一种从web访问日志提取web资产的方法
技术领域
1.本发明涉及网络信息技术,特别是涉及一种从web访问日志提取web资产的方法。
背景技术:
2.随着互联网技术的飞速发展,网络已经深入社会生活的各个方面,用户正常访问网站以及黑客利用web应用缺陷对服务器发起攻击都会在网站遗留web日志记录,因此在网络服务器端存储了海量的web访问日志。面对如此宝贵的资源,如何分析和发现蕴藏在其中的信息和知识并加以利用,是当前互联网企业面临的主要需求之一。
3.需要说明的是,在上述背景技术部分公开的信息仅用于对本技术的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现要素:
4.目前,对web访问日志的分析主要集中在通过统计分析、文本挖掘、关联分析等技术,得到系统的运行状态、性能指标、用户的访问行为等有价值的知识,从而提高网站的性能,改善网站的结构,发现用户的意图与偏好,另外,通过分析用户异常行为也可为网站漏洞挖掘、入侵攻击防范等提供依据。但是,缺乏通过web日志分析web应用本身的方法。本发明的主要目的在于提供一种从web访问日志提取web资产的方法。
5.为实现上述目的,本发明采用以下技术方案:
6.一种从web访问日志提取web资产的方法,包括如下步骤:
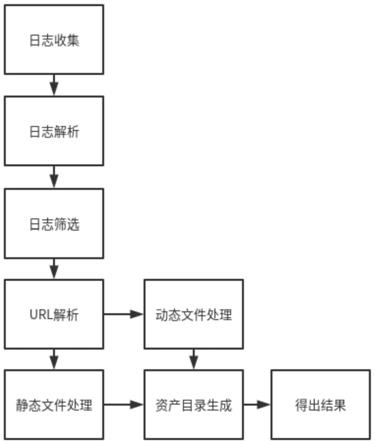
7.s1.日志收集:收集web访问日志;
8.s2.日志解析:解析web访问日志,提取出web请求的url、状态码、响应体大小;
9.s3.日志筛选:根据状态码筛选出请求成功的访问记录;
10.s4.url解析:参照标准url格式,对访问记录中的url进行解析,解析提取资产对应的协议、域名/ip、端口、路径及文件名,在url包含请求参数的情况下还提取请求参数;
11.s5.静态/动态文件判断:通过web访问记录中,同一资产所有记录的文件大小是否保持一致和文件后缀名判断文件为静态文件还是动态文件;若同一资产所有记录的文件大小都保持一致,且文件名后缀属于静态文件后缀,则将该资产判定为静态文件,否则为动态文件;
12.s6.静态/动态文件处理:对于静态文件,文件大小记录为资产文件大小;对于动态文件,根据其参数列表生成函数签名来表示其动态性及多态性;
13.s7.资产目录生成:根据资产的文件名、文件大小及其路径处理成树状目录结构,即网站对应的web资产。
14.进一步地:
15.步骤s2中,对收集到的日志,使用空格作为分隔符,分隔成数组,并从中提取url、状态码、响应体大小。
16.步骤s2具体包括如下步骤:
17.逐行读取日志;
18.使用空格分割日志行,结果为一个字段列表;
19.从上一步获得的字段列表中找出url、状态码、响应体大小,组装成一个日志访问记录对象;
20.将所有日志行解析出的日志访问记录对象存储到一个数组(records)中。
21.步骤s4具体包括如下步骤:
22.a.判断url中是否包含“?”,如果包含“?”,进入步骤b;如果不包含“?”,将url记为path,进入步骤d;
23.b.以url中从左到右出现的第一个“?”为界,将url一分为二,前半部分记为path,后半部分记为query_string;
24.c.判断query_string中是否包含“&”,如果不包含“&”,说明有且仅有一个参数,此时query_string的格式为“参数名=参数值”,其中参数值可能为空;如果包含“&”,说明含有两个以上的参数,使用“&”为分隔,将query_string分割成一个参数列表,格式为“参数名=参数值”,其中参数值可能为空;从query_string提取出由参数名构成的列表,并按照字母顺序对其排序,格式为[参数名1,参数名2,参数名3...],将该列表记为params;
[0025]
d.如果path的内容为“/”,说明为根目录,文件名为“index”;如果path内容不为“/”,使用“/”为分隔,将path分割成一个目录名列表,格式为[目录名1,目录名2,...];
[0026]
e.从左到右对目录名列表中的每一个目录进行检查,如果目录名中包含“.”,则将目录名解释为“文件名.扩展名”的格式;检查扩展名是否在配置的动态文件类型中,如果是,则以当前目录名为分隔,前面的所有目录名拼接成“/目录名1/目录名2/.../”的形式,记为file_path,后面的所有目录拼接成“目录名1_目录名2_...”的形式,记为file_func,将扩展名记为file_type,将文件名记为file_name;
[0027]
f.如果检查完所有的目录名都没有符合条件的,则将最后一个目录名以前的目录名拼接成“/目录名1/目录名2/.../”的形式,记为file_path,检查最后一个目录名是否包含“.”,如果是则进入步骤g,否则将最后一个目录名记为file_name,file_type、file_func均为空;
[0028]
g.将目录名解释为“文件名.扩展名”的格式,将扩展名记录为file_type,将文件名记录为file_name。
[0029]
步骤s5中,检查file_type是在配置的动态文件类型中,如果是则判定该文件为动态文件,否则判定该文件为静态文件;
[0030]
步骤s6中,对于静态文件,指定file_size为响应体大小,再进行如下处理;
[0031]
