一种基于fecf的深度灾害预案智能语义匹配方法
技术领域
1.本发明涉及自然语言处理和深度学习领域,是一种对灾害预案进行语义匹配的方法。
背景技术:
2.灾害发生具有高度的不确定性和不可预见性,所以对于灾害的处理重在灾害发生后的科学善后,所以只要在事先建立起完备的灾害应急响应处理方案,就可以有效的降低突发灾害带来的严重后果。而灾后预案的合理实施很大程度上取决于灾害预案选取准确性。通过实施合理的灾害预案,可以大大降低灾害带来的严重后果。除此之外,灾害可能的发生具有时间上的不确定性、地点的随机性,灾害后果随着不同的时间空间的变换,产生不同的结果。所以如何选择合适的灾害预案,成为一个非常重要的问题。对于灾害预案的语义匹配,可以辅助完成对灾害预案的精准选择。文本语义的匹配,通常是通过分割关键词,然后分析判断出两个文本之间的语义关联程度,传统的基于机器学习的文本匹配需要人为定义和抽取文本特征,参数较少、泛化能力较差,效率较低,不能满足高效准确的需求。有较高的错误匹配几率。
3.在灾害预案智能语义匹配的问题上,重点是语义匹配的高效性与准确性。由于灾害发生的情况的多样性与不确定性,因此对于灾害预案的语义匹配提出了更高的要求。因此要实现灾害预案语义的准确匹配,确保灾后方案实施的高效性和稳定性,提出了一种基于fecf的智能语义匹配方法,降低了语义匹配的时间并且提高了灾情预案的匹配准确性,大大节省了灾情发生到预案合理选择的时间。
技术实现要素:
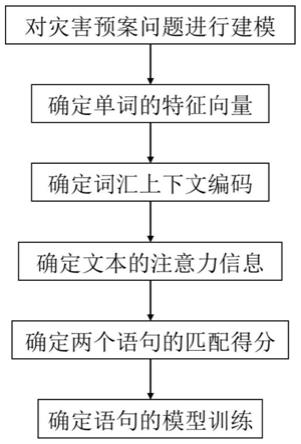
4.针对上述现有技术中存在的问题,本发明要解决技术问题是提供一种基于fecf的深度灾害预案智能语义匹配方法,其具体流程如图1所示。
5.技术方案实施步骤如下:
6.(1)对灾害预案问题进行建模:
7.score(xk,yk)=f(φ(xk),φ(yk))
8.式中,和分别是文本xk和yk的第i个和第j个词汇,φ(
·
)表示将文本进行词向量表征的函数,f(
·
)为计算两段文本语义匹配分值的匹配模型,m是语句x的长度,n是语句y的长度。
9.(2)确定单词xi的特征向量
[0010][0011]
式中,i为计数单位,e
tr
是可训练词向量矩阵,e
fix
为不可训练词向量矩阵,conv为一维卷积操作,
对于语句中的每一个词都采用上述步骤来抽取词汇特征向量,为可训练词向量,为固定词向量,为词汇前文编码向量,为词汇后文编码向量。
[0012]
(3)确定词汇上下文编码,t位置的隐含状态输出h
t
:
[0013][0014]
式中,为bi-lstm模型在t位置的正向输出,为li-lstm模型在t位置的反向输出,x
t
为t位置的输入,(
·
)
t
为转置操作。
[0015]
(4)确定文本的注意力信息
[0016][0017]
式中,n为语句y的长度,k为计数单位,e
i,k
为xi位置和yk位置隐含输出的余弦相似度,e
i,j
为xi位置和yj位置隐含输出的余弦相似度,和分别为xi位置和yj位置的隐含输出,α
i,j
为xi相对yj的注意力评分,为xi相对y的注意力向量表示。拼接基于注意力的上下文向量和触发后的作为下一层的输出同样的,确定语句y的下一层输出对不同位置的交互信息进行建模。
[0018]
(5)确定两个语句的匹配得分r:
[0019]
将得到的交互信息经过池化层和全连接层,通过一个非线性函数进行匹配得分值的输出:
[0020]
r=f(wrq br),s=wsq bs[0021]
式中,f(
·
)为非线性激活函数,wr、ws均是权重函数,br、bs是偏置向量,q为经过池化后的向量经过降序排列组成的新向量,s为经过线性变换输出的得分匹配值。
[0022]
(6)确定语句的模型训练:
[0023]
搭建卷积神经网络,将上述预处理的数据输入网络中,经过卷积层、池化层、全连接层等操作进行特征特征提取,确定两个语句的得分score(x,y):
[0024]
score(x,y)=s λs'
[0025]
式中,s是深度多视图语义模块的匹配得分,s'是基于实体上下特征的语义匹配模块得分,λ为平衡因子,调节两个模块的得分比重。
[0026]
本发明比现有技术具有的优点:
[0027]
(1)本发明有效的解决了灾害预案匹配时间较长问题,大大节省灾害预案匹配时间,提高了灾害预案的效率,为灾害发生后的处理提供了解决方案。
[0028]
(2)本发明有效的改善灾害预案文本语义匹配不准确的问题,大大提升了灾害预案匹配的准确率,为灾后处理提供了科学有效的依据。
