1.本发明涉及计算机数据处理技术领域,具体为一种用于云计算系统的资源数据读取方法。
背景技术:
2.云计算(cloud computing)是分布式计算的一种,指的是通过网络“云”将巨大的数据计算处理程序分解成无数个小程序,然后,通过多部服务器组成的系统进行处理和分析这些小程序得到结果并返回给用户。云计算早期,简单地说,就是简单的分布式计算,解决任务分发,并进行计算结果的合并。因而,云计算又称为网格计算。通过这项技术,可以在很短的时间内(几秒钟)完成对数以万计的数据的处理,从而达到强大的网络服务。
3.现有传统的云计算下数据读取方法,一直存在数据读取质量不高,读取数据重复率较高的问题。
技术实现要素:
4.针对上述技术问题,本发明提供一种用于云计算系统的资源数据读取方法,可以便捷的提高分布式数据的安全读写熟读和读取正确率,降低了计算复杂度,提高了适用范围。
5.为实现上述目的,本发明提供如下技术方案:一种用于云计算系统的资源数据读取方法,包括以下步骤:
6.步骤1:设云计算下的数据为x,x表示原始资源分布式数据随机变量(x1,x2,
…
,xn);
7.步骤2:将x分布式数据样本变换为服从(0,1)均匀分布的分布式数据区间,并对变换后的数据通过分布式数据的分布函数变换进行均匀分布的检验验证,获取范围型属性的值域l;
8.步骤3:根据所述步骤2获取所述范围型属性的值域l,将分布式数据值域按照资源数据库的分布样本划分为多个子区间;
9.步骤4:完成云计算下分布式数据的安全读取。
10.优选的,所述步骤2中,检验验证过程如下:
11.第一步:设x的分布数据分布函数为f(t),则分布式数据的经验分布函数计算公式为:式中,i表示分布式数据的示性函数;n表示分布式数据样本数量;i表示分布式数据样本参数值;t表示分布式数据的分布概率;xi表示分布式数据的均匀分布概率;
12.第二步:给定任意t,则公式(1)的分布式数据经验分布函数转为二项分布为:nfn(t)~b(n,f(t))(2),并通过公式(2)获取fn(t)分布式数据期望与方差;
13.第三步:假设分布式数据随机变量f(x)的分布函数为h,则分布式数据的二阶分布
函数计算表达式为通过所述分布式数据的二阶分布函数计算表达式即可验证f(x)服从分布式数据(0,1)区间上的均匀分布(u(0,1));
14.第四步:将分布式数据fn(xi))二阶收敛到f(xi),则可近似确定fn(xi)服从分布式数据(0,1)区间上均匀分布。
15.优选的,所述步骤3中,将资源数据库的数据划分为多个子区间,过程如下:
16.(1)、将待划分的分布式数据的每个子区间上限值设为ci,c0=0,则分布式数据样本中的每个子区间均可表示为[c
i-1
,ci];
[0017]
(2)、将分布式数据样本中的每个子区间上限记为ai,则分布式数据样本中的每个子区间表示为[c
i-1
,ci];
[0018]
(3)、假设a0=0,分布式数据样本区间[a
i-1
,ai]中分布式数据记录的集合表示为b1,b1,
…bi
;则分布式数据的范围属性c1为:q>2,b
l
表示分布式数据查询记录属性值;
[0019]
(4)、通过(3)可得到c1,bq表示分布式数据中重复的数据记录;j表示分布式数据限定性值域;
[0020]
(5)、根据(1)到(4)获取c1过程可获取c2,m表示分布式数据读取时间,则可求得ci。
[0021]
本发明的有益效果:首先采用经验分布函数与核估计对云计算下分布式数据的分布函数进行估计;然后以分布式数据的分布函数变换进行均匀分布的假设检验;再以分布式数据分析结果为依据,利用范围型属性的值域特征,将分布式数据值域按照目标数据库的分布样本划分为多个子区间,再在此基础下完成云计算下分布式数据的安全读取,提高了分布式数据的安全读取速度和读取正确率,降低了计算复杂度,也提高了适用范围。
附图说明
[0022]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制,在附图中:
[0023]
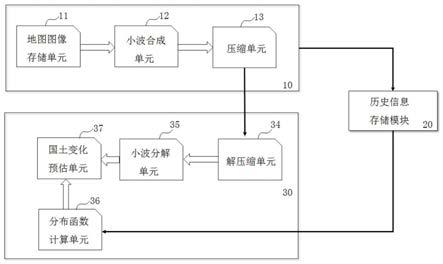
图1为本发明提出的用于云计算系统的资源数据读取方法简易结构示意图。
具体实施方式
[0024]
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结
