由gpu执行的视频帧处理方法和包括gpu的视频帧处理装置
技术领域
1.本公开的实施例涉及计算机技术领域,具体地,涉及由图形处理器(gpu)执行的视频帧处理方法和包括gpu的视频帧处理装置。
背景技术:
2.随着多媒体技术的发展,在教学、娱乐、通信等多个应用领域中,对视频文件的各种处理需求日益增多。有时需要将视频文件进行转码处理,以适应不同的网络带宽或者画质要求。在一些情况下,还可能需要对视频文件进行渲染,以实现更好的显示效果。例如,在一些应用场景中,可能需要使得视频帧中的某些对象更加逼真。在显示房子外墙的视频帧中,可能需要通过渲染处理使得房子外墙上的砖块更加立体。在显示湖面的视频帧中,可能需要通过渲染处理使得湖面显得波光粼粼。在显示人脸的视频帧中,可能需要通过渲染处理使得人脸看起来更柔和或者更白皙。在另一些应用场景中,还可以通过渲染处理制作出例如镜面效果等。此类渲染处理可能需要进行大量的计算,消耗大量的系统资源。
3.常用的视频编解码方式是在中央处理器(cpu)上进行的,这种编解码方式也被称作软件编解码。但是软件编解码的速度比较慢。为了提升视频编解码的速度,可能会使用gpu(俗称显卡)来参与视频编解码,以使得视频编解码的部分工作由硬件部分完成。
技术实现要素:
4.本文中描述的实施例提供了一种由gpu执行的视频帧处理方法以及一种包括gpu的视频帧处理装置。
5.根据本公开的第一方面,提供了一种由gpu执行的视频帧处理方法。该nvidia gpu包括渲染器、共享模块和视频编码器。在该方法中,由渲染器获得渲染后的纹理。然后,使得共享模块与渲染器共享渲染后的纹理的存储空间。建立渲染后的纹理的索引号与共享模块的指向该存储空间的指针之间的映射关系。接着,根据该映射关系从渲染后的纹理获得渲染数据。之后,将渲染数据复制到视频编码器的输入缓冲区中。
6.在本公开的一些实施例中,gpu是nvidia gpu。共享模块由nvidia gpu的统一计算设备架构(compute unified device architecture,简称cuda)提供。在本公开的一些实施例中,该映射关系借助于cuda来建立。
7.在本公开的一些实施例中,渲染器是opengl,渲染后的纹理是通过opengl渲染的。
8.在本公开的一些实施例中,将渲染数据复制到视频编码器的输入缓冲区中的步骤由cuda调用以下函数中的至少一个来执行:cugraphicsglregisterimage;cugraphicsmapresources;cugraphicssubresourcegetmappedarray;cugraphicsunmapresources;以及cumemcpy2d。
9.在本公开的一些实施例中,该方法还包括:由视频编码器将输入缓冲区中的渲染数据编码成编码数据。
10.在本公开的一些实施例中,该视频编码器是nvenc。
11.根据本公开的第二方面,提供了一种包括gpu的视频帧处理装置。该gpu包括渲染器、共享模块和视频编码器。该gpu被配置为:由该渲染器获得渲染后的纹理;使得共享模块与该渲染器共享渲染后的纹理的存储空间;建立渲染后的纹理的索引号与共享模块的指向该存储空间的指针之间的映射关系;根据该映射关系从渲染后的纹理获得渲染数据;以及将渲染数据复制到视频编码器的输入缓冲区中。
12.在本公开的一些实施例中,gpu是nvidia gpu。共享模块由nvidia gpu的cuda提供。
13.在本公开的一些实施例中,该映射关系借助于cuda来建立。
14.在本公开的一些实施例中,该渲染器是opengl,渲染后的纹理是通过该opengl渲染的。
15.在本公开的一些实施例中,将渲染数据复制到视频编码器的输入缓冲区中的步骤由cuda调用以下函数中的至少一个来执行:cugraphicsglregisterimage;cugraphicsmapresources;cugraphicssubresourcegetmappedarray;cugraphicsunmapresources;以及cumemcpy2d。
