1.本发明涉及群智能感知系统激励方法领域,具体是一种基于对称加密和双层真值发现的连续群感知激励方法。
背景技术:
2.移动群智能感知(mobile crowd sensing,mcs)系统具有收集感知数据方式灵活,部署成本低等优点。随着便携式设备的普及,mcs得到了迅速的发展与广泛的应用,并以连续感知为代表的群智感知已广泛应用于智慧城市服务中。为提供实时和可靠的感知服务,连续群智感知通常要求有尽可能多的任务参与者提供感知数据。然而,因为任务参与者的行为是不可控的并且其设备具有差异性,所以最终收集的感知数据的质量也是不尽相同。并且,出于对个人隐私的保护,会降低任务参与者参与感知任务的积极性。参与任务所需要花费的代价,例如时间,需要设备的计算量等也会影响任务参与者是否能够主动参与感知任务[7]。综上,连续群智感知应用将很难收集到足够可靠的大量感知数据。为了使得更多的任务参与者接收感知任务并提供可靠的数据,需要解决激励机制设计、数据可靠性评估、隐私保护和系统执行效率的问题。
[0003]
群体智能感知通常使用金钱型激励机制来提高用户的参与度。虽然采用金钱型激励机制能够实现有效并且真实的激励,但是如何合理地分配奖励给任务参与者仍然是一个挑战。同时,虽然可以基于感知数据质量为任务参与者提供一个合理且公平的奖金,但是对于任务参与者来说,感知数据也是一种不愿意被其他实体获得的隐私信息。如何实现评估数据的可靠性并保护任务参与者的隐私仍然是一个挑战。现有隐私保护方法大都使用paillier同态加密技术,虽然可以实现数据的隐私保护,但是其计算复杂度较高,导致系统开销大。所以在隐私要求较低并且所需要的参与计算的感知数量较大时,如何减少系统的计算量,进而提高系统执行效率仍然是一个挑战。
[0004]
此外,越来越多的连续群智感知系统需要实时收集所需感知数据,因此mcs感知数据的收集通常需要流数据。然而现有方案大都无法实现连续感知任务中流数据的隐私保护并进行相应奖励的分发。为支持连续感知的流数据并实现实时的奖励分发,通常采用时间片机制将流数据分片处理,然后对单个时间片上的感知数据进行数据可靠性评估的隐私保护以及分发实时的奖励。然而,在时间片上进行真值发现并基于感知质量进行实时奖金的分发时,会存在恶意的任务参与者为了获得更多的奖励通过共谋的方式提交不可靠的感知数据,从而使得感知数据的评估真值偏离真实值的情况,并且在这个时间片上诚实的任务参与者也无法获得公平的奖励,所以如何在时间片上有恶意任务参与者时实现更加公平的实时奖励仍然时一个挑战。
技术实现要素:
[0005]
本发明的目的是提供一种基于对称加密和双层真值发现的连续群感知激励方法,以解决现有技术群智能感知系统由于隐私性问题难以收集大量感知数据,以及难以实现实
时公平奖励的问题。
[0006]
为了达到上述目的,本发明所采用的技术方案为:
[0007]
基于对称加密和双层真值发现的连续群感知激励方法,构建由连续感知平台a、连续感知平台b构成的连续群感知系统,其中连续感知平台a负责招募多个任务参与者,向任务参与者和连续感知平台b分发密钥,以及计算任务参与者的任务奖励并为任务参与者提供相应的报酬;连续感知平台b则在加密的情况下计算感知任务的估计真值和对应任务参与者的权重,方法过程如下:
[0008]
步骤1、连续感知平台a广播感知任务,招募多个任务参与者;
[0009]
步骤2、每个任务参者选择感兴趣的任务并将自己的请求发送给连续感知平台a,连续感知平台a确认任务参加者并把每个任务参加者的随机身份发送给连续感知平台b;
[0010]
步骤3、连续感知平台a基于随机数集合,计算得到每个任务参与者的加密密钥pk
i(t)
,以及连续感知平台b的聚合解密密钥并由连续感知平台a将所述加密密钥pk
i(t)
发送至每个任务参与者,以及将所述聚合解密密钥发送至连续感知平台b;
[0011]
步骤4、第一层真值发现:
