一种基于ofdm的卫星物联网大规模接入设计方法
技术领域
1.本发明属于卫星通信技术领域,涉及一种基于ofdm的卫星物联网大规模接入设计方法。
背景技术:
2.通信系统中常用的用户接入方法为基于授权的随机接入,用户首先随机选取一个正交前导或导频序列进行接入,选取同一个导频的用户之间会发生冲突,未发生冲突的用户会得到基站的授权以及分配的物理资源,进行接下来的数据传输。对于卫星物联网通信系统,卫星服务的用户数大大增加,由于正交导频资源有限,基于授权的随机接入方法在面对大规模接入时会产生严重的用户冲突,导致极大的接入时延。
3.针对此问题,免授权随机接入技术被视为极具潜力的解决方案。该技术预先对用户分配固定的非正交导频,活跃用户无需授权即可发送导频和数据信号,但是接收端需要根据接收的导频检测出活跃用户并估计其信道,再进行数据解码。由于系统中大部分用户处于非活跃状态,用户的信道向量或矩阵具有稀疏结构,因此活跃用户检测可以转化为压缩感知问题。如文献“massive connectivity with massive mimo—part i:device activity detection and channel estimation”使用向量近似消息传递算法进行联合的活跃用户检测和信道估计;文献“generalized channel estimation and user detection for massive connectivity with mixed-adc massive mimo”在使用实际模数转换器的系统中利用turbo压缩感知算法进行联合的活跃用户检测和信道估计。
4.此外,由于卫星的高速运动,卫星信道具有严重的多普勒频移,在时域体现为不同ofdm符号上的时变特性。在这种情况下,信道估计问题具有更高的挑战性。
5.由于多普勒拓展通常远远小于系统带宽,卫星信道在多普勒域呈现稀疏性。充分利用信道的稀疏特性可以获得更好的信道估计性能。如文献“compressive estimation of doubly selective channels on multicarrier systems:leakage effects and sparsity-enhancing processing”在ofdm系统中使用压缩感知技术利用时延域和多普勒域的联合稀疏性进行信道估计;文献“channel estimation for orthogonal time frequency space(otfs)massive mimo”利用时延-多普勒-角度域的三维稀疏性使用正交匹配追踪算法进行信道估计。
技术实现要素:
6.针对卫星物联网的大规模接入问题,本发明提出了一种收发端联合设计的免授权随机接入方法,在发送端使用重复的ofdm符号并在接收端使用基于方差状态传播的消息传递算法进行联合活跃用户检测和信道估计,一方面通过重复发送ofdm符号达到提升接收端频域分辨率的效果,另一方面在接收端充分利用信道在时延-多普勒-用户域的稀疏性建立先验概率模型提升活跃用户检测和信道估计性能,并通过em算法更型参数减少模型与实际信道的误差。
7.在发送端,本发明提出重复ofdm符号调制方式,每个重复符号由n个相同ofdm符号拼接构成。接收端在去除cp后,对每个重复符号的时域采样时间为n个ofdm符号长度,其分域分辨率是常规ofdm系统的1/n,因此可以更精确地分辨多普勒频移。
8.为了降低信道估计难度,本发明将信道在时延-多普勒域离散化为2维网格,信道可由为网格参数和网格上的信道增益近似表征。相较于直接估计时变信道,网格化的信道模型只需估计少量的信道参数,大大减少了待估计参数。同时本发明还使用期望最大化(em)框架更新网格参数,减少信道模型与实际信道的误差。
9.在接收端,本发明充分利用信道在时延-多普勒-用户域的稀疏性,建立信道方差状态的马尔可夫场(mrf)先验概率模型,设计基于方差状态传播的消息传递算法进行联合活跃用户检测和信道估计。
10.本发明采用的技术方案包括以下步骤:
11.s1、用户端使用重复ofdm符号技术生成上行信号;用户k根据频域导频序列进行基带调制得到ofdm符号,将该ofdm符号重复n次并添加cp,得到第u个重复符号d
k,u
(t):
[0012][0013]