将文件以file_path中的目录名为节点存储到树状结构中,如果file_path、file_name和file_type都相同,则将两个文件合并,如果将要合并的两个文件为静态文件且file_size不同,则将file_size指定为“*”,否则file_size不变;
[0032]
步骤s6中,对于动态文件,对文件生成函数签名,指定file_size为“*”,将file_func,file_name,file_type,params进行拼接,生成形如“file_name.file_type::file_func(param1,param2,...)”的函数签名,记为signature,如果file_func为空,则其格式为“file_name.file_type(param1,param2,...)”,再进行上述的处理。
[0033]
步骤s6中,对于动态文件,以“&”为分隔符,将url中的请求体分为多个请求参数,
如果请求参数中包含“=”,则“=”前为参数名,“=”后为参数值;如果请求参数中不包含“=”,则将请求参数视为参数名,将请求记录中的参数列表记录下来,与文件名一起作为动态文件的函数签名。
[0034]
步骤s6中,如果同一动态文件有多个不同的函数签名则记录在同一资产下,判断该动态资产具有多态性。
[0035]
步骤s7后还包括如下步骤:使用web资产信息分析访问的网站所使用的组件。
[0036]
步骤s7后还包括如下步骤:通过对比不同网站的web资产,确定不同网站之间的相似性。
[0037]
一种计算机可读存储介质,存储有计算机程序,所述计算机程序由处理器执行时,实现所述的方法。
[0038]
本发明与现有技术相比具有如下有益效果:
[0039]
现有技术对web访问日志的分析,聚焦在用户访问行为、网站运行状态等分析,缺乏对web应用资产的分析,更没有提出从web访问日志中提取web应用资产的方法。本发明提出一种从web访问日志提取web应用资产的方法,该方法分别针对静态资源和动态资源提出了对应的提取方法,利用提取的web资产信息可分析出网站使用的组件,有利于尽早发现web应用可能存在的风险,而且通过比对不同web应用的资产信息,能够计算网站的相似性,具有重要的现实意义。
[0040]
在仅有web访问日志的情况下,提取出web资产信息:包含文件名、文件路径、文件大小,动态文件还有函数签名以及多态性分析;当web访问日志数据量足够大时,可以精准还原出web资产情况;以函数签名的形式描述动态文件,让安全人员在黑盒的情况下,充分了解web应用,能更高效、更有针对性地对web应用进行测试和维护;可以通过web资产信息刻画出web应用的指纹,通过web应用指纹的比对,推测出web应用所使用的组件,并分析其可能存在的漏洞和风险。
附图说明
[0041]
图1为本发明从web访问日志提取web资产的方法的整体流程图。
[0042]
图2为本发明实施例的url解析流程图。
[0043]
图3为本发明实施例的动态文件、静态文件处理流程图。
[0044]
图4为本发明实施例的文件项插入目录树流程图。
具体实施方式
[0045]
以下对本发明的实施方式做详细说明。应该强调的是,下述说明仅仅是示例性的,而不是为了限制本发明的范围及其应用。
[0046]
参阅图1,本发明实施例提供一种从web访问日志提取web资产的方法,通过对web中间件的访问日志进行分析,提取web应用的资产信息,包括文件目录结构、文件类型、动态文件函数签名信息、静态文件大小;并根据web应用的资产信息,对web应用资产情况进行刻画,构建出树状存储结构即资产目录,从而还原出web应用的文件目录结构、文件类型、动态文件函数签名信息、静态文件大小。
[0047]
在一些实施例中,所述方法包括如下步骤:
[0048]
1.日志收集:对web访问日志进行收集。
[0049]
2.日志解析:根据不同格式的web访问日志,可使用正则表达式对web访问日志的每一行数据进行匹配,或以日志中的分隔符进行分割,提取出每一个web请求的url、状态码、响应体大小。
[0050]
3.日志筛选:筛选出状态码为200的访问记录。
[0051]
4.url解析:参照标准url格式,对访问记录中的url进行分析,解析出协议、域名/ip、端口、路径、文件名及请求体。url以“?”为分隔,“?”后为请求体,以url中“?”前的内容作为资产名,将相同资产名的不同访问记录看作是对同一资产的不同访问记录,从资产名中提取出资产对应的协议、域名/ip、端口、路径、文件名。
[0052]
5.静态/动态文件判断:通过web访问记录中,同一资产所有记录的文件大小是否保持一致和文件后缀名判断文件为静态文件还是动态文件。若同一资产所有记录的文件大小都保持一致,且文件名后缀属于静态文件后缀,则将该资产判定为静态文件,其余为动态文件。
[0053]
6.静态/动态文件处理:对于静态文件,文件大小记录为资产文件大小;与标准url解析不同的是,对于动态文件,会根据其参数列表生成函数签名来表示它的动态性及多态性。以“&”为分隔符,将请求体分为多个请求参数,如果请求参数中包含“=”,则“=”前为参数名,“=”后为参数值;如果请求参数中不包含“=”,则将请求参数视为参数名,将一个请求记录中的参数列表记录下来,与文件名一起作为动态文件的函数签名,如同一动态文件有多个不同的函数签名则记录在同一资产下,判断该动态资产具有多态性。
[0054]
7.资产目录生成:根据资产的文件名、文件大小及其路径处理成树状目录结构,即网站对应的web资产,使用web资产信息可分析网站使用的组件,也可通过对比不同网站的web资产,得到网站相似性。