合具体实施例和附图,进一步阐述本发明,但下述实施例仅为本发明的优选实施例,并非全部。基于实施方式中的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得其它实施例,都属于本发明的保护范围。
[0025]
请参阅图1,一种用于云计算系统的资源数据读取方法,包括以下步骤:
[0026]
步骤1:设云计算下的数据为x,x表示原始资源分布式数据随机变量(x1,x2,
…
,xn);
[0027]
步骤2:将x分布式数据样本变换为服从(0,1)均匀分布的分布式数据区间,并对变换后的数据通过分布式数据的分布函数变换进行均匀分布的检验验证,获取范围型属性的值域l;
[0028]
步骤3:根据步骤2获取范围型属性的值域l,将分布式数据值域按照资源数据库的分布样本划分为多个子区间;
[0029]
步骤4:完成云计算下分布式数据的安全读取。
[0030]
如图1所示,可以便捷的提高分布式数据的安全读写熟读和读取正确率,降低了计算复杂度,提高了适用范围。
[0031]
其中:在实际应用过程中,该云计算下分布式数据安全读取的方法有不同的优缺点,为了进一步证明基于范围型属性云计算下分布式数据安全读取方法的有效性,可通过分布式数据读取准确率(%)e来衡量算法的有效性能,其中,通过获取测试的分布数据进行测试多次,并取多次数据结果的平均值作为最终的分布式数据读取结果。
[0032]
检验过程,首先获取测试数据,测试数据采用北京外国语大学实验室提供的分布式数据基准语料库,选取了计算机、汉语言文学、对外贸易、国际金融等四类分布式数据作为实验测试数据.每类分布式数据各取500篇共计2000篇分布式数据文档进行检验。采用10折交叉验证法,将整个分布式数据集随机分为10份,选取其中8份合并并作为分布式数据训练集,剩下的2份作为分布式数据测试集,实验运行6次,选其平均值作为最后的分布式数据读取结果,其中样本1采用了基于spark的大规模语义数据分布式推理框架读取数据相比本发明提出的方法提取时间更长,严重影响分布式数据读取效率。
[0033]
步骤2中,检验验证过程如下:
[0034]
第一步:设x的分布数据分布函数为f(t),则分布式数据的经验分布函数计算公式为:式中,i表示分布式数据的示性函数;n表示分布式数据样本数量;i表示分布式数据样本参数值;t表示分布式数据的分布概率;xi表示分布式数据的均匀分布概率;
[0035]
第二步:给定任意t,则公式(1)的分布式数据经验分布函数转为二项分布为:nfn(t)~b(n,f(t))(2),并通过公式(2)获取fn(t)分布式数据期望与方差;
[0036]
第三步:假设分布式数据随机变量f(x)的分布函数为h,则分布式数据的二阶分布函数计算表达式为通过分布式数据的二阶分布函数计算表达式即可验证f(x)服从分布式数据(0,1)区间上的均匀分布(u
(0,1));
[0037]
第四步:将分布式数据fn(xi))二阶收敛到f(xi),则可近似确定fn(xi)服从分布式数据(0,1)区间上均匀分布。
[0038]
步骤3中,将资源数据库的数据划分为多个子区间,过程如下:
[0039]
(1)、将待划分的分布式数据的每个子区间上限值设为ci,c0=0,则分布式数据样本中的每个子区间均可表示为[c
i-1
,ci];
[0040]
(2)、将分布式数据样本中的每个子区间上限记为ai,则分布式数据样本中的每个子区间表示为[c
i-1
,ci];
[0041]
(3)、假设a0=0,分布式数据样本区间[a
i-1
,ai]中分布式数据记录的集合表示为b1,b1,
…bi
;则分布式数据的范围属性c1为:q>2,b
l
表示分布式数据查询记录属性值;
[0042]
(4)、通过(3)可得到c1,bq表示分布式数据中重复的数据记录;j表示分布式数据限定性值域;
[0043]
(5)、根据(1)到(4)获取c1过程可获取c2,m表示分布式数据读取时间,则可求得ci。
[0044]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的仅为本发明的优选例,并不用来限制本发明,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。