1.本发明涉及深度伪造及检测技术领域,特别涉及一种基于插件式部署的深度伪造及检测模型应用系统及方法。
背景技术:
2.深度伪造技术是基于人工智能伪造音视频媒体的技术,尤其是基于深度学习的deepfake类造假技术(如换脸视频、伪造声音、人脸合成、视频生成等);深度伪造检测技术是对网络上的音视频等媒体进行检测,判断其是否为deepfake伪造的音视频媒体的技术。深度伪造及检测技术均以深度学习等人工智能技术作为基础,目前各个研究团队进行深伪相关技术研究的时候,所使用的ai框架不同(tensorflow、caffe、pytorch、mxnet等)、版本不同、技术栈不同(c 、python、matlab等),从而造成所研究出来的深伪检测模型在工程化落地进行模型推演预测时遇到极大的困难。并且,由于深度伪造和检测技术是不断的在发展的,所以伪造和检测模型会持续的提供新的版本或新的算法,如何快速、无缝的将新的算法发布到算法工程化平台上,也是部署方式所需要重点解决的问题。
3.目前来看主流的部署方法有以下三种方案,他们各有优缺点。
4.1、python服务接口:在python服务器上部署模型文件,给出一个http服务,后台通过这个服务就可以调用模型进行输入输出了。优点:算法与后端的工作界限明显,不需要特别多的沟通;在使用模型前还需要进行数据预处理,不需要额外再进行代码迁移。缺点:需要服务器安装python环境,维护的成本增加,服务器之间接口的通信问题,获取模型输出所需时间可能更长。
5.2、java直接加载模型:目前工业界比较成熟的部署方案就是使用tensorflow的java包,然后加载训练的模型文件。需要事先将模型文件保存成pb格式,然后在java的环境中添加依赖,最后再加载模型。优点:不需要额外的接口,调用方便;不需要额外安装python环境。缺点:需要将数据预处理这部分代码迁移成java,并添加到后端项目代码中。另外google对这种方法重视不高,没有详细的文档,也很少更新维护代码。模型预测速度和调python接口差不多。
6.3、docker tf-serving部署模型:这个是google比较推荐的部署方法,部署文档比较详细。也是广泛使用的方法。这种方法直接将模型部署在docker容器中,然后提供两种接口,分别是grpc接口和http接口,前者据说是在读取批量数据上更有优势,例如图片数据;服务启动后只要可以连接,任何语言都可以调用。优点:部署方便,不受服务器限制;可以同时部署多个模型,方便模型的管理和版本控制;模型推理的速度快,经过测试比前两种快2倍。缺点:同样需要编写数据预处理代码,数据输入格式需要按文档的要求。
7.目前通用的部署方案中,首先所有方案对输入数据进行预处理都需要在部署平台上由工程师来完成,每新增一个模型都需要部署平台进行代码开发和程序的整体上线,不利于模型的持续增加;其次上述部署方案对深度学习ai框架是有要求的,比如tfserving方案只适用于tensorflow框架的模型,对pytorch的模型则束手无策;再次深度伪造及检测模
式有其独特的特性,并没有一种通用的方案可以完美的适配深度伪造模型的上线部署;最后,一些高度稳定的深度学习部署架构相对而言体量比较重,学习成本也比较高,且发挥不了专业人员的优势。
技术实现要素:
8.本发明的首要目的在于提供一种基于插件式部署的深度伪造及检测模型应用系统,解决了不同ai框架的封装问题,且可不停机的实现新模型的横向扩展问题。