[0012]
1)时间片上权重更新
[0013]
每个任务参与者接收到时间片上估计真值x
(t)
之后,计算自己的感知数据与时间片上估计真值的距离和并用自己的加密密钥pk
i(t)
加密距离得到和然后由每个任务参与者将和这两个结果发送至连续感知平台b;其中,表示时间片t内每个任务参与者收集的感知数据;
[0014]
连续感知平台b接收到所有任务参与者发送的加密的距离和后,根据安全求和算法计算得到所有任务参与者的距离函数总和如公式(6):
[0015][0016]
公式(6)中,n
t
表示时间片t内所有任务参与者的数量;
[0017]
接着,连续感知平台b计算并根据计算得到每个任务参与者的加密权重如公式(7):
[0018][0019]
公式(7),表示时间片t内每个任务参与者收集的感知数据对应的权重;
[0020]
2)时间片上真值更新
[0021]
然后,连续感知平台b生成随机掩码mc,根据每个任务参与者对应的权重计算并将结果发送给对应的任务参与者;
[0022]
每个任务参与者接收到结果后,将该结果乘以自己的感知数据,得到由每个任务参与者用自己的加密密钥pk
i(t)
对其进行加密得到并由每个任务参与者将加密后的数据发送给连续感知平台b;同时,每个任务参与者计算干扰数据并将计算的干扰数据发送给连续感知平台b;
[0023]
连续感知平台b接收到时间片t内所有任务参与者发送的消息后,执行安全求和算法,即计算公式(8):
[0024][0025]
同理,连续感知平台b计算出和
[0026]
故连续感知平台b可最终计算出公式(9):
[0027][0028]
连续感知平台b得出时间片t对应的估计真值如公式(10):
[0029][0030]
以上权重更新和真值更新步骤将进行反复迭代,直到时间片上的估计真值x
(t)
与上一轮迭代计算时间片上的估计真值x
(t)
之间差值小于给定阈值;
[0031]
连续感知平台b将计算得到的每个时间片t上每个任务参与者的加密权重和每个时间片t上估计真值x
(t)
传输给连续感知平台a;
[0032]
步骤5、连续感知平台a基于连续感知平台b传送的时间片上t每个任务参与者的加密权重和时间片上的估计真值x
(t)
,计算得到每个时间片上每个任务参与者的实时奖励;
[0033]
步骤6、第二层真值发现:
[0034]
一个周期内所有时间片的第一层真值发现后,得到每个时间片的估计真值{x
(1)
,x
(2)
,...,x(i)},连续感知平台b计算每个时间片的更新权重并使计算一个周期内的所有时间片的估计真值集合{x
(1)
,x
(2)
,...,x(i)}对应的更新估计真值x
*
,即如公式(14)所示:
[0035][0036]
以上权重更新和真值更新步骤将进行反复迭代,直到周期上的估算真值x
*
与上一轮迭代计算的估计周期真值x
*
之间差值小于给定阈值;
[0037]
连续感知平台b将周期的估计真值x
*
发送给每个任务参与者;
[0038]
每个任务参与者接收到周期的估计真值x
*
之后,计算自己的数据与周期的估计真值x
*
的距离和并用自己的加密密钥pk
i(t)
加密距离得到和由每个任务参与者将加密得到的和发送到连续感知平台b;
[0039]
连续感知平台b接收到所有任务参与者发送的后,根据安全求和算法计算得到所有任务参与者的距离函数总和如公式(15)所示:
[0040][0041]
连续感知平台b计算并根据计算得到每个任务参与者的加密权重如公式(16)所示:
[0042][0043]
连续感知平台b将计算得到的每个任务参与者的加密权重和周期上的估计真值x
*
传输给连续感知平台a;
[0044]
步骤7、连续感知平台a基于连续感知平台b传送的每个任务参与者在周期上的加密权重和估计周期真值x
*
,计算所有任务参与者在周期上的奖惩因子,以及所有任务参与者在周期上的奖励。
