1.本技术涉及网络安全技术领域,尤其涉及一种基于参数压缩的面向联邦学习隐私推理攻击的防御方法。
背景技术:
2.联邦学习(federated learning)是一种机器学习框架,实现私有数据、共享模型,每个参与方客户端(可以简称客户端)拥有私有数据,多个客户端共同训练一个模型。每一轮训练,每个客户端上传其本地训练得到的模型参数(可以称为本地模型参数),通过中心服务器进行联邦平均获得全局模型参数,然后下发到各个客户端进行下一轮的训练。
3.随着联邦学习的流行,针对联邦学习的攻击手段也在日益增多。客户端使用生成对抗网络(generative adversarial network,gan)进行隐私推理攻击,以实现对其他联邦学习客户端的数据的窃取。联邦学习基于对多方参与者隐私保护的一个背景,即共享的模型不会泄露本地私有数据,所以恶意参与者通过获取联邦模型参数并使用gan去窃取被攻击者的数据的行为是需要被防御的。
4.目前,对于联邦学习的隐私保护的主要方法之一为差分隐私(differential privacy),其基本方法为在数据集中加入高斯噪声或拉普拉斯噪声,可以有效地防止隐私数据的泄露。但是为了有效的保护隐私数据,随着噪声的增加,全局模型的准确率却在下降。
技术实现要素:
5.有鉴于此,本技术提供一种基于参数压缩的面向联邦学习隐私推理攻击的防御方法。
6.具体地,本技术是通过如下技术方案实现的:
7.根据本技术实施例的第一方面,提供一种基于参数压缩的面向联邦学习隐私推理攻击的防御方法,包括:
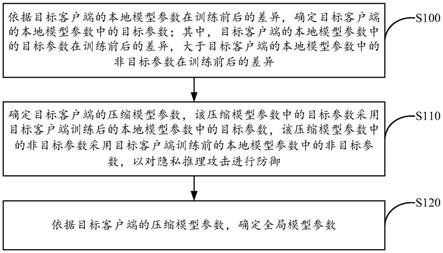
8.依据目标客户端的本地模型参数在训练前后的差异,确定所述目标客户端的本地模型参数中的目标参数;其中,所述目标客户端的本地模型参数中的目标参数在训练前后的差异,大于所述目标客户端的本地模型参数中的非目标参数在训练前后的差异;
9.确定所述目标客户端的压缩模型参数,所述压缩模型参数中的目标参数采用所述目标客户端训练后的本地模型参数中的目标参数,所述压缩模型参数中的非目标参数采用所述目标客户端训练前的本地模型参数中的非目标参数,以对隐私推理攻击进行防御;
10.依据所述目标客户端的压缩模型参数,确定全局模型参数。
11.根据本技术实施例的第二方面,提供一种电子设备,该电子设备包括:
12.处理器和机器可读存储介质,所述机器可读存储介质存储有能够被所述处理器执行的机器可执行指令;所述处理器用于执行机器可执行指令,以实现上述方法。
13.本技术实施例的基于参数压缩的面向联邦学习隐私推理攻击的防御方法,通过在
每一轮本地训练完成的情况下,依据客户端的本地模型参数在训练前后的差异,将训练前后差异较大的参数确定为需要保持训练后的状态的目标参数,以及训练前后差异相对较小的参数确定为需要恢复为训练前的状态的非目标参数,通过将训练前后差异大的目标参数保持为训练后的状态,以保证全局模型的准确性;通过将训练前后差异相对较小的非目标参数恢复为训练前的状态,截断完整模型参数中的部分参数信息,实现客户端本地模型参数的稀疏化,减少泄漏给攻击者的参数信息,可以有效防御攻击者从模型参数中推断出被攻击者的隐私数据信息,保护客户端的本地私有数据特征,实现针对隐私推理攻击的防御。
附图说明
14.图1为本技术一示例性实施例示出的一种基于参数压缩的面向联邦学习隐私推理攻击的防御方法的流程示意图;
15.图2a为本技术一示例性实施例示出的一种确定目标客户端的本地模型参数中的目标参数的流程示意图;
16.图2b为本技术一示例性实施例示出的另一种确定目标客户端的本地模型参数中的目标参数的流程示意图;
17.图3为本技术一示例性实施例示出的一种基于参数压缩的面向联邦学习隐私推理攻击的防御方法的流程示意图;
18.图4为本技术一示例性实施例示出的一种基于参数压缩的面向联邦学习隐私推理攻击的防御装置的结构示意图;