[0055]
在一些实施例中,从web访问日志提取web资产包括静态资产提取和动态资产提取两部分,分别对web日志中的静态文件资产提取和动态文件资产提取提出了对应的方法,并给出了静态文件和动态文件的判断方法。从web访问日志中提取静态文件资产包括日志收集、日志解析、日志筛选、url解析、静态文件判断、静态文件处理、资产目录生成这七个步骤。从web访问日志中提取动态文件资产与提取静态文件资产不同的是动态文件判断和动态文件函数签名这两个步骤,其余五个步骤均相同。
[0056]
下面结合实施例对本发明作进一步地详细说明,但本发明的实施方式不限于此。
[0057]
实施例1:
[0058]
1.日志收集:从nginx/apache等中间件中导出一段时间的访问日志(即access.log),截取日志片段如下。
[0059]
...
[0060]
192.168.5.22
‑‑
[04/dec/2020:10:52:04 0800]"get/images/index/t_02.png http/1.1"404 548"mozilla/5.0(windows nt 6.1;wow64)applewebkit/537.36(khtml,like gecko)chrome/72.0.3626.81safari/537.36se 2.x metasr 1.0"
[0061]
192.168.5.22
‑‑
[04/dec/2020:10:52:06 0800]"get/images/index/t_03.png http/1.1"200 548"mozilla/5.0(windows nt 6.1;wow64)applewebkit/537.36(khtml,like gecko)chrome/72.0.3626.81safari/537.36se 2.x metasr 1.0"
[0062]
192.168.5.22
‑‑
[04/dec/2020:10:52:06 0800]"get/images/index/t_03.png http/1.1"200 548"mozilla/5.0(windows nt 6.1;wow64)applewebkit/537.36(khtml,like gecko)chrome/72.0.3626.81safari/537.36se 2.x metasr 1.0"
[0063]
192.168.5.22
‑‑
[04/dec/2020:10:52:08 0800]"get/images/index/t_04.png http/1.1"200 548"mozilla/5.0(windows nt 6.1;wow64)applewebkit/537.36(khtml,like gecko)chrome/72.0.3626.81safari/537.36se 2.x metasr 1.0"
[0064]
192.168.5.22
‑‑
[04/dec/2020:10:52:08 0800]"get/images/index/t_04.png http/1.1"200 500"mozilla/5.0(windows nt 6.1;wow64)applewebkit/537.36(khtml,like gecko)chrome/72.0.3626.81safari/537.36se 2.x metasr 1.0"
[0065]
192.168.5.22
‑‑
[04/dec/2020:10:52:20 0800]"get/index.php http/1.1"200 120"mozilla/5.0(windows nt 6.1;wow64)applewebkit/537.36(khtml,like gecko)chrome/72.0.3626.81safari/537.36se 2.x metasr 1.0"
[0066]
192.168.5.22
‑‑
[04/dec/2020:10:53:54 0800]"get/index.php?m=user&a=login http/1.1"200 15"mozilla/5.0(windows nt 6.1;wow64)applewebkit/537.36(khtml,like gecko)chrome/72.0.3626.81safari/537.36se 2.x metasr 1.0"
[0067]
192.168.5.22
‑‑
[04/dec/2020:10:55:08 0800]"get/index.php/user?uid=100234http/1.1"200 1548"mozilla/5.0(windows nt 6.1;wow64)applewebkit/537.36(khtml,like gecko)chrome/72.0.3626.81safari/537.36se 2.x metasr 1.0"
[0068]
192.168.5.22
‑‑
[04/dec/2020:11:25:01 0800]"get/admin/index.php?m=user&a=edit http/1.1"200 152"mozilla/5.0(windows nt 6.1;wow64)applewebkit/537.36(khtml,like gecko)chrome/72.0.3626.81safari/537.36se 2.x metasr 1.0"
[0069]
...