[0045]
进一步的,步骤3中,连续感知平台a基于随机数集合计算得到连续感知平台b的聚合解密密钥并基于随机数集合的子集计算得到每个任务参与者的加密密钥pk
i(t)
。
[0046]
进一步的,步骤3中过程如下:
[0047]
连续感知平台a通过随机数集合,计算任务参与者i的加密密钥,具体如公式(1)所示:
[0048][0049]
其中,s表示所有随机数的集合,si(i∈[1,n
t
])表示第i个随机数子集,显然h表示哈希函数;fs′
表示以s
′
为索引的伪随机函数,其中s
′
为随机数,s
′
∈si且s
′
∈{0,1}
λ
,λ∈n;每个h(fs′
(t))都是在{0,1}
λ
上均匀分布的,所以在{0,1}
λ
上也是均匀分布的;m是一个大质数;
[0050]
连续感知平台a通过已有随机数集合s,计算感知平台b的聚合解密密钥,具体如公式(2)所示:
[0051][0052]
进一步的,步骤5过程如下:
[0053]
连续感知平台a解密每个时间上每个任务参与者的权重如公式(11)所示:
[0054][0055]
连续感知平台a计算每个时间片上的每个任务参与者的权重如公式(12)所示:
[0056][0057]
连续感知平台a计算每个时间片上每个任务参与者的实时奖励
如公式(13)所示:
[0058][0059]
进一步的,步骤7过程如下:
[0060]
连续感知平台a解密周期上所有任务参与者的权重如公式(17)所示:
[0061][0062]
连续感知平台a计算周期内所有任务参与者的权重和如公式(18)所示:
[0063][0064]
连续感知平台a计算所有任务参与者在周期上的奖励如公式(19)所示:
[0065][0066]
连续感知平台a计算所有任务参与者在周期上的奖惩因子,过程如下:
[0067]
作为一个奖惩因子,其定义为如果则任务参与者i被奖励个单位的金钱;否则被惩罚个单位的金钱;当即任务参与则者因为提供不可靠消息被惩罚较多的金钱使得最终奖励为负收益时,给予任务参与者较少的任务参与奖励;其中,0.1设置为最基本的参与金钱奖励。
[0068]
进一步的,步骤7中,连续感知平台a还计算所有任务参与者在周期上的最终奖励如公式(20)所示:
[0069][0070]
本发明使用一种对称加密进行隐私保护,使用双层真值发现提高感知数据可靠性,并基于感知质量设计激励机制提高任务参与者积极性。本发明在以下两个方面具有创新:
[0071]
1)在隐私要求较高并且所需要的参与计算的感知数量较大时,使用对称加密算法对感知数据进行隐私保护,降低计算开销,进而减少奖励计算时间,从隐私保护方法设计上实现一种实时激励机制。
[0072]
2)在连续感知任务中,提出双层真值发现模型,用真值发现权重衡量数据可靠性,当时间片上有大量不可靠的感知数据时,实现诚实的任务参与者仍能得到基于感知质量的合理的实时奖励,实现一种公平的激励机制。
附图说明
[0073]
图1是本发明双层数据流真值计算模型原理图。
[0074]
图2是本发明连续群感知系统架构图。
[0075]
图3是本发明仿真实验所用真实气温数据图。
[0076]
图4是本发明仿真实验所用气温合成的感知数据图。
[0077]
图5是本发明仿真实验时rmse迭代曲线对比图。
[0078]
图6是本发明仿真实验时真值评估结果对比图。
[0079]
图7是本发明仿真实验时无恶意行为的奖励示意图。
[0080]
图8是本发明仿真实验时有恶意行为的奖励示意图。
具体实施方式
[0081]
下面结合附图和实施例对本发明进一步说明。
[0082]
本发明基于对称加密和双层真值发现的连续群感知激励方法,主要目标包括隐私目标性和公平性目标:
[0083]
