1.本发明涉及教育演示领域,具体地,涉及一种利用增强现实佩戴设备可视化智能互动教考系统和方法。
背景技术:
2.对医护人员进行操作练习和考核是非常重要的,因此,市场上诞生了各种供医护人员操作练习的设备。专利文献cn211979995u公开了一种胰岛素皮下注射可穿戴练习操作装置,专门应用于胰岛素皮下注射项目。
3.正如上述的专利文献所公开的装置,现有的医护人员操作练习的设备需要针对于每一种训练项目分别进行设计,导致目前各种操作练习的设备种类繁多,使用和存放不便。
技术实现要素:
4.针对现有技术中的缺陷,本发明的目的是提供一种利用增强现实佩戴设备可视化智能互动教考系统和方法。
5.根据本发明提供的一种利用增强现实佩戴设备可视化智能互动教考系统,包括:
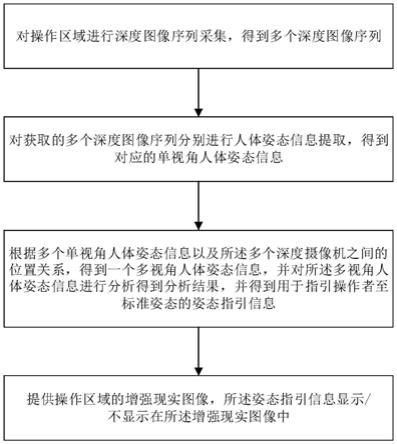
6.多个深度摄像机:对操作区域进行深度图像序列采集,得到多个深度图像序列;
7.边缘计算节点:连接所述深度摄像机,对获取的多个深度图像序列分别进行人体姿态信息提取,得到对应的单视角人体姿态信息;
8.云服务器:根据多个单视角人体姿态信息以及所述多个深度摄像机之间的位置关系,得到一个多视角人体姿态信息,并对所述多视角人体姿态信息进行分析得到分析结果,并得到用于指引操作者至标准姿态的姿态指引信息;所述多视角人体姿态信息是多个单视角人体姿态信息的集合;在对所述多视角人体姿态信息进行分析中,将多个单视角人体姿态信息分别与标准姿态进行比较,得出多个初步的姿态指引信息,再根据多个初步的姿态指引信息得到用于指引操作者至标准姿态的姿态指引信息;
9.增强现实佩戴设备:提供所述操作区域的增强现实图像,所述姿态指引信息显示/不显示在所述增强现实图像中。
10.优选地,所述多个深度摄像机分布设置于所述操作区域的周围不同位置,每个所述深度摄像机连接一个或多个所述边缘计算节点。
11.优选地,所述多个深度摄像机之间的位置关系的获取方式包括:
12.根据所述多个深度摄像机采集到的深度图像序列中人体上的固定尺寸及图案的多个标记物的几何形变,得到所述多个深度摄像机之间的位置关系。
13.在所述根据多个初步的姿态指引信息得到用于指引操作者至标准姿态的姿态指引信息中,将多个深度摄像机在圆周方向上均匀布置,操作者位于圆周的圆心位置,统计各姿势的初步的姿态指引信息的数量,以数量最多的初步的姿态指引信息对应的姿态认为是当前操作者的实际姿态,根据实际姿态指引操作者至标准姿态;
14.若数量最多的初步的姿态指引信息对应的姿态有多个,则按照数量递减方向,以
首个出现的数量第n多的初步的姿态指引信息对应的姿态的只有一个的姿态,认定为是当前操作者的实际姿态;若仍不能认定,则提示姿态不规范无法识别。
15.优选地,还包括触控屏,用于系统控制以及增强现实图像、所述分析结果的显示。
16.优选地,所述姿态指引信息的获取包括:将所述多视角人体姿态信息与预设的标准姿态信息的相似度进行比对。
17.根据本发明提供的一种利用增强现实佩戴设备可视化智能互动教考方法,包括:
18.采集步骤:通过多个深度摄像机对操作区域进行深度图像序列采集,得到多个深度图像序列;
19.单视角人体姿态获取步骤:连接所述深度摄像机,对获取的多个深度图像序列分别进行人体姿态信息提取,得到对应的单视角人体姿态信息;
20.多视角人体姿态获取步骤:根据多个单视角人体姿态信息以及所述多个深度摄像机之间的位置关系,得到一个多视角人体姿态信息,并对所述多视角人体姿态信息进行分析得到分析结果,并得到用于指引操作者至标准姿态的姿态指引信息;所述多视角人体姿态信息是多个单视角人体姿态信息的集合;在对所述多视角人体姿态信息进行分析中,将多个单视角人体姿态信息分别与标准姿态进行比较,得出多个初步的姿态指引信息,再根据多个初步的姿态指引信息得到用于指引操作者至标准姿态的姿态指引信息;
21.显示步骤:提供所述操作区域的增强现实图像,所述姿态指引信息显示/不显示在所述增强现实图像中。
22.优选地,所述多个深度摄像机分布设置于所述操作区域的周围不同位置,每个所述深度摄像机连接一个或多个所述边缘计算节点。