其中:δf是子载波间隔,m为子载波数目,t=1/δf为ofdm符号长度,t
cp
为导频长度,为一个重复符号和cp的长度,ξ(t)为矩形脉冲:
[0014][0015]
将用户导频部分的所有重复符号拼接到一起,得到上行信号sk(t):
[0016][0017]
其中:u是一个传输帧中的重复符号数;
[0018]
s2、用户的信号传送到发射天线后经过实际信道,卫星接收到包含所有用户信号的叠加以及高斯白噪声的信号r(t);去除r(t)中的cp后,计算得到频域接收信号第u个重复符号的第n个子载波上的接收信号y
n,u
的计算公式为
[0019][0020]
s3、信道建模;对第k个用户,预先设定其网格时延参数τk和多普勒参数vk:τ
l,k
∈[0,τ
max
)v
j,k
∈[-v
max
,v
max
);其中,l
×
j是时延-多普勒域网格的维度,τ
max
和v
max
分别表示网格所包含的最大时延和最大多普勒频移;信道可以近似表征为:
[0021][0022]
其中:h
′
k,l,j
为用户k的实际物理信道在时延τ=τ
k,l
和多普勒频移ν=ν
k,j
的等效信道增益;定义αk为用户活跃状态:
[0023][0024]
每个用户的活跃状态相互独立且概率为p(αk=1)=ρ;将用户的活跃状态和信道参数拼接到一起得到h:
[0025]
h=[h
1,1
,h
1,2
,
…
,h
1,lj
,h
2,1
,h
2,2
,
…
,h
2,lj
,
…
,h
k,1
,h
k,2
,
…
,h
k,lj
]
t
,
[0026]
其中:表示向下取整,k是系统中总的用户数;
[0027]
s4、接收端进行频域过采样,得到观测信号y;根据网格信道模型,卫星接收信号y可表示为y=ah w,其中w是方差为σ2的高斯白噪声,为测量矩阵,计算方法为:,
[0028][0029][0030][0031][0032][0033]
s5、建立概率模型;h
k,i
分配0均值方差为υ
k,i
的高斯分布h的条件概率为
[0034][0035]
其中υ=[υ
1,1
,υ
1,2
,
…
,υ
k,lj
];υ
k,i
建模为关于隐藏状态s
k,i
的条件分布:
[0036]
p(υ
k,i
|s
k,i
)=gamma(υ
k,i
;γ1,γ2)δ(s
k,i-1) δ(υ
k,i
)δ(s
k,i
1),
[0037]
其中s
k,i
∈{-1,1}表示υ
k,i
的状态,δ(
·
)为狄拉克delta函数,gamma(υ
k,i
;a,b)表示gamma分布:
[0038]
[0039]
为gamma函数,γ
k,1
和γ
k,2
是gamma分布的参数;
[0040]
隐藏状态s
k,i
和用户活跃状态αk的联合概率建模为马尔科夫随机场(mrf)概率模型:
[0041][0042]
其中:sk=[s
k,1
,s
k,2
,
…
,s
k,lj
],
∝
表示正比关系,[lj]\i表示集合{1,
…
,lj}不包含元素i的子集,β是mrf的参数,表示s
k,i
邻居节点的下边集合,即{i-1,i 1,i-j,i j},αk和s
k,i
之间的约束为
[0043][0044]
其中m
ψ
=2ρ
s-1,ρs是的稀疏度,即p(s
k,i
=1)=ρs;
[0045]
联合概率p(y,h,υ,s,α)可以表示为:
[0046][0047]
其中s=[s1,s2,
…
,sk],α=[α1,α2,
…
,αk];
[0048]
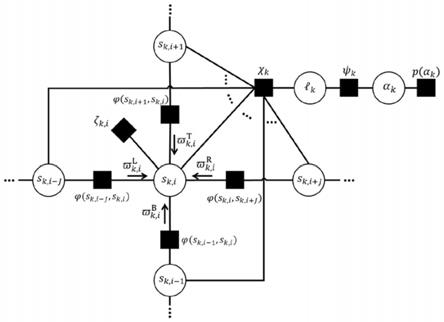
s6、对联合概率p(y,h,υ,s,α)进行因子图表示,h、υ、s和α的每一个元素都是因子图中的一个变量节点,每一个概率因子都是一个因子节点;根据因子图设计迭代近似消息传递算法,因子图中包含两个模块,左半部分为线性模块,右半部分为mrf模块;因子节点{ζ
k,i
},{η
k,i
},{χk}和{ψk}分别定义为
[0049]
ζ
k,i
:p(υ
k,i
|s
k,i
),
[0050][0051][0052][0053]
ψk:ψ(lk,αk);
[0054]
s7、初始化因子图上的各个消息,进入消息更新:对任意的k、i,初始化s7、初始化因子图上的各个消息,进入消息更新:对任意的k、i,初始化