16.在本公开的一些实施例中,该gpu还被配置为:由视频编码器将输入缓冲区中的渲染数据编码成编码数据。
17.在本公开的一些实施例中,该视频编码器是nvenc。
附图说明
18.为了更清楚地说明本公开的实施例的技术方案,下面将对实施例的附图进行简要说明,应当知道,以下描述的附图仅仅涉及本公开的一些实施例,而非对本公开的限制,其中:
19.图1是根据本公开的实施例的由gpu执行的处理视频帧的方法的示例性流程图;
20.图2是在图1所示的实施例中的获得视频帧的转码数据的步骤的示例性流程图;
21.图3是图1所示的实施例的方法所包括的进一步的步骤的示例性流程图;以及
22.图4是根据本公开的实施例的处理视频帧的过程的示意图。
23.附图中的元素是示意性的,没有按比例绘制。
具体实施方式
24.为了使本公开的实施例的目的、技术方案和优点更加清楚,下面将结合附图,对本公开的实施例的技术方案进行清楚、完整的描述。显然,所描述的实施例是本公开的一部分实施例,而不是全部的实施例。基于所描述的本公开的实施例,本领域技术人员在无需创造性劳动的前提下所获得的所有其它实施例,也都属于本公开保护的范围。
25.除非另外定义,否则在此使用的所有术语(包括技术和科学术语)具有与本公开主题所属领域的技术人员所通常理解的相同含义。进一步将理解的是,诸如在通常使用的词典中定义的那些的术语应解释为具有与说明书上下文和相关技术中它们的含义一致的含义,并且将不以理想化或过于正式的形式来解释,除非在此另外明确定义。如在此所使用的,诸如“第一”和“第二”的术语仅用于将一个元素(或元素的一部分)与另一个元素(或元素的另一部分)区分开。
[0026]“视频”在本文中指的是一组连续图像的数字化表示。该组连续图像中的每一个图像可被称为一个视频帧。尽管“视频”的通常含义还可能包括音频部分,但是在本文中主要讨论视频中的图像部分,即,视频帧。
[0027]
通常视频编解码的流程包括对视频帧执行以下操作:解封装-》解码-》转码-》渲染-》编码-》封装。如上所述为了提升视频编解码的速度,可能会使用gpu(俗称显卡)来参与视频编解码,以使得视频编解码的部分工作由硬件部分完成。在使用gpu来参与视频编解码的一些应用中,由cpu对视频帧进行解封装以获得视频帧的经解封装的压缩数据。然后cpu将经解封装的压缩数据发送给gpu,由gpu对压缩数据进行解码以获得视频帧的原始数据。视频帧的原始数据一般为yuv格式,而渲染操作需要针对rgb格式的数据进行。因此在渲染之前还要进行转码,将yuv格式的数据转换成rgb格式的数据。一般情况下转码可采用ffmpeg或libyuv转码的方式。ffmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。libyuv是google开源的实现各种yuv与rgb之间相互转换、旋转、缩放的库。此类转码方式是在cpu上进行的。因此,在gpu解码得到视频帧的原始数据之后,gpu需要将视频帧的原始数据发送给cpu以进行转码。在cpu通过转码得到rgb格式的数据之后,cpu将rgb格式的数据发送给gpu,以便在gpu中进行渲染操作。渲染后的数据(在本公开的上下文中可被称为“渲染数据”)可在gpu中被编码。编码后的数据可被发送给cpu以进行封装处理。
[0028]
在上述过程中,由于视频帧数据需要在cpu与gpu之间多次传输,并且转码操作由软件完成,因此这种视频编解码方式(在本公开的上下文中也可被称为“半硬件编解码方式”)仍然比较耗时。
[0029]