9.为实现以上目的,本发明采用的技术方案为:一种基于插件式部署的深度伪造及检测模型应用系统,包括应用层:使用户可以通过客户端与部署平台进行交互;web服务层:用于封装部署平台的常用功能界面;应用服务层:用于对各模型推理服务进行服务部署、任务调度、gpu调度、结果保存以及程序监控操作;模型接口层:是所有插件化的、封装好的模型推理服务所提供的接口集合;模型部署层:用于部署封装好的模型推理服务和执行推理任务;数据存储层:用于存储各种临时或永久数据。
10.本发明的另一个目的在于提供一种基于插件式部署的深度伪造及检测模型应用方法,解决了不同ai框架的封装问题,且可不停机的实现新模型的横向扩展问题。
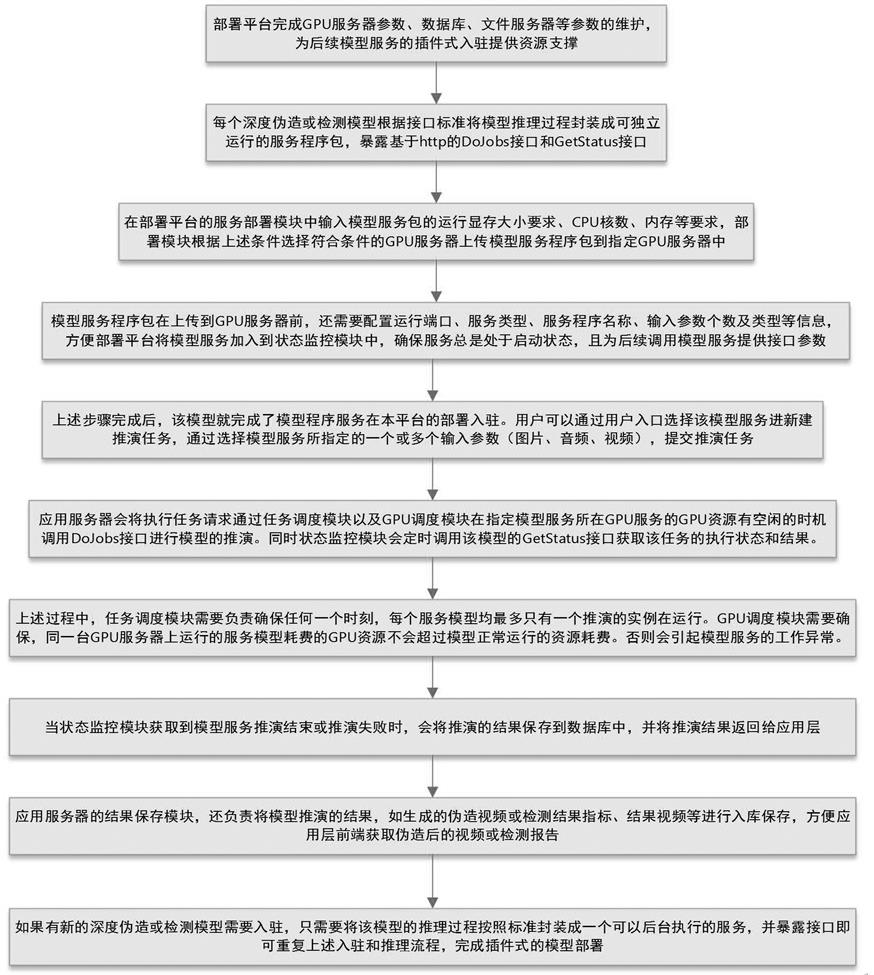
11.为实现以上目的,本发明采用的技术方案为:一种基于插件式部署的深度伪造及检测模型应用方法,包括如下步骤:s100、部署平台完成gpu服务器参数、数据库、文件服务器参数的维护;s200、每个深度伪造或检测模型根据接口标准将模型推理过程封装成可独立运行的服务程序包;s300、在部署平台的服务部署模块中输入模型服务包的运行显存大小要求、cpu核数、内存要求,服务部署模块根据上述条件选择符合条件的gpu服务器上传模型服务程序包到指定的gpu服务器中;s400、模型服务程序包上传到gpu服务器前,需要配置运行端口、服务类型、服务程序名称、输入参数个数及类型信息;s500、模型服务程序完成平台的部署入驻后,用户通过用户入口选择该模型服务新建推演任务。
12.与现有技术相比,本发明存在以下技术效果:通过制定深度伪造模型推演过程输入输出接口标准,要求模型生成方通过自己的技术栈和ai框架完成对模型推演过程的封装形成一个独立的推演服务程序,这样每一个推演服务程序就是一个独立的插件服务,对外暴露出支持http的接口,并输出含推演结果信息的json字符串;通过该方案,一方面解决了不同的模型使用不同的ai框架的封装问题(封装成独立服务或docker,并暴露特定的接口);另一方面解决了深度伪造模型升级或产生新的算法时,可以不停机实现新模型的横向扩展的问题。
附图说明
13.图1是部署平台整体架构图;图2是本发明主要使用流程图。
具体实施方式
14.下面结合图1至图2,对本发明做进一步详细叙述。
15.参阅图1,一种基于插件式部署的深度伪造及检测模型应用系统,包括应用层:使用户可以通过客户端与部署平台进行交互;web服务层:用于封装部署平台的常用功能界
面;应用服务层:用于对各模型推理服务进行服务部署、任务调度、gpu调度、结果保存以及程序监控操作;模型接口层:是所有插件化的、封装好的模型推理服务所提供的接口集合;模型部署层:用于部署封装好的模型推理服务和执行推理任务;数据存储层:用于存储各种临时或永久数据。
16.深度伪造及检测模型具有一定的特殊性,即:模型的输入和输出相对是固定的。输入一般是图片、音频、视频文件中的一种或几种,输出一般是伪造的文件或检测的文本结果、图片结果或视频结果。这就给为每个模型的推演任务过程进行封装奠定了基础。本发明所采用的部署方案依赖于上述的特殊性,通过制定深度伪造模型推演过程输入输出接口标准,要求模型生成方通过自己的技术栈和ai框架完成对模型推演过程的封装形成一个独立的推演服务程序,当然,如果条件许可也可以由工程化团队负责对每个模型推演过程进行封装。对部署平台而言,并不关心具体如何封装,只关心封装出的推演服务程序是否与我们制定的标准输入输出一致。这样每一个推演服务程序就是一个独立的插件服务,对外暴露出支持http的接口,并输出含推演结果信息的json字符串。另外在后端通过java通用框架对各个推演服务程序进行服务部署、任务调度、gpu调度、结果保存、程序监控等操作,并辅以一定的前端ui界面,即可打造一个基于深度伪造与检测技术的在线推演平台。通过该方案,一方面解决了不同的模型使用不同的ai框架的封装问题(封装成独立服务或docker,并暴露特定的接口);另一方面解决了深度伪造模型升级或产生新的算法时,可以不停机实现新模型的横向扩展的问题。