[0055]
s8、实施线性模块消息传递;根据节点υ
k,i
的均值计算关于p(h|y,υ)的均值m和方差φ:
[0056]
m=dah(σ-2
i adah)-1
y,
[0057]
φ=d-dah(σ-2
i adah)-1
ad,
[0058]
其中:d是一个对角矩阵,第(k-1)lj i个对角元为
[0059]
s9、对任意的k、i,使用证据下界(elbo)(m.zhang,x.yuan,and z.-q.he,“variance state propagation for structured sparse bayesian learning,”ieee trans.signal process.,vol.68,pp.2386
–
2400,2020.)做近似计算节点η
k,i
向υ
k,i
传递的消息
[0060][0061]
其中:m
(k-1)lj i
为m的第(k-1)lj i个元素,φ
(k-1)lj i
为φ的第(k-1)lj i个对角元素;
[0062]
s10、对任意的k、i,近似计算节点ζ
k,i
向节点s
k,i
传递的消息
[0063][0064]
其中γ
k,1
/γ
k,2
用κk近似计算,κk为中值最大的个的元素的均值,;若κk<κ
thres
,则κk=κ
thres
,κ
thres
的确定方法如下:将按从大到小顺序排列,得到则将消息作为节点υ
k,i
向节点η
k,i
的消息,即
[0065]
s11、重复s8-s10直至线性模块收敛或达到最大重复次数,得到线性模块向mrf模块传递的消息
[0066]
s12、实施mrf模块消息传递;对任意的k、i,计算节点s
k,i
邻近同类节点传递的消息,其左侧同类节点传递的消息为:
[0067][0068]
其中:
[0069][0070]
分别表示左,右,上,下,为向传递的消息;右侧节点上侧节点和下侧节点传递的消息具有类似的计算公式;
[0071]
s13、对任意的k,近似计算节点χk向节点lk传递的消息
[0072][0073]
其中:
[0074]
[0075][0076]
s14、对任意的k,计算节点ψk向节点αk传递的消息
[0077][0078]
其中:
[0079][0080][0081]
s15、对任意的k,节点ψk向节点lk传递的消息是一个常量:
[0082][0083]
通过高斯近似,计算节点χk向节点s
k,i
传递的消息
[0084][0085]
其中:
[0086][0087][0088][0089]
s16、对任意的k、i,计算节点s
k,i
向节点ζ
k,i
传递的消息
[0090][0091]
其中:
[0092]
s17、对任意的k、i,计算节点υ
k,i
向节点η
k,i
传递的消息
[0093][0094]
这里γ
k,1
/γ
k,2
使用s10中的近似值;
[0095]
s18、重复s12-s17直至mrf模块收敛或达到最大重复次数,得到mrf模块向线性模
块传递的消息
[0096]
s19、重复s8-s18直至两个模块收敛或达到最大重复次数,对任意的k,得到用户活跃度检测结果以及信道估计结果
[0097][0098][0099]
s20、使用期望最大化(em)算法更新网格参数;以h为隐藏变量,最大化关于h的似然函数的后验均值等价于最小化函数
[0100][0101]
其中:ω={τ0,...,τ
k-1
,ν0,...,ν
k-1
},ω(i)表示ω经过i次em迭代更新后的结果,和ω(i)(ω(i))分别是h根据y和ω(i)计算得到的后验均值和协方差矩阵;通过梯度下降法更新ω中的网格参数,以τk为例,第i次em迭代第j次更新公式为:
[0102][0103]
其中:∈
(i,j)
为更新步长,的第l个元素为
[0104][0105][0106][0107]
ω={τ0,...,τ
k-1
,ν0,...,ν
k-1
}中的其他参数具有类似的更新方式;
[0108]
s21、重复s8-s20直至em收敛或达到最大重复次数,得到收敛后的网格参数和信道估计结果;
[0109]
s22、对任意的k,输出用户活跃度检测结果以及信道估计结果
[0110][0111][0112]