如果转码操作也由gpu来执行,则可以减少视频帧数据在cpu与gpu之间传输的次数。解码操作、转码操作、渲染操作都在gpu中执行的方式在本公开的上下文中可被称为“完全硬件解码方式”。解码操作、转码操作、渲染操作以及编码操作都在gpu中执行的方式在本公开的上下文中可被称为“完全硬件编解码方式”。在采用完全硬件解码方式的情况下,如何将执行转码操作的硬件部件与执行渲染操作的硬件部件高效地结合起来使用是本公开的实施例所研究的一个方面。在采用完全硬件编解码方式的情况下,如何将执行渲染操作的硬件部件与执行编码操作的硬件部件高效地结合起来使用是本公开的实施例所研究的另一个方面。
[0030]
图1示出根据本公开的实施例的由gpu执行的处理视频帧的方法100的示例性流程图。下面参考图1来描述由gpu执行的处理视频帧的方法100。
[0031]
在图1的框s102处,获得视频帧的转码数据。在本公开的一些实施例中,该转码数据是在gpu中生成的。图2示出获得视频帧的转码数据的步骤的示例性流程图。
[0032]
在图2的框s202处,获得视频帧的经解封装的压缩数据。视频文件可包括文件头,用于定义视频文件的一些参数和/或信息,例如序列参数集(sps)/图像参数集(pps)信息。根据文件头中包括的参数和/或信息,可以知道视频帧的起始位置、视频帧的总长度等信息。根据此类信息,可以知道视频帧数据在视频文件中的具体存储位置。为节省视频的存储空间,该视频帧数据通常是压缩数据,也可被理解为原始数据的压缩包。从视频文件中取得该压缩数据的过程被称为解封装。由于解封装操作耗时较少,因此通常在cpu中执行解封装操作。在cpu对视频进行解封装操作之后,cpu可获得视频帧的经解封装的压缩数据。然后,
cpu将该压缩数据发送给gpu。在这种情况下,获得视频帧的经解封装的压缩数据的过程可以被理解为:gpu从cpu接收视频帧的经解封装的压缩数据。在一些实施例中,也可以由gpu进行解封装操作,以获得视频帧的经解封装的压缩数据。
[0033]
在框s204处,将压缩数据解码为视频帧的原始数据。在本公开的一些实施例中,在gpu获得经解封装的压缩数据之后,将该经解封装的压缩数据送入解码器中进行解码。在送入例如4帧数据后,解码器可返回解码后的原始数据。原始数据一般为yuv格式的数据。在本公开的一些实施例中,该gpu例如是nvidia gpu(显卡厂商英伟达生产的gpu)。该压缩数据可由nvidia gpu中的视频解码器引擎nvdec解码为原始数据。本领域技术人员应了解,该gpu也可以是由其他厂商生产的具有视频解码器的gpu。
[0034]
在框s206处,将原始数据转码为视频帧的转码数据。由于渲染操作需要针对rgb格式的数据进行,因此在渲染之前还要对yuv格式的原始数据进行转码,将yuv格式的数据转换成rgb格式的数据。如上所述,在本公开的一些实施例中,该gpu例如是nvidia gpu。该yuv格式的原始数据可由nvidia gpu中的cuda转码为rgb格式的转码数据。cuda是显卡厂商nvidia推出的通用并行计算架构,该架构使gpu能够解决复杂的计算问题。它包含了cuda指令集架构(isa)以及gpu内部的并行计算引擎。本领域技术人员应了解,该gpu也可以是由其他厂商生产的具有转码功能的gpu。
[0035]
下面回到图1,在框s104处,将转码数据存储在gpu中的指定地址空间。在一些实施例中,可获得指向该指定地址空间的指针。在gpu是nvidia gpu且转码操作由cuda执行的示例中,该转码数据可存储在cuda中。
[0036]
在框s106处,建立指向指定地址空间的指针与要在gpu中创建的目标纹理的索引号之间的第一映射关系。纹理可以是表示物体表面细节的一个或多个图形,其实质上是数据数组,例如颜色数据、亮度数据等。纹理数组中的单个值通常被称为纹理单元,也叫纹素(texel)。纹理的索引号是纹理在存储器中存储的索引号。在一些图形处理应用中,例如opengl、opengles等,纹理是按照无符号int型数据的索引号来存储的。例如,如果有10个纹理,则可以分别用0到9这十个数字作为索引号,来表示每个纹理的存储地址。在创建目标纹理之前,可以先确定目标纹理的索引号,以便预留该索引号所指向的存储空间,以供将来在该存储空间中创建目标纹理。