17.本发明中,应用服务层实现了重要的逻辑功能,并通过提供相应的api接口供web服务层调用,具体地,所述的应用服务层包括:服务部署模块,用于将封装好的模型推理服务上传到gpu服务器进行部署运行;gpu调度模块,用于实现一台gpu服务器多个gpu显卡的资源利用监控和调配,确保模型服务运行时拥有足够的显存供模型推理正常运行;任务调度模块,负责合理安排部署平台的伪造或检测任务的运行队列,在保证每个模型服务在同一时刻最多运行一个实例的前提下,安排推理任务在多个gpu服务器合理、有序的执行;状态监测模块,用于监控每个伪造或检测任务的运行状况,同时还负责监控模型推理服务是否异常停止,确保模型推理服务停止的时候能够快速启动;结果保存模块,用于将每个伪造或检测任务的执行过程、结果信息存储到数据库中,并提供接口供web服务层调用返回伪造或检测任务执行情况给前端页面;日志监控模块,负责维护每个模型推理服务以及整个部署平台的异常或运行日志,协助定位和排查问题。
18.模型接口层是所有插件化的封装好的模型推理服务所提供的接口集合。主要由两种接口组成:第一种接口提供调动模型推理服务功能——dojobs,该接口可以根据推理模型的要求传入图片、视频或音频中的一种或多种媒体文件路径以及该模型将要运行的显卡的序号;第二种接口是获取模型推理服务的任务执行状态接口——getstatus,通过该接口可以获得推理任务的执行状态(执行到哪一步、成功还是失败),并将推理的结果通过json字符串返回。其中json字符串中字段在封装标准中进行了约定,比如输出视频定义为output_video_file字段、输出音频定义为output_audeo_file字段、输出检测报告定位为output_detection_report字段等,应用服务层的结果保存模块就可以根据标准的约定将任务的执行结果保存到关系数据库中,供前端来查询任务执行情况和结果。
19.进一步地,所述的模型部署层是多个gpu服务器组成的集群,每个gpu服务器至少
拥有一个gpu显卡。封装好的模型推理服务会部署在这些服务器中,实际的推理任务也会在这些服务器中执行。当模型推理服务的数量超过服务器集群的承受能力时可以进行横向扩展,增加更多的gpu服务器到集群中来,形成规模更大的分布式模型部署层。
20.进一步地,数据存储层是本发明的部署平台存储各种临时或永久数据的媒介。它由关系数据库、redis缓存、文件服务器三大部分组成。数据库保存部署平台的业务数据,redis缓存保存服务运行期间所产生的临时数据用以提高系统的接口性能,文件服务器用来保存运行模型推理任务输入输出的多媒体文件和报告文件数据。
21.进一步地,所述的web服务层包括用于供用户登陆及权限设置的登陆模块、用于新建伪造任务的伪造任务模块、用于新建检测任务的检测任务模块、用于查看伪造结果的伪造报告模块、用于查看检测结果的检测报告模块,web服务封装了部署平台的一些常用功能界面,具体的功能需要由web服务器层与应用服务层通过api接口交互来实现,除上述述及的功能外,还可以根据需要封装一些其他功能。应用层使用户可以通过客户端与部署平台进行交互,通过调用应用服务层提供的相关api接口,可以实现用户登录和创建、执行伪造检测任务并查看执行结果。由于整体部署方案采用前后端分离的技术,主要的运算在后端和gpu服务器上,对前端的入口没有硬性要求。因此,本发明的应用层入口可以是pc网页、微信小程序、app或windows桌面应用中的一种或多种。