19.图5为本技术一示例性实施例示出的另一种基于参数压缩的面向联邦学习隐私推理攻击的防御装置的结构示意图;
20.图6为本技术一示例性实施例示出的一种电子设备的硬件结构示意图。
具体实施方式
21.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本技术的一些方面相一致的装置和方法的例子。
22.在本技术使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本技术。在本技术和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。
23.为了使本领域技术人员更好地理解本技术实施例提供的技术方案,下面先对本技术实施例涉及的部分术语进行简单说明。
24.联邦学习:联邦学习过程包括以下几个步骤:(1)、客户端的本地模型的初始化;(2)、对客户端的本地模型进行训练至模型收敛,上传本地模型参数值中心参数服务器;(3)、中心参数服务器聚合所有客户端上报的本地模型参数生成和分发新一轮初始参数至所有客户端。
25.gan隐私:攻击者从中心参数服务器下载联邦模型参数(即全局模型参数)以更新其本地模型的本地模型参数,通过创建一个新的联邦模型的副本作为鉴别器(d),并在d上
运行生成器(g)来实现对被攻击用户样本的模拟,并错误的标记生成的样本至本地模型,进而影响到联邦模型(即全局模型),迫使被攻击者更多的使用样本进行本地训练以实现对假的生成样本的区分。
26.序列top k:设有无序列表l,对其运行top k算法,得到该序列前k大的列表内容的序列。
27.non-iid数据(非独立同分布数据):联邦学习中多个客户端拥有的源训练数据以非独立同分布的形式存在,即对于两个客户端mi,mj∈m,i≠j,存在数据标签为k的数据
28.为了使本技术实施例的上述目的、特征和优点能够更加明显易懂,下面结合附图对本技术实施例中技术方案作进一步详细的说明。
29.请参见图1,为本技术实施例提供的一种基于参数压缩的面向联邦学习隐私推理攻击的防御方法的流程示意图,如图1所示,该基于参数压缩的面向联邦学习隐私推理攻击的防御方法可以包括以下步骤:
30.步骤s100、依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中的目标参数;其中,目标客户端的本地模型参数中的目标参数在训练前后的差异,大于目标客户端的本地模型参数中的非目标参数在训练前后的差异。
31.本技术实施例中,目标客户端并不特指某一固定的客户端,而是可以指代联邦学习系统中的任一客户端。
32.本技术实施例中,由于客户端的全部模型参数包含了关于客户端的私有关键训练数据的完整信息,而隐私推理攻击的攻击者正是通过被攻击者的模型参数来推断被攻击者的隐私数据信息,为了实现针对隐私推理攻击的防御,在依据客户端的本地模型参数确定全局模型参数之前,可以先对客户端的本地模型参数进行压缩,将参数稀疏化,保持部分参数为训练后的状态(即使用训练后的参数),并将其余参数恢复为训练前的状态(即使用训练前的参数),截断完整模型参数中的部分参数信息,实现客户端本地模型参数的稀疏化,减少泄漏给攻击者的参数信息,以保护各客户端的本地私有数据特征。
33.此外,考虑到训练前后参数的差异越大,通常表明该参数对模型性能优化的贡献越大,因而,为了在实现针对隐私推理攻击的防御的情况下,保持全局模型的准确性,在对本地模型参数进行压缩时,可以优先保持训练前后差异较大的参数为训练后的状态,对于训练前后差异相对较小的参数,则可以恢复为训练前的状态。
34.相应地,对于任一轮的模型训练,可以依据目标客户端训练前的本地模型参数与训练后的本地模型参数,确定目标客户端的本地模型参数在训练前后的差异,并依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中需要保持训练后的状态的参数(本文中称为目标参数)。
