1.本发明涉及试题查重领域,特别是一种相似试题查重的判定方法。
背景技术:
2.伴随在线教育的蓬勃发展,在线作业、在线考试、随堂测评已经广泛进入了学生的日常学习生活中,尤其一些网络教育学院、成人教育学院已经将部分学科课程考试进行了线上考试的常态化组织。在线考试已经广泛的应用在大中专院校学生的课程考试中。在线作业、在线考试实施的前提之一是题库建设工作,题库建设中初始试题建设、每年的定期试题更新中往往会遇到,重复试题录入、导入的问题。如果有重复试题或者试题相似度比较高的试题在同一张试卷中,试卷质量往往就不会太高。
3.录入试题、或者导入试题时,如何可以比较准确的判定是重复试题,或者相似度比较高的试题,是一个技术难点。一门学科中试题比较少量时,还可以通过负责本学科的老师进行人工筛查,但如果一门学科试题比较多时,人工筛查就很困难了。
技术实现要素:
4.本发明目的在于提供一种相似试题查重的判定方法,以解决现有题库中录入试题、或者导入试题时,如何可以比较准确的判定是重复试题,或者相似度比较高的试题,是一个技术难点。一门学科中试题比较少量时,还可以通过负责本学科的老师进行人工筛查,但如果一门学科试题比较多时,人工筛查就很困难了的问题。
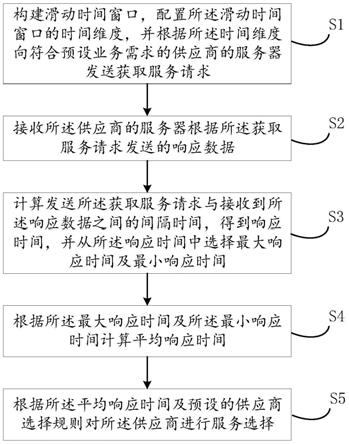
5.本发明的目的通过以下技术方案来实现:一种相似试题查重的判定方法,包括:s1:获取新增试题;s2:对所述新增试题进行hash计算并得到所述新增试题的hash编码,对redis数据库中的已有试题进行hash计算并得到所述已有试题的hash编码;s3:将所述新增试题的hash编码和所述已有试题的hash编码进行对比,若对比结果为重复,则将重复的所述新增试题删除,若比对结果为不重复,则将不重复的所述新增试题和所述已有试题进行相似度比较,并添加到所述redis数据库中。
6.优选的,步骤s2中,所述将所述新增试题的hash编码和所述已有试题的hash编码进行对比,具体包括:将所述已有试题的hash编码保存到对应试题的附加字段中,并将所述已有试题的hash编码作为key值、试题id作为value值初始化到所述redis数据库中;将所述新增试题的hash编码作为key值、新增试题的id作为value值保存到对应试题的附加字段中;调用所述redis数据库中的exists命令,将所述新增试题的hash编码调入到所述redis数据库中进行检索,如有值,返回所述redis数据库中的试题id值,标记为试题重复,如不存在,则调用所述redis数据库中中的append命令将所述新增试题新增到所述redis数据库中。
7.优选的,步骤s3中,所述相似度比较具体包括:调用solr搜索引擎对所述不重复试
题进行相似度标记,将所述不重复试题与所述已有试题相似度大于60%、80%分别作为相似、高度相似分别进行试题相似度标记。
8.优选的,若所述新增试题采用逐题增加的进行试题查重时,则将每一个所述新增试题重复步骤s1-步骤s3;若所述新增试题采用批量模板导入的方式进行查重时,则导入新增试题后采用异步的方式执行步骤s2-步骤s3两步操作。
9.优选的,针对所述redis数据库中已入库的所述已有试题进行查重,具体包括:将每一个所述已有试题hash编码与其他所述已有试题hash编码分别进行查重判定对比,若比对结果为重复,则只保留其中一个,若比对结果不重复,则对其进行相似度比较,并进行相似度标记。
10.优选的,若新录入的所述新增试题和此科目下任一所述已有试题完成相同,系统给出重复的所述已有试题的id值,并询问是否继续录入;如果新录入的所述新增试题与此科目下已有已有所述已有试题高度相似,系统给出所述以后试题的id值,以及所述新增试题与所述已有的相似度,并询问是否继续录入。
11.优选的,在步骤s1之前,在系统中搭建solr引擎。
12.优选的,在步骤s2-s3z之间,将题库中所述已有试题通过solr建立索引。
13.本发明具有以下至少一个优点:本发明中,本发明能够系统的对试题进行查重以及相似度标记,通过对每一个试题进行hash计算,分别得出一个hash编码,然后用各自的hash编码进行对比,节约了存储空间,提高了对比效率,且对比完成之后进行相似度比较,提高了题库建设的质量、降低试题录入、校对工作的人工工作量,保障在线作业、在线考试、线下考试试卷出题质量。