[0070]
2.日志解析,对收集到的日志,使用空格作为分隔符,分隔成数组,并从中提取url、状态码、响应体大小。
[0071]
步骤为:
[0072]
a.逐行读取日志
[0073]
b.使用空格分割日志行,结果为一个字段列表
[0074]
c.从上一步获得的字段列表中找出url、状态码、响应体大小,组装成一个日志访问记录对象
[0075]
d.将所有日志行解析出的日志访问记录对象存储到一个数组(records)中,结果如下:
[0076]
records内容:
[0077]
[0078][0079]
3.日志筛选,筛选出日志记录中状态码为200的访问记录,筛选过后日志访问记录对象数组(records)的内容如下
[0080]
records内容:
[0081]
[0082][0083]
4.url解析及静态/动态资源判断
[0084]
对解析出的日志访问记录对象数组的每一项的url进行解析,提取出协议、域名/ip、端口、路径、文件名和请求参数,流程如图2所示,解析方法为:
[0085]
a.判断url中是否包含“?”,如果包含“?”,说明该url包含请求参数,进入步骤b;如果不包含“?”,说明该url不包含请求参数,将url记为path,进入步骤d;
[0086]
b.以url中从左到右出现的第一个“?”为界,将url一分为二,前半部分记为path,后半部分记为query_string;
[0087]
c.判断query_string中是否包含“&”,如果不包含“&”,说明有且仅有一个参数,此时query_string的格式为“参数名=参数值”,其中参数值可能为空;如果包含“&”,说明含有两个以上的参数,使用“&”为分隔,将query_string分割成一个参数列表,格式为“参数名=参数值”,其中参数值可能为空。将query_string按上述规则,提取出一个由参数名构成的列表,并按照字母顺序对其排序,格式为[参数名1,参数名2,参数名3...],将这个列表记为params;
[0088]
d.如果path的内容为“/”,说明为根目录,文件名为“index”;如果path内容不为“/”,使用“/”为分隔,将path分割成一个目录名列表,格式为[目录名1,目录名2,...];
[0089]
e.从左到右对目录名列表中的每一个目录进行检查,如果目录名中包含“.”,则将目录名解释为“文件名.扩展名”的格式,其中扩展名不能含有“.”,文件名可以包含“.”;检查扩展名是否在配置的动态文件类型中,如果是,则以当前目录名为分隔,前面的所有目录名拼接成“/目录名1/目录名2/.../”的形式,记为file_path,后面的所有目录拼接成“目录名1_目录名2_...”的形式,记为file_func,将扩展名记为file_type,将文件名记为file_name;
[0090]
f.如果检查完所有的目录名都没有符合条件的,则将最后一个目录名以前的目录名拼接成“/目录名1/目录名2/.../”的形式,记为file_path,检查最后一个目录名是否包含“.”,如果是则进入步骤g,否则将最后一个目录名记为file_name,file_type、file_func均为空;
[0091]
g.将目录名解释为“文件名.扩展名”的格式,其中扩展名不能含有“.”,文件名可以包含“.”,将扩展名记录为file_type,将文件名记录为file_name;
[0092]
结果:
[0093]
...