本发明的有益效果分别体现在发送端与接收端。在发送端,本发明通过重复的
ofdm符号从而实现接收端的频域过采样,对多普勒频移达到更好的区分效果;在接收端,mrf先验概率模型充分利用了信道的三维稀疏结构,对活跃用户检测和信道估计性能由较大的提升;同时使用em算法减少模型与实际信道的不匹配,进一步提升了性能。通过仿真表明:重复发送ofdm符号可以带来一定的性能增益,提出算法的活跃用户检测和信道估计性能显著优于对比方案。
附图说明
[0113]
图1是概率模型的因子图;
[0114]
图2是mrf模块的因子图;
[0115]
图3是发送端导频序列的结构示意图;
[0116]
图4是整个算法的流程图;
[0117]
图5是发送端重复符号中不同ofdm符号重复次数下进行信道估计的nmse仿真曲线;
[0118]
图6为使用不同算法进行信道估计的nmse仿真曲线。
[0119]
图7为使用不同算法进行活跃用户检测的检测错误概率仿真曲线。
具体实施方式
[0120]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
[0121]
图4是算法的流程图,包括发送端的重复符号,多径信道的引入,以及接收端的消息传递算法。
[0122]
下面给出本发明基于上述算法的一个具体实施方法,该具体方法的参数设置如下:
[0123]
在发送端,重复符号中重复ofdm符号数为n=2,一个传输帧中u=6个重复符号,子载波数为m=16,子载波间隔为15khz。系统服务的用户总数为k=100,每个用户的信道网格大小为4
×
10。实际物理信道的最大多普勒频移为15khz,最大时延为1.675
×
10-5
(秒)。
[0124]
根据以上参数设置,该仿真的具体步骤如下:
[0125]
s1、用户端使用重复ofdm符号技术生成上行信号;用户k根据频域导频序列进行基带调制得到ofdm符号,将该ofdm符号重复n=2次并添加cp,得到第u个重复符号d
k,u
(t):
[0126][0127]
其中:δf=15khz是子载波间隔,m=16为子载波数目,t=1/δf为ofdm符号长度,t
cp
=1.675
×
10-5
(秒)为导频长度,为一个重复符号的长度,ξ(t)为矩形脉冲:
[0128][0129]
将用户导频部分的所有重复符号拼接到一起,得到上行信号sk(t):
[0130][0131]
其中:u是一个传输帧中的重复符号数;
[0132]
s2、用户的信号传送到发射天线后经过实际信道,卫星接收到包含所有用户信号的叠加以及高斯白噪声的信号r(t);去除r(t)中的cp后,计算得到频域接收信号第u个重复符号的第n个子载波上的接收信号y
n,u
的计算公式为
[0133][0134]
s3、信道建模;对第k个用户,预先设定其网格时延参数τk和多普勒参数vk:τ
l,k
∈[0,τ
max
),ν
j,k
∈[-ν
max
,ν
max
);其中,l
×
j是时延-多普勒域网格的维度,l=4,j=10,τ
max
=1.675
×
10-5
(秒)和ν
max
=15000khz分别表示网格所包含的最大时延和最大多普勒频移;信道可以近似表征为:
[0135][0136]
其中:h
′
k,l,j
为用户k的实际物理信道在时延τ=τ
k,l
和多普勒频移ν=ν
k,j
的等效信道增益;定义αk为用户活跃状态:
[0137][0138]
每个用户的活跃状态相互独立且概率为p(αk=1)=ρ=0.1;将用户的活跃状态和信道参数拼接到一起得到h:
[0139]
h=[h
1,1
,h
1,2
,
…
,h
1,lj
,h
2,1
,h
2,2
,
…
,h
2,lj
,
…
,h
k,1
,h
k,2
,
…
,h
k,lj
]
t
,
[0140]
其中:表示向下取整,k=100是系统中总的用户数;
[0141]
s4、接收端进行频域过采样,得到观测信号y;根据网格信道模型,卫星接收信号y可表示为y=ah w,其中w是方差为σ2的高斯白噪声,为测量矩阵,计算方法为:,
[0142][0143][0144][0145]
[0146][0147]
s5、建立概率模型;h
k,i
分配0均值方差为υ
k,i
的高斯分布h的条件概率为
[0148][0149]