[0037]
在gpu是nvidia gpu的示例中,第一映射关系可由nvidia gpu中的cuda来建立。
[0038]
在框s108处,根据第一映射关系将指定地址空间中存储的转码数据创建成目标纹理。由于渲染工具(也可被称为“渲染器”)的操作对象是纹理而非图像数据,因此,需要从转码数据创建目标纹理以供渲染工具执行渲染操作。目标纹理中包含了转码数据的信息。由于在框s106处建立了指向指定地址空间的指针与目标纹理的索引号之间的第一映射关系,因此不需要将转码数据拷贝到渲染工具中。可以通过指向指定地址空间的指针与目标纹理的索引号之间的第一映射关系来快速地创建目标纹理。
[0039]
这样,根据本公开的实施例的处理视频帧的方法可将执行转码操作的硬件部件与执行渲染操作的硬件部件高效地结合起来使用。
[0040]
下面进一步讨论在采用完全硬件编解码方式的情况下,如何将执行渲染操作的硬件部件与执行编码操作的硬件部件高效地结合起来使用。
[0041]
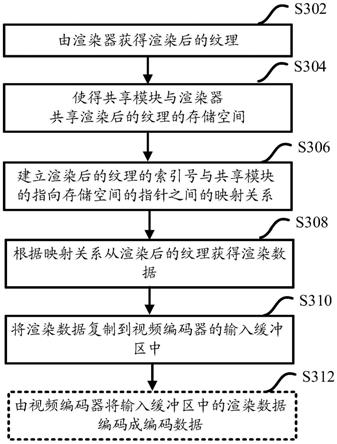
图3示出图1所示的实施例的方法所包括的进一步的步骤的示例性流程图。
[0042]
在框s302处,由渲染器获得渲染后的纹理。在本公开的一些实施例中,可由渲染器对目标纹理进行渲染以获得渲染后的纹理。如上所述,纹理数组中包括纹理单元。纹理单元是对能够被渲染工具中的着色器采样的纹理对象的引用。纹理对象本身包括纹理需要的数据,比如图像数据。渲染工具可通过纹理单元对纹理进行渲染,形成渲染后的纹理。渲染后的纹理存储在与目标纹理不同的存储空间中,对应与目标纹理不同的索引号。
[0043]
在gpu中,渲染后的纹理不能直接输入编码器中进行编码。因此,在本公开的一些实施例中,在gpu中提供了共享模块,借助于该共享模块来从渲染器中获取纹理对应的图像数据,并提供给编码器。如图3所示,在框s304处,使得共享模块与渲染器共享渲染后的纹理的存储空间。在gpu是nvidia gpu且nvidia gpu包括cuda的示例中,共享模块由nvidia gpu的cuda提供。在本公开的一些实施例中,渲染后的纹理可被保存在渲染工具中的某个地址空间。通过将该地址空间注册为cuda的图形资源cudaresource,可使得cuda能够共享该存储空间。
[0044]
在框s306处,建立渲染后的纹理的索引号与共享模块的指向上述存储空间的指针之间的第二映射关系。在本公开的一些实施例中,第二映射关系可借助于cuda来建立。
[0045]
在框s308处,根据第二映射关系从渲染后的纹理获得渲染数据。如前所述,纹理实质上是数据数组,例如颜色数据、亮度数据等。从该数据数组可以得到经过渲染处理的图像(视频帧)数据,在上下文中也可被称为渲染数据。因为视频编码器的操作对象是图像数据而非纹理,因此需要从渲染后的纹理中提取出图像数据的信息。由于cuda的指针指向cuda与渲染后的纹理所共享的存储空间,因此,通过该指针可以获得该存储空间中存储的纹理所对应的渲染数据。由于在框306处建立了渲染后的纹理的索引号与共享模块的指向存储空间的指针之间的第二映射关系,因此能够方便地从渲染后的纹理获得渲染数据。
[0046]
在框s310处,将渲染数据复制到视频编码器的输入缓冲区中。在本公开的一些实施例中,在每次通过该指针获得一个渲染数据之后,可以将该渲染数据复制到视频编码器的输入缓冲区中。复制操作可由cuda调用以下函数中的至少一个来执行:cugraphicsglregisterimage;cugraphicsmapresources;cugraphicssubresourcegetmappedarray;cugraphicsunmapresources;以及cumemcpy2d。在一个示例中,cuda调用上述函数中的全部函数来执行复制操作。
