1.本发明涉及无线通信领域,具体来说,本发明涉及一种基于深度强化学习的软件定义空天地一体化网络路由优化方法。
背景技术:
2.随着通信技术的发展和互联网业务需求的增长,用户对网络通信范围和网络通信质量的要求不断提高。传统的地基网络具备良好的通信质量,但无法覆盖森林、山地、海洋等环境恶劣的地区。天基网络通过卫星作为中继节点可以保证信号的全球覆盖,但是由于太空环境的影响,天基网络存在长时延、高误码率等问题。随着用户需求的不断提高,将地基网络和天基网络结合的空天地一体化网络成为有效的解决方法之一。空天地一体化网络具有覆盖范围大、通信速度快、可靠性高等特点,能够满足不同领域对网络通信的需求。然而,由于网络拓扑动态变化、链路质量差等问题,空天地一体化网络需要建立有效的路由优化策略以提高网络的性能。
3.由于空天地一体化网络中拓扑动态变化、误码率高、传输时延大等复杂特征,导致网络很难在保障业务服务质量的基础上构建稳定的端到端传输路径。由于无法实时应对动态变化的拓扑,传统的静态拓扑路由算法不能根据节点和链路状态的实时变化调整相应的路由策略。而动态拓扑路由算法对网络的硬件条件要求较高,且占用大量的节点资源,不能完全适应空天地一体化网络中节点资源有限的特点。因此,在适应动态变化的空天地一体化网络拓扑的情况下实现数据转发成为一个亟需解决的问题。
4.近年来,深度强化学习算法被广泛应用于多种场景。它在强化学习的基础上结合了深度学习,在保证决策能力的同时提高了对环境的感知能力,可以直接控制从原始输入到输出的全部过程。根据优化过程中动作的选取方式的不同,深度强化学习可以分为基于值函数的深度强化学习和基于策略梯度的深度强化学习。由于网络通信技术的发展以及新兴网络架构的提出,深度强化学习在空天地一体化网络架构下实现动态路由在软硬件条件上都具备了可能性。因此,将深度强化学习算法运用到网络路由模块上,为空天地一体化网络路由优化提供了新的思路。
技术实现要素:
5.针对目前存在的问题,本发明提出一种基于深度强化学习的软件定义空天地一体化网络路由优化方法,从而适应动态的网络服务质量需求,提高数据传输效率,最终实现网络路由的优化。
6.区别于现有的处理方法,本发明的改进方法是:(1)根据空天地一体化网络的特点,建立深度强化学习模型,从而更好的感知网络环境,并提高网络路由的稳定性和可靠性;(2)利用长短期记忆网络处理状态之间内在关系的能力提取相邻状态间的时序特征,从而提高了深度强化学习模型的时间敏感性;(3)利用ksp算法计算备选路径集合,并根据控
制器检测的网络状态选择合适的路径,从而避免了频繁使用单个路径导致的局部拥塞问题。本发明与现有的技术相比,可以根据网络链路状态实现自适应路由策略,在获取最短路径的同时实现网络全局的负载均衡。
7.本发明所述的方法有益效果是:(1)根据空天地一体化网络特性建立深度强化学习模型,提高路由算法对动态拓扑的适应能力;(2)在平均端到端时延和吞吐量上都有显著提升,提高空天地一体化网络的数据传输效率,具有较高的理论价值和实际意义。
附图说明
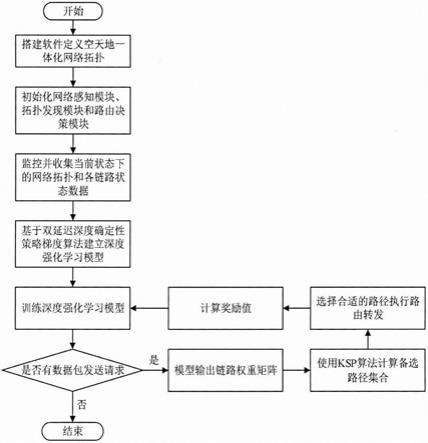
8.图1是本发明的流程图。
9.图2是本发明中的神经网络结构图。
10.图3是实施例中的软件定义空天地一体化网络结构图。
11.图4是实施例中本发明的路由优化算法与其他路由优化算法的标准化吞吐量的仿真对比图。
12.图5是实施例中本发明的路由优化算法与其他路由优化算法的平均端到端时延的仿真对比图。
具体实施方式
13.下面结合附图1的流程,详细说明本发明一种基于深度强化学习的软件定义空天地一体化网络路由优化方法的具体实施方式。
14.如图1所示,本发明提供的一种基于深度强化学习的软件定义空天地一体化网络路由优化方法,包括:
15.步骤1:根据软件定义网络思想和空天地一体化网络节点参数搭建软件定义空天地一体化网络拓扑,并初始化拓扑发现模块、网络感知模块与路由决策模块。
16.步骤2:通过步骤1中初始化的拓扑发现模块和网络感知模块,控制器监控当前状态下的网络拓扑和当前网络中各链路状态数据,并将收集到的链路状态数据保存为状态矩阵l。
17.步骤3:将网络传输过程建模成马尔可夫决策过程,并基于双延迟深度确定性策略梯度算法建立深度强化学习模型,将步骤2中的状态矩阵l输入到深度强化学习模型中,通过训练输出网络拓扑的链路权重矩阵w。
18.深度强化学习模型的建立结合了空天地一体化网络的特点,具体的建立过程如下:
19.首先,将网络传输过程建模成马尔可夫决策过程,需要设计的参数包括:状态s,动作a,奖励值r;