22.参阅图2,本发明还公开了一种基于插件式部署的深度伪造及检测模型应用方法,包括如下步骤:s100、部署平台完成gpu服务器参数、数据库、文件服务器参数的维护;s200、每个深度伪造或检测模型根据接口标准将模型推理过程封装成可独立运行的服务程序包;s300、在部署平台的服务部署模块中输入模型服务包的运行显存大小要求、cpu核数、内存要求,服务部署模块根据上述条件选择符合条件的gpu服务器上传模型服务程序包到指定的gpu服务器中;s400、模型服务程序包上传到gpu服务器前,需要配置运行端口、服务类型、服务程序名称、输入参数个数及类型信息;s500、模型服务程序完成平台的部署入驻后,用户通过用户入口选择该模型服务新建推演任务。
23.进一步地,应用服务层将执行任务请求通过任务调度模块以及gpu调度模块在指定模型服务所在gpu服务的gpu资源有空闲的时机调用dojobs接口进行模型的推演,同时状态监测模块会定时调用该模型的getstatus接口获取该任务的执行状态和结果;任务调度模块确保任何一个时刻,每个服务模型均最多只有一个推演的实例在运行;gpu调度模块确保同一台gpu服务器上运行的服务模块耗费的gpu资源不会超过模型正常运行的资源耗费;状态监控模块获取到模型服务推演结束或推演失败时将推演的结果保存至数据库中,并将推演结果返回给应用层。
24.本发明实现过程中,能够实现插件化运行的关键是需要将模型推演过程封装成一个提供指定功能接口的可以独立运行的http服务。一方面需要有提供切实可行的适合深度伪造及检测模型推理的标准接口和输出字段标准;另一方面需要能够将推理框架和运行环境均打包封装的技术手段。
25.在标准接口方面,本发明经过实施验证,只需要提供执行推理和获取状态两个接口即可。其中执行推理接口需要指定推理该模型所需的输入参数以及gpu显卡序号信息,同时对输出结果字段做规范化定义。这份标准随着部署平台接入越来越多的深伪相关模型将会得到持续的更新和补充,特别是不同的模型在推理出的结果往往会有一些附加字段。本
发明目前集成了20个算法模型,基本上已经完成了接口标准和输出字段的标准化。
26.在封装的技术方面,一种简单的方法是可以使用anconda虚拟环境配合python wsgi web框架(flask或django) pyinstaller打包的方案来将深度学习模型的推理过程封装符合标准接口的http服务。此方法简单、容易上手,但是一般部署包比较大且运行速度较慢,稳定性也稍微差些,不过作为对实时性要求不高的深伪检测场景还是比较适用的。另一种方法是将模型的推理过程通过c 或java语言进行封装。比如可以用可以用c 的libtorch库来封装torch框架模型的推理过程,并封装成http服务;java语言可以通过deeplearing4j库实现对深度学习模型的推演过程调用和封装。总之,在封装技术上,目前各个主流技术栈对深度学习模型的调用的支持还是比较成熟的,这也是本发明可以将不同技术栈不同ai框架实现的深度伪造模型通过插件化的方式部署的前提。
27.本发明还公开了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现前述的基于插件式部署的深度伪造及检测模型应用方法。并公开了一种电子设备,包括存储器、处理器及存储在存储器上的计算机程序,所述处理器执行所述计算机程序时,实现前述的基于插件式部署的深度伪造及检测模型应用方法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。