附图说明
[0029]
为了更好地理解本发明,下面结合附图作进一步的说明。
[0030]
图1是建立基于fecf的深度灾害预案智能语义匹配方法的步骤流程图;
[0031]
图2是建立基于fecf的深度灾害预案智能语义匹配方法流程图;
[0032]
图3是卷积神经网络的结构示意图;
[0033]
图4是利用本发明对四组灾害预案进行语义匹配的结果;
具体实施方案
[0034]
本实施案例选用的数据来自地下遮蔽空间的典型示范区,一共有1000组样本,其中,来自地下隧道、铁路隧道、地下商场、地下停车场、地铁站5种场景,每种场景各有200组数据,采用随机抽样的方法从5组场景中的每份数据中各抽取140组样本作为训练集,剩下的作为测试集。最终,用作训练集的样本总数为700,用作测试集的样本总数为300。
[0035]
本发明所提供的深度灾害预案智能语义匹配方法整体流程图如图1所示,具体步骤如下:
[0036]
(1)对灾害预案问题进行建模:
[0037]
score(xk,yk)=f(φ(xk),φ(yk))
[0038]
式中,和分别是文本xk和yk的第i个和第j个词汇,φ(
·
)表示将文本进行词向量表征的函数,f(
·
)为计算两段文本语义匹配分值的匹配模型,m是语句x的长度,n是语句y的长度,分别为35和55。
[0039]
(2)确定单词xi的特征向量
[0040][0041]
式中,i为计数单位,e
tr
是可训练词向量矩阵,e
fix
为不可训练词向量矩阵,conv为一维卷积操作,对于语句中的每一个词都采用上述步骤来抽取词汇特征向量,为可训练词向量,为固定词向量,为词汇前文编码向量,为词汇后文编码向量。
[0042]
(3)确定词汇上下文编码,t位置的隐含状态输出h
t
:
[0043][0044]
式中,为bi-lstm模型在t位置的正向输出,为li-lstm模型在t位置的反向输出,x
t
为t位置的输入,(
·
)
t
为转置操作。
[0045]
(4)确定文本的注意力信息
[0046][0047]
式中,n为语句y的长度,大小为35,k为计数单位,ei,k
为xi位置和yk位置隐含输出的余弦相似度,e
i,j
为xi位置和yj位置隐含输出的余弦相似度,和分别为xi位置和yj位置的隐含输出,α
i,j
为xi相对yi的注意力评分,为xi相对y的注意力向量表示。拼接基于注意力的上下文向量和触发后的作为下一层的输出同样的,确定语句y的下一层输出对不同位置的交互信息进行建模。
[0048]
(5)确定两个语句的匹配得分r:
[0049]
将得到的交互信息经过池化层和全连接层,通过一个非线性函数进行匹配得分值的输出:
[0050]
r=f(wrq br),s=wsq bs[0051]
式中,f(
·
)为非线性激活函数,wr、ws均是权重函数,br、bs是偏置向量,q为经过池化后的向量经过降序排列组成的新向量,s为经过线性变换输出的得分匹配值。
[0052]
(6)确定语句的模型训练:
[0053]
搭建卷积神经网络,将上述预处理的数据输入网络中,经过卷积层、池化层、全连接层等操作进行特征特征提取,确定两个语句的得分score(x,y):
[0054]
score(x,y)=s 0.35s'
[0055]
式中,s是深度多视图语义模块的匹配得分,s'是基于实体上下特征的语义匹配模块得分,λ为平衡因子,取值为0.35,调节两个模块的得分比重。在搭建模型进行训练的过程中,卷积层、池化层的层数共为300,全连接层的层数为100,dropout层的概率为0.2,激活函数采用tanh函数,迭代次数为1000,通过上述参数对模型进行训练。
[0056]
对训练好的深度神经网络,利用测试集样本对模型进行测试,实现灾害预案的智能语义匹配,得到匹配结果,完成基于fecf的深度灾害预案智能语义匹配方法。
[0057]
为了验证本发明对灾害预案语义匹配的准确性,对本发明进行了四组语义匹配实验,实验结果如图4所示。由图4可知,本发明所建立的深度灾害预案智能语义匹配方法对灾害预案的语义匹配准确率均保持在96%以上,能够在保证稳定性的基础上达到较高的准确率,匹配效果良好。这表明本发明建立的灾害预案语义匹配方法是有效的,为建立准确的灾害预案匹配模型提供了更好的方法,具有一定的实用性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。