隐私性目标:为了满足任务参与者的隐私需求,本发明的隐私目标包括对任务参与者的提交感知数据和权重的双重隐私保护。具体而言,对提交感知数据的隐私保护是指除了数据所有者之外,没有任何实体可以获得感知数据的具体内容;而对权重的隐私保护是指为防止任务参与者根据自己的权重值推测其他任务参与者的权重值,任务参与者不应知道自己的权重值,系统中尽可能少的实体知道任务参与者的权重值,并且系统外没有别的实体可以获得任务参与者在感知任务中的权重信息。
[0084]
公平性目标:当一个时间片上有任务参与者为了获得更多的奖励,存在有共谋或者伪造数据等恶意行为的情况下,能实现诚实的任务参与者能够获得更多的奖励,恶意的任务参与者获得较少的奖励。
[0085]
本发明所用到的符号及含义如表1所示:
[0086]
表1相关符号及定义表
[0087][0088]
本发明方法中计算了双层数据流的估计真值,双层数据流真值计算模型属于数据流的真值计算,该模型包括两次估计真值计算。如图1所示,其第一层真值计算是对单独一个时间片内的数据计算估计真值,第二层真值计算是对每个时间片估计的真值再求真值。具体如下,已知一个周期内包含的感知数据流为{υ1,υ2,...,υi},其中第一层真值计算需要计算每个时间片内数据的估计真值x(1≤t≤i);第二层真值计算需要计算估计的真值集合{x
(1)
,x
(2)
,...,x(i)}的真值x
*
。
[0089]
两层数据流真值计算可以有效的解决由于任务参与者为了获得更多的奖励有共谋或者伪造数据等恶意行为,使得该时间片的评估的真值偏离真值的问题。例如,一个时间片内的6个任务参与者有4个共谋并提交偏离真实值的感知数据,根据第一层的真值计算会使得4个共谋的任务参与者比诚实的任务参与者获得更大的权重。一般情况,一个恶意的任务参与者可以在一个时间片上与多个任务参与者共谋,但是他几乎不可能在一个采样周期内与大多数的任务参与者共谋,所以两层数据真值计算模型可以有效的防止任务参与者共谋使得感知数据偏离真实值,从而使得诚实的任务参与者获得一个公平的奖励。
[0090]
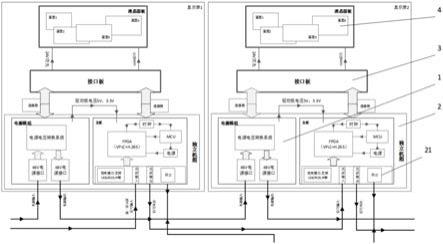
本发明中连续群感知系统架构如图2所示,包含连续感知平台a、连续感知平台b和一群任务参与者。连续感知平台a负责招募任务参与者,向任务参与者和连续感知平台b分发密钥,并根据规定的条件计算任务参与者的任务奖励为其提供相应的报酬;连续感知平台b则在加密的情况下,以保护任务参与者感知数据隐私性的方式计算感知任务的真值和对应任务参与者的权重;任务参与者接收感兴趣的感知任务并根据要求收集相应的数据,
然后使用私钥对数据进行加密与连续感知平台b进行真值发现,最后从连续感知平台a处获得相应的奖励。
[0091]
本发明假定任务参与者为半诚实体,在提交数据时不会随意篡改自己的感知数据。同时,在本发明研究的连续群感知系统是一种需要任务参与者在多个采样周期内收集感知数据的感知模式。在这种连续感知模式下,允许任务参与者在一个采样周期的任意时间提交感知数据,但一个任务参与者在一个采样周期内提交多次数据,只认为其中的第一次数据提交是有效的提交数据。
[0092]
本发明过程如下:
[0093]
步骤1.参与者招募:连续感知平台a广播感知任务,招募任务参与者。
[0094]
步骤2.任务参者选择感兴趣的任务并将自己的请求发送给连续感知平台a,连续感知平台a确认任务参加者并把任务参加者的随机身份发送给连续感知平台b。
[0095]
步骤3.连续感知平台a为任务参与者提供加密密钥,并为连续感知平台b提供聚合解密密钥。
[0096]
本发明提出一种对称加密方法,具体为在保护单个感知数据隐私的情况下,聚合所有感知数据密文,进而得到所有感知数据的明文总和。感知平台a根据随机数集合为感知平台b产生聚合解密密钥,并根据随机数集合的子集为任务参与者产生加密私钥。如此,感知平台b不能知道任何任务参与者的加密私钥,因为它不知道随机数子集和任务参与者之间的映射关系。
[0097]