23.优选地,所述多个深度摄像机之间的位置关系的获取方式包括:
24.根据所述多个深度摄像机采集到的深度图像序列中人体上的固定尺寸及图案的多个标记物的几何形变,得到所述多个深度摄像机之间的位置关系。在所述根据多个初步的姿态指引信息得到用于指引操作者至标准姿态的姿态指引信息中,将多个深度摄像机在圆周方向上均匀布置,操作者位于圆周的圆心位置,统计各姿势的初步的姿态指引信息的数量,以数量最多的初步的姿态指引信息对应的姿态认为是当前操作者的实际姿态,根据实际姿态指引操作者至标准姿态;
25.若数量最多的初步的姿态指引信息对应的姿态有多个,则按照数量递减方向,以首个出现的数量第n多的初步的姿态指引信息对应的姿态的只有一个的姿态,认定为是当前操作者的实际姿态;若仍不能认定,则提示姿态不规范无法识别。
26.优选地,采用触控屏,用于系统控制以及增强现实图像、所述分析结果的显示。
27.优选地,所述姿态指引信息的获取包括:将所述多视角人体姿态信息与预设的标准姿态信息的相似度进行比对。
28.与现有技术相比,本发明具有如下的有益效果:
29.本发明通过增强现实技术实现了医护人员操作练习的教学和考核,填补了现有技术的空白;
30.通过采用多视角深度摄像机的结构,解决了人体运动时肢体互相遮挡的问题;
31.通过采用“摄像头-边缘计算节点-服务器”的结构,解决了多路深度图像数据流占用云服务器大量带宽的问题,提升网络运行效率,降低私有云部署成本;
32.通过采用私有云服务器的结构,解决了人体运动数据在公网流通的数据安全问题。
附图说明
33.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
34.图1为本发明的结构示意图;
35.图2为本发明的结构模块图;
36.图3为本发明的工作原理图;
37.图4为本发明的工作流程图。
具体实施方式
38.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
39.如图1、图2和图3所示,本发明提供的一种利用增强现实佩戴设备可视化智能互动教考系统,包括:多个深度摄像机1、多个边缘计算节点4、私有云服务器5、触控大屏2、识别场地3、配准标记物及增强现实佩戴设备。在具备充足白光照明的识别场地3周围不同视角设置多个深度摄像机1,摄像机分组连接至多个边缘计算节点4,所有边缘计算节点4通过网络接入私有云服务器5,服务器将数据实时传输至场地一侧设置的触控大屏2。
40.设备安置:所述深度摄像机1布置在识别场地3周围不同位置;在附近的网络汇聚点布置边缘计算节点4,每台所述边缘计算节点可连接多个深度摄像机1;所述边缘计算节点通过网络连接至私有云服务器5;所述场地一侧设置触控大屏2,连接至私有云服务器5。增强现实佩戴设备通过wifi连接私有云服务器5。
41.深度摄像机标定:手持印有固定尺寸及图案的标记物站立在多个所述深度摄像机1均可识别位置,待所有摄像机均识别到标记物后遮盖标记物。标记物在各所述深度摄像机1中的标记物影像被传输至所述私有云服务器5,所述服务器匹配各摄像机所拍摄影像时间码后,依据各视角下同一时间内标记物的几何变形,求得所述深度摄像机1相互之间的位置关系和距离。
42.数据采集:多个所述深度摄像机1同步采集人体运动,各自实时输出深度图像序列至所述边缘计算节点4。
43.单视角人体姿态识别:所述边缘计算节点4实时接收每路所述深度摄像机1提供的深度图像序列数据后,通过内置的人工智能模型提取每个视角的人体姿态信息,并实时传输至所述私有云服务器5。
44.多视角人体姿态识别:所述私有云服务器5接收到各个视角的人体姿态信息后,依据深度摄像机标定阶段获取的信息拼接多个视角信息,从而获得更完整、更少遮挡的多视角人体姿态信息。
45.动作分析:所述私有云服务器5依据人工智能判断实时多视角人体姿态信息分段、
分类为各种动作并进行分析。