35.示例性的,目标客户端的本地模型参数中,目标参数在训练前后的差异大于非目标参数(即本地模型参数中除目标参数之外的其余参数)在训练前后的差异。
36.需要说明的是,本技术实施例中,若未特殊说明,所提及的训练前后均是针对一轮训练而言,即对于任一轮训练,客户端的训练前的本地模型参数是指开始训练时本地模型的参数,训练后的本地模型参数是指本轮训练至本地模型收敛后本地模型的参数。
37.步骤s110、确定目标客户端的压缩模型参数,该压缩模型参数中的目标参数采用
目标客户端训练后的本地模型参数中的目标参数,该压缩模型参数中的非目标参数采用目标客户端训练前的本地模型参数中的非目标参数,以对隐私推理攻击进行防御。
38.本技术实施例中,在确定了目标客户端的本地模型参数中的目标参数的情况下,对于本地模型参数中的目标参数,可以保持为训练后的状态,即使用训练后的本地模型参数中的参数值;对于本地模型参数中的非目标参数,则可以恢复为训练前的状态,即使用训练前的本地模型参数中的参数值,在实现针对隐私推理攻击的防御的情况下,保持全局模型的准确性。
39.步骤s120、依据目标客户端的压缩模型参数,确定全局模型参数。
40.本技术实施例中,对于任一客户端,均可以按照上述方式确定压缩模型参数,并在确定了各客户端的压缩模型参数的情况下,可以依据各客户端的压缩模型参数确定全局模型参数。
41.可见,在图1所示方法流程中,通过在每一轮本地训练完成的情况下,依据客户端的本地模型参数在训练前后的差异,将训练前后差异较大的参数确定为需要保持训练后的状态的目标参数,以及训练前后差异相对较小的参数确定为需要恢复为训练前的状态的非目标参数,通过将训练前后差异大的目标参数保持为训练后的状态,以保证全局模型的准确性;通过将训练前后差异相对较小的非目标参数恢复为训练前的状态,截断完整模型参数中的部分参数信息,实现客户端本地模型参数的稀疏化,减少泄漏给攻击者的参数信息,可以有效防御攻击者从模型参数中推断出被攻击者的隐私数据信息,保护客户端的本地私有数据特征,实现针对隐私推理攻击的防御。
42.在一些实施例中,上述基于参数压缩的面向联邦学习隐私推理攻击的防御方法可以应用于中心参数服务器。
43.如图2a所示,步骤s100中,依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中的目标参数,可以通过以下步骤实现:
44.步骤s101a、向各客户端下发全局模型参数;
45.步骤s102a、接收目标客户端上报的本地模型参数;
46.步骤s103a、以全局模型参数为目标客户端训练前的本地模型参数,以接收到的目标客户端上报的本地模型参数为目标客户端训练后的本地模型参数,确定目标客户端的本地模型参数在训练前后的差异;
47.步骤s104a、依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中的目标参数。
48.示例性的,以上述基于参数压缩的面向联邦学习隐私推理攻击的防御方法可以应用于中心参数服务器为例。
49.中心参数服务器可以依据各客户端上报的本地模型参数确定全局模型参数,并将所确定的全局模型参数下发至各客户端。
50.目标客户端接收到中心参数服务器下发的全局模型参数时,可以以接收到的全局模型参数为训练前的本地模型参数,对本地模型进行新一轮的训练,直至本地模型收敛,得到训练后的本地模型参数,并将训练后的本地模型参数上报至中心参数服务器。
51.中心参数服务器在接收到目标客户端上报的本地模型参数(训练后的本地模型参数)的情况下,可以以下发至各客户端的全局模型参数(本轮训练下发至各客户端的全局模
型参数)为目标客户端训练前的本地模型参数,以接收到的目标客户端上报的本地模型参数为训练后的本地模型参数,确定目标客户端的本地模型参数在训练前后的差异,并依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中的目标参数。