[0047]
在框s312处,由视频编码器将输入缓冲区中的渲染数据编码成编码数据。在一些实施例中,在输入缓冲区中的渲染数据超过例如3帧的时候开始执行编码操作。在gpu是nvidia gpu的示例中,该图像数据可由nvidia gpu中的视频编码器引擎nvenc编码成编码数据。本领域技术人员应了解,该gpu也可以是由其他厂商生产的具有视频编码器的gpu。
[0048]
为了更清楚的描述根据本公开的实施例的处理视频帧的过程,在图4中示出了整个视频编解码过程的示意图。图4中的虚线用于划分cpu和gpu分别执行的操作。由虚线分割的图4的上半部分的操作由cpu执行。由虚线分割的图4的下半部分的操作由gpu执行。
[0049]
在图4的示例中,以gpu是nvidia gpu为例进行说明。其中,该nvidia gpu可包括:视频解码器引擎nvdec、cuda、opengl和视频编码器引擎nvenc。nvdec可执行解码操作。cuda可执行转码操作。opengl可执行渲染操作。nvenc可执行编码操作。
[0050]
如图4所示,在框402处,由cpu获得输入视频文件。在一些实施例中,cpu可检测当前系统中的gpu的信息,以获取gpu相关数据。gpu相关数据例如是gpu的名称、型号和内存等
信息。根据该信息可知道gpu是否支持解码、转码、渲染和编码功能。在gpu支持解码、转码、渲染和/或编码功能的情况下,该gpu可执行根据本公开的实施例的处理视频帧的操作。
[0051]
在框404处,cpu通过例如调用ffmpeg api来创建用于解封装的上下文指针。在框406处,基于该上下文指针,cpu使用ffmpeg api进行视频文件的解封装。以mp4格式的文件为例进行说明。mp4文件的sps/pps信息存储在文件头中。因此,可在文件头中提取sps/pps信息,以根据该sps/pps信息执行解封装操作。在解封装操作之后,cpu获取原始数据的压缩包(即,视频帧的经解封装的压缩数据)。
[0052]
然后在框408处,cpu将所获取的原始数据的压缩包发送给gpu,以在gpu的解码器(nvdec)中进行解码操作。在解码器接收到例如4帧压缩数据后,可返回解码后的原始数据(即,视频帧的原始数据)。解码后的原始数据不能直接被渲染,因为渲染工具opengl的输入数据需要是rgb格式的数据,而原始数据一般是yuv格式的数据。所以在原始数据被发送给opengl进行渲染之前还要对原始数据进行转码,将yuv格式的数据转换成rgb格式的数据。在图4的示例中,在框410处,由cuda在gpu上执行转码操作。转码后的数据存储在cuda中的指定地址空间。
[0053]
然后,在框412处使得执行渲染操作的opengl与执行转码操作的cuda建立映射关系。在一些实施例中,可使用cudeviceptr类型的指针指向转码后的数据所存储的地址空间。然后,可由cuda采用映射方法使得要在gpu中创建的目标纹理的索引号(可被称为“opengl纹理id”)与该cudeviceptr类型的指针关联起来。opengl可借助opengl纹理id与该cudeviceptr类型的指针的映射关系来快速地生成opengl纹理。这样cuda不需要把转码后的数据复制(copy)到opengl以供opengl生成纹理,这样可节省复制操作占用的时间和资源。并且在每次获得转码后的数据时,opengl纹理都可以快速更新,从而加快渲染速度。
[0054]
在框414处,由opengl执行渲染操作。渲染工具opengl的输入和输出均是纹理。渲染后的纹理与渲染前的纹理具有不同的纹理索引号,被存储在不同的地址空间。在一些实施例中,渲染后的纹理(也可被理解为渲染后的视频帧)可以被显示或者被输出(未在图4中示出)。