20.a、将控制器收集到的状态矩阵l作为马尔可夫决策过程的状态s,状态s表示如下:
[0021][0022]
其中,b
ij
和d
ij
分别是链路l
ij
的带宽和延迟,n是节点的总数。
[0023]
b、将深度强化学习模型输出的链路权重矩阵w作为马尔可夫决策过程的动作a,动作a表示如下:
[0024][0025]
其中,w
ij
是经过actor网络输出的链路l
ij
的权值。
[0026]
c、引入网络中各链路的带宽和延迟以计算马尔可夫决策过程的奖励值r,奖励值r的计算公式如下:
[0027][0028]
其中,α和β是根据路由策略决定的调整因子。
[0029]
然后,由于深度强化学习模型基于双延迟深度确定性策略梯度算法,因此需要设计合理的神经网络结构进行价值函数的更新。在本实施例中,神经网络结构如图2所示;
[0030]
双延迟深度确定性策略梯度算法的神经网络模块包含actor模块、critic_1模块和critic_2模块,每个模块都由一个在线网络和一个目标网络组成,且在线网络和目标网络的神经网络结构相同,actor模块、critic_1模块和critic_2模块的网络结构如下:
[0031]
a、actor模块包括一层长短期记忆网络(long short-term memory,lstm)层和三层全连接(fully connected,fc)层网络,actor网络的输入为状态矩阵l,actor网络的输出为网络中各链路权重组成的权重矩阵w。
[0032]
b、critic_1模块和critic_2模块包括一层长短期记忆网络和三层全连接层网络,critic_1网络和critic_2网络的输入为两部分,分别是与actor网络输入相同的状态矩阵l和actor网络输出的权重矩阵w,critic_1模块和critic_2模块的输出为当前状态下对应动作的q值。
[0033]
步骤4:将步骤3中深度强化学习模型输出的链路权重矩阵w输入到步骤2初始化的路由决策模块中,通过执行k条最短路径算法(k shortest paths algorithm,ksp)获取一条最优路径,并进行数据转发,同时计算当前状态的奖励值r
t
。
[0034]
a、利用ksp算法计算出k条可用路径,并组成备选路径集合p,备选路径集合p表示如下:
[0035]
p={pi|i=1,2,
…
,k}
ꢀꢀꢀ
(4)
[0036]
其中,pi是备选路径集合中的第i条路径。
[0037]
b、对备选路径集合中的路径按照路径权重从低到高排序,选择路径权重最低的一条路径作为数据包传输的最优路径。
[0038]
c、在传输过程中,当控制器监控到路径中某节点的可用带宽小于数据包大小时,从备选路径集合中选择次优路径进行转发。
[0039]
步骤5:将步骤2获取的当前时隙t的状态矩阵l
t
和与下一个时隙的状态矩阵l
t 1
、步骤3输出的当前时隙t的链路权重矩阵w
t
以及步骤4计算的当前状态的奖励值r
t
以(l
t
,w
t
,r
t
,l
t 1
)的形式输入到深度强化学习模型的经验回放池中,同时采用随机采样策略进行参
数更新,并根据更新的参数进行迭代训练直到模型达到收敛。
[0040]
下文通过一个实例对本发明进行分析。空天地一体化网络拓扑结构由3个地球同步轨道(geosynchronous earth orbit,geo)卫星、70颗低轨道(low earth orbit,leo)卫星和16个地面站组成。其中geo卫星的轨道高度为36000千米,轨道个数为1,轨道倾角0
°
。leo卫星的轨道高度为550千米,轨道个数为7,轨道倾角53
°
。同时在leo卫星上部署虚拟交换机,在geo卫星上部署控制器从而实现软件定义空天地一体化网络,如图3所示。
[0041]
本发明一共进行150次的数据传输仿真实验,并使用bwm-ng工具和ping工具在实验过程中监测本发明提出的方法与对比方法的标准化吞吐量和平均端到端时延,监测的结果如图4和图5所示。对比基于深度确定性策略梯度算法的路由算法的结果,本发明提出的算法具有更低的平均端到端时延和更高的标准化吞吐量。本发明提出的算法可以根据网络状态自适应的调整路由策略,可以很好的适应动态变化的空天地一天化网络场景,具有较高的理论价值和实际意义。
[0042]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所做的等效结构或等流程变换,或直接或间接运用在相关技术领域,均同理包括在本发明的专利保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