52.示例性的,中心参数服务器可以依据所确定的目标客户端的本地模型参数中的目标参数,对目标客户端上报的本地模型参数进行压缩,得到压缩模型参数。
53.示例性的,中心服务器在确定了各客户端的压缩模型参数的情况下,可以依据各客户端的压缩模型参数,确定最新的全局模型参数。
54.例如,可以将各客户端的压缩模型参数的平均值确定为最新的全局模型参数。
55.可见,通过在中心参数服务器侧实现客户端的本地模型参数的压缩,降低了对客户端的性能要求。
56.在一些实施例中,上述基于参数压缩的面向联邦学习隐私推理攻击的防御方法可以应用于客户端。
57.如图2b所示,步骤s100中,依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中的目标参数,可以通过以下步骤实现:
58.步骤s101b、接收中心参数服务器下发的全局模型参数;
59.步骤s102b、以该全局模型参数为训练前的本地模型参数,对本地模型进行训练,得到训练后的本地模型参数;
60.步骤s103b、依据本地模型参数在训练前后的差异,确定本地模型参数中的目标参数。
61.示例性的,以上述基于参数压缩的面向联邦学习隐私推理攻击的防御方法可以应用于客户端为例。
62.示例性的,中心参数服务器可以依据各客户端上报的本地模型参数确定全局模型参数,并将所确定的全局模型参数下发至各客户端。
63.目标客户端接收到中心参数服务器下发的全局模型参数时,可以以接收到的全局模型参数为训练前的本地模型参数,对本地模型进行新一轮的训练,直至本地模型收敛,得到训练后的本地模型参数。
64.目标客户端可以依据训练前的本地模型参数,以及训练后的本地模型参数,确定本地模型参数在训练前后的差异,并依据本地模型参数在训练前后的差异,确定本地模型参数中的目标参数。
65.可见,通过各客户端对本端的本地模型参数进行压缩,降低了中心参数服务器的处理负荷。
66.在一个示例中,步骤s130中,依据目标客户端的压缩模型参数,确定全局模型参数,可以包括:
67.将压缩模型参数上报至中心参数服务器,以使中心参数服务器依据接收到的各客户端上报的压缩模型参数,确定最新的全局模型参数。
68.示例性的,目标客户端在确定了本地模型参数中的目标参数的情况下,可以对训练后的本地模型参数进行压缩,得到压缩模型参数,并将压缩模型参数上报至中心参数服务器。
69.中心参数服务器在接收到各客户端上报的压缩模型参数的情况下,可以依据接收到的各客户端的压缩模型参数,确定最新的全局模型参数。
70.在一些实施例中,步骤s100中,依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中的目标参数,可以包括:
71.确定目标客户端的本地模型参数中各参数在训练前后的差值;
72.依据各参数在训练前后的差值的绝对值,将训练前后的差值的绝对值前k大的参数确定为目标参数,k为正整数。
73.示例性的,为了简化目标参数确定的处理操作,可以分别确定目标客户端的本地模型参数中各参数在训练前后的差值,并依据各参数在训练前后的差值的绝对值,将训练前后的差值的绝对值前k大的参数确定为目标参数。
74.例如,可以使用top k算法,从各参数在训练前后的差值的绝对值中,确定差值的绝对值前k大的参数。
75.在一些实施例中,步骤s100中,依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中的目标参数,可以包括:
76.对于目标客户端的本地模型任一层模型参数,确定该层模型参数中各参数在训练前后的差值;
77.依据该层模型参数中各参数在训练前后的差值的绝对值,将训练前后的差值的绝对值前k大的参数确定为目标参数,k为正整数。