[0055]
在一些实施例中,在需要以压缩的格式存储渲染后的视频帧的情况下,可能需要对渲染后的视频帧进行编码操作。编码操作需要针对图像数据进行,而如上所述,渲染工具opengl的输出是纹理而非图像数据。因此,不能将opengl的输出直接作为编码器的输入。针对该问题,在本公开的实施例中,提出借助于cuda从opengl的输出得到编码器可处理的数据,供编码器进行编码操作。
[0056]
在框416处,使得opengl与cuda建立另一映射关系。具体地,渲染后的纹理被保存在opengl中的某个地址空间。在一个示例中,该地址空间可被注册为cuda的图形资源cudaresource。这样,opengl与cuda可共享该地址空间。在cuda中生成cudaarrary类型的指针,该cudaarrary类型的指针指向所注册的cudaresource。cuda可采用映射方法使得渲染后的纹理的索引号(可被称为“opengl渲染后的纹理id”)与该cudaarrary类型的指针关联起来。通过opengl渲染后的纹理id与该cudaarrary类型的指针之间的映射关系,渲染后的数据(在本公开的上下文中,可被称为渲染数据)可被通过该cudaarrary类型的指针来获得。这样在每次获取渲染后的数据时,该cudaarrary类型的指针会同步更新。cuda可将该cudaarrary类型的指针所指向的数据复制到编码器的输入缓冲区。这样,可以将编码操作
与渲染操作在gpu中结合起来。
[0057]
在框418处,编码器对输入缓冲区中存储的数据进行编码。在一些实施例中,在输入缓冲区中的渲染数据超过例如3帧的时候开始执行编码操作。编码后的数据可被存储在一个二维数组中,并被发送给cpu。
[0058]
在框420处,cpu可创建一个avpacket类型的对象,循环读取该二维数组,以将编码后的数据拷贝到avpacket类型的对象的数据部分中。
[0059]
在框422处,cpu可调用ffmpeg api进行视频文件的封装,然后在框424处获得或输出经封装的输出视频文件。
[0060]
本公开的实施例通过在gpu上进行解码、转码和编码,并将转码和编码与opengl渲染进行绑定,提升了整体的编解码速度,还减少了cpu的资源占用。
[0061]
附图中的流程图和框图显示了根据本公开的多个实施例的装置和方法的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或指令的一部分,所述模块、程序段或指令的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
[0062]
除非上下文中另外明确地指出,否则在本文和所附权利要求中所使用的词语的单数形式包括复数,反之亦然。因而,当提及单数时,通常包括相应术语的复数。相似地,措辞“包含”和“包括”将解释为包含在内而不是独占性地。同样地,术语“包括”和“或”应当解释为包括在内的,除非本文中明确禁止这样的解释。在本文中使用术语“示例”之处,特别是当其位于一组术语之后时,所述“示例”仅仅是示例性的和阐述性的,且不应当被认为是独占性的或广泛性的。
[0063]
适应性的进一步的方面和范围从本文中提供的描述变得明显。应当理解,本技术的各个方面可以单独或者与一个或多个其它方面组合实施。还应当理解,本文中的描述和特定实施例旨在仅说明的目的并不旨在限制本技术的范围。
[0064]
以上对本公开的若干实施例进行了详细描述,但显然,本领域技术人员可以在不脱离本公开的精神和范围的情况下对本公开的实施例进行各种修改和变型。本公开的保护范围由所附的权利要求限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。