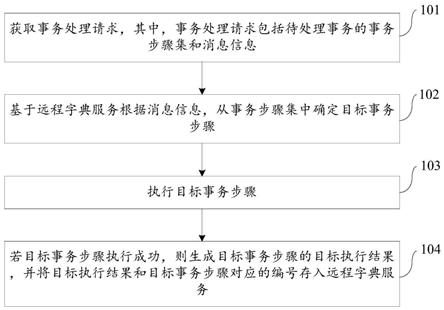
技术特征:
1.一种机器学习模型的训练方法,其特征在于,包括:获取多个第一训练样本;对所述第一训练样本进行第一随机增强处理,得到第二训练样本;在基于预设增强总数判断到所述第二训练样本满足预设增强条件后,对所述第二训练样本进行第二随机增强处理,得到第三训练样本,所述预设增强总数为批处理数量的约数;利用训练样本对机器学习模型进行训练,得到训练完的机器学习模型,所述训练样本包括所述第二训练样本或所述第三训练样本,所述批处理数量为每次输入至所述机器学习模型的训练样本的数量。2.根据权利要求1所述的机器学习模型的训练方法,其特征在于,所述对所述第一训练样本进行第一随机增强处理,得到第二训练样本的步骤之前,包括:对增强统计表进行初始化,所述增强统计表包括不同类别的所述第一训练样本以及与所述第一训练样本对应的增强次数;从所述增强统计表中选取增强次数为第一预设值的第一训练样本,以形成本轮增强样本集;其中,在所述增强统计表中的增强次数均为第二预设值时,执行所述对增强统计表进行初始化的步骤。3.根据权利要求2所述的机器学习模型的训练方法,其特征在于,所述对所述第二训练样本进行第二随机增强处理,得到第三训练样本的步骤之前,包括:将本轮样本更新数量初始化为第三预设值;将所述本轮样本更新数量与所述预设增强总数进行比较,得到比较结果;基于所述比较结果,判断所述第二训练样本是否满足所述预设增强条件。4.根据权利要求3所述的机器学习模型的训练方法,其特征在于,所述第二随机增强处理为随机遮挡处理,所述将所述本轮样本更新数量与所述预设增强总数进行比较的步骤,包括:判断所述本轮样本更新数量是否小于所述预设增强总数;若所述本轮样本更新数量小于所述预设增强总数,则判断当前所述第二训练样本是否满足预设遮挡条件;若当前所述第二训练样本满足所述预设遮挡条件,则确定所述第二训练样本满足所述预设增强条件,对所述第二训练样本进行随机遮挡处理,得到所述第三训练样本;将所述本轮样本更新数量与预设步长相加,并返回所述判断所述本轮样本更新数量是否小于所述预设增强总数的步骤,直至所述本轮样本更新数量大于/等于所述预设增强总数;在所述本轮样本更新数量大于/等于所述预设增强总数后,则执行所述利用训练样本对机器学习模型进行训练的步骤。5.根据权利要求4所述的机器学习模型的训练方法,其特征在于,所述判断当前所述第二训练样本是否满足预设遮挡条件的步骤,包括:随机生成一个位于预设数值范围内的遮挡因子;判断所述遮挡因子是否大于预设遮挡阈值;若是,则确定当前所述第二训练样本满足所述预设遮挡条件。
6.根据权利要求4所述的机器学习模型的训练方法,其特征在于,所述第二训练样本包括多个第一待处理数据,所述对所述第二训练样本进行随机遮挡处理,得到所述第三训练样本的步骤,包括:从所有所述第一待处理数据中随机选择至少一个所述第一待处理数据,得到第二待处理数据;对所述第二待处理数据进行随机化处理,得到第三待处理数据;利用所述第三待处理数据替换所述第二训练样本中相应的第一待处理数据,得到所述第三训练样本。7.根据权利要求2所述的机器学习模型的训练方法,其特征在于,所述方法包括:基于所述训练样本对应的标签值与所述机器学习模型输出的预测值,判断当前所述机器学习模型是否满足预设训练结束条件;若否,则对所述本轮增强样本集中第一训练样本对应的增强次数进行更新,并返回所述从所述增强统计表中选取增强次数为第一预设值的第一训练样本的步骤,直至所述机器学习模型满足所述预设训练结束条件。8.根据权利要求7所述的机器学习模型的训练方法,其特征在于,所述基于所述训练样本对应的标签值与所述机器学习模型输出的预测值,判断当前所述机器学习模型是否满足预设训练结束条件的步骤,包括:计算所述训练样本对应的标签值与所述机器学习模型输出的预测值之间的损失值;判断所述损失值是否小于预设损失阈值或当前训练次数是否大于预设迭代次数阈值;若是,则确定当前所述机器学习模型满足所述预设训练结束条件。9.一种电子装置,其特征在于,包括互相连接的存储器和处理器,其中,所述存储器用于存储计算机程序,所述计算机程序在被所述处理器执行时,用于实现权利要求1-8中任一项所述的机器学习模型的训练方法。10.一种计算机可读存储介质,用于存储计算机程序,其特征在于,所述计算机程序在被处理器执行时,用于实现权利要求1-8中任一项所述的机器学习模型的训练方法。
技术总结
本申请公开了一种机器学习模型的训练方法、装置和可读存储介质,该方法包括:获取多个第一训练样本;对第一训练样本进行第一随机增强处理,得到第二训练样本;在基于预设增强总数判断到第二训练样本满足预设增强条件后,对第二训练样本进行第二随机增强处理,得到第三训练样本,预设增强总数为批处理数量的约数;利用训练样本对机器学习模型进行训练,得到训练完的机器学习模型,训练样本包括第二训练样本或第三训练样本,批处理数量为每次输入至机器学习模型的训练样本的数量。通过上述方式,本申请能够加速模型的收敛速度。本申请能够加速模型的收敛速度。本申请能够加速模型的收敛速度。
技术研发人员:张兴明 周旭亚 陈波扬 黄鹏
受保护的技术使用者:浙江大华技术股份有限公司
技术研发日:2021.11.15
技术公布日:2022/3/21
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。