)的加权操作,再经过sigmoid激活操作,生成最终的通道注意力特征图(channel attention feature map)。将该通道注意力特征图(channel attention feature map)与输入特征图(input feature map)做元素级(element-wise)乘法操作,生成空间注意力(spatial attention)模块需要的特征输入。
66.通道注意力机制是将特征图在空间维度上进行压缩,得到一个一维矢量后再进行操作。在空间维度上进行压缩时,同时考虑到平均池化和最大池化。平均池化和最大池化可用来聚合特征映射的空间信息,送到一个共享网络,压缩输入特征图的空间维数,逐个元素求和合并,以产生通道注意力图。对于一张输入图像而言,通道注意力关注的是这张图上哪些内容是有重要作用的。平均池化对特征图上的每一个像素点都有反馈,最大池化再进行梯度方向传播时,只在特征图中响应最大的地方有梯度的反馈。通道注意力机制可以用公式表示为:
67.68.空间注意力模块网络结构如附图8所示。该模块将通道注意力(channel attention)模块输出的特征图作为本模块的输入特征图,首先对该输入特征图进行一个基于通道的全局最大池化(global max pooling)和全局平均池化(global average pooling),然后将这两个池化后的结果基于通道做叠加(concat)操作。然后经过一个卷积操作,降维为1个通道。最后再经过sigmoid激活函数生成空间注意力特征图(spatial attention feature)。之后将该特征图与该模块最初的输入特征图做乘法,得到最终生成的特征。
69.空间注意力机制是对通道进行压缩,在通道维度分别进行了平均池化和最大池化。最大池化的操作就是在通道上提取最大值,提取的次数是高(height)乘以宽(width);平均池化的造作是在通道上提取平均值,提取的次数和最大池化的次数相同;接着将前面所提取到的特征图(通道数为1)合并到一个通道数为2的特征图。空间注意力机制可以用公式表示为:
[0070][0071]
上述公式中的σ为sigmoid操作,7
×
7表示卷积核的大小,可以选择3
×
3或7
×
7,实验表明7
×
7的卷积核比3
×
3的卷积核效果更好。
[0072]
encoder-decoder骨干网络的第二个构成部分是dlaup特征融合模块,如附图9所示,该模块将dla34-base网络的level3,level4,level5层的输出作为输入,每一个up模块使用两个deformable convolution即dcn可形变卷积并通过convtranspose2d反卷积进行上采样,类似于resnet的残差连接,将不同模块之间的特征融合,最终得到三个输出out[0],out[1],out[2]。
[0073]
encoder-decoder骨干网络的第三个构成部分是idaup特征融合模块,如附图10所示,该模块的up模块中仅包含一个dcn可变性卷积和一个convtranspose2d反卷积。该模块将dlaup的输出out[0],out[1]输入up模块进行处理,得到输出layer[1]和layer[2],然后将dlaup的输出out[2]与layer[2]相加并通过dcn处理,将得到的输出再与layer[1]相加并通过dcn处理,至此得到骨干网络最终的输出结果。其效果如densenet的connection连接,能够将不同层级间的特征融合。
[0074]
参照附图11是目标检测分支的结构图,该分支是在encoder-decoder骨干网络后附加了三个平行的检测头,依次为heatmap检测头、box size检测头及center offset检测头,分别用来预测物体中心的位置、物体边界框的大小和物体中心点的偏移量。下面分别介绍这三个检测头:
[0075]
在模型中,heatmap检测头使用的是ttfnet的heatmap检测头,该头比原模型的头多一个relu层和conv2d层,可以更好的提取输入特征图中的信息。这个检测头主要负责预测物体中心的位置。在原模型中热图的尺寸是1
×h×
w,每一个热图负责估计一类物体中心的位置,因为实验一共有10类,因此在的模型中,heatmap检测头的输出尺寸设为10
×h×
w。
[0076]
对于图像中的每一个真实标签框计算出该目标的中心点坐标这里的然后将中心点坐标除以步幅得到该目标在特征图中的
中心点位置然后坐标(x,y)的热图响应由公式求得,其中n表示该图像中的目标的数量,σc表示标准差。则损失函数定义为像素逻辑回归的focal loss:
[0077][0078]
是估计的热图,α,β是focal loss预定义的参数。
[0079]
在模型中box size检测头使用的是ttfnet模型中wh检测头,其网络结构与上述heatmap检测头的结构相同,相比原模型中的检测头多了一个relu层和conv2d卷积层,可以更好的提取输入特征图中的信息,该检测头主要负责预测目标框在每个位置的高度和宽度。center offset检测头的网络结构与box size检测头一样,旨在更精准地定位对象,由于最终特征图的步幅是4,那么将会带来多达四个像素的量化误差,这个分支估计每个像素相对于目标中心的连续偏移量,以减轻向下采样带来的影响。
[0080]
假设box size检测头和center offset检测头的输出分别为为对于原图像中的每一个真实标签框计算其尺寸其偏移值假设在相应位置估计的尺寸和偏移量分别为和那么对这两个检测头执行l1损失:
[0081][0082]
附图12是重识别分支的结构图。该分支的目的是生成能够区分对象的特征。在实验中使用fairmot原模型的重识别特征提取器,该重识别特征提取器由两层conv2d卷积层和relu层构成,用于在骨干网络上提取每个位置的re-id特征。该分支通过分类任务学习重识别特征。将训练集中所有具有相同身份的对象实例视为同一类。对于图像中的每一个真实标签框在heatmap中获取它的目标中心点提取行人重识别特征向量并学会将其映射到一个类分布矢量p={p(k),k∈[1,k]}。假设该真实标签类的标签是li(k),则重识别损失为:
[0083][0084]
公式中的k是数据集中类别的数量,在本实验中为10。在网络的训练过程中,只是用目标中心的身份嵌入向量进行训练,因为在测试中可以从目标热图中获得目标中心。
[0085]
步骤3,训练网络
[0086]
网络的训练主要包括目标检测分支的训练和行人重识别分支的训练
[0087]
训练目标检测分支的损失函数为:
[0088]
l
detection
=l
heat
l
box
ꢀꢀ
(6)
[0089]
整个网络的训练使用不确定性损失函数来自动平衡检测和重新识别任务,其损失函数定义如下:
[0090]
[0091]
其中w1,w2是平衡两个任务的可学习参数。具体来说,给定一幅图像,其中包含一些对象及其对应的ids,生成热图、偏移量、边框尺寸以及对象的one-hot类。这些用于估计的数据进行比较以此来获得损失,进而训练整个网络。
[0092]
在整个训练时,使用fairmot模型在imagenet上的预训练权重,然后在的数据集上进行微调,通过这种方法,获得最终的效果。
[0093]
步骤4,多类别多目标追踪
[0094]
模型训练好之后,将得到的训练权重加载,对无人机测试数据集进行追踪。追踪过程中会生成一个txt文件,该文件内保存了追踪的结果,通过此文件可以将追踪到的目标的边框、类别以及id在原始视频序列中进行可视化,并且根据此文件能够生成每个目标在60帧以内的运动轨迹。
[0095]
步骤5,算法性能评估
[0096]
将追踪过程中生成的txt文件与真实标签进行比对,可以计算出追踪算法的相关评价指标。
[0097]
实验以及分析
[0098]
1.实验条件
[0099]
本发明的硬件测试平台是:配置geforce rtx 3090的服务器,显卡内存24gb;软件平台为ubuntu 18.0操作系统和pycharm 2019.编程语言是python,使用pytorch深度学习框架实现网络结构。
[0100]
2.实验数据
[0101]
本发明的性能评价主要用到两个数据集。uavdt无人机数据集、visdrone2019无人机数据集。
[0102]
uavdt无人机数据集是iccv2018提出的一个数据集,数据集包含从100个视频序列中选择的80k带注释的帧,主要包含轿车、卡车和公共汽车三个类别的车辆,不仅可以用于目标跟踪,也可以用于目标检测等。
[0103]
visdrone2019数据集由天津大学机器学习与数据挖掘实验室的aiskyeye团队收集。基准数据集由261,908帧和10,209张静态图像组成的288个视频片段组成,由各种安装在无人机上的摄像头捕获,涵盖了广泛的方面,包括位置(从中国相距数千公里的14个不同城市中拍摄),环境(城市和乡村),物体(行人,车辆,自行车等)和密度(稀疏和拥挤的场景)。此外,值得注意的是,该数据集是在各种情况下以及在各种天气和光照条件下使用各种无人机平台(即具有不同模型的无人机)收集的。
[0104]