1)感知平台a产生任务参与者的加密密钥:
[0098]
连续感知平台a通过随机数集合,计算任务参与者i的加密密钥,具体如公式(1)所示:
[0099][0100]
其中,s表示所有随机数的集合,si(i∈[1,n
t
])表示第i个随机数子集,显然h表示哈希函数;fs′
表示以s
′
为索引的伪随机函数,其中s
′
为随机数,s
′
∈si且s
′
∈{0,1}
λ
,λ∈n;每个h(fs′
(t))都是在{0,1}
λ
上均匀分布的,所以在{0,1}
λ
上也是均匀分布的;m是一个大质数。
[0101]
2)感知平台a产生感知平台b的聚合解密密钥:
[0102]
连续感知平台a通过已有随机数集合s,计算感知平台b的聚合解密密钥,具体如公式(2)所示:
[0103][0104]
3)通过安全的通信信道,感知平台a将和分别发送给感知平台b和每个任务参与者。
[0105]
4)任务参与者使用私钥加密自己的数据得到加密后的数据如公式(3)所示:
[0106][0107]
需要说明的是,此处是任务参与者待加密数据的统称。
[0108]
5)感知平台b使用聚合解密密钥得到聚合数据c
(t)
,具体表示如公式(4)所示:
[0109][0110]
6)感知平台a使密钥解密任务参与者的数据表示为公式(5)所示:
[0111][0112]
步骤4.第一层真值发现:在加密环境下,感知平台b与时间片上所有任务参与者计算并更新时间片内感知任务的估计真值和时间片上所有任务参与者的权重,并将得到的时间片上所有任务参者的加密权重和真值信息传输给感知平台a。
[0113]
1)时间片上权重更新
[0114]
每个任务参与者接收到时间片上估计真值x
(t)
之后,计算自己的感知数据与时间片上估计真值的距离和并用自己的加密密钥pk
i(t)
加密距离得到和然后由每个任务参与者将和这两个结果发送至连续感知平台b;其中,表示时间片t内每个任务参与者收集的感知数据;
[0115]
连续感知平台b接收到所有任务参与者发送的加密的距离和后,根据安全求和算法计算得到所有任务参与者的距离函数总和如公式(6):
[0116][0117]
公式(6)中,n
t
表示时间片t内所有任务参与者的数量;
[0118]
接着,连续感知平台b计算并根据计算得到每个任务参与者的加密权重如公式(7):
[0119][0120]
公式(7),表示时间片t内每个任务参与者收集的感知数据对应的权重;
[0121]
2)时间片上真值更新
[0122]
然后,连续感知平台b生成随机掩码mc,根据每个任务参与者对应的权重计算并将结果发送给对应的任务参与者;
[0123]
每个任务参与者接收到结果后,将该结果乘以自己的感知数据,得到由每个任务参与者用自己的加密密钥pk
i(t)
对其进行加密得到并由每个任务参与者将加密后的数据发送给连续感知平台b;同时,每个任务参与者计算干扰数据并将计算的干扰数据发送给连续感知平台b;
[0124]
连续感知平台b接收到时间片t内所有任务参与者发送的消息后,执行安全求和算法,即计算公式(8):
[0125][0126]
同理,连续感知平台b计算出和
[0127]
故连续感知平台b可最终计算出公式(9):
[0128][0129]
连续感知平台b得出时间片t对应的估计真值如公式(10):
[0130][0131]
以上权重更新和真值更新步骤将进行反复迭代,直到时间片上的估算真值x
(t)
与上一轮迭代计算时间片上的估计真值x
(t)
之间差值小于给定阈值;
[0132]
连续感知平台b将计算得到的每个时间片t上每个任务参与者的加密权重和每个时间片t上估计真值x
(t)
传输给连续感知平台a;
[0133]
步骤5.实时奖励:根据接收的加密权重数据,感知平台a解密并计算每个任务参与者的实时奖励,并分发奖励。
[0134]
连续感知平台a解密每个时间上每个任务参与者的权重如公式(11)所示:
[0135][0136]
连续感知平台a计算每个时间片上的每个任务参与者的权重如公式(12)所示:
[0137][0138]
连续感知平台a计算每个时间片上每个任务参与者的实时奖励如公式(13)所示:
[0139][0140]
步骤6.第二层真值发现:根据多个时间片内的估计真值,感知平台b计算周期上感知任务的估计真值,然后在加密环境下,与周期上所有任务参与者计算并更新周期上每个任务参与者的权重,最后将得到的周期上每个任务参者的加密权重和真值信息传输给感知平台a。
[0141]
一个周期内所有时间片的第一层真值发现后,得到每个时间片的估计真值{x
(1)
,x
(2)
,...,x(i)},连续感知平台b计算每个时间片的更新权重并使计算一个周期内的所有时间片的估计真值集合{x
(1)
,x
(2)
,...,x(i)}对应的更新估计真值x
*
,即如公式(14)所示:
[0142]
[0143]
以上权重更新和真值更新步骤将进行反复迭代,直到周期上的估算真值x
*
与上一轮迭代计算的估计周期真值x
*
之间差值小于给定阈值;
[0144]
连续感知平台b将周期的估计真值x
*
发送给每个任务参与者;
[0145]
每个任务参与者接收到周期的估计真值x
*
之后,计算自己的数据与周期的估计真值x
*
的的距离和并用自己的加密密钥pk
i(t)
加密距离得到和由每个任务参与者将加密得到的和发送到连续感知平台b;
[0146]
连续感知平台b接收到所有任务参与者发送的后,根据安全求和算法计算得到所有任务参与者的距离函数总和如公式(15)所示:
[0147][0148]
连续感知平台b计算并根据计算得到周期上每个任务参与者的加密权重如公式(16)所示:
[0149][0150]
连续感知平台b将计算得到的每个任务参与者的加密权重和周期上的估计真值x
*
传输给连续感知平台a;
[0151]
步骤7.最终奖励:根据任务参与者第一层真值发现的权重值和第二层真值发现的权重值,感知平台a计算奖惩因子、确定最终奖励,并分发给参与用户。
[0152]
连续感知平台a解密周期上所有任务参与者的权重如公式(17)所示:
[0153][0154]
连续感知平台a计算周期内所有任务参与者的权重和如公式(18)所示:
[0155][0156]
连续感知平台a计算所有任务参与者在周期上的奖励如公式(19)所示:
[0157][0158]
连续感知平台a计算所有任务参与者在周期上的奖惩因子,过程如下:
[0159]
作为一个奖惩因子,其定义为如果则任务参与者i被奖励个单位的金钱;否则被惩罚个单位的金钱。特别的当即任务参与则者因为提供不可靠消息被惩罚较多的金钱使得最终奖励为负收益时,给予任务参与者较少的任务参与奖励。其中,0.1设置为最基本的参与金钱奖励。
[0160]
连续感知平台a还计算所有任务参与者在周期上的最终奖励如公式(20)所示:
[0161][0162]
本发明方法隐私性分析如下:
[0163]
定义隐私性。本发明方法中连续感知平台和任务参与者是半诚实且每个时间片上任务参与者i≥2的情况下,系统中每个任务参与者的感知数据没有被出自己以外其他实体获得;任务参与者不知道自己的权重值,本发明系统架构中尽可能少的实体知道任务参与者的权重值,并且系统外没有别的实体可以获得任务参与者在感知任务中的权重信息。
[0164]
定理1本发明所提基于对称加密方法能实现感知数据和权重的双重隐私性。
[0165]
证明:在整个基于感知质量的激励过程中,连续感知平台和任务参与者之间的数据传输都是通过对称加密进行的,系统外部的实体无法获得相关的真实数据。为此,任务参与者的真实身份也用随机身份来代替。
[0166]