78.示例性的,为了细化目标参数确定的粒度,优化压缩模型参数的训练性能,在确定目标参数时,可以分别针对本地模型各层模型参数进行确定。
79.示例性的,对于目标客户端的本地模型任一层模型参数,可以确定该层模型参数中各参数在训练前后的差值,并依据该层模型参数中各参数在训练前后的差值的绝对值,将训练前后的差值的绝对值前k大的参数确定为目标参数。
80.在一些实施例中,步骤s100中,依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中的目标参数,可以包括:
81.对于目标客户端的本地模型任一层模型参数的任一模型参数分量,确定该模型参数分量中各参数在训练前后的差值;
82.依据该模型参数分量中各参数在训练前后的差值的绝对值,将训练前后的差值的绝对值前k大的参数确定为目标参数,k为正整数。
83.示例性的,为了细化目标参数确定的粒度,优化压缩模型参数的训练性能,在确定目标参数时,可以分别针对本地模型各层模型参数的各模型参数分量进行确定。
84.示例性的,本地模型的任一层模型参数可以为一个二维矩阵,模型参数分量可以为该二维矩阵的一行或一列。
85.示例性的,对于目标客户端的本地模型任一层模型参数的任一模型参数分量,可以确定该模型参数分量中各参数在训练前后的差值,并依据该模型参数分量中各参数在训练前后的差值的绝对值,将训练前后的差值的绝对值前k大的参数确定为目标参数。
86.示例性的,上述实施例中,k可以依据预设压缩率以及参与排序的参数数量确定。
87.举例来说,以本地模型参数中全部参数参与排序为例,假设本地模型参数中参数的总数为n1,预设压缩率为r1,则k可以为n1*(1-r1)。
88.其中,若n1*(1-r1)为非整数,则可以通过向上取整、向下取整或四舍五入等方式得到整数k。
89.又举例来说,以模型参数分量中参数参与排序为例,假设模型参数分量中参数的数量为n2,预设压缩率为r2,则k可以为n2*(1-r2)。
90.其中,若n2*(1-r2)为非整数,则可以通过向上取整、向下取整或四舍五入等方式得到整数k。
91.需要说明的是,在本技术实施例中,针对本地模型参数整体、分别针对各单层模型参数或分别针对各单个模型参数分量进行目标参数确定的实施例中,k可以不同;针对单层模型参数确定目标参数的实施例中,不同层的模型参数中的目标参数的k也可以不同;针对单个模型参数分量确定目标参数的实施例中,不同模型参数分量中的目标参数的k也可以不同。
92.此外,确定本地模型参数中的目标参数的方式并不限于上述实施例中描述的方式,还可以通过其它方式确定本地模型参数中的目标参数,例如,依据本地模型参数中各模型在训练前后的差值的绝对值,将差值的绝对值超过预设阈值的参数确定为目标参数;或者,依据模型参数分量中各参数在训练前后的差值的绝对值,将差值的绝对值超过预设阈值的参数确定为目标参数;其中,不同模型参数分量中确定目标参数的预设阈值的取值可以不同。
93.在一些实施例中,上述基于参数压缩的面向联邦学习隐私推理攻击的防御方法可以应用于中心参数服务器。
94.步骤s100中,依据目标客户端的本地模型参数在训练前后的差异,确定目标客户端的本地模型参数中的目标参数之前,还可以包括:
95.对全局模型进行预训练,得到预训练后的全局模型参数;
96.将预训练后的全局模型参数下发至各客户端,作为各客户端的初始本地模型参数。
97.示例性的,由于在一轮训练过程中,中心参数服务器需要依据下发给客户端的全局模型参数,以及接收到的客户端上报的本地模型参数(训练后的本地模型参数),确定本地模型参数中的目标参数,进而实现模型参数压缩,因此,在首轮训练开始之前,中心参数服务器可以先对全局模型进行预训练,得到预训练后的全局模型参数,并将预训练后的全局模型参数下发至各客户端,作为各客户端的初始本地模型参数。
98.客户端依据初始本地模型参数完成本地模型训练的情况下,可以将训练后的本地模型参数上报至中心参数服务器,由中心参数服务器依据训练前后的本地模型参数进行模型参数压缩。