3.性能比较
[0105]
本发明用到的技术对比方法如下:
[0106]
(1)张等人在《a simple baseline for multi-object tracking》提出的基于anchor-free的one-shot多目标跟踪算法,简称为fairmot方法。该方法采用基于anchor-free的检测头,用heatmap来预测目标的中心点,并使用one-shot的方法,让re-id分支与detection分支共用骨干网络进行特征提取。
[0107]
(2)在fairmot基础上改进的fairmot-ttfhead模型,该模型在fairmot模型的基础上使用ttfnet模型的ttfhead检测头替换fairmot的检测头得到,试图替换性能更加优异的检测头来提升模型的精准度。
[0108]
(3)在fairmot-ttfhead模型的基础上改进的fairmot-newttfhead模型,该模型在fairmot-ttfhead模型的基础上为目标检测分支添加了一个目标中心点偏移量预测的检测头,该检测头的引入能够更好的对齐目标中心的位置。
[0109]
(4)在fairmot-newttfhead模型的基础上改进的fairmot-newttfhead_cbam模型,该模型在fairmot-newttfhead模型的基础上通过在骨干网络中引入cbam注意力机制得到,能够更好的提取图像中的特征,供检测分支和重识别分支使用。
[0110]
在实验中,采用以下九个指标来评价本发明的性能:
[0111]
第一个评价指标是多目标跟踪的准确度(mota),体现在确定目标的个数,以及有关目标的相关属性方面的准确度,用于统计在跟踪中的误差积累情况。
[0112]
第二个评价指标是id f1得分(idf1),正确识别的检测与地面真实和计算检测的平均数量之比。
[0113]
第三个评价指标是大部分时间被跟踪的目标(mt),在各自的生命周期中至少80%的时间里,轨迹假设覆盖的地面真实轨迹的比例。
[0114]
第四个评价指标是召回率(rcll),正确检测与gtbox总数之比。
[0115]
第五个评价指标是精确率(prcn),tp与(tp fp)之比。
[0116]
第六个评价指标是大部分时间跟踪丢失的目标(ml),轨迹假设覆盖的地面真实轨迹的比例,最多占其各自寿命的20%。
[0117]
第七个评价指标是缺失数(漏检数)(fp),即在第t帧中该目标没有假设位置与其匹配。
[0118]
第八个评价指标是误判数(fn),即在第t帧中给出的假设位置没有跟踪目标与其匹配。
[0119]
第九个评价指标是误配数(ids),即在第t帧中跟踪目标发生id切换的次数。
[0120]
前五个评价指标值越高说明模型效果越好,后四个评价指标值越低说明模型的效果越好。
[0121]
表4是本发明对uavdt无人机数据集多目标追踪的准确率以及对比。
[0122]
表5是本发明对visdrone2019无人机数据集多目标追踪的准确率以及对比。
[0123]
表4
[0124][0125]
表5
[0126][0127]
从表4、表5可以看出,对于同一个无人机数据集,本发明提出的基于改进的注意力机制fairmot多类别跟踪方法,其效果要优于原始方法和其他版本的改进方法。对于uavdt
数据集来说,其只有三个类别,而visdrone2019高达十二个类别,同数量级训练集规模下同样的训练轮数,更加集中的类别有助于模型训练的收敛,因此可以发现在测试集上,uavdt数据集上的测试结果整体优于visdrone2019数据集的测试结果。
[0128]
另外图13和图14展示了两个数据集上追踪效果图(图13为uavdt数据集上的追踪效果图,图14为visdrone2019数据集上的追踪效果图),其可视化的追踪效果与表4,表5列出的结果一致。从结果的可视化来看,本发明实现的基于改进的注意力机制fairmot多类别跟踪方法的效果更好。
[0129]
综上所述,本发明提出了一种基于改进的注意力机制fairmot多类别跟踪方法。在fairmot的dl34-base的基础上添加了注意力机制,可以使网络更好的学习图像中的语义信息和空间信息。还对网络的其它结构进行了修改,在目标检测分支中修改heatmap检测头与box size检测头,使得目标检测分支对于目标中心点位置和目标尺寸的预测的精确度更高,进而对整个模型的追踪性能有了不错的提升。实验结果表明,本发明比现有技术具有更高的追踪精准度。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