在权重更新阶段,连续感知平台b无法获得单个任务参与者真实的感知数据和真实的权重值。任务参与者计算相应的值然后用自己的私钥进行加密,连续感知平台b接收到所有任务参与者的加密的数据后,使用聚合解密密钥进行解密,得到的是所有参与者的数据总和。单个任务参与者是注重隐私的,不会主动将自己拥有的私钥与连续感知平台b共享,所以感知平台b无法获得单个任务参与者真实的感知数据并且连续感知平台b只能在加密的情况下计算出任务参与者的权重值,无法获得单个任务参与者的真实权重信息。
[0167]
在真值更新阶段,任务参与者无法获得自己真实的权重值,感知平台b无法获得单个任务参与者真实的加权感知数据。为了避免任务参与者使用自己的私钥对自己的权重值进行解密获得自己的权重值并推测其他任务参者的数据,连续感知平台b使用随机掩码二次加密任务参与者的加密权重。连续感知平台b会诚实的执行系统任务,不会将自己生成的随机掩码告诉任务参与者,所以任务参者无法获得自己真实的权重信息。在接受到所有任务参与者加密的加权感知数据后,使用聚合解密密钥进行解密,得到的是所有任务参与者的数据总和,而无法获得单个数据值。
[0168]
在计算感知奖励阶段,连续感知平台a无法获得任务参与者真实的感知数据。连续感知平台a虽然拥有任务参与者的私钥但连续感知平台b只会给它传输任务参与者的权重值和感知任务的评估真值,所以连续感知平台a无法通过私钥解密获得任务参与者真实的感知数据值。
[0169]
综上所述,本发明实现了感知数据和权重的双重隐私性。
[0170]
本发明数值仿真与结果分析如下:
[0171]
1、实验环境与参数设置
[0172]
实验数据集:实验所使用的感知数据集是从中国天气网上获得5个时间段的真实气温,然后基于真实数据产生服从高斯分布x~n(μ,σ2)的数据集,其中μ为收集的真实气温。假定有一个连续感知任务要求任务参与者收集某公园的五个时间段如图3气温以给出人们出行建议。通过连续移动感知任务,就可以获的所需的气温数据,从而无需在公园系统的安装温度传感器,减少安装和维护成本。
[0173]
设备及参数设置:实验用matlab编写实现连续感知任务。实验由intel(r)core(tm)i7-1065g7 cpu@1.30ghz 1.50ghz处理器,16gb内存,以及操作系统为windows 10的笔记本电脑完成。此外,本发明实验选用的加密算法为sha-256,安全参数为128bits。一个时间片的时间长度设置为60秒,连续感知的采样周期数g设置为5。图4显示了实验所使用的感知数据,本发明最终的实验结果都是基于运行1000次的平均值。
[0174]
2、性能分析
[0175]
2.1收敛性
[0176]
实验使用第5个采样周期的感知数据集x~n(17,0.6),数据量为200。选用方案[25]中的方法,并采用rmse来体现评估的真值和实际真值之间的差异。此外,为了检验sdim的收敛性,本发明将sdim产生的结果与crh
[25]
、rptd
[26]
方案产生的结果进行对比,具体对比图如图5所示。从图5可以看出,本发明所提出的sdim方案通过迭代,估计的真值与真实值之间的差距会减少并且逐渐收敛;本发明所提方法收敛速度快,并且收敛终值与rptd、crh的差值保持在0.01以内。
[0177]
2.2、方法可行性
[0178]
sdim计算周期上的真值并通过权重更新计算第二次奖励分发。为了证明sdim所提出的计算出周期真值方法的可行性,与相关所提的crh
[25]
进行了对比实验,对比结果如图6所示。从图6可以看出,在数据量为200,感知数据集服从x~n(12,0.5)分布情况下,sdim所得到的评估真值与crh所得到的评估真值差别小于0.005,并且与真值值之间的差别小于0.05。实验结果证明了sdim使用方法的可行性。
[0179]
2.3、奖励分发的时效性
[0180]
实验使用第二个采样周期的数据作为感知数据,该采样周期包含5个时间片,且每个时间片的数据量分别是24、28、60、47和17。实验中,将priinc4ri