99.为了使本领域技术人员更好地理解本技术实施例提供的技术方案,下面结合具体实例对本技术实施例提供的技术方案进行说明。
100.本技术实施例提供了一种基于参数压缩的面向联邦学习隐私推理攻击的防御方法,主要方法流程可以包括:
101.对于每一轮训练,中心参数服务器获取客户端的本地模型参数;对于任一客户端(如上述目标客户端),统计该客户端的本地模型参数在训练前后的浮动情况,取浮动变化最大的部分参数,作为本轮训练中该客户端所要更新的参数(即上述目标参数),并参与中
心服务器的联邦平均,以确定全局模型参数。
102.通过依据参数训练前后的变化的对参数进行选择性更新,有效的隐藏了客户端的私有数据特征,降低了数据泄露的风险;同时极大程度的保证了模型对多种数据集的准确性,更加有效的提高了整个联邦学习系统的鲁棒性。
103.在该实施例中,联邦学习系统可以包括模块a~模块d;其中:
104.模块a,用于对原始数据集进行处理,对整个联邦学习系统进行初始化并分配非独立同分布数据。
105.模块b,用于对联邦学习的过程使用生成对抗网络实施隐私窃取攻击。
106.模块c,用于获取联邦学习的神经网络模型的每层具体参数信息。
107.模型d、用于筛选出相对浮动最大的部分参数,将此部分参数确定为需要更新的参数,进行模型参数压缩,依据压缩模型参数确定最新的全局模型参数。
108.下面结合图3对各模块的功能进行详细说明。
109.模块a:对原始数据集进行处理,对整个联邦学习系统进行初始化并分配非独立同分布数据。
110.示例性的,可以使用mnist(mixed national institute of standards and technology database)手写数字数据集,其中包括60000个实例训练集和10000个实例测试集。
111.示例性的,可以创建10个联邦学习的客户端,客户端使用相同模型,均为两层卷积神经网络;为客户端按顺序编号,同时将数据集中标签与客户端编号对应的数据分配给相应的客户端。
112.例如,每个客户端所拥有的数据量以及标签分布可以如表1所示:
113.表1
[0114][0115]
示例性的,可以使用warmup(热身)策略对全局模型进行预训练。
[0116]
例如,可以对全局模型预训练25轮得到初始的全局模型参数,将其作为所有客户端的初始化本地模型参数。
[0117]
需要说明的是,对全局模型进行预训练时使用的数据为全类别数据,即包括各客户端的数据的类别。
[0118]
其中,不同客户端的数据的类别不同。
[0119]
示例性的,同一客户端可以的数据可以包括一个或多个类别的数据。
[0120]
模块b:对联邦学习的过程使用生成对抗网络实施隐私窃取攻击。
[0121]
示例性的,假设攻击者a为编号为1的客户端,其拥有标签为0的数据。a意图窃取被攻击者v的标签为3的数据,被攻击者v的客户端编号为4。
[0122]
当联邦模型(即全局模型)和局部模型(即本地模型)的测试准确率均大于阈值且
联邦学习系统训练至少一轮,即所有客户端的本地模型均收敛时,隐私推理攻击便被启动。
[0123]
示例性的,该阈值可以设置为85%。
[0124]
攻击者可以在本地构建一个gan模型,通过为gan模型构建出的数据标注上错误的标签,得到“有毒数据”。攻击者使用有毒数据进行本地模型训练,使被攻击者v提供更多数据特征,然后攻击者使用v提供的更丰富的数据特征利用gan生成更准确地照片,循环往复,得到被攻击者v的私有数据的目标类别信息。
[0125]
模块c:获取联邦学习的神经网络模型的每层具体参数信息。
[0126]
示例性的,在每一个联邦学习参与者将客户端训练后的本地模型参数上传至中心参数服务器之前,可以使用keras(一种开源人工神经网络库)获取本地模型所有层的参数,以列表存储每层的参数。
[0127]