[0094]
{'url':'/images/index/t_03.png','status':'200','length':'548','file_path':'/images/index','file_name':'t_03.png','file_type':'png','file_func':”,'params':[”]}
[0095]
{'url':'/images/index/t_03.png','status':'200','length':'548','file_path':'/images/index','file_name':'t_03.png','file_type':'png','file_func':”,'params':[”]}
[0096]
{'url':'/images/index/t_04.png','status':'200','length':'548','file_path':'/images/index','file_name':'t_04.png','file_type':'png','file_func':”,'params':[”]}
[0097]
{'url':'/images/index/t_04.png','status':'200','length':'500','file_path':'/images/index','file_name':'t_04.png','file_type':'png','file_func':”,'params':[”]}
[0098]
{'url':'/index.php','status':'200','length':'120','file_path':”,'file_name':'index.php','file_type':'php','file_func':”,'params':[”]}
[0099]
{'url':'/index.php?m=user&a=login','status':'200','length':'15','file_path':”,'file_name':'index.php','file_type':'php','file_func':”,'params':['a','m']}
[0100]
{'url':'/index.php/user?uid=100234','status':'200','length':'1548','file_path':”,'file_name':'index.php','file_type':'php','file_func':'user','params':['uid']}
[0101]
{'url':'/admin/index.php?m=user&a=edit','status':'200','length':'152','file_path':'/admin','file_name':'index.php','file_type':'php','file_func':”,'params':['a','m']}
[0102]
...
[0103]
将上述结果进行静态、动态文件处理,流程如图3所示,方法为:
[0104]
a.检查file_type是在配置的动态文件类型中,如果是则判定该文件为动态文件,进入步骤b,否则判定该文件为静态文件,进入步骤c;
[0105]
b.与标准url解析不同的是,当文件为动态文件时,会对该文件生成函数签名。指定file_size为“*”,将file_func,file_name,file_type,params进行拼接,生成形如“file_name.file_type::file_func(param1,param2,...)”的函数签名,记为signature,如果file_func为空,则其格式为“file_name.file_type(param1,param2,...)”,进入步骤d;
[0106]
c.文件为静态文件,指定file_size为响应体大小,进入步骤d;
[0107]
d.将文件以file_path中的目录名为节点存储到树状结构中,流程如图4所示,如果file_path、file_name和file_type都相同,则将两个文件合并,如果将要合并的两个文件为静态文件且file_size不同,则将file_size指定为“*”,否则file_size不变,树状结构形如:
[0108]
/
[0109]
‑‑
目录名1
[0110]
‑‑‑‑
目录名2
[0111]
‑‑‑‑‑‑
文件1
[0112]
‑‑‑‑
文件2
[0113]
‑‑
目录名3
[0114]
‑‑‑‑
文件3
[0115]
‑‑‑‑
文件4
[0116]
‑‑
目录名4
[0117]
‑‑‑‑
目录名5
[0118]
‑‑‑‑‑‑
目录名6
[0119]
‑‑‑‑‑‑‑‑
文件5
[0120]
...
[0121]
处理结果为:
[0122]
[0123][0124]
与现有技术对web访问日志的分析聚焦在用户访问行为、网站运行状态等分析不同,本发明通过从web访问日志提取web应用资产,利用提取的web资产信息可分析出网站使用的组件,有利于尽早发现web应用可能存在的风险,而且通过比对不同web应用的资产信息,能够计算网站的相似性,具有重要的现实意义。在仅有web访问日志的情况下,提取出
web资产信息:包含文件名、文件路径、文件大小,动态文件还有函数签名以及多态性分析;当web访问日志数据量足够大时,可以精准还原出web资产情况;以函数签名的形式描述动态文件,让安全人员在黑盒的情况下,充分了解web应用,能更高效、更有针对性地对web应用进行测试和维护;可以通过web资产信息刻画出web应用的指纹,通过web应用指纹的比对,推测出web应用所使用的组件,并分析其可能存在的漏洞和风险。
[0125]
本发明的背景部分可以包含关于本发明的问题或环境的背景信息,而不一定是描述现有技术。因此,在背景技术部分中包含的内容并不是申请人对现有技术的承认。
[0126]
以上内容是结合具体/优选的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,其还可以对这些已描述的实施方式做出若干替代或变型,而这些替代或变型方式都应当视为属于本发明的保护范围。在本说明书的描述中,参考术语“一种实施例”、“一些实施例”、“优选实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。尽管已经详细描述了本发明的实施例及其优点,但应当理解,在不脱离专利申请的保护范围的情况下,可以在本文中进行各种改变、替换和变更。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