具体实施方式
14.为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施方式,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。因此,以下对本发明的实施方式的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
15.需要说明的是,在不冲突的情况下,本发明中的实施方式及实施方式中的特征可以相互组合。
16.具体实施例1本实施例提出一种相似试题查重的判定方法,包括:s1:获取新增试题;s2:对所述新增试题进行hash计算并得到所述新增试题的hash编码,对redis数据库中的已有试题进行hash计算并得到所述已有试题的hash编码;s3:将所述新增试题的hash编码和所述已有试题的hash编码进行对比,若对比结果为重复,则将重复的所述新增试题删除,若比对结果为不重复,则将不重复的所述新增试题和所述已有试题进行相似度比较,并添加到所述redis数据库中。
17.本实施例中,hash算法是将一个不定长的输入,通过散列函数变换成一个定长的
输出,即散列值,即在对试题进行hash计算时,其可将每一个试题信息分别转换为一个二进制序列,大大节省了空间,本实施例中当计算出例如已有试题a的hash编码、新增试题b的hash编码后,将新增试题b的 hash编码与已有试题a的hash编码、进行对比,若新增试题b的hash编码与已有试题a的hash编码相同,则将已有试题a删除,若新增试题a的 hash编码与已有试题b的hash编码不同,则对其进行相似度比较,并对其进行相似度标记,然后导入redius数据库中。
18.本实施例能够系统的对试题进行查重以及相似度标记,通过对每一个试题进行hash计算,分别得出一个hash编码,然后用各自的hash编码进行对比,节约了存储空间,提高了对比效率,且对比完成之后进行相似度比较,提高了题库建设的质量、降低试题录入、校对工作的人工工作量,保障在线作业、在线考试、线下考试试卷出题质量。
19.具体实施例2本实施例是在上述实施例的基础上对步骤s2进行进一步的说明,步骤s2中,所述将所述新增试题的hash编码和所述已有试题的hash编码进行对比,具体包括:将所述已有试题的hash编码保存到对应试题的附加字段中,并将所述已有试题的hash编码作为key值、试题id作为value值初始化到所述redis数据库中;将所述新增试题的hash编码作为key值、新增试题的id作为value值保存到对应试题的附加字段中;调用所述redis数据库中的exists命令,将所述新增试题的hash编码调入到所述redis数据库中进行检索,如有值,返回所述redis数据库中的试题id值,标记为试题重复,如不存在,则调用所述redis数据库中中的append命令将所述新增试题新增到所述redis数据库中。
20.具体实施例3本实施例是在上述实施例的基础上对步骤s3进行进一步的说明,在步骤s3中,所述相似度比较具体包括:调用solr搜索引擎对所述不重复试题进行相似度标记,将所述不重复试题与所述已有试题相似度大于60%、80%分别作为相似、高度相似分别进行试题相似度标记。
21.本实施例中,在使用solr之前,需要在系统中搭建solr引擎。配置中文分词引擎jieba。并且在schema.xml中设置solrqueryparser defaultoperator="and",之后将题库中所述已录入有试题通按题干 选项 答案通过solr建立索引过solr建立索引进行分词,通过分词对比进行相似度判定。