示例性的,参数可以以ndarray(用于存放同类型元素的多维数组)格式保存。
[0128]
模块d:筛选出相对浮动最大的部分参数,将此部分参数确定为需要更新的参数,进行模型参数压缩,依据压缩模型参数确定最新的全局模型参数。
[0129]
示例性的,计算本轮客户端训练得到的本地模型参数(即训练后的本地模型参数)与本轮开始时的本地模型参数(即训练前的本地模型参数)的差值,以绝对值的格式存储差值e。使用top k算法获取e中排列靠前的序列列表。
[0130]
例如,假设预设压缩率为99.9%,则可以取差值e序列中前0.1%(即1-99.9%)大的差值,将对应的参数确定为目标参数。
[0131]
示例性的,对于本地模型中的任一层模型,其参与训练的参数的数量可以通过利用深度学习框架获取参数维度信息,并依据参数维度信息确定。
[0132]
对于任一客户端,本地模型参数中的目标参数保持为训练后的状态,非目标参数恢复为训练前的状态。
[0133]
示例性的,模块d可以通过以下流程实现模型参数压缩:
[0134]
4.1、对于w的第j个参数分量w[j],计算其与上一轮的w[j]的差值e;
[0135]
示例性的,w为本地模型的任一层网络的模型参数,其可以为二维矩阵,w[j]可以为该二维矩阵中的第j行或第j列。
[0136]
4.2、将w[j]中e的绝对值最大的k个参数确定为目标参数。
[0137]
4.3、将w[j]中该k个参数(即目标参数)保持为训练后的状态,w[j]中其余参数(即非目标参数)恢复为训练前的状态。
[0138]
4.4、各参数分量均压缩完毕得到该客户端压缩后的本地模型参数(即压缩模型参数,可以记为w
compressed
)。
[0139]
可见,在该实施例中,以较小的计算量,实现了在联邦学习下针对gan隐私推理攻击的有效防御,同时最大程度的保证联邦模型的准确率不受影响。
[0140]
以上对本技术提供的方法进行了描述。下面对本技术提供的装置进行描述:
[0141]
请参见图4,为本技术实施例提供的一种基于参数压缩的面向联邦学习隐私推理攻击的防御装置的结构示意图,如图4所示,该基于参数压缩的面向联邦学习隐私推理攻击的防御装置可以包括:
[0142]
第一确定单元410,用于依据目标客户端的本地模型参数在训练前后的差异,确定所述目标客户端的本地模型参数中的目标参数;其中,所述目标客户端的本地模型参数中
的目标参数在训练前后的差异,大于所述目标客户端的本地模型参数中的非目标参数在训练前后的差异;
[0143]
第二确定单元420,用于确定所述目标客户端的压缩模型参数,所述压缩模型参数中的目标参数采用所述目标客户端训练后的本地模型参数中的目标参数,所述压缩模型参数中的非目标参数采用所述目标客户端训练前的本地模型参数中的非目标参数,以对隐私推理攻击进行防御;
[0144]
第三确定单元430,依据所述目标客户端的压缩模型参数,确定全局模型参数。
[0145]
在一些实施例中,当所述装置部署于中心参数服务器时,
[0146]
所述第一确定单元410依据目标客户端的本地模型参数在训练前后的差异,确定所述目标客户端的本地模型参数中的目标参数,包括:
[0147]
向各客户端下发全局模型参数;
[0148]
接收所述目标客户端上报的本地模型参数;
[0149]
以所述全局模型参数为所述目标客户端训练前的本地模型参数,以接收到的所述目标客户端上报的本地模型参数为所述目标客户端训练后的本地模型参数,确定所述目标客户端的本地模型参数在训练前后的差异;
[0150]
依据所述目标客户端的本地模型参数在训练前后的差异,确定所述目标客户端的本地模型参数中的目标参数。
[0151]
在一些实施例中,当所述装置部署于客户端时,
[0152]
所述第一确定单元410依据目标客户端的本地模型参数在训练前后的差异,确定所述目标客户端的本地模型参数中的目标参数,包括:
[0153]
接收中心参数服务器下发的全局模型参数;