46.对所述多视角人体姿态信息进行分析得到分析结果,并得到用于指引操作者至标准姿态的姿态指引信息,增强现实佩戴设备提供操作区域的增强现实图像,姿态指引信息显示/不显示在增强现实图像中。
47.在一个优选例中,所述多视角人体姿态信息是多个单视角人体姿态信息的集合;在对所述多视角人体姿态信息进行分析中,将多个单视角人体姿态信息分别与标准姿态进行比较,得出多个初步的姿态指引信息,再根据多个初步的姿态指引信息得到用于指引操作者至标准姿态的姿态指引信息;在所述根据多个初步的姿态指引信息得到用于指引操作者至标准姿态的姿态指引信息中,将多个深度摄像机在圆周方向上均匀布置,操作者位于圆周的圆心位置,统计各姿势的初步的姿态指引信息的数量,以数量最多的初步的姿态指引信息对应的姿态认为是当前操作者的实际姿态,根据实际姿态指引操作者至标准姿态;若数量最多的初步的姿态指引信息对应的姿态有多个,则按照数量递减方向,以首个出现的数量第n多的初步的姿态指引信息对应的姿态的只有一个的姿态,认定为是当前操作者的实际姿态;若仍不能认定,则提示姿态不规范无法识别。例如,共有五个深度摄像机,三个深度摄像机得到的姿态是站立,两个深度摄像机得到的姿态是蹲下,则认为当前操作者的实际姿态是站立。又例如,共有五个深度摄像机,两个深度摄像机得到的姿态是站立,另两个深度摄像机得到的姿态是蹲下,剩余一个深度摄像机得到的姿态是半蹲,则数量最多的姿势有两个,即站立两个,蹲下两个,此时首次出现的数量第二多的姿态是半蹲,则认定半蹲为当前操作者的实际姿态,原因是当数量最多的初步的姿态指引信息对应的姿态有多个时,认为操作者当前的实际姿态与这些姿态之间均不存在类似的姿态。
48.如图4所示,本发明还提供的一种利用增强现实佩戴设备可视化智能互动教考方法,包括:
49.采集步骤:通过多个深度摄像机对操作区域进行深度图像序列采集,得到多个深度图像序列。
50.单视角人体姿态获取步骤:连接所述深度摄像机,对获取的多个深度图像序列分别进行人体姿态信息提取,得到对应的单视角人体姿态信息。
51.多视角人体姿态获取步骤:根据多个单视角人体姿态信息以及所述多个深度摄像机之间的位置关系,得到一个多视角人体姿态信息,并对所述多视角人体姿态信息进行分析得到分析结果,并得到用于指引操作者至标准姿态的姿态指引信息。所述多视角人体姿态信息是多个单视角人体姿态信息的集合;在对所述多视角人体姿态信息进行分析中,将多个单视角人体姿态信息分别与标准姿态进行比较,得出多个初步的姿态指引信息,再根据多个初步的姿态指引信息得到用于指引操作者至标准姿态的姿态指引信息;
52.显示步骤:提供所述操作区域的增强现实图像,所述姿态指引信息显示/不显示在所述增强现实图像中。
53.所述多个深度摄像机分布设置于所述操作区域的周围不同位置,每个所述深度摄像机连接一个或多个所述边缘计算节点。
54.所述多个深度摄像机之间的位置关系的获取方式包括:
55.根据所述多个深度摄像机采集到的深度图像序列中人体上的固定尺寸及图案的多个标记物的几何形变,得到所述多个深度摄像机之间的位置关系;
56.在所述根据多个初步的姿态指引信息得到用于指引操作者至标准姿态的姿态指引信息中,将多个深度摄像机在圆周方向上均匀布置,操作者位于圆周的圆心位置,统计各姿势的初步的姿态指引信息的数量,以数量最多的初步的姿态指引信息对应的姿态认为是当前操作者的实际姿态,根据实际姿态指引操作者至标准姿态;
57.若数量最多的初步的姿态指引信息对应的姿态有多个,则按照数量递减方向,以首个出现的数量第n多的初步的姿态指引信息对应的姿态的只有一个的姿态,认定为是当前操作者的实际姿态;若仍不能认定,则提示姿态不规范无法识别。
58.采用触控屏,用于系统控制以及增强现实图像、所述分析结果的显示。
59.所述姿态指引信息的获取包括:将所述多视角人体姿态信息与预设的标准姿态信息的相似度进行比对。
60.本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
61.以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。