22.查询相似试题方法为querysimilarquestionid,主要实现代码如下:solrquery query = new solrquery();query.setrequesthandler("/mlt");query.setquery("id:" id);query.addfilterquery("question:" question);query.setparam("fl", "id");query.setparam("mlt", "true");query.setparam("mlt.mintf", "1");query.setparam("mlt.mindf", "1");query.setparam("mlt.fl", "stem");query.set("start", 0);
query.set("rows",count);solrserverserver=newhttpsolrserver(solrurl);queryresponseresponse=server.query(query,method.post);通过调用querysimilarquestionid方法,得到相似值similarscore,判定similarscore》=6认为相似,小于6认为不相同,过滤掉。如果大于6再进行判定,一般相似、高度相似。默认similarscore》8,高度相似。
23.具体实施例4本实施例与上述实施例大致相同,不同之处在于,若所述新增试题采用逐题增加的进行试题查重时,则将每一个所述新增试题重复步骤s1-步骤s3;若所述新增试题采用批量模板导入的方式进行查重时,则导入新增试题后采用异步的方式执行步骤s2-步骤s3两步操作。
24.本实施例中,若教师单独将新增试题逐题导入题库中进行查重时,则直接将已有试题a的hash编码保存到附加字段中,并将已有试题a的hash编码作为key值、试题id作为value值初始化到redis内存数据库中;然后将新增试题b的hash编码作为key值、新增试题id作为value值保存到对应试题的附加字段中;通过调用redis中的exists命令,将新增试题b的hash值调入到所述redis内存数据库中进行检索,如有值,返回redis中的试题id值,标记为试题重复,如不存在,则调用append命令新增到redis列表中,然后通过solr进行相似度标记。
25.若教师批量模板导入的方式进行查重的话(通过excel、word等模板方式按一定格式进行试题批量导入),则系统采用异步的方式执行步骤2)-步骤3)对每一个新增进行查重或者相似度标记。
26.具体实施例5本实施例与上述实施例大致相同,不同之处在于,针对所述redis数据库中已入库的所述已有试题进行查重,具体包括:将每一个所述已有试题hash编码与其他所述已有试题hash编码分别进行查重判定对比,若比对结果为重复,则只保留其中一个,若比对结果不重复,则对其进行相似度比较,并进行相似度标记。
27.本实施例中,若题库中包括d试题、e试题、f试题,对其进行查重和相似度对比时,首先将对d试题、e试题以及f试题的分别进行hash计算,得出d试题的hash编码、e试题的hash编码以及f试题hash编码,然后将各自的hash编码保存到对应试题的附加字段中,调用redis中的exists命令,逐题将每个试题hash值调入到所述redis内存数据库中进行检索,进行查重,如有值,返回redis中的试题id值,标记为试题重复,并将重复试题删除,若进行相似度对比的话,则逐题通过调用solr进行相似度标记。
28.具体实施例6本实施例与上述实施例大致相同,不同之处在于,若新录入的所述新增试题和此科目下任一所述已有试题完成相同,系统给出重复的所述已有试题的id值,并询问是否继续录入;如果新录入的所述新增试题与此科目下已有已有所述已有试题高度相似,系统给出所述以后试题的id值,以及所述新增试题与所述已有的相似度,并询问是否继续录入。
29.例如若新录入的所述新增试题和此科目下已有所述已有试题完成相同,系统给出提示,“新录入试题与题库中已有试题【试题编号】重复,请确认是否继续录入”,若重复,教
师则可点击“否”按钮,若不重复,教师则可点击“是”按钮,如果新录入的所述新增试题与此科目下已有已有所述已有试题高度相似,系统给出提示,“新录入试题与题库中已有试题【试题编号】相似度为n%,请确认是否继续录入”。若相似度低于某个值,则教师可点击“是”按钮,相反点击“否”按钮。
30.尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。