[0154]
以所述全局模型参数为训练前的本地模型参数,对本地模型进行训练,得到训练后的本地模型参数;
[0155]
依据本地模型参数在训练前后的差异,确定本地模型参数中的目标参数。
[0156]
在一些实施例中,所述第三确定单元430依据所述目标客户端的压缩模型参数,确定全局模型参数,包括:
[0157]
将所述压缩模型参数上报至中心参数服务器,以使所述中心参数服务器依据接收到的各客户端上报的压缩模型参数,确定最新的全局模型参数。
[0158]
在一些实施例中,所述第一确定单元410依据目标客户端的本地模型参数在训练前后的差异,确定所述目标客户端的本地模型参数中的目标参数,包括:
[0159]
确定所述目标客户端的本地模型参数中各参数在训练前后的差值;
[0160]
依据各参数在训练前后的差值的绝对值,将训练前后的差值的绝对值前k大的参数确定为目标参数,k为正整数。
[0161]
在一些实施例中,所述第一确定单元410依据目标客户端的本地模型参数在训练前后的差异,确定所述目标客户端的本地模型参数中的目标参数,包括:
[0162]
对于所述目标客户端的本地模型任一层模型参数,确定该层模型参数中各参数在训练前后的差值;
[0163]
依据该层模型参数中各参数在训练前后的差值的绝对值,将训练前后的差值的绝对值前k大的参数确定为目标参数,k为正整数。
[0164]
在一些实施例中,所述第一确定单元410依据目标客户端的本地模型参数在训练前后的差异,确定所述目标客户端的本地模型参数中的目标参数,包括:
[0165]
对于所述目标客户端的本地模型任一层模型参数的任一模型参数分量,确定该模型参数分量中各参数在训练前后的差值;
[0166]
依据该模型参数分量中各参数在训练前后的差值的绝对值,将训练前后的差值的绝对值前k大的参数确定为目标参数,k为正整数。
[0167]
在一些实施例中,k依据预设压缩率以及参与排序的参数数量确定。
[0168]
在一些实施例中,当所述装置部署于中心参数服务器时,
[0169]
如图5所示,所述装置还包括:
[0170]
预训练单元440,用于对全局模型进行预训练,得到预训练后的全局模型参数;将所述预训练后的全局模型参数下发至各客户端,作为各客户端的初始本地模型参数。
[0171]
对应地,本技术还提供了图4或图5所示装置的硬件结构。参见图6,该硬件结构可包括:处理器和机器可读存储介质,机器可读存储介质存储有能够被所述处理器执行的机器可执行指令;所述处理器用于执行机器可执行指令,以实现本技术上述示例公开的方法。
[0172]
基于与上述方法同样的申请构思,本技术实施例还提供一种机器可读存储介质,所述机器可读存储介质上存储有若干机器可执行指令,所述机器可执行指令被处理器执行时,能够实现本技术上述示例公开的方法。
[0173]
示例性的,上述机器可读存储介质可以是任何电子、磁性、光学或其它物理存储装置,可以包含或存储信息,如可执行指令、数据,等等。例如,机器可读存储介质可以是:ram(radom access memory,随机存取存储器)、易失存储器、非易失性存储器、闪存、存储驱动器(如硬盘驱动器)、固态硬盘、任何类型的存储盘(如光盘、dvd等),或者类似的存储介质,或者它们的组合。
[0174]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个......”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0175]
以上所述仅为本技术的较佳实施例而已,并不用以限制本技术,凡在本技术的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本技术保护的范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。