其中υ=[υ
1,1
,υ
1,2
,
…
,υ
k,lj
];υ
k,i
建模为关于隐藏状态s
k,i
的条件分布:
[0150]
p(υ
k,i
|s
k,i
)=gamma(υ
k,i
;γ1,γ2)δ(s
k,i-1) δ(υ
k,i
)δ(s
k,i
1),
[0151]
其中s
k,i
∈{-1,1}表示υ
k,i
的状态,δ(
·
)为狄拉克delta函数,gamma(υ
k,i
;a,b)表示gamma分布:
[0152][0153]
为gamma函数,γ
k,i
和γ
k,2
是gamma分布的参数;
[0154]
隐藏状态s
k,i
和用户活跃状态αk的联合概率建模为马尔科夫随机场(mrf)概率模型:
[0155][0156]
其中:sk=[s
k,1
,s
k,2
,
…
,s
k,lj
],
∝
表示正比关系,[lj]\i表示集合{1,
…
,lj}不包含元素i的子集,β=-1.3540是mrf的参数,表示s
k,i
邻居节点的下边集合,即{i-1,i 1,i-j,i j},αk和s
k,i
之间的约束为
[0157][0158]
其中m
ψ
=2ρ
s-1,ρs=0.05是的稀疏度,即p(s
k,i
=1)=ρs;
[0159]
联合概率p(y,h,υ,s,α)可以表示为:
[0160][0161]
其中s=[s1,s2,
…
,sk],α=[α1,α2,
…
,αk];
[0162]
s6、对联合概率p(y,h,υ,s,α)进行因子图表示,h、υ、s和α的每一个元素都是因子图中的一个变量节点,每一个概率因子都是一个因子节点;根据因子图设计迭代近似消息传递算法,因子图中包含两个模块,左半部分为线性模块,右半部分为mrf模块;因子节点
{ζ
k,i
},{η
k,i
},{χk}和{ψk}分别定义为
[0163]
ζ
k,i
:p(υ
k,i
|s
k,i
),
[0164][0165][0166][0167]
ψk:ψ(lk,αk);
[0168]
s7、初始化因子图上的各个消息,进入消息更新:对任意的k、i,初始化s7、初始化因子图上的各个消息,进入消息更新:对任意的k、i,初始化
[0169]
s8、实施线性模块消息传递;根据节点υ
k,i
的均值计算关于p(h|y,υ)的均值m和方差φ:
[0170]
m=dah(σ-2
i adah)-1
y,
[0171]
φ=d-dah(σ-2
i adah)-1
ad,
[0172]
其中:d是一个对角矩阵,第(k-1)lj i个对角元为
[0173]
s9、对任意的k、i,使用证据下界(elbo)(m.zhang,x.yuan,and z.-q.he,“variance state propagation for structured sparse bayesian learning,”ieee trans.signal process.,vol.68,pp.2386
–
2400,2020.)做近似计算节点η
k,i
向υ
k,i
传递的消息
[0174][0175]
其中:m
(k-1)lj i
为m的第(k-1)lj i个元素,φ
(k-1)lj i
为φ的第(k-1)lj i个对角元素;
[0176]
s10、对任意的k、i,近似计算节点ζ
k,i
向节点s
k,i
传递的消息
[0177][0178]
其中γ
k,1
/γ
k,2
用κk近似计算,κk为中值最大的个的元素的均值,;若κk<κ
thres
,则κk=κ
thres
,κ
thres
的确定方法如下:将按从大到小顺序排列,得到则将消息作为节点υ
k,i
向节点η
k,i
的消息,即
[0179]
s11、重复s8-s10直至线性模块收敛或达到最大重复次数200,得到线性模块向mrf模块传递的消息
[0180]
s12、实施mrf模块消息传递;对任意的k、i,计算节点s
k,i
邻近同类节点传递的消息,其左侧同类节点传递的消息为:
[0181][0182]
其中:
[0183][0184]
分别表示左,右,上,下,为向传递的消息;右侧节点上侧节点和下侧节点传递的消息具有类似的计算公式;
[0185]
s13、对任意的k,近似计算节点χk向节点lk传递的消息
[0186][0187]
其中:
[0188][0189][0190]
s14、对任意的k,计算节点ψk向节点αk传递的消息
[0191][0192]
其中:
[0193][0194][0195]
s15、对任意的k,节点ψk向节点lk传递的消息是一个常量:
[0196][0197]
通过高斯近似,计算节点χk向节点s
k,i
传递的消息
[0198][0199]
其中:
[0200][0201]
[0202][0203]
s16、对任意的k、i,计算节点s
k,i
向节点ζ
k,i
传递的消息
[0204][0205]
其中:
[0206]
s17、对任意的k、i,计算节点υ
k,i
向节点η
k,i
传递的消息
[0207][0208]
这里γ
k,1
/γ
k,2
使用s10中的近似值;
[0209]
s18、重复s12-s17直至mrf模块收敛或达到最大重复次数100,得到mrf模块向线性模块传递的消息
[0210]
s19、重复s8-s18直至两个模块收敛或达到最大重复次数6,对任意的k,得到用户活跃度检测结果以及信道估计结果
[0211][0212][0213]
s20、使用期望最大化(em)算法更新网格参数;以h为隐藏变量,最大化关于h的似然函数的后验均值等价于最小化函数
[0214][0215]
其中:ω={τ0,...,τ
k-1
,ν0,...,ν
k-1
},ω(i)表示ω经过i次em迭代更新后的结果,和ω(i)(ω(i))分别是h根据y和ω(i)计算得到的后验均值和协方差矩阵;通过梯度下降法更新ω中的网格参数,以τk为例,第i次em迭代第j次更新公式为:
[0216][0217]
其中:∈
(i,j)
为更新步长,的第l个元素为
[0218]
[0219][0220][0221]
ω={τ0,...,τ
k-1
,ν0,...,ν
k-1
}中的其他参数具有类似的更新方式;
[0222]
s21、重复s8-s20直至em收敛或达到最大重复次数10,得到收敛后的网格参数和信道估计结果;
[0223]
s22、对任意的k,输出用户活跃度检测结果以及信道估计结果
[0224][0225][0226]
图5是重复符号中不同ofdm重复次数对于信道估计性能的影响曲线,横坐标表示信噪比(snr),纵坐标表示信道估计的归一化均方误差(nmse)。可见在图示信噪比范围内,重复ofdm符号能够为信道估计带来一定的增益,且随着信噪比的增加,重复符号带来的增益逐渐增加,在snr=20db时有超过1.5db的增益。
[0227]
图6为使用不同算法进行信道估计的nmse仿真曲线。命名“omp”对应着“j.a.tropp and a.c.gilbert,“signal recovery from random measurements via orthogonal matching pursuit,”ieee trans.inf.theory,vol.53,pp.4655
–
4666,dec.2007.”中算法,命名“sbl”对应“m.e.tipping,“sparse bayesian learning and the relevance vector machine,”journal of machine learning research,vol.1,pp.211
–
244,sept.2001.”中算法,命名“tcs”对应“j.ma,x.yuan,and l.ping,“turbo compressed sensing with partial dft sensing matrix,”ieee signal process.lett.,vol.22,pp.158
–
161,feb.2015.”中算法,命名“em-mvsp”对应本发明提出来的算法。可以看到,本发明提出的算法具有明显的增益,在图示snr范围内nmse性能优于其他对比算法,在snr=20db时有超过6db的增益。
[0228]
图7为使用不同算法进行活跃用户检测的检测错误概率仿真曲线。本发明提出的算法在活跃用户检测上有显著的优势,在snr=20db时检测错误概率可以降至10-3
,较对比算法有数量级上的优势。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。