[18]
设置为对比方案。如表2和表3所示的分别是sdim和priinc4ri的实时奖励分发时间与最终奖励分发时间对比。从表2可以看出,1)在本发明所提出的方案中,每个时间片上任务参与者提交的感知数据不同时,每个任务参与者只需要等待约0.02秒便可以得到第一次的奖励,等待奖励的时间远小于时间片的时间,奖励机制可以被认为时有效的实时奖励;2)sdim进行实时奖励分发的时间远小于priinc4ri进行实时奖励分发的时间,priinc4ri中每个任务参与者需要等待约3秒得到第一轮的实时奖励奖励,在数据量增加的过多时,计算奖励所用的时间会明显增加甚至会大于一个时间片60秒的时间,便不能实现有效的实时奖励。从表3可以看出,1)在一个采样周期中进行一次数据收集以后,priinc4ri需要等待约3秒完成第二轮奖励分发,而sdim中任务参与者只需要等待约0.1秒后便得到最终的奖励,可见sdim中奖励分发的高效
性;2)sdim计算奖励分发的时间远小于priinc4ri所用的时间,这是因为在整个系统中,实体使用加法加密数据,而priinc4ri中需要使用pailler同态加密的方法来加密数据,后者的计算量明显大于加法运算的计算量;3)在感知任务的隐私性要求不是特别高的时候,使用paillier同态加密的方法增加了成本。
[0181]
表2实时奖励分发时间
[0182]
时间片数priinc4ri(秒)sdim(秒)11.4520.00921.7080.01033.5920.02042.8410.01751.0290.008
[0183]
表3最终奖励分发时间
[0184]
方案最终奖励分发时间priinc4ri(秒)2.627sdim(秒)0.102
[0185]
2.4、奖励分发机制的有效性
[0186]
实验使用与前面相同的感知数据。图7所示为任务参与者没有恶意行为时,任务参与者的实时奖励和最终奖励;图8所示为存在一个时间片上有任务参与者共谋提交不可靠的感知数据时的实时奖励和最终奖励情况。特别地,图8的感知数据是将有24个感知数据的时间片1上的15个数据设置为xi′
=xi 1,并将时间片1作为有故障的时间片。对比图7与图8可知,当时间片1上有15个任务参与者共谋提供不可靠的感知数据时,会导致时间片1上诚实的任务参与者在实时奖励时无法得到公平的奖励;通过本发明使用的奖励机制在最终奖励时,即使一个时间片上有大量恶意的任务参与者共谋,诚实的任务参与者也可以获得公平的奖励,而不诚实的任务参与者则获得较少的奖励。体现了奖励机制的有效性和公平性。
[0187]
故,本发明针对连续群智感知迅速发展,隐私保护、感知数据可靠性以及如何激励使得收集大量感知数据备受关注的现状,本发明提出了一种基于对称加密和双层真值发现的连续群智感知激励机制。使用对称加密方法实现感知数据传输过程中的隐私保护,使用真值发现来提高感知数据的可靠性,并根据数据质量提出激励机制,提高任务参与者的积极性进而收集到更多的感知数据。最后本发明通过仿真证明了所使用方法的收敛性,可行性以及激励机制的高效性,在时间片上有恶意行为时,仍可以得到更加公平的奖励,提高任务参与者的积极性。虽然sdim在数据可靠性评估上进行了有益的探索,然而实际的连续群智感知应用需求的数据是异构的,即感知数据不仅有数值型数据、也包括文本数据和图片、视频等多媒体数据。因此,如何在连续群智感知中的数据收集阶段评估异构数据的可靠性仍有待探索。
[0188]
本发明所述的实施例仅仅是对本发明的优选实施方式进行的描述,并非对本发明构思和范围进行限定,在不脱离本发明设计思想的前提下,本领域中工程技术人员对本发明的技术方案作出的各种变型和改进,均应落入本发明的保护范围,本发明请求保护的技术内容,已经全部记载在权利